通过 Markdown 改进 RAG 文档处理
作者:Tableau
原文地址:https://zhuanlan.zhihu.com/p/29139791931
通过 Markdown 改进 RAG 文档处理 https://mp.weixin.qq.com/s/LOBOKNA71dANXHuwxe7yxw
https://mp.weixin.qq.com/s/LOBOKNA71dANXHuwxe7yxw
如何将 PDF 转换为 Markdown 以获得更好的 LLM RAG 结果
Markdown 是一种轻量级、易读的格式化文本语言。许多人可能通过 GitHub 的 README.md 文件熟悉 Markdown。
以下是一些基本的 Markdown 语法示例:
# Heading level 1
## Heading level 2
### Heading level 3
This is **bold text**.
This is *italicized text*.
> This text is a quote
This is how to do a link [Link Text](https://www.example.org)
This text is code
| Header 1 | Header 2 |
|------------|------------|
| table data | table data |
Markdown 正在成为大语言模型(LLMs)的流行格式。
Markdown 具有一些重要优势,例如[1]:
-
为标题、表格、列表、链接等提供结构
-
添加粗体或斜体等排版强调元素
-
易于编写且人类可读
-
已经广泛使用,例如在 GitHub 和 Jupyter notebooks 中
Markdown 不仅在 LLM 输入文档的上下文中有用,它也是像 ChatGPT 这样的聊天机器人格式化其响应的方式。注意 ChatGPT 的响应如何以大号粗体字呈现标题,并对关键词使用粗体文本。

在本文中,我们将在 LLM 和检索增强生成(RAG)的背景下探讨 Markdown。
比较 PDF 库
我们首先测试两个生成纯文本的流行 PDF 阅读器库。然后我们将尝试两个专门为 LLM 设计的新 PDF 阅读器,它们可以生成 Markup。
为了比较不同的 PDF 阅读器,我将使用 Docling 技术报告 2408.09869v3.pdf 作为我的输入 PDF 文件[2],该文件采用 CC BY 4.0 许可。
FILE = "./2408.09869v3.pdf"
PyPDF
PyPDF 是一个免费开源的 Python 库,我们可以用它来轻松读取 PDF 文档。
以下是如何使用 PyPDF 来从 PDF 文件中提取文本:
# pip install pypdf
from pypdf import PdfReader
reader = PdfReader(FILE)
pages = [page.extract_text() for page in reader.pages]
pypdf_text = "\n\n".join(pages)
输出的 pypdf_text 是一个包含提取文本的字符串。
Docling Technical Report
Version 1.0
Christoph Auer Maksym Lysak Ahmed Nassar Michele Dolfi Nikolaos Livathinos
Panos Vagenas Cesar Berrospi Ramis Matteo Omenetti Fabian Lindlbauer
Kasper Dinkla Lokesh Mishra Yusik Kim Shubham Gupta Rafael Teixeira de Lima
Valery Weber Lucas Morin Ingmar Meijer Viktor Kuropiatnyk Peter W. J. Staar
AI4K Group, IBM Research
R¨uschlikon, Switzerland
Abstract
This technical report introduces Docling , an easy to use, self-contained, MIT-
licensed open-source package for PDF document conversion. It is powered by
state-of-the-art specialized AI models for layout analysis (DocLayNet) and table
structure recognition (TableFormer), and runs efficiently on commodity hardware
in a small resource budget. The code interface allows for easy extensibility and
addition of new features and models.
1 Introduction
Converting PDF documents back into a machine-processable format has been a major challenge
然而,我注意到 PyPDF 提取的文本有一些问题:
-
标题除了被换行符包围外,与文本格式没有区别
-
文本高亮,如粗体文本,都丢失了
-
页码在换行符上(就像标题一样)
-
表格没有被正确提取
以下是真实 PDF 表格与 PyPDF 提取的表格的比较:

来自文档[2]的原始 PDF 表格与 PyPDF 提取的文本对比。作者提供的图片。
我怀疑任何人或 LLM 都无法使用这个变形的表格做出任何正确的陈述。
Unstructured
链接:http://Unstructured.io
流行的开源库 unstructured 对于 PDF 文档的处理与 PyPDF 类似。
以下是如何使用 Unstructured 来从 PDF 文件中提取文本:
# pip install unstructured[pdf]==0.16.5
from unstructured.partition.pdf import partition_pdf
elements = partition_pdf(FILE)
unstructured_text = "\n\n".join([str(el) for el in elements])
输出格式和问题与 PyPDF 类似。
Unstructured 将上面的表格提取为单行,这也不是我们想要的:
CPU Thread budget TTS native backend Pages/s Mem pypdfium backend TTS Pages/s Mem Apple M3 Max (16 cores) 4 16 177 s 167 s 1.27 1.34 6.20 GB 103 s 92 s 2.18 2.45 2.56 GB Intel(R) Xeon E5-2690 4 16 375 s 244 s 0.60 0.92 6.16 GB 239 s 143 s 0.94 1.57 2.42 GB (16 cores)
PyMuPDF4LLM
PyMuPDF4LLM 是一个专门设计用于提取 PDF 内容并将其转换为 Markdown 格式以用于 LLM 和 RAG 用例的 Python 库。
PyMuPDF4LLM 是开源的,采用 AGPL-3.0 许可。
以下是如何使用 PyMuPDF4LLM 来从 PDF 文件中提取 Markdown 文本:
# pip install pymupdf4llm==0.0.17
import pymupdf4llm
md_text = pymupdf4llm.to_markdown(FILE)
在下图中,我使用 print(md_text) 生成上面的图像,使用 IPython.display 中的 Markdown(md_text) 生成下面的图像。

从文档[2]中 PyMuPDF4LLM 提取的 Markdown 输出。作者提供的图片。
与之前的 PDF 阅读器相比,现在标题使用 Markdown 清晰地格式化。总的来说,输出非常干净。提取的文本中不再有随机的页码。
然而,PyMuPDF4LLM 没有正确解析表格示例:
Thread native backend pypdfium backend
CPU
budget
TTS Pages/s Mem TTS Pages/s Mem
Apple M3 Max 4 177 s 1.27 103 s 2.18
6.20 GB 2.56 GB
(16 cores) 16 167 s 1.34 92 s 2.45
Intel(R) Xeon
E5-2690
(16 cores)
Docling
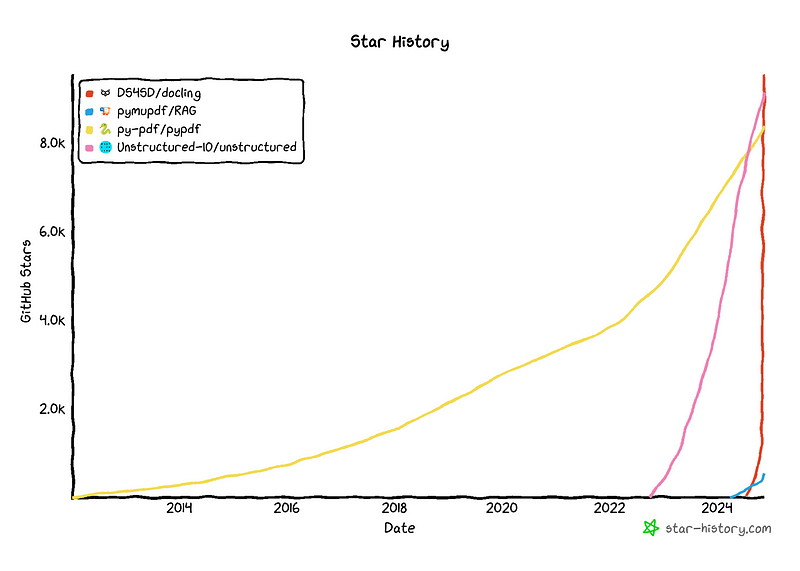
Docling 目前是 GitHub 上的热门仓库。图片由作者使用 https://star-history.com 创建。
IBM 最近发布的 Docling 可以解析文档(PDF、DOCX、PPTX、图像、HTML、AsciiDoc、Markdown)并将它们导出为 Markdown 或 JSON 格式,用于 LLM 和 RAG 用例。
Docling 是开源的,采用 MIT 许可。
以下是如何使用 Docling 来从 PDF 文件中提取 Markdown 文本:
# pip install docling==2.5.2
from docling.document_converter import DocumentConverter
converter = DocumentConverter()
result = converter.convert(FILE)
docling_text = result.document.export_to_markdown()
docling_text 的输出与 PyMuPDF4LLM 的输出类似。然而,Docling 在提取我们的示例表格方面做得更好:
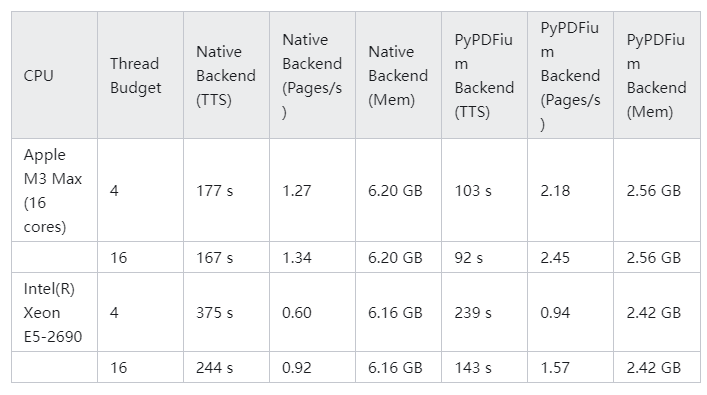
因为输入到 LLM 的表格已经是 Markdown 格式,当我们在 RAG 用例中将这些数据输入到 LLM 时,LLM 可以简单地向用户重现相同的表格,并且它将以人类可读的格式呈现。
Docling 具有出色的表格提取功能的原因是它包含了专门用于表格结构识别的 AI 模型[2]。
基于我的 PDF 文件的结果,Docling 产生了迄今为止最好的结果。 输出的 docling_text 完美地以 Markdown 格式呈现,可以用于下游的 LLM 任务。
处理速度
然而,使用 Docling 有一个缺点,那就是处理速度。我使用 timeit 计算了每个库处理我的 9 页 PDF 示例文件的平均处理速度。
虽然 Docling 给出了最好的结果,但它处理文件也花费了大约 38 秒。另一方面,PyPDF 非常快,只需 461 毫秒。
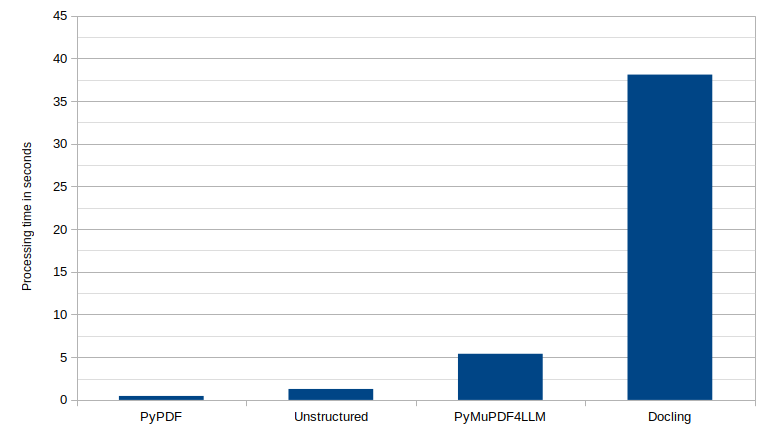
处理 9 页 PDF 文件的时间。PyPDF:461 ms,Unstructured:1.28s,PyMuPDF4LLM:5.4s,Docling:38.1s。作者提供的图片。
分块
在 RAG 上下文中处理 Markdown 的一个重要优势是我们可以使用标题将文档分成连贯的片段。
在读取 PDF 文档并将其转换为 Markdown 后,我们可以使用 LangChain 的 RecursiveCharacterTextSplitter 根据特定的 Markdown 语法进行分块。
LangChain 在 Language.MARKDOWN 中定义了这些默认分隔符:
separators = [
# First, try to split along Markdown headings (starting with level 2)
"\n#{1,6} ",
# End of code block
"```\n",
# Horizontal lines
"\n\\*\\*\\*+\n",
"\n---+\n",
"\n___+\n",
"\n\n",
"\n",
" ",
"",
]
使用 langchain_text_splitter,我们现在可以使用Markdown 特定的分隔符对我们的 Markdown 文件进行分块:
# pip install langchain-text-splitters==0.3.2
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_text_splitters.base import Language
text_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.MARKDOWN,
chunk_size=1000,
chunk_overlap=100,
)
documents = text_splitter.create_documents(texts=[docling_text])
print(documents[1].page_content)
在 https://langchain-text-splitter.streamlit.app 有一个 LangChain 各种文本分割器的在线演示,你可以尝试使用。
当我比较基本 PyPDF 输出上的 RecursiveCharacter 文本分割器与 Docling 输出上的 MARKDOWN 文本分割器时,Markdown 分割器明显更胜一筹。
向 Markdown 添加元数据
我们可以对 Markdown 文件做的另一件好事是添加 YAML front matter 元数据。
YAML front matter 必须放在文档的开头,所有元数据都包含在三个破折号之间。
以下是可以添加到我们文档中的 YAML front matter 示例:
---
title: document title
filename: document filename
tags: keyword1 keyword2 keyword3
description: summary of the document
---
我们可以从 PDF 文件中提取这些元数据(Docling 的元数据提取功能“即将推出”),或者我们可以使用 LLM 生成必要的元数据。
Anthropic 最近发布了他们称为上下文检索的想法,其中每个文档块都包含一个由 AI 生成的块上下文的简短摘要[3]。
同样,我们可以将 YAML front matter 元数据添加到每个块中。这将为 LLM 提供关于每个块的额外信息,并提高 RAG 检索性能。
让我们从 Docling documents 向每个块添加元数据:
metadata = """---
title: Docling Technical Report
filename: 2408.09869v3.pdf
description: This technical report introduces Docling, an easy to use, self-contained, MIT licensed open-source package for PDF document conversion.
---"""
for doc in documents:
doc.page_content = "\n".join([metadata, doc.page_content])
现在我们可以将这些块移动到向量数据库中。每个块都以 Markdown 格式精美呈现,并带有额外的元数据。
例如,看看 documents[19].page_content 中的表格有多漂亮。如果没有额外的元数据,表格块将孤立存在,没有任何上下文。
---
title: Docling Technical Report
filename: 2408.09869v3.pdf
description: This technical report introduces Docling, an easy to use, self-contained, MIT licensed open-source package for PDF document conversion.
---
| CPU | Thread budget | native backend | native backend | native backend | pypdfium backend | pypdfium backend | pypdfium backend |
|-----------------------|-----------------|------------------|------------------|------------------|--------------------|--------------------|--------------------|
| | Thread budget | TTS | Pages/s | Mem | TTS | Pages/s | Mem |
| Apple M3 Max | 4 | 177 s | 1.27 | 6.20 GB | 103 s | 2.18 | 2.56 GB |
| (16 cores) | 16 | 167 s | 1.34 | 6.20 GB | 92 s | 2.45 | 2.56 GB |
| Intel(R) Xeon E5-2690 | 4 16 | 375 s 244 s | 0.60 0.92 | 6.16 GB | 239 s 143 s | 0.94 1.57 | 2.42 GB |
总之,这是如何使用 Docling 为 RAG 准备 PDF 文件:
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_text_splitters.base import Language
from docling.document_converter import DocumentConverter
def process_file(filename: str, metadata: str = None):
"""read file, convert to markdown, split into chunks and optionally add metadata"""
# read file and export to markdown
converter = DocumentConverter()
result = converter.convert(filename)
docling_text = result.document.export_to_markdown()
# chunk document into smaller chunks
text_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.MARKDOWN,
chunk_size=1000,
chunk_overlap=100,
)
docling_documents = text_splitter.create_documents(texts=[docling_text])
if metadata:
for doc in docling_documents:
doc.page_content = "\n".join([metadata, doc.page_content])
return docling_documents
结论
在本文中,我比较了四个不同的用于读取 PDF 文件的 Python 库:PyPDF、http://unstructured.io、PyMuPDF4LLM 和 Docling。
前两个库生成纯文本输出,后两个库生成 Markdown。
通过使用 PyMuPDF4LLM 或 Docling 并将 PDF 转换为 Markdown,我们获得了更好的文本格式,减少了信息丢失,并获得了更好的表格解析。
使用 Markdown 语法,我们可以获得更好的文档分块,因为标题可以轻松指导分块过程。
使用 YAML 的 front matter 语法,我们可以向每个块添加额外的元数据。
Docling 在输出质量方面是明显的赢家。然而,Docling 的每个文档的处理时间也是最长的。
参考引用
[1] PyMuPDF (2024), RAG/LLM and PDF: Conversion to Markdown Text with PyMuPDF, Medium blog post from Apr. 10, 2024
[2] C. Auer et al. (2024), Docling Technical Report, arXiv:2408.09869, licensed under CC BY 4.0
[3] Anthropic (2024), Introducing Contextual Retrieval, Blog post from Sep. 19, 2024 on anthropic.com
[4] Unstructured Data Isn’t Just for Embeddings: Hidden Structure can Improve RAG







![[物联网iot]对比WIFI、MQTT、TCP、UDP通信协议](https://i-blog.csdnimg.cn/direct/cb73323f30824085b063cfb2f7f6f2c3.png)
![P4305 [JLOI2011] 不重复数字](https://i-blog.csdnimg.cn/direct/1e5a4ac616ea4152a1e897b50c9df629.png)