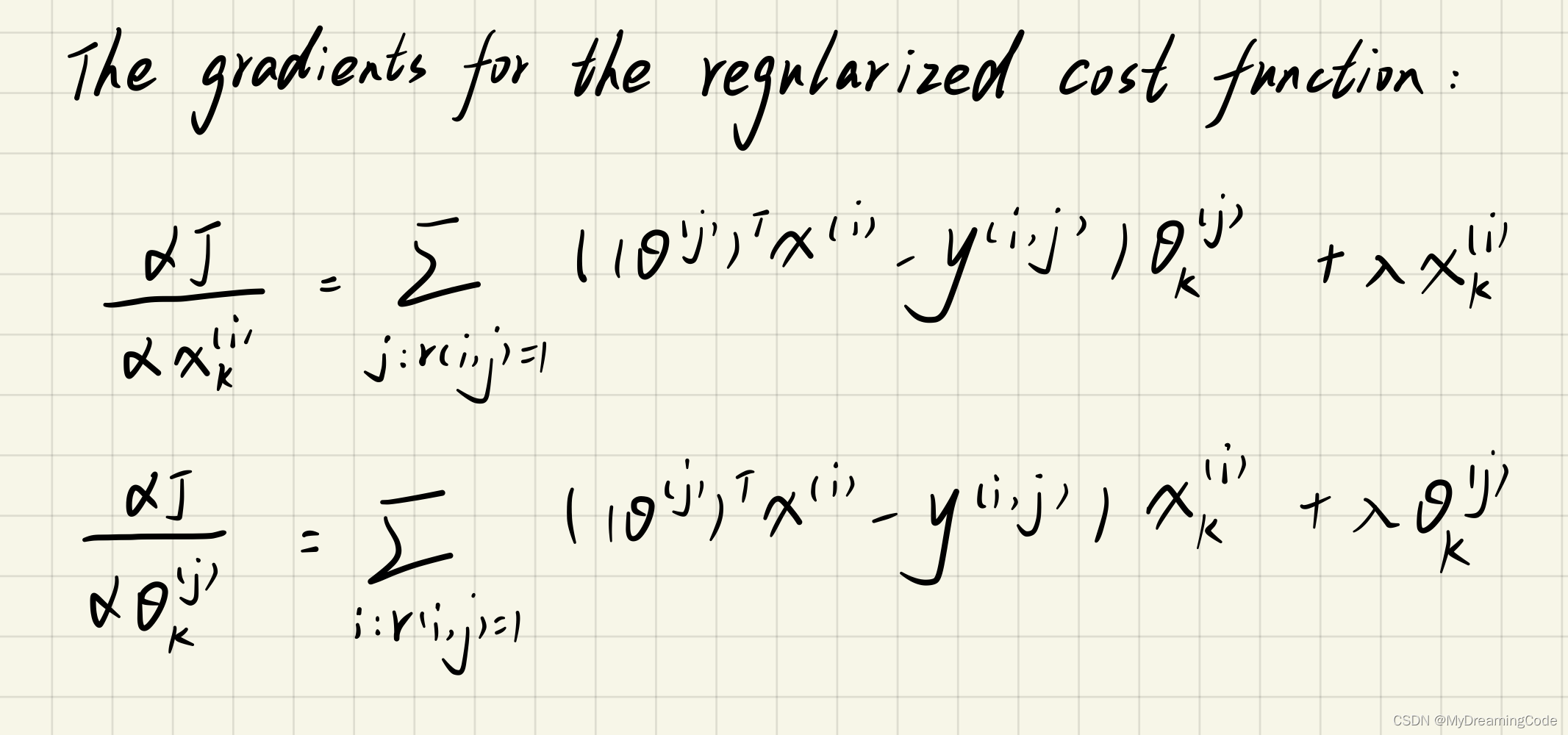1.CONFIDENCE ESTIMATION FOR ATTENTION-BASED SEQUENCE-TO-SEQUENCE MODELS FOR SPEECH RECOGNITION : https://arxiv.org/pdf/2010.11428.pdf
1.引言
1).置信度的目的:
在半监督学习和主动学习中,选择较高置信度的数据来进一步提高ASR性能;
利用较低的置信度分数进行筛选模糊的数据,然后通过人工确认来减少错误;
2).置信度的方法:
在传统的基于hmm的系统中,通过从假设compact空间中计算单词的后x验概率,可以很容易地获得可靠的置信分数,egs:lattice, confusion networks;
解释语音识别中的lattice与confusion network_lattice语音识别(https://blog.csdn.net/yutianzuijin/article/details/77621511),相比于lattice,我们可以很容易从混淆网络中获取one best结果,只需要从每一段中选择后验概率最大的边即可。混淆网络作为lattice的简化版,会引入原始lattice中不存在的路径。但是通常情况下,用混淆网络获取的one best结果要好于原始的one best。混淆网络还有一个好处,我们可以很容易获取每个时刻相互竞争的词有哪些。
基于神经网络构建置信度模型;
3).存在问题:
目前端到端模型语音识别模型成为主流,但在端到端语音识别中,在不使用特定解码器架构情况下,是不能生成像lattice一样的compact 空间;因此,在端到端假设空间中计算词后验变得非常复杂。一般简单的方法:使用贪婪近似将解码器每一步的softmax最大概率作为每个令牌的置信分数;但是,软最大概率估计置信度估计质量可能非常差。
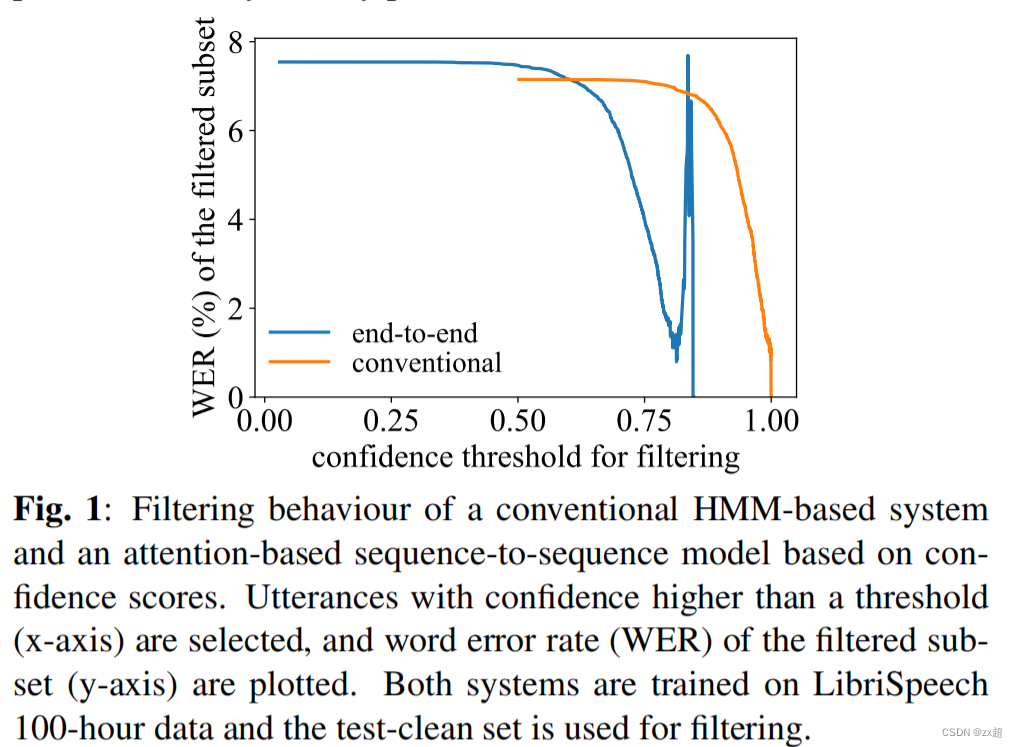
随着置信阈值的增加,常规系统的WER单调地减小。然而,对于端到端模型,较高的阈值(置信度)并不总是意味着WER的降低,可以看出模型是overconfident。
4).解决问题
针对模型过度自信问题,提出了基于注意的序列到序列模型的置信估计模块(CEM)
2.CEM模型介绍

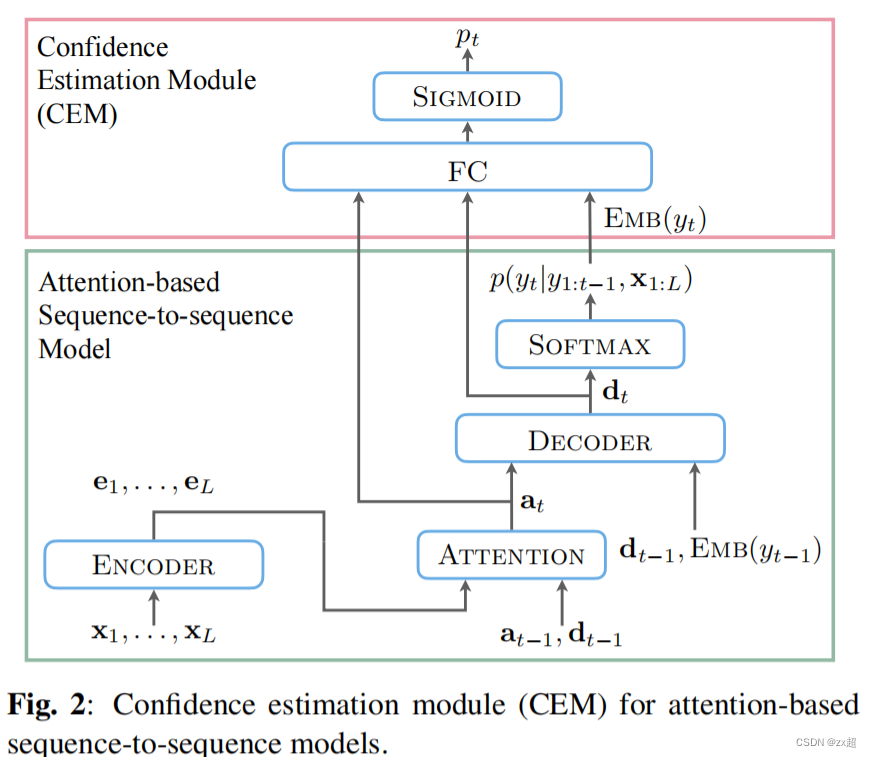

细化问题:
1.在token级别的上,asr的置信度分数被定义token正确的概率,如果识别器对输出token非常自信,那么相应的置信度分数应该接近于1。
2.Word或话语平均置信分数可以通过取一个单词或一个话语中的平均值来获得。
3.对于基于注意力的序列到序列模型,自回归解码器中的每一步都被视为对所有可能的输出token的分类任务。然而,在(softmax)标准化分类和序列置信度分数之间存在细微的差异。解码器的自回归性质和使用teacher-forece 方法进行训练,对具有错误历史的序列的校准行为是不确定的。此外,当模型为了追求最先优的性能而变得非常深和大时,模型可能会很难被纠正。
4.基于此提出了CEM模型,目的是让模型的softmax输出和增加一个FC层Pt输出,来共同决策句子级别的置信度。
5.训练过程:在有监督预训练过attention-asr model基础下,即固定asr模型参数,主要进行训练FC层。
6.loss计算:模型预测结果是Pt(置信度分数,范围0~1),然后通过Pt和Ct (0/1)计算二进制交叉熵。
3.CEM模型评估

(1)评估指标是NCE,主要与H(c)=-Σ c * log©, H(c, p)相关,H(c, p)< 0 和loss的计算方式是相同的;当置信度估计效果比单词正确率好时候,NCE为正。对于完美的分数,NCE是等于1。说明NCE主要用来衡量置信度得分与识别单词正确率的接近程度。

(2)但是,我们使用置信度时候,通常去设置一个阈值P~来进行筛选正确的和不正确的,因此制定了三个指标precision和recall,AUC。通常情况下,当阈值p˜增加时,假正例更少,假负例更多,这导致准确率更高,召回率更低。精确度和召回率之间的权衡行为产生了一条从左上角到右下角的向下趋势曲线。因此,曲线下面积(AUC)可以测量置信度估计量的质量,其最大值为1。值得注意的是,两个置信度估计模型可以有相同的AUC值,但NCE值不同。
3.2.数据:LibriSpeech数据集,测试集test-clean/test-other
4.实验
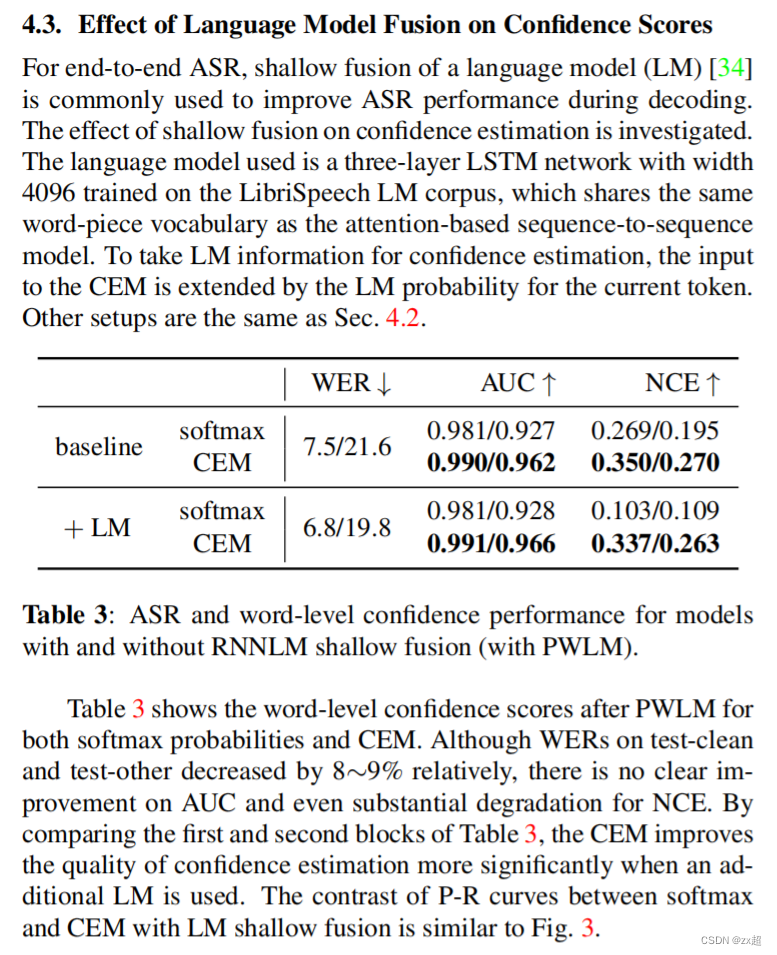
4.1 正则化方法对置信度得分的影响
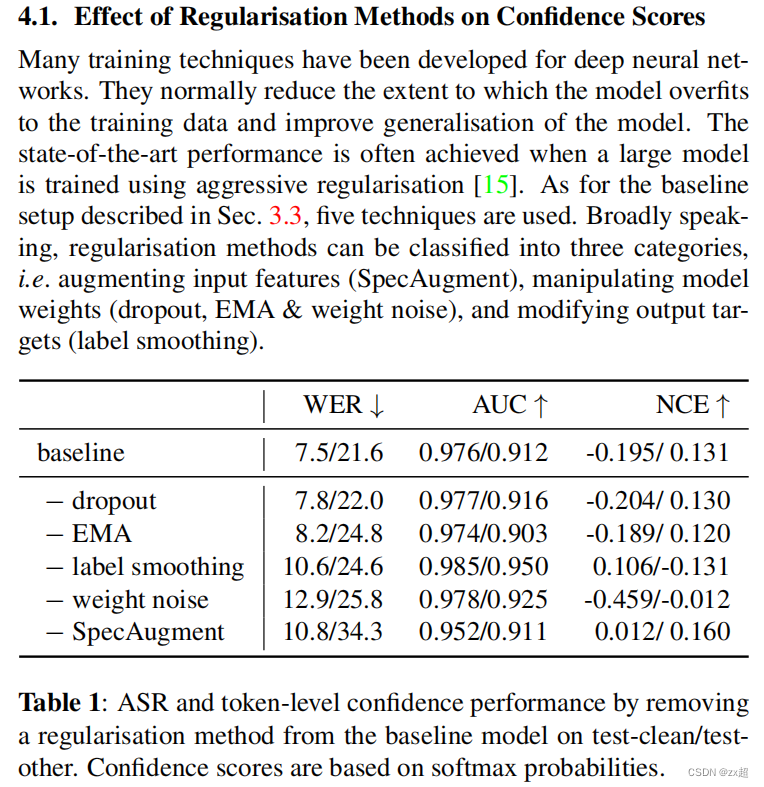
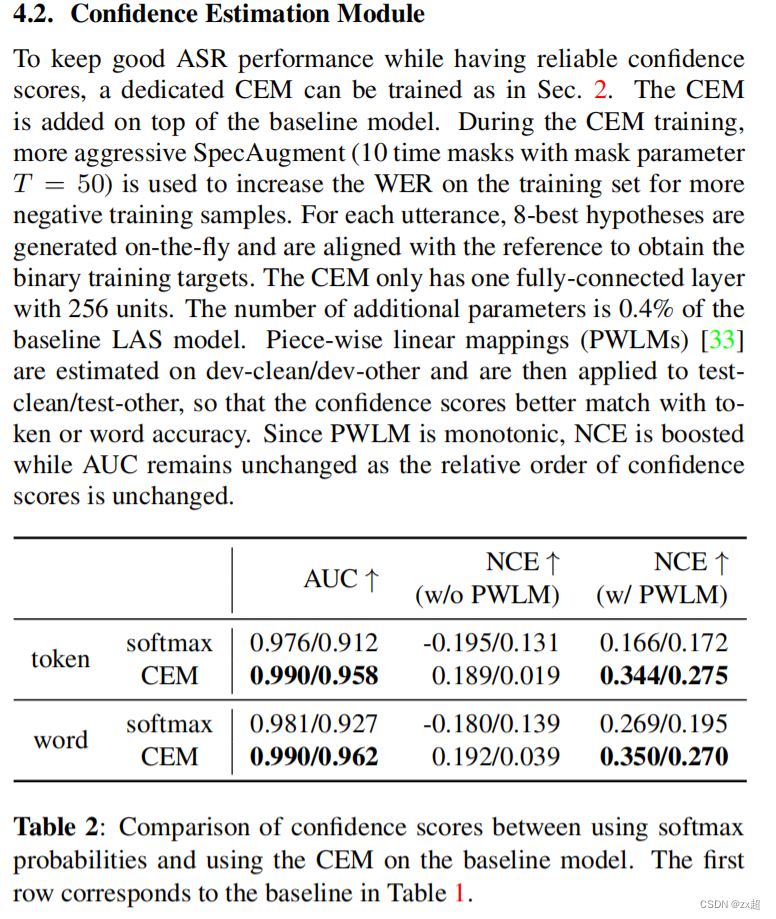
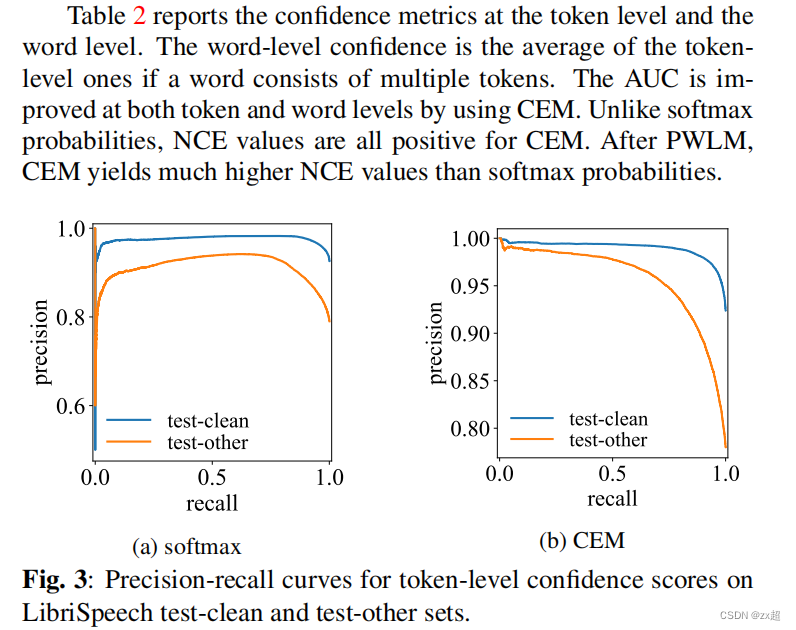
然而,AUC值并没有显示出【过度自信】这个情况。如图3所示,softmax和CEM的P-R曲线有很大差异。在图3(a)中,高置信区域急剧下降的峰值对应于低精度和低查全率。换句话说,对于一些不正确的标记,softmax概率是过度自信,这也解释了图1中所示的峰值。然而,CEM几乎没有过度自信的影响,图3(b)描述了精确度和召回率之间的权衡。总的来说,CEM在这两个指标下都是一个更可靠的置信度估计模型。