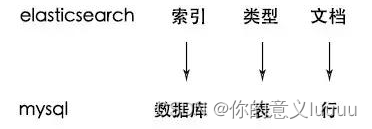
声明是ElasticSearch?
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,
基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是
当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方
便。
Solr的架构不适合实时搜索的应用。
倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值
和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位
置,因而称为倒排索引(inverted index)。
ElasticSearch的基本知识点

1、linux环境准备
(1)搭建es集群,开启集群中的三个节点(服务器)
分别进入三个集群的目录,es1,es2,es3,开启节点,搭建集群
bin/elasticsearch
(2)开启elasticSearch-head插件,查看es的运行状态以及数据,它位于集群es的plunings插件中。
在elasticsearch-head目录下执行命令, 运行head插件
npm run start
(3)Kibana是一个软件,不是插件。它位于和ElasticSearch同级目录。
Kibana 是一款开源的数据分析和可视化平台,它是 Elastic Stack 成员之一,设计用于和
Elasticsearch 协作。您可以使用 Kibana 对 Elasticsearch 索引中的数据进行搜索、查看、交互操作。
可以很方便的利用图表、表格及地图对数据进行多元化的分析和呈现。
在kibana目录下执行命令,开启kibana
bin/kibana --allow-root
(4)IK Analysis中文分词器
IK Analysis插件将Lucene IK分析器集成到elasticsearch中,支持自定义词典
ik分词器是每一个集群都需要有的,所有每一个es,如es1,es2,es3目录下的plunings目录下都有一个ik目录。
分词器会在节点开启的时候,自动开启,无需自动配置。
Analyzer分词配置解释: ik_smart:粗粒度分词,比如中华人民共和国国歌,会拆分为中华人民共和国,国歌;
ik_max_word:细粒度分词,比如中华人民共和国国歌,会拆分为中华人民共和国,中华人民,
中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌,会穷尽各种可能的组 合。
(5)mysql在linux环境下,有的时候我们搜索引擎查询的数据可能来源于数据库,也就是说搜索引擎需要从数据库中去查询。
因此我们需要在linux环境下开启我们所需要的数据库。
linux环境下安装mysql8.0.30
查看mysql是否被启动
ps -ef|grep mysql
若没有则启动mysql服务
systemctl start mysql
(6)Elasticsearch导入MySQL数据
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据
发送到您最喜欢的 “存储库” 中。(我们的存储库当然是 Elasticsearch。)
具体操作见文档。。。
因为在这一part我用到了rpc框架,所有我还需要开启zookeeper,也用到了redis缓存,所以我还需要开启zookeeper和redis,redis我设置了开机自启,所有我这里只需要手动开启zookeeper。
bin/zkServer.sh start
ElasticSearch集成springboot
(1)导入依赖
父项目导入依赖的版本号,声明依赖
<properties>
<!-- elasticsearch 依赖 -->
<elasticsearch.version>7.5.0</elasticsearch.version>
</properties>
<dependencyManagement>
<dependencies>
<!-- elasticsearch 服务依赖 -->
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
<!-- rest-client 客户端依赖 -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
<!-- rest-high-level-client 客户端依赖 -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
</dependencies>
</denpendencyManagement>
因为ElatiscSearch在前台或者后台系统中都有应用,所有我们可以将它提取出来封装成一个服务,让其他系统充当消费者的角色在需要的时候调用服务。
rpc项目中导入依赖
<!-- elasticsearch 服务依赖 -->
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
</dependency>
<!-- rest-client 客户端依赖 -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
</dependency>
<!-- rest-high-level-client 客户端依赖 -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
配置Es.config和yml文件
我们需要告诉Es.config我们linux的集群的地址,协议,端口号,让这个类文件给我们创建客户端。
application-dec.yml
# Elasticsearch
elasticsearch:
address: 192.168.186.128:9201, 192.168.186.128:9202, 192.168.186.128:9203
EsConfig java配置类
@Configuration
public class EsConfig {
//ES服务器地址
@Value("${elasticsearch.address}")
private String[] address;
//ES服务器连接方式
private static final String SCHEME = "http";
/**
* 根据服务器地址构建HttpHost对象
* @param s
* @return
*/
@Bean
public HttpHost builderHttpHost(String s){
String[] address = s.split(":");
if (2!=address.length){
return null;
}
String host = address[0];
Integer port = Integer.valueOf(address[1]);
return new HttpHost(host,port,SCHEME);
}
/**
* 创建RestClientBuilder对象
* @return
*/
@Bean
public RestClientBuilder restClientBuilder(){
HttpHost[] hosts = Arrays.stream(address)
.map(this::builderHttpHost)
.filter(Objects::nonNull)
.toArray(HttpHost[]::new);
return RestClient.builder(hosts);
}
/**
* 创建RestHighLevelClient对象
* @param restClientBuilder
* @return
*/
@Bean
public RestHighLevelClient restHighLevelClient(@Autowired RestClientBuilder restClientBuilder){
return new RestHighLevelClient(restClientBuilder);
}
}
解释:
1、只要是配置类都需要加上@Configuration注解
2、配置ElasticSearch的节点,我们首先需要获取结点的地址和端口号,也就是获取HttpPost对象,通过传进来的地址获取HtppPost对象。
HttpHost对象是Apache HttpComponents库提供的一种数据类型,用于表示一个HTTP主机地址,包括主机名、端口号和协议类型等信息。
在Elasticsearch的Java客户端中,HttpHost对象常用于配置Elasticsearch服务器的主机地址和端口号,创建连接到Elasticsearch服务器的RestClientBuilder和RestHighLevelClient对象等。
在yml文件中我们可以进行配置,然后再Config类中取出来就好了。从配置文件yml中取数据用@Value("${elasticsearch.address}"),赋值给数组。
已知String[] address={“192.168.186.128:9201”,“192.168.186.128:9202”,“192.168.186.128:9201”};
创建HttpPost对象的函数为new HttpHost(host,port,SCHEME)。
获取host,post可以获取address的每一个元素然后对他进行分隔,得到host和post。SCHEME是协议。
SCHEME常量用于构建HttpHost对象时指定HTTP协议的类型,即"http"或"https"。定义的是一个私有的静态常量,因此它只能被本类中的其他方法调用,而且它不需要基于任何实例化对象而存在,不能被修改。
@Bean
public HostPost bulderHostPost(String s){
String[] address=s.split(":");
if(2!=address.length()){
return null;
}
String host = address[0];
int post = Integer.valueOf(address[1]);
return new HttpPost(host,post,Scheme);
}
用@Bean是要把HostPost对象放入spring容器中进行管理。
RestClient是Elasticsearch官方提供的RESTful风格的Java客户端,封装了对Elasticsearch服务器的REST API的访问。它提供了更高层次的API,对JSON数据格式和HTTP请求和响应进行了更好的封装和管理。RestClient同时又支持低级别的查询和索引操作。RestClient分为Low Level REST Client和High Level REST Client两种,Low Level REST Client提供基础的 REST API 操作,而High Level REST Client提供了更加高级的 API 接口以及更强的可扩展性。
接下来就是HostPost创建连接到ElasticSearch服务器的客户端了。
创建客户端直接调用RestClient.builder(HttpPost)
通过传进来的所有地址和端口号,获取一个RestClient客户端
利用java8新特性,我们可以将传过来的数组进行改造,返回一个HttpPost类型的数组。
@Bean
public RestClientBuilder restClientBuilder(){
HttpHost[] hosts = Arrays.stream(address)
.map(this::builderHttpHost)
.filter(Objects::nonNull)
.toArray(HttpHost[]::new);
return RestClient.builder(hosts);
}
创建RestHighLevelClient对象
/**
* @param restClientBuilder
* @return
*/
@Bean
public RestHighLevelClient restHighLevelClient(@Autowired RestClientBuilder restClientBuilder){
return new RestHighLevelClient(restClientBuilder);
}
后端代码调用
因为把搜索引擎抽取出来当做服务了,因此需要用到Dubbo。
首先我们要清楚搜索引擎的入参和出参是什么。当我们输入关键字,点击搜索按钮的时候,出来的一个个的框框,这个框框里面有分页,还有List集合,我们把他砍成一个对象,结合在一起,我们需要把List集合中的对象抽取出来写一个实体类,还需要定义一个相关的分页对象,返回一个分页对象到前端,渲染页面。因为要在网络中传输,所以这个对象要实现序列化。
》实体类,List集合中的类
public class GoodsVo implements Serializable {
private static final long serialVersionUID = -1905915184535584387L;
private Integer goodsId;
private String goodsName;
private String goodsNameHl;
private BigDecimal marketPrice;
private String originalImg;
public GoodsVo() {
}
public GoodsVo(Integer goodsId, String goodsName, String goodsNameHl, BigDecimal marketPrice, String originalImg) {
this.goodsId = goodsId;
this.goodsName = goodsName;
this.goodsNameHl = goodsNameHl;
this.marketPrice = marketPrice;
this.originalImg = originalImg;
}
public Integer getGoodsId() {
return goodsId;
}
public void setGoodsId(Integer goodsId) {
this.goodsId = goodsId;
}
public String getGoodsName() {
return goodsName;
}
public void setGoodsName(String goodsName) {
this.goodsName = goodsName;
}
public String getGoodsNameHl() {
return goodsNameHl;
}
public void setGoodsNameHl(String goodsNameHl) {
this.goodsNameHl = goodsNameHl;
}
public BigDecimal getMarketPrice() {
return marketPrice;
}
public void setMarketPrice(BigDecimal marketPrice) {
this.marketPrice = marketPrice;
}
public String getOriginalImg() {
return originalImg;
}
public void setOriginalImg(String originalImg) {
this.originalImg = originalImg;
}
@Override
public String toString() {
return "GoodsVo{" +
"goodsId=" + goodsId +
", goodsName='" + goodsName + '\'' +
", goodsNameHl='" + goodsNameHl + '\'' +
", marketPrice=" + marketPrice +
", originalImg='" + originalImg + '\'' +
'}';
}
}
》分页对象中里面有页数,总记录条数等等,还有一个List<T> result来存储分页查询出来的对象,这个之前我们在写商品列表的时候实现过,这里就不赘述了。可见他是经常用到,所以放在了common系统中。
public class ShopPageInfo<T> implements Serializable {
// 当前页
private int currentPage;
// 每页显示条数
private int pageSize;
// 总页数
private int total;
// 总记录数
private int count;
// 上一页
private int prePage;
// 下一页
private int nextPage;
// 是否有上一页
private boolean hasPre;
// 是否有下一页
private boolean hasNext;
// 返回结果
private List<T> result;
// 构造函数1
public ShopPageInfo() {
super();
}
// 构造函数2
public ShopPageInfo(int currentPage, int pageSize) {
super();
this.currentPage = (currentPage < 1) ? 1 : currentPage;
this.pageSize = pageSize;
// 是否有上一页
this.hasPre = (currentPage == 1) ? false : true;
// 是否有下一页
this.hasNext = (currentPage == total) ? false : true;
// 上一页
if (hasPre) {
this.prePage = (currentPage - 1);
}
// 下一页
if (hasNext) {
this.nextPage = currentPage + 1;
}
}
// 构造函数3
public ShopPageInfo(int currentPage, int pageSize, int count) {
super();
this.currentPage = (currentPage < 1) ? 1 : currentPage;
this.pageSize = pageSize;
this.count = count;
// 计算总页数
if (count == 0) {
this.total = 0;
} else {
this.total = (count % pageSize == 0) ? (count / pageSize) : (count / pageSize + 1);
}
// 是否有上一页
this.hasPre = (currentPage == 1) ? false : true;
// 是否有下一页
this.hasNext = (currentPage == total) ? false : true;
// 上一页
if (hasPre) {
this.prePage = (currentPage - 1);
}
// 下一页
if (hasNext) {
this.nextPage = currentPage + 1;
}
}
public int getCurrentPage() {
return currentPage;
}
public void setCurrentPage(int currentPage) {
this.currentPage = currentPage;
}
public int getPageSize() {
return pageSize;
}
public void setPageSize(int pageSize) {
this.pageSize = pageSize;
}
public int getTotal() {
return total;
}
public void setTotal(int total) {
this.total = total;
}
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
public int getPrePage() {
return prePage;
}
public void setPrePage(int prePage) {
this.prePage = prePage;
}
public int getNextPage() {
return nextPage;
}
public void setNextPage(int nextPage) {
this.nextPage = nextPage;
}
public boolean isHasPre() {
return hasPre;
}
public void setHasPre(boolean hasPre) {
this.hasPre = hasPre;
}
public boolean isHasNext() {
return hasNext;
}
public void setHasNext(boolean hasNext) {
this.hasNext = hasNext;
}
public List<T> getResult() {
return result;
}
public void setResult(List<T> result) {
this.result = result;
}
}
在进行搜索的时候,我需要传进去一个关键字,还有分页查询的关键字眼pageNum,pageSize
ServerImp
@Service(interfaceClass = SearchService.class)
@Component
public class SearchServiceImpl implements com.wll.shoprpc.service.SearchService {
@Resource
private RestHighLevelClient client;
/**
* 搜索
* @param searchStr
* @param pageNum
* @param pageSize
* @return
*/
@Override
public ShopPageInfo<GoodsVo> doSearch(String searchStr, Integer pageNum, Integer pageSize) {
//构建分页对象
ShopPageInfo<GoodsVo> shopPageInfo;
try {
//指定索引库
SearchRequest searchRequest = new SearchRequest("shop");
//构建查询对象
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//设置分页条件
searchSourceBuilder.from((pageNum-1)*pageSize).size(pageSize);
//构建高亮对象
HighlightBuilder highlightBuilder = new HighlightBuilder();
//设置高亮字段及高亮样式
highlightBuilder.field("goodsName")
.preTags("<span style='color:red'>")
.postTags("</span>");
searchSourceBuilder.highlighter(highlightBuilder);
//添加查询条件
searchSourceBuilder.query(QueryBuilders.multiMatchQuery(searchStr,"goodsName"));
searchRequest.source(searchSourceBuilder);
//执行请求
List<GoodsVo> list = new ArrayList<>();
SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);
//总条数
Long total = response.getHits().getTotalHits().value;
if (0>total){
return null;
}
SearchHit[] hits = response.getHits().getHits();
for (SearchHit hit : hits) {
Integer goodsId = Integer.valueOf((Integer) hit.getSourceAsMap().get("goodsId"));
String goodsName = String.valueOf(hit.getSourceAsMap().get("goodsName"));
String goodsNameHl = String.valueOf(hit.getHighlightFields().get("goodsName").fragments()[0]);
BigDecimal marketPrice = new BigDecimal(String.valueOf(hit.getSourceAsMap().get("marketPrice")));
String originalImg = String.valueOf(hit.getSourceAsMap().get("originalImg"));
GoodsVo goodsVo = new GoodsVo(goodsId,goodsName,goodsNameHl,marketPrice,originalImg);
list.add(goodsVo);
}
shopPageInfo = new ShopPageInfo<GoodsVo>(pageNum,pageSize,total.intValue());
shopPageInfo.setResult(list);
return shopPageInfo;
//处理数据
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
这是一个搜索商品的方法,可以根据搜索关键字进行商品搜索。该方法使用Elasticsearch进行搜索,根据搜索结果返回一个ShopPageInfo对象,包含符合条件的商品列表和分页信息。
参数说明:
- searchStr: 搜索关键字
- pageNum: 当前页码
- pageSize: 每页显示条目数
方法实现:
该方法首先构造了一个SearchRequest对象,并指定搜索的索引库为 "shop",然后构建一个SearchSourceBuilder对象,用于设置搜索条件。通过设置from()和size()方法实现分页功能,并使用highlighter()方法设置高亮字段及高亮样式。接着,使用multiMatchQuery()方法构建查询条件,指定需要匹配的字段和搜索关键字,将查询条件添加到SearchSourceBuilder对象中。
然后将SearchSourceBuilder对象设置到SearchRequest对象中,并通过Elasticsearch的Java客户端的search()方法执行搜索请求,并获取响应结果SearchResponse。从SearchResponse中获取到搜索结果的总条数total和匹配了查询条件的商品列表hits。遍历hits列表,从中获取商品信息,构造GoodsVo对象并添加到list中。
最后,构造ShopPageInfo对象,将list设置为结果列表,返回ShopPageInfo对象。
如果发生异常,返回null。