SentenceTransformers 是一个可以用于句子、文本和图像嵌入的Python库。 可以为 100 多种语言计算文本的嵌入并且可以轻松地将它们用于语义文本相似性、语义搜索和同义词挖掘等常见任务。
该框架基于 PyTorch 和 Transformers,并提供了大量针对各种任务的预训练模型。 还可以很容易根据自己的模型进行微调。
阅读论文 Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks,深入了解模型的训练方式。
在本文中,我们将看到该库的一些可能用例的代码示例。 模型训练将在后面的文章中介绍。
安装
在深入研究代码之前,使用pip安装sentencetransformer库。
sentence-transformers (Sentence Transformers) (huggingface.co)
pip install -U sentence-transformers
Sentence-Transformers使用方法介紹
Sentence-Transformers使用分兩個部分
- 使用Pretrained Model進行Inference
- Train你自己的BERT的model
因为BERT embedding的维度动辄就是500, 700,后续运算不易,一般会直接用PCA来做dimension reduction。而实际上Sentence-Transformers有很多已经针对特定问题预训练好的Model了,后面举两个例子。
使用Pretrained Model进行Inference
获得嵌入向量
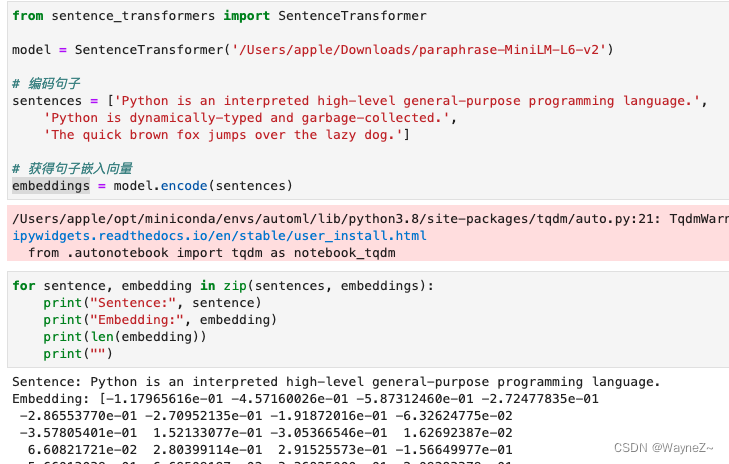
语义文本相似度
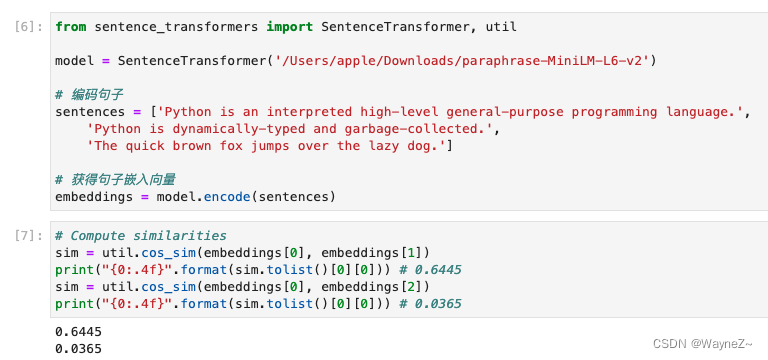
一旦我们有了句子的嵌入,我们就可以使用util模块中的cos_sim函数来计算它们的余弦相似度。
取值范围为[-1:1],取值为-1表示完全不相似,取值为1表示完全相似
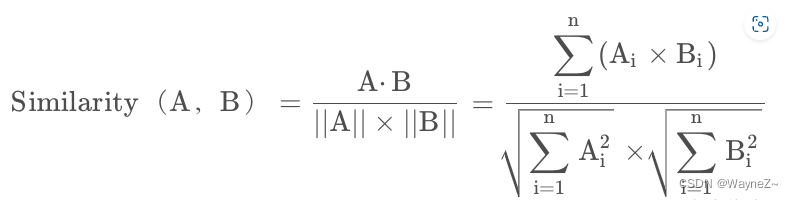
语义搜索
语义搜索通过理解搜索查询的内容来提高搜索的准确性,而不是仅仅依赖于词汇匹配。这是利用嵌入之间的相似性完成的。
语义搜索是将语料库中的所有条目嵌入到向量空间中。在搜索时,查询也会被嵌入到相同的向量空间中,并从语料库中找到最接近的嵌入。
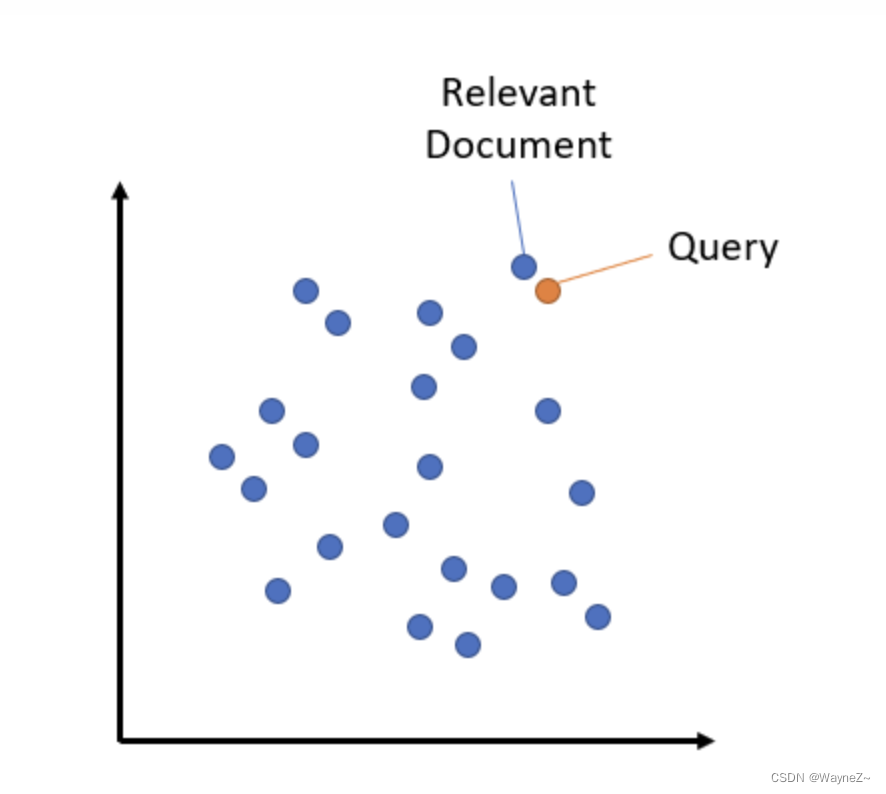
向量空间中语义搜索的例子。
语义搜索可以使用util模块的semantic_search函数来执行,该函数处理语料库中的文档的嵌入和查询的嵌入。
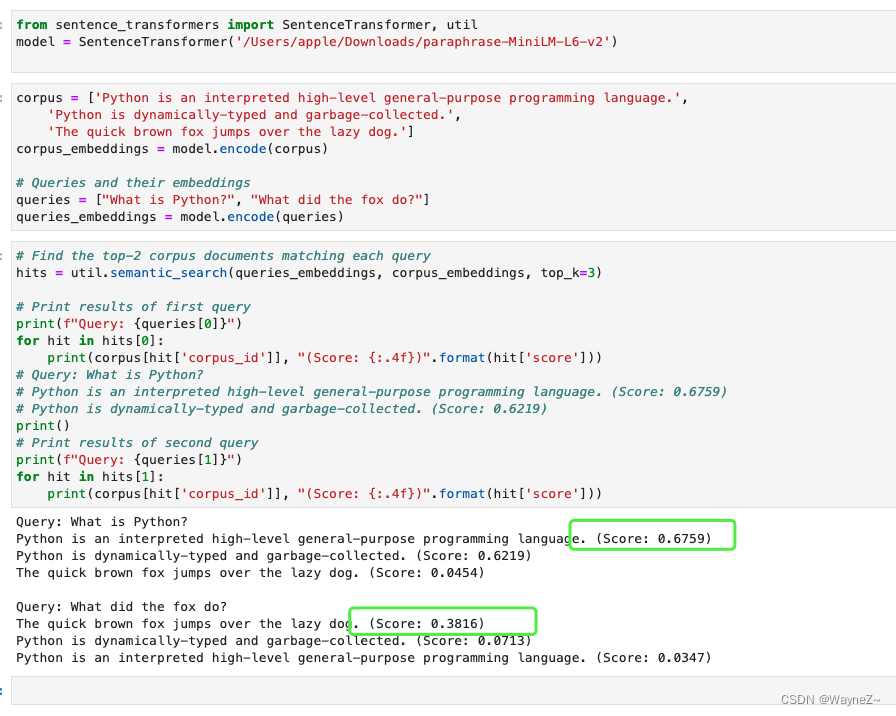
为了充分利用语义搜索,必须区分对称和非对称语义搜索,因为它会严重影响要使用的模型的选择。
Paraphrase Mining
Paraphrase Mining是在大量句子中寻找释义的任务,即具有非常相似含义的文本。
这可以使用 util 模块的 paraphrase_mining 函数来实现。
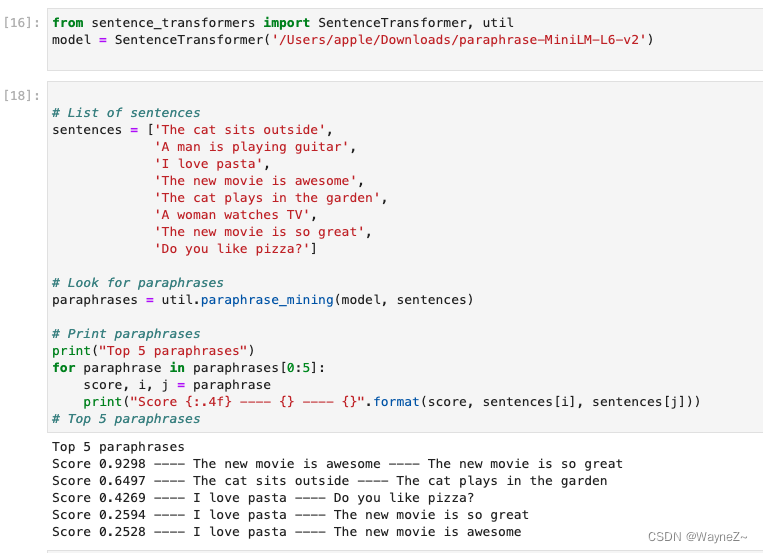
图片搜索
Image Search = 給定文字敘述,看跟圖像內容是否相似。
使用’clip-ViT-B-32'这个model就可以同时encode图片跟文字,并且两个出来的embedding可以直接算similarity,得到文字叙述跟图像内容的相似程度
SentenceTransformers 提供允许将图像和文本嵌入到同一向量空间,通过这中模型可以找到相似的图像以及实现图像搜索,即使用文本搜索图像,反之亦然。

同一向量空间中的文本和图像示例。
要执行图像搜索,需要加载像 CLIP 这样的模型,并使用其encode 方法对图像和文本进行编码。

多模态模型获得的嵌入也允许执行图像相似性等任务。
Extractive Summarization
给文章,Model从里面选几句话当成这个文章的摘要可以直接参考官方的example
"""
This example uses LexRank (https://www.aaai.org/Papers/JAIR/Vol22/JAIR-2214.pdf)
to create an extractive summarization of a long document.
The document is splitted into sentences using NLTK, then the sentence embeddings are computed. We
then compute the cosine-similarity across all possible sentence pairs.
We then use LexRank to find the most central sentences in the document, which form our summary.
Input document: First section from the English Wikipedia Section
Output summary:
Located at the southern tip of the U.S. state of New York, the city is the center of the New York metropolitan area, the largest metropolitan area in the world by urban landmass.
New York City (NYC), often called simply New York, is the most populous city in the United States.
Anchored by Wall Street in the Financial District of Lower Manhattan, New York City has been called both the world's leading financial center and the most financially powerful city in the world, and is home to the world's two largest stock exchanges by total market capitalization, the New York Stock Exchange and NASDAQ.
New York City has been described as the cultural, financial, and media capital of the world, significantly influencing commerce, entertainment, research, technology, education, politics, tourism, art, fashion, and sports.
If the New York metropolitan area were a sovereign state, it would have the eighth-largest economy in the world.
"""
import nltk
from sentence_transformers import SentenceTransformer, util
import numpy as np
from LexRank import degree_centrality_scores
model = SentenceTransformer('paraphrase-distilroberta-base-v1')
# Our input document we want to summarize
# As example, we take the first section from Wikipedia
document = """
New York City (NYC), often called simply New York, is the most populous city in the United States. With an estimated 2019 population of 8,336,817 distributed over about 302.6 square miles (784 km2), New York City is also the most densely populated major city in the United States. Located at the southern tip of the U.S. state of New York, the city is the center of the New York metropolitan area, the largest metropolitan area in the world by urban landmass. With almost 20 million people in its metropolitan statistical area and approximately 23 million in its combined statistical area, it is one of the world's most populous megacities. New York City has been described as the cultural, financial, and media capital of the world, significantly influencing commerce, entertainment, research, technology, education, politics, tourism, art, fashion, and sports. Home to the headquarters of the United Nations, New York is an important center for international diplomacy.
Situated on one of the world's largest natural harbors, New York City is composed of five boroughs, each of which is a county of the State of New York. The five boroughs—Brooklyn, Queens, Manhattan, the Bronx, and Staten Island—were consolidated into a single city in 1898. The city and its metropolitan area constitute the premier gateway for legal immigration to the United States. As many as 800 languages are spoken in New York, making it the most linguistically diverse city in the world. New York is home to more than 3.2 million residents born outside the United States, the largest foreign-born population of any city in the world as of 2016. As of 2019, the New York metropolitan area is estimated to produce a gross metropolitan product (GMP) of $2.0 trillion. If the New York metropolitan area were a sovereign state, it would have the eighth-largest economy in the world. New York is home to the highest number of billionaires of any city in the world.
New York City traces its origins to a trading post founded by colonists from the Dutch Republic in 1624 on Lower Manhattan; the post was named New Amsterdam in 1626. The city and its surroundings came under English control in 1664 and were renamed New York after King Charles II of England granted the lands to his brother, the Duke of York. The city was regained by the Dutch in July 1673 and was subsequently renamed New Orange for one year and three months; the city has been continuously named New York since November 1674. New York City was the capital of the United States from 1785 until 1790, and has been the largest U.S. city since 1790. The Statue of Liberty greeted millions of immigrants as they came to the U.S. by ship in the late 19th and early 20th centuries, and is a symbol of the U.S. and its ideals of liberty and peace. In the 21st century, New York has emerged as a global node of creativity, entrepreneurship, and environmental sustainability, and as a symbol of freedom and cultural diversity. In 2019, New York was voted the greatest city in the world per a survey of over 30,000 people from 48 cities worldwide, citing its cultural diversity.
Many districts and landmarks in New York City are well known, including three of the world's ten most visited tourist attractions in 2013. A record 62.8 million tourists visited New York City in 2017. Times Square is the brightly illuminated hub of the Broadway Theater District, one of the world's busiest pedestrian intersections, and a major center of the world's entertainment industry. Many of the city's landmarks, skyscrapers, and parks are known around the world. Manhattan's real estate market is among the most expensive in the world. Providing continuous 24/7 service and contributing to the nickname The City that Never Sleeps, the New York City Subway is the largest single-operator rapid transit system worldwide, with 472 rail stations. The city has over 120 colleges and universities, including Columbia University, New York University, Rockefeller University, and the City University of New York system, which is the largest urban public university system in the United States. Anchored by Wall Street in the Financial District of Lower Manhattan, New York City has been called both the world's leading financial center and the most financially powerful city in the world, and is home to the world's two largest stock exchanges by total market capitalization, the New York Stock Exchange and NASDAQ.
"""
#Split the document into sentences
sentences = nltk.sent_tokenize(document)
print("Num sentences:", len(sentences))
#Compute the sentence embeddings
embeddings = model.encode(sentences, convert_to_tensor=True)
#Compute the pair-wise cosine similarities
cos_scores = util.pytorch_cos_sim(embeddings, embeddings).numpy()
#Compute the centrality for each sentence
centrality_scores = degree_centrality_scores(cos_scores, threshold=None)
#We argsort so that the first element is the sentence with the highest score
most_central_sentence_indices = np.argsort(-centrality_scores)
#Print the 5 sentences with the highest scores
print("\n\nSummary:")
for idx in most_central_sentence_indices[0:5]:
print(sentences[idx].strip())Sentence-Transformers处理中文
如果要使用Sentence-Transformers处理中文的话,就要load裡面的Multilingual Model近来,可以参考下面页面。
常用的是paraphrase-xlm-r-multilingual-v1这个Model,不过大小1G,相对比较臃肿
model = SentenceTransformer('paraphrase-xlm-r-multilingual-v1')
其他像是distiluse-base-multilingual-cased-v2效果也非常好。
使用在非英文上的时候要特别注意,即便你今天使用的Model没有支持你需要的语言,他还是会产出Embedding,只是是非常非常差的Embedding。
所以一般需要用非常简单的word pair去测试现在的Embedding有没有正确运作。(这一步非常重要,针对特定Project我会整理出越来越复杂的Pair来测试)
下面给范例
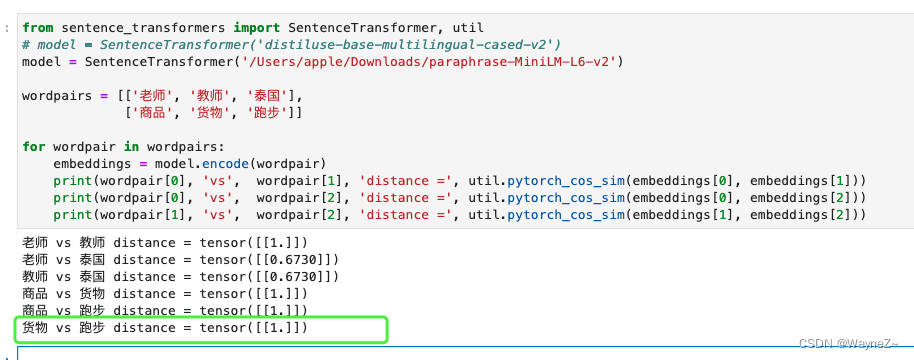
其他任务
1、对于问答检索等复杂的搜索任务,可以通过使用 Retrieve & Re-Rank 显著改进语义搜索。
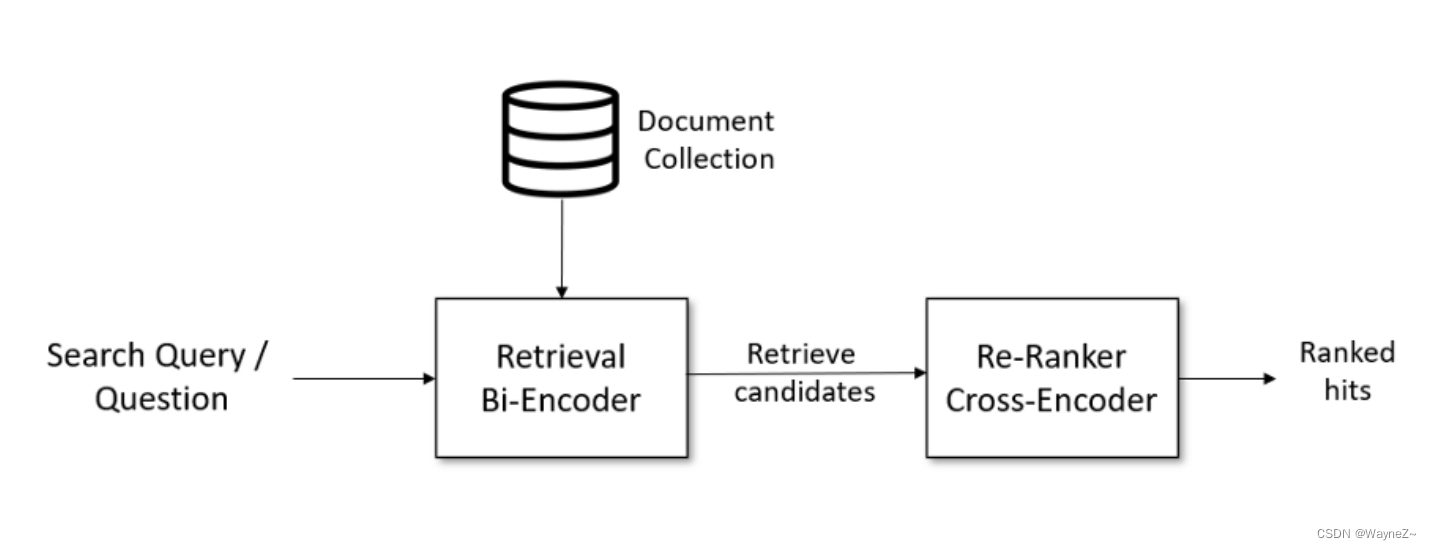 Retrieve & Re-Rank 架构
Retrieve & Re-Rank 架构
2、SentenceTransformers 可以以不同的方式用于对小或大的句子集进行聚类。

model.encode参数
sentence – 要嵌入的句子
batch_size – 用于计算的批大小
show_progress_bar – 对句子进行编码时输出进度条
output_value – 默认sentence_embedding,用于获取句子嵌入。可以设置为token_embeddings以获取字片标记嵌入。设置为"无",以获取所有输出值
convert_to_numpy – 如果为 true,则输出为 numpy 向量的列表。否则,它是一个 pytorch 张量列表。
convert_to_tensor – 如果为 true,将返回一个tensor大张量。覆盖convert_to_numpy中的任何设置
normalize_embeddings – 如果设置为 true,则返回的向量的长度将为 1。在这种情况下,可以使用更快的点积(util.dot_score)而不是余弦相似性。
需要注意的点:
1.输入的多个句子放在列表里;
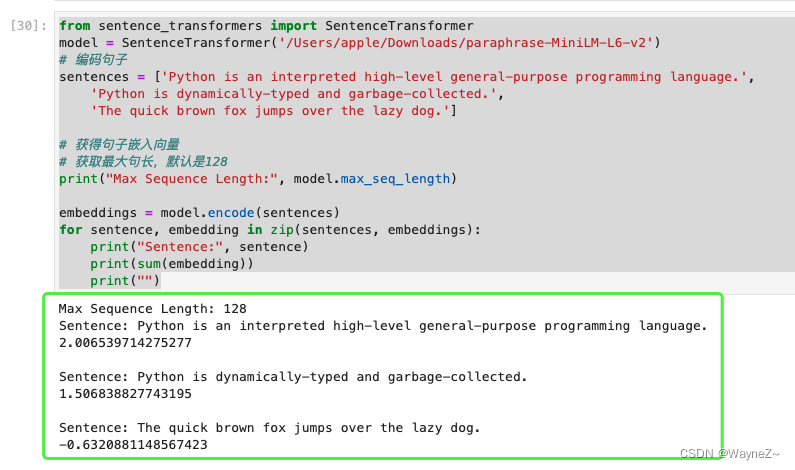
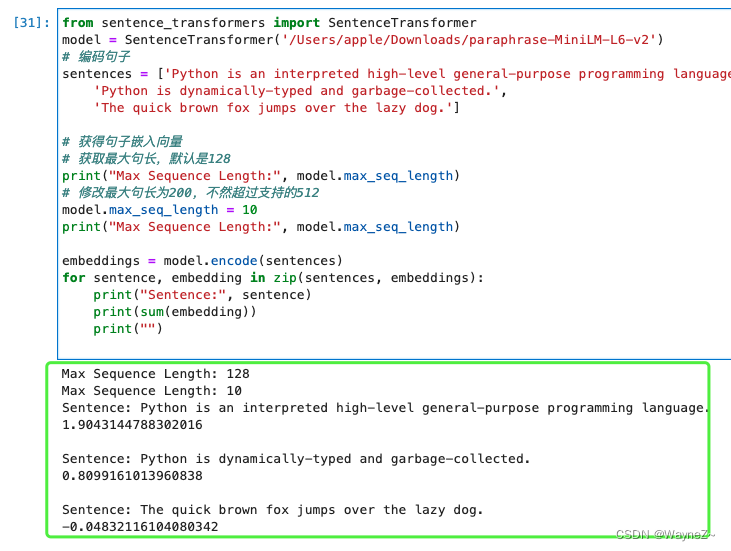
2.也可以输入短语或者长句子,超过最大句长会被截断,最大句长为512个单词片段,约为300-400单词(以英语单词来衡量)
对文档进行主题建模示例
最后 SentenceTransformers的官网:https://www.sbert.net/
作者:Fabio Chiusano
無痛使用超強NLP model — BERT. Sentence Transformers 使用方法介紹 | by 倢愷 Oscar | Medium
5分钟 NLP系列 — SentenceTransformers 库介绍 - 知乎 (zhihu.com)
文本相似度的BERT度量方法 - 知乎 (zhihu.com)
训练一个SentenceTransformer模型 | Lowin Li