项目实战 | YOLOv5 + Tesseract-OCR 实现车牌号文本识别
最近看到了各种各样的车牌识别,觉得挺有意思,自己也简单搞一个玩玩😼。
传统的图像处理算法我也不太会,就直接用深度学习的方法实现吧。
文章目录
- 项目实战 | YOLOv5 + Tesseract-OCR 实现车牌号文本识别
- 1. 预期效果
- 2. 整体流程
- 3. 准备数据集
- 4. 训练YOLOv5模型
- 4.1 下载源码
- 4.2 安装环境
- 4.3 修改配置文件
- 4.4 训练模型
- 4.5 测试模型
- 5. 截取车牌
- 6. 形态学处理
- 7. Tesseract-OCR安装
- 7.1 下载 Tesseract-OCR
- 7.2 配置环境变量
- 7.3 调用Tesseract-OCR
- 7.4 显示中文
- 8. 完整代码
- 9. 数据集及代码资源
- 10. 更多YOLOv5实战内容
1. 预期效果
先看看预期的效果吧,大概就是这样子的,输入一张图片可以把图片中的车牌号以文本的形式打印出来。目前还比较简陋,以后可以尝试加个PyQt5页面实现更加丰富的功能。


2. 整体流程
- 首先训练一个
YOLOv5的车牌检测器; - 然后将车牌切下来;
- 将切下来的部分通过
OpenCV进行形态学处理; - 最后通过
Tesseract-OCR识别车牌并在控制台上打印。
3. 准备数据集
这次就不自己标注了,直接找了一个开源的。训练集 245 245 245张、验证集 70 70 70张、测试集 35 35 35张。数据集质量一般。

4. 训练YOLOv5模型
4.1 下载源码
git clone https://github.com/ultralytics/yolov5
4.2 安装环境
pip install -qr requirements.txt
4.3 修改配置文件
license.yaml
train: D:\Pycharm_Projects\datasets\License\train\images
val: D:\Pycharm_Projects\datasets\License\valid\images
nc: 2
names: ['license-plate', 'vehicle']
4.4 训练模型
数据量比较少,直接用yolov5s跑就可以。
python train.py --weights yolov5s.pt --cfg yolov5s.yaml --datalicense.yaml --epoch 100 --batch-size 16
简单跑了 100 100 100轮,看着还可以,就直接用了。

4.5 测试模型
python detect.py --source D:\Pycharm_Projects\datasets\License\valid\images --weights runs\train\exp\weights\best.pt


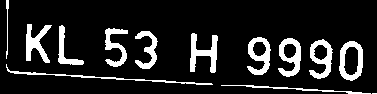
5. 截取车牌
python detect.py --source D:\Pycharm_Projects\datasets\License\valid\images --weights runs\train\exp2\weights\best.pt --save-crop --classes 0
 |  | |
|---|---|---|
 |  | |
 |  |
因为数据集质量原因,有一些图拍摄不是很清晰,所以截取到的车牌也不是很清楚,我这里选了一些相对来说清楚一些的。其实到这里我们就可以通过Tesseract-OCR进行识别了,但是不对图像进行处理就识别的话效果很不好,所以我这里还是选择对车牌进行一些形态学处理。
6. 形态学处理
这部分也不算完全意义上的形态学处理吧,我并没有使用腐蚀膨胀等操作,只是使用了几个OpenCV的础操作对车牌进行了处理,大家可以对比一下效果。(其实还有很大的优化空间的)
| 原始图片 | 处理后 |
|---|---|
 |  |
 |  |
 |  |
def Corver_Gray(image_path):
# 读取模板图像
img = cv2.imread(image_path)
# 转换为灰度图 也可读取时直接转换
ref = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 二值图像
ref = cv2.threshold(ref, 60, 255, cv2.THRESH_BINARY_INV)[1]
return ref
7. Tesseract-OCR安装
7.1 下载 Tesseract-OCR

下载地址:Tesseract-OCR
我下载的是最下面的版本,下载好后直接安装就可以,没有什么坑。

7.2 配置环境变量


7.3 调用Tesseract-OCR
在调用前要导入 pytesseract 包。
pip install pytesseract
随后在YOLOv5项目里新建一个py文件
text = pytesseract.image_to_string(Image.open("test.png"))
print(text)
传入图片的路径后就可以在控制台看到最终输出的结果了。



7.4 显示中文
如果想显示车牌上的中文,我们还要下载一个东西,下载地址:tessdata/chi_sim.traineddata

下载好后直接放到如下位置就可以。代码也要改动一下。


8. 完整代码
import cv2
from PIL import Image
import pytesseract
def Corver_Gray(image_path):
# 读取模板图像
img = cv2.imread(image_path)
# 转换为灰度图 也可读取时直接转换
ref = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 二值图像
ref = cv2.threshold(ref, 60, 255, cv2.THRESH_BINARY_INV)[1]
return ref
def Read_Img(img_path):
image = Corver_Gray(img_path)
image = cv2.imwrite("test.png", image)
return image
Read_Img(r"D:\GitHub\Yolov5_Magic\number\1.png")
text = pytesseract.image_to_string(Image.open("test.png"))
print(text)
9. 数据集及代码资源

给个赞吧~
链接:https://pan.baidu.com/s/1MKWPpb8dAcZwFQPqjCwTaA?pwd=csdn
提取码:csdn
10. 更多YOLOv5实战内容
更多YOLOv5实战内容可以关注我的专栏







![[ Linux ] 重定向的再理解,以及文件系统的理解、inode和软硬链接](https://img-blog.csdnimg.cn/img_convert/44a707415d2f26d4ae016e7c3a48b1fd.png)