文章目录
- Grid_mdp.py
- 定义和初始化
- 从环境状态构建观测值
- Reset
- Step
- Rendering
- Close
- 注册环境
- 参考文章
Grid_mdp.py
定义和初始化
首先自定义环境,自定义的环境将继承gym.env环境。在初始化的时候,可以指定环境支持的渲染模式(例如human,rgb_array,ansi)以及渲染环境的帧速率。当没有初始化的时候都有默认的渲染模式,在Grid World中将支持rgb_array和human模式,并以4FPS的速度渲染。
环境的__init__方法将接受整数大小,它决定了方形网格的大小。同时将设置一些用于渲染的变量,并定义self.observation_space和self.action_space。
在我们代码中,观测值应该提供有关代理和目标在二维网格上的位置的信息。将选择以字典的形式表示观察结果,并带有键“代理”和“目标”。观察结果可能看起来像 {“agent”: array([1, 0]), “target”: array([0, 3])}。由于我们的环境中有 4 个动作(“右”、“上”、“左”、“下”),将使用 Disparte(4) 作为动作空间。以下是GridWorldEnv的声明和__init__的实施:
import gym
from gym import spaces
import pygame
import numpy as np
class GridEnv(gym.Env):
metadata = {"render_modes": ["human", "rgb_array"], "render_fps": 4}
def __init__(self, render_mode=None, size=5):
self.size = size # The size of the square grid
self.window_size = 512 # The size of the PyGame window
# Observations are dictionaries with the agent's and the target's location.
# Each location is encoded as an element of {0, ..., `size`}^2, i.e. MultiDiscrete([size, size]).
self.observation_space = spaces.Dict(
{
"agent": spaces.Box(0, size - 1, shape=(2,), dtype=int),
"target": spaces.Box(0, size - 1, shape=(2,), dtype=int),
}
)
# We have 4 actions, corresponding to "right", "up", "left", "down", "right"
self.action_space = spaces.Discrete(4)
"""
The following dictionary maps abstract actions from `self.action_space` to
the direction we will walk in if that action is taken.
I.e. 0 corresponds to "right", 1 to "up" etc.
"""
self._action_to_direction = {
0: np.array([1, 0]),
1: np.array([0, 1]),
2: np.array([-1, 0]),
3: np.array([0, -1]),
}
assert render_mode is None or render_mode in self.metadata["render_modes"]
self.render_mode = render_mode
"""
If human-rendering is used, `self.window` will be a reference
to the window that we draw to. `self.clock` will be a clock that is used
to ensure that the environment is rendered at the correct framerate in
human-mode. They will remain `None` until human-mode is used for the
first time.
"""
self.window = None
self.clock = None
从环境状态构建观测值
我们需要在reset和step中计算观测值,因此通常可以方便地使用_get_obs私有方法将环境状态转化为观测值:
def _get_obs(self):
return {"agent": self._agent_location, "target": self._target_location}
对于逐步返回并重置的辅助信息,机器人找金币例子中,提供agent和target之间的曼哈顿距离:
def _get_info(self):
return {"distance": np.linalg.norm(self._agent_location - self._target_location, ord=1)}
通常,信息还将包含一些仅在步骤方法中可用的数据(例如个人奖励条款)。在这种情况下,我们将不得不更新 _get_info 按步骤返回的字典。
Reset
每次使用reset的方法来启动新的episode,每当发出完成信号是,都应该调用reset。可以传递seed进行重置,以将环境使用的任何随机数生成器初始化为确定性状态。在机器人找金币实例中,我们随机选择agent的位置和随机抽样的target位置,直到它与agent的位置不一致。
def reset(self, seed=None, options=None):
# We need the following line to seed self.np_random
super().reset(seed=seed)
# Choose the agent's location uniformly at random
self._agent_location = self.np_random.integers(0, self.size, size=2, dtype=int)
# We will sample the target's location randomly until it does not coincide with the agent's location
self._target_location = self._agent_location
while np.array_equal(self._target_location, self._agent_location):
self._target_location = self.np_random.integers(
0, self.size, size=2, dtype=int
)
observation = self._get_obs()
info = self._get_info()
if self.render_mode == "human":
self._render_frame()
return observation, info
Step
step方法通常包括环境的大部分逻辑。它接受一个操作,在应用该操作后计算环境的状态,并返回四元组(观察、奖励、完成、信息)。一旦计算了环境的新状态,就可以检查它是否是最终状态,并相应地设置完成。由于在GridWorld中使用稀疏二进制,因此一旦知道完成,计算奖励就变得微不足道。为收集观察和信息,再次利用_get_obs和_get_info:
def step(self, action):
# Map the action (element of {0,1,2,3}) to the direction we walk in
direction = self._action_to_direction[action]
# We use `np.clip` to make sure we don't leave the grid
self._agent_location = np.clip(
self._agent_location + direction, 0, self.size - 1
)
# An episode is done iff the agent has reached the target
terminated = np.array_equal(self._agent_location, self._target_location)
reward = 1 if terminated else 0 # Binary sparse rewards
observation = self._get_obs()
info = self._get_info()
if self.render_mode == "human":
self._render_frame()
return observation, reward, terminated, False, info
Rendering
在这里,我们使用 PyGame 进行渲染。在 Gym 附带的许多环境中都使用了类似的渲染方法:
def render(self):
if self.render_mode == "rgb_array":
return self._render_frame()
def _render_frame(self):
if self.window is None and self.render_mode == "human":
pygame.init()
pygame.display.init()
self.window = pygame.display.set_mode((self.window_size, self.window_size))
if self.clock is None and self.render_mode == "human":
self.clock = pygame.time.Clock()
canvas = pygame.Surface((self.window_size, self.window_size))
canvas.fill((255, 255, 255))
pix_square_size = (
self.window_size / self.size
) # The size of a single grid square in pixels
# First we draw the target
pygame.draw.rect(
canvas,
(255, 0, 0),
pygame.Rect(
pix_square_size * self._target_location,
(pix_square_size, pix_square_size),
),
)
# Now we draw the agent
pygame.draw.circle(
canvas,
(0, 0, 255),
(self._agent_location + 0.5) * pix_square_size,
pix_square_size / 3,
)
# Finally, add some gridlines
for x in range(self.size + 1):
pygame.draw.line(
canvas,
0,
(0, pix_square_size * x),
(self.window_size, pix_square_size * x),
width=3,
)
pygame.draw.line(
canvas,
0,
(pix_square_size * x, 0),
(pix_square_size * x, self.window_size),
width=3,
)
if self.render_mode == "human":
# The following line copies our drawings from `canvas` to the visible window
self.window.blit(canvas, canvas.get_rect())
pygame.event.pump()
pygame.display.update()
# We need to ensure that human-rendering occurs at the predefined framerate.
# The following line will automatically add a delay to keep the framerate stable.
self.clock.tick(self.metadata["render_fps"])
else: # rgb_array
return np.transpose(
np.array(pygame.surfarray.pixels3d(canvas)), axes=(1, 0, 2)
)
Close
close 方法应关闭环境使用的任何开放资源。在许多情况下,通常不需要额外使用该方法。但是,在我们的示例中,render_mode可能是“人类”,我们可能需要关闭已打开的窗口:
def close(self):
if self.window is not None:
pygame.display.quit()
pygame.quit()
注册环境
- 将我们⾃⼰的环境⽂件(笔者创建的⽂件名为
grid_mdp.py)拷⻉到你的gym安装⽬录/gym/gym/envs/classic_control⽂件夹中(拷⻉在此⽂件夹中是因为要使⽤rendering模块。 - 打开该⽂件夹(第⼀步中的⽂件夹)下的
__init__.py⽂件,在⽂件末尾加⼊语句:
from gym.envs.classic_control.grid_mdp import GridEnv
- 进⼊⽂件夹的
gym安装⽬录/gym/gym/envs,打开该⽂件夹下
的__init__.py⽂件,添加代码:
register(
# gym.make(‘id’)时的id
id=“GridWorld-v0”,
# 函数路口
entry_point=“gym.envs.classic_control.grid_mdp:GridEnv”,
max_episode_steps=200,
reward_threshold=100.0,
)
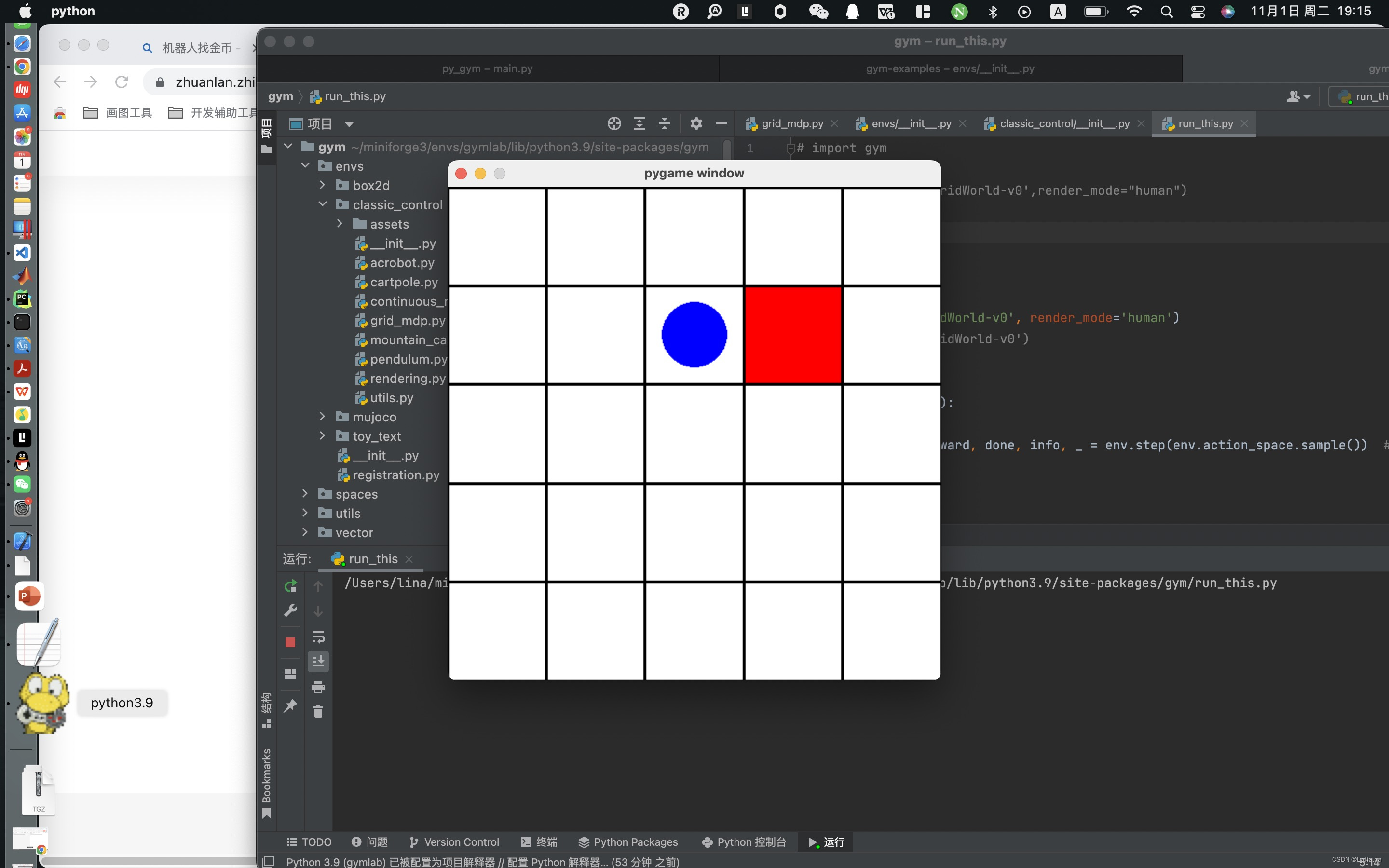
- 用pycharm打开项目,解释器为安装gym环境的解释器。同时运行以下代码:
import gym
env = gym.make('GridWorld-v0', render_mode='human')
#env = gym.make('GridWorld-v0')
env.reset()
env.render()
for _ in range(1000):
env.render()
observation, reward, done, info, _ = env.step(env.action_space.sample()) # take a random action
if done:
env.reset()
env.close()
- 代码运行后出现如下结果:
参考文章
https://www.gymlibrary.dev/content/environment_creation/







![[ Linux ] 重定向的再理解,以及文件系统的理解、inode和软硬链接](https://img-blog.csdnimg.cn/img_convert/44a707415d2f26d4ae016e7c3a48b1fd.png)