前言
同样是一个 很常用的 glibc 库函数
不管是 用户业务代码 还是 很多类库的代码, 基本上都会用到 内存数据的拷贝
不过 我们这里是从 具体的实现 来看一下
它的实现 主要是使用 汇编 来进行实现的, 因此 理解需要一定的基础
测试用例
就是简单的使用了一下 memcpy, memset, memcmp
#include "stdio.h"
int main(int argc, char** argv) {
int x = 2;
int y = 3;
int z = x + y;
void *p1 = malloc(20);
void *p2 = malloc(20);
void *p3 = malloc(20);
printf("p1 : 0x%x\n", p1);
printf("p2 : 0x%x\n", p2);
printf("p3 : 0x%x\n", p3);
memset(p1, 'a', 12);
memcpy(p2, p1, 17);
int p1CmpResult = memcmp(p1, p2);
printf(" x + y = %d, p1CmpResult = %d\n ", z, p1CmpResult);
}
memcpy 的实现
memcpy 的实现是在 memcpy.S 中
但是通过调试发现, 类库的很多 memcpy 的调用都是走的这个 memcpy.S
但是 用户代码中的 memcpy 却没有进入这里的断点, 呵呵 这个就是一些 我们常规的理解 和 实际运行时存在差异的一个体现了, 调试是 最准确的能够说明确实执行的这里的代码的证据
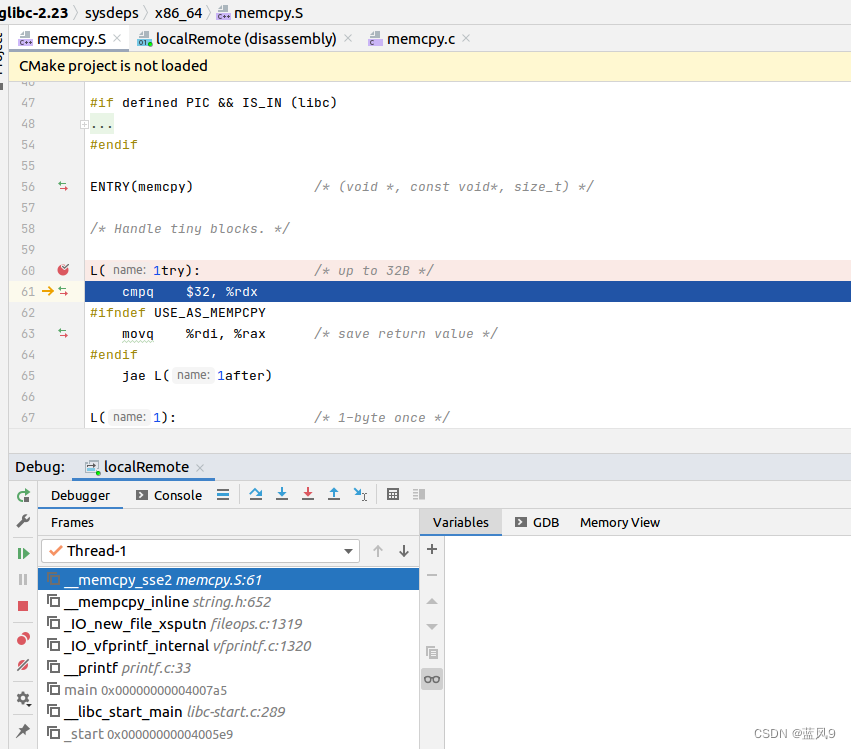
上面 memcpy 的调用, 在 main 中的代码如下
可以看到是调用 "printf(" x + y = %d, p1CmpResult = %d\n ", z, p1CmpResult);" 的时候, 用户代码调用了 printf 函数, 然后 printf 的实现中具体调用了 memcpy 来处理业务 [这里主要是复制第一个 占位符之前的 常量字符串部分 " x + y = "]
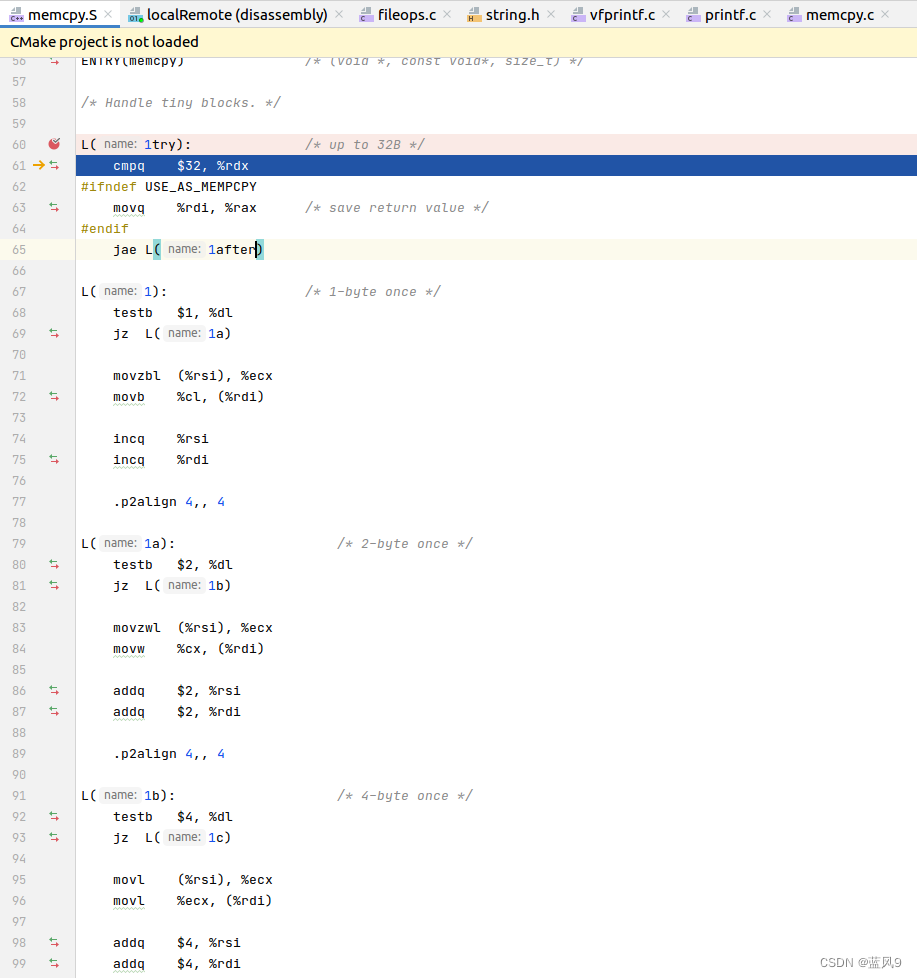
如果是需要拷贝的长度 大于等于 32 字节, 则走后面 1after 的逻辑, 待会儿来看, 这里先看 小于 32 字节的拷贝处理
道理大致如下, 32 以下的数字, 换为二进制的表示, 最大为 0b11111, 数字 0-31 的表示为 0/1个16 + 0/1个8 + 0/1个4 + 0/1个2 + 0/1个1
因此 这里就是如果有 1 个 1, 则拷贝 1 字节, 如果有 1 个 2, 则拷贝 2 字节, 如果有 1 个 4, 则拷贝 4字节, 如果有 1 个 8, 则拷贝 8 字节, 如果有 1 个 16, 则拷贝 16 字节
走到最后, 需求的 数量的数据均拷贝完成, 效率也是 最极限的效率

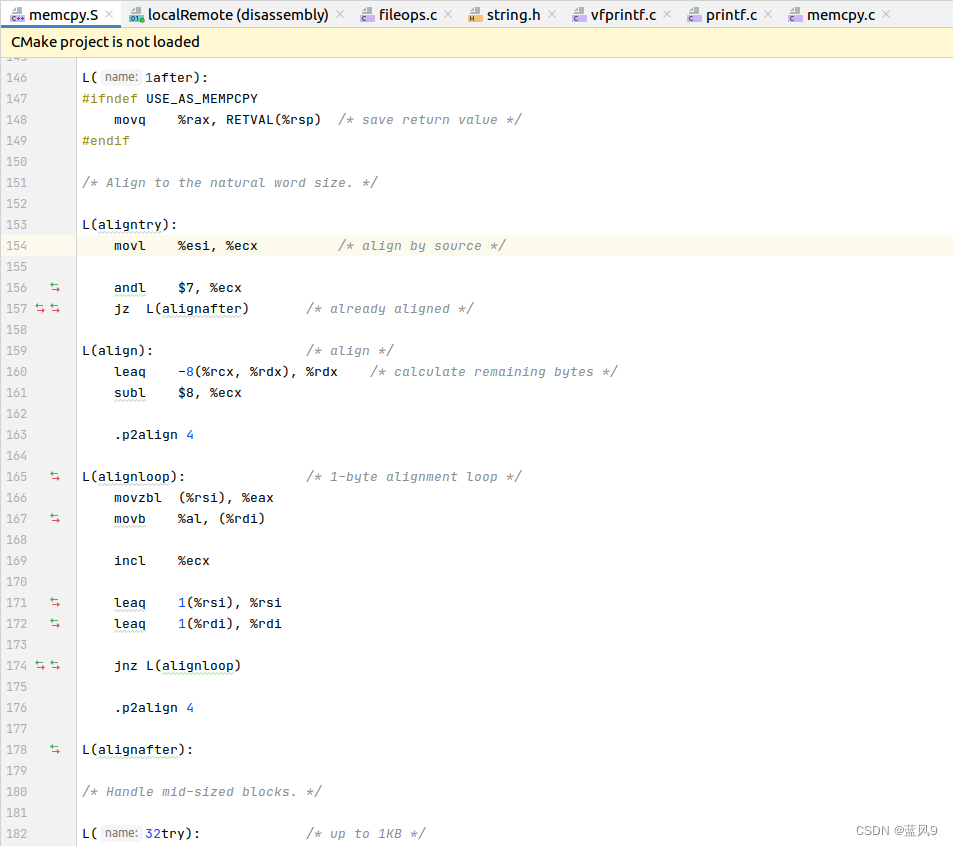
如果是待拷贝的字节数大于等于 32 字节
先拷贝源字节对其 对齐 8 字节的数据, 这里的 alignloop 就是循环处理 这多余的字节, 单字节循环处理
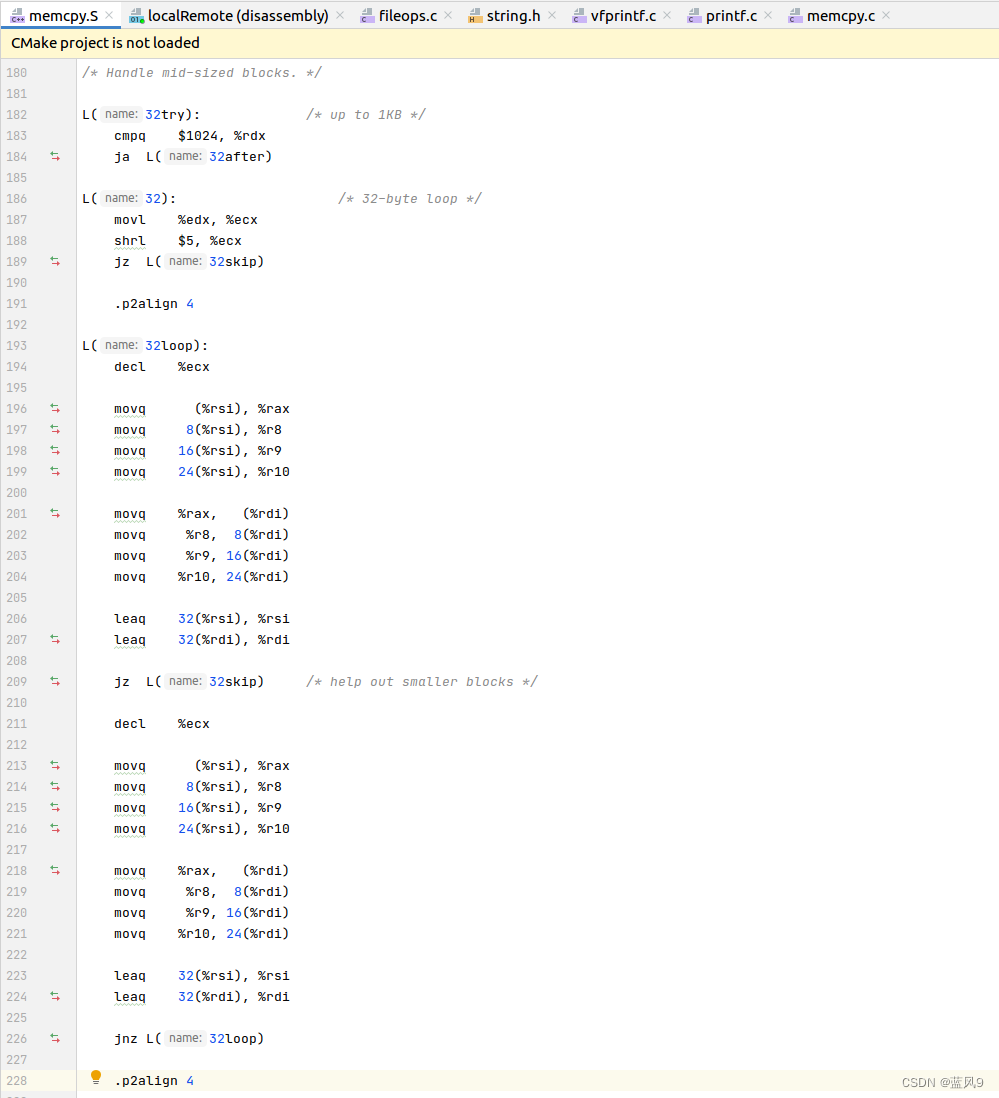
后面的 32try, 以 32 字节为单位来开始循环拷贝数据, 循环拷贝, 最终剩余的数据小于 32 字节, 跳转到上面 小于32字节的处理流程
后面的 大于1kb 的场景, 我们这里就不深究了
完