多目标检测思路
-
单目标检测:图片 输入到 模型,模型输出 4个值
-
为什么模型只能检测单个目标?
因为模型 固定输出4个值,表示 一个目标
- 如何实现多目标检测?思路:一个一个地数
-
模型要能够 认识目标(单目标检测)
-
设计一个算法,让模型 一个一个的找;不能重复 不能漏掉的方式去找目标
-
模型怎么处理这个问题?
- 模型不知道 人脸在什么地方,所以从左上角开始检测
- 抠出来的区域 输入到模型, 模型输出5个值,cls x1 y1 x2 y2 (cls有没有目标 置信度、 x1 y1左上、 x2 y2右下坐标)
-
- 我们通过设计一个 单目标检测网络
一个一个 去统计图像上的 目标区域
- 思考:我们如何实现多目标检测?
- 认识目标 (提取特征)
- 一个一个数 (单目标检测)(怎么数?从上到下,从左到右,把目标传进 单目标检测模型,模型输出5个值)
- 统计结果
图像金字塔 & NMS
思考:框的大小多大?框的步长多大?
-
一个框 把某块区域 截取出来
-
输入的框的 大小如何确定?
如何设计一个框,这个框可以包含所有尺寸的人脸
因为框的大小是固定 (因为单目标检测模型 输入的数据是固定尺寸的图片)
- 框的大小要定死
如果定小了,可能框不住目标
如果定大了,可能漏掉目标 (一个框框住了两个目标,就漏掉了一个目标,应该一个框对应一个目标)
但又必须要 固定框的尺寸
框不能动,那就动图片
图像金字塔
-
图像金字塔
图片每缩小一次,这个固定大小的框都是 从左到右,从上到下,去扫描图片
- 图像金字塔
- 做 多目标检测 时候,利用 框在原图上 不断的滑动 去检测人脸,框的大小是 固定的。框的大小是 12*12,(正方形,人脸这个目标 刚好接近于正方形)
- 没法检测 大一点的人脸,因此引入了 图像金字塔 的概念
- 不断的 缩小图片 以适应 框的大小,当下一次图片的 最小边长 小于或等于 框的大小时,图片就 停止缩放

使用图像金字塔,每次框的目标的个数,最多只有一个目标,或者没有目标

-
框的步长为多大?
- 框的步长大了,会丢脸
- 把步长调小,步长2个像素
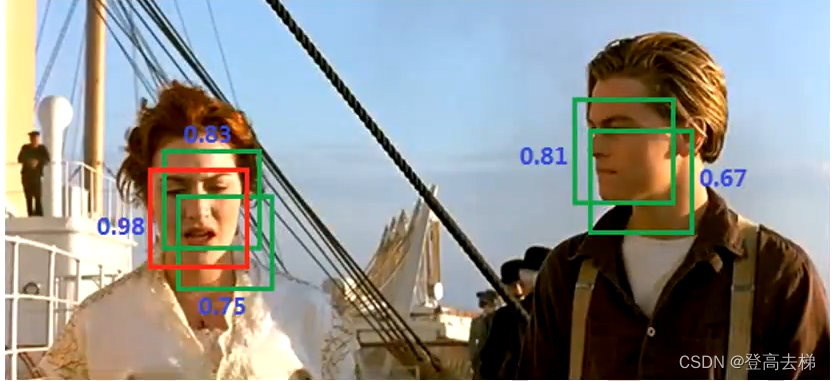
步长调小了, 可能检测到目标,但会重复检测目标 - 去重,选出最好的框, 非极大值抑制 (NMS)
非极大值抑制 (NMS) 思路
- 非极大值抑制 (NMS) 思路:
- 对置信度进行排序,先保留置信度 最大的框,移动到新的集合
- 置信度 最大的框 和剩余4个框 求交并比(iou),有4个iou值,和阈值 作比较,大于阈值时,就删除 (阈值是重合度,自定义值,一般偏大的值,比如 0.6)
- 再对剩下的框,又进行排序,又保留 置信度最大的框,再求iou,再删除 大于阈值的框
- 直到原集合数据为空



IOU & NMS代码实现
utils.py
"""
计算交并比
rec1 是第1个矩形的 x1,y1,x2,y2
rec2 是第2个矩形的 x1,y1,x2,y2
得到最大的 x1,y1 -> interX1,interY1
得到最小的 x2,y2 -> interX2,interY2
交集矩形宽 w = max(0,interX2-interX1)
交集矩形高 h = max(0,interY2 - interX2)
交集面积 interArea = w * h
并集面积 twoArew = 两个矩形面积和
交并比 = 交集面积 / (并集面积 - 交集面积)
"""
import numpy as np
def iou(rec1, rec2):
# x1 y1 x2 y2
# 0 1 2 3
interX1, interY1 = np.maximum(rec1[0:2], rec2[0:2])
interX2, interY2 = np.minimum(rec1[2:4], rec2[2:4])
w = max(0, interX2 - interX1)
h = max(0, interY2 - interY1)
interArea = w * h
area1 = (rec1[2] - rec1[0]) * (rec1[3] - rec1[1])
area2 = (rec2[2] - rec2[0]) * (rec2[3] - rec2[1])
twoArew = area1 + area2
return interArea / (twoArew - interArea)
"""
计算某个box,与其它多个box分别求iou
box 的坐标(x1,y1,x2,y2)
boxes
[
[x1,y1,x2,y2],
[x1,y1,x2,y2],
[x1,y1,x2,y2],
[x1,y1,x2,y2],
]
"""
def iou2(box,boxes):
# box = [0 0 4 4]
# 求框的面积
box_area = (box[2] - box[0]) * (box[3] - box[1])
"""
boxes =
[
[6,6,7,7]
[1,1,5,5]
]
# [ 1 16]
"""
boxes_area = (boxes[:,2] - boxes[:,0]) * (boxes[:,3] - boxes[:,1]) # [ 1 16]
# 求交集的面积
xx1 = np.maximum(box[0],boxes[:,0]) # np.maximum(5,[1,2,5,6,8]) -> [5, 5, 5, 6, 8]
yy1 = np.maximum(box[1],boxes[:,1])
xx2 = np.minimum(box[2],boxes[:,2])
yy2 = np.minimum(box[3],boxes[:,3])
w = np.maximum(0,xx2 - xx1)
h = np.maximum(0,yy2 - yy1)
inv = w * h
iou = inv / (box_area+boxes_area - inv)
return iou
"""
非极大值抑制
boxes 框
thresh 阈值
boxes.shape[n,5]
"""
def nms(boxes,thresh=0.3):
# 先对boxes 的置信度进行排序
# argsort 按照从小到大进行排序,并按照对应的索引值输出
new_index = np.argsort(-boxes[:,0]) # 得到排序的索引 负号表示倒序 # np.argsort([3,4,1,6,2]) -> array([2, 4, 0, 1, 3])
new_boxes = boxes[new_index]
# 最终输出所有的框
boxes_result = []
while len(new_boxes)>1:
box = new_boxes[0]
# 直接将置信度最大的box加入结果中
boxes_result.append(box)
new_boxes = new_boxes[1:]
# 置信度最大的框和其他框分别求iou
iou = iou2(box[1:],new_boxes[:,1:])
# 取出和第一个box的iou小于阈值的框
box_index = np.where(iou<thresh)
new_boxes = new_boxes[box_index]
if len(new_boxes) > 0:
boxes_result.append(new_boxes[0])
return boxes_result
if __name__ == '__main__':
# 测试 iou2
# box = np.array([0,0,4,4])
# boxes = np.array([[6,6,7,7],[1,1,5,5]])
#
# iou = iou2(box,boxes)
# print(iou)
# 测试 nms
boxes = np.array([
[0.2, 1,2,4,4],
[0.9, 8,8,9,9],
[0.7, 1,1,4,4]
])
boxes = nms(boxes)
print(boxes)
MTCNN网络结构介绍
级联: 把一个复杂的问题, 拆多个步骤
好处:高效
P网络 R网络 O网络结构图
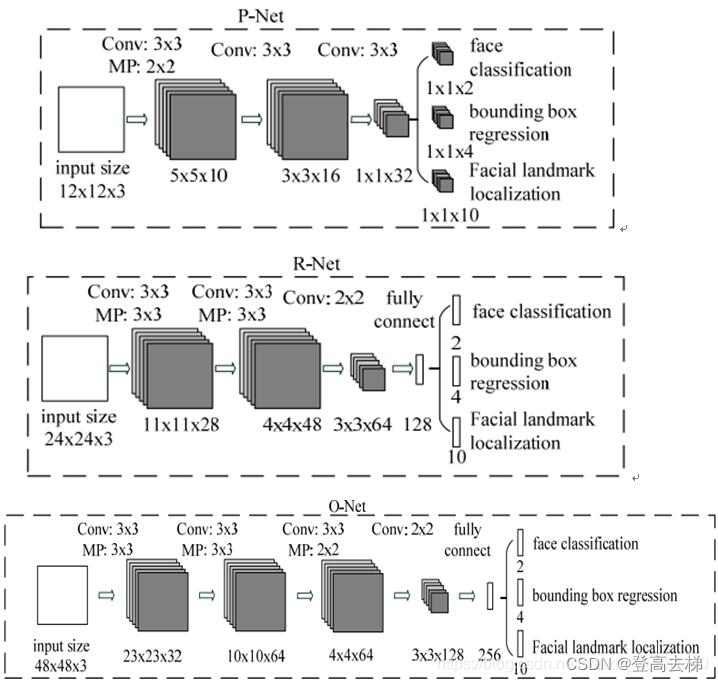
- p网络数据量是最大
- 图像金字塔相当于把一张图片变成了很多张图片
- 网络越浅,网络越小,速度越快
- p网络是 卷积层 作为输出层;r网络和o网络是 全连接层作为输出层;
- p r o 网络 分别是 3 4 5 层网络
- 输出2 表示 有无目标的概率;输出4 表示框的左上 右下坐标值;输出10 表示5个关键点 坐标
mtcnn 代码
PNet.py
import torch
import torch.nn as nn
class PNet(nn.Module):
def __init__(self):
super(PNet, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3,out_channels=10,kernel_size=3,stride=1)
self.prelu1 = nn.PReLU()
self.pool1 = nn.MaxPool2d(kernel_size=2,stride=2,ceil_mode=True) # ceil_mode :计算输出形状,布尔类型,为True,用向上取整的方法;默认是向下取整。
self.conv2 = nn.Conv2d(in_channels=10,out_channels=16,kernel_size=3)
self.prelu2 = nn.PReLU()
self.conv3 = nn.Conv2d(in_channels=16,out_channels=32,kernel_size=3)
self.prelu3 = nn.PReLU()
# 三个输出层;分别是 置信值,框的左上 右下 坐标 ,五个关键点坐标
self.outConv1 = nn.Conv2d(32,2,kernel_size=1)
self.outConv2 = nn.Conv2d(32,4,kernel_size=1)
self.outConv3 = nn.Conv2d(32,10,kernel_size=1)
# todo
for m in self.modules():
print(f"m的值:{m}")
if isinstance(m,nn.Conv2d):
nn.init.kaiming_normal(m.weight,mode='fan_out', nonlinearity="relu")
def forward(self, x):
# 三层卷积
x = self.pool1(self.prelu1(self.conv1(x))) # 有池化
x = self.prelu2(self.conv2(x))
x = self.prelu3(self.conv3)
"""
torch.squeeze
不指定维度时,删除所有大小为1的维度
指定维度的大小为1,删除指定维度
指定的维度大小不为1,不做任何改变
"""
# 分类是否人脸的卷积输出层
class_out = self.outConv1(x)
class_out = torch.squeeze(class_out, dim=2) # todo debug
class_out = torch.squeeze(class_out, dim=2)
# 人脸box的回归卷积输出层
bbox_out = self.outConv2(x)
bbox_out = torch.squeeze(bbox_out, dim=2)
bbox_out = torch.squeeze(bbox_out, dim=2)
# 5个关键点的回归卷积输出层
landmark_out = self.outConv3(x)
landmark_out = torch.squeeze(landmark_out, dim=2)
landmark_out = torch.squeeze(landmark_out, dim=2)
return class_out, bbox_out, landmark_out
RNet.py
import torch
import torch.nn as nn
class RNet(nn.Module):
def __init__(self):
super(RNet, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=28,kernel_size=3),nn.PReLU(),
nn.MaxPool2d(kernel_size=3,stride=2)
)
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels=28,out_channels=48,kernel_size=3),nn.PReLU(),
nn.MaxPool2d(kernel_size=3,stride=2)
)
self.conv3 = nn.Sequential(
nn.Conv2d(in_channels=48,out_channels=64,kernel_size=2),nn.PReLU(),
)
self.flatten = nn.Flatten() # 展平
# 全连接层
self.fc = nn.Linear(in_features=576, out_features=128)
# 三个输出层
self.class_fc = nn.Linear(in_features=128, out_features=2)
self.bbox_fc = nn.Linear(in_features=128, out_features=4)
self.landmark_fc = nn.Linear(in_features=128, out_features=10)
for m in self.modules():
print(f"m的值:{m}")
if isinstance(m,nn.Conv2d):
nn.init.kaiming_normal(m.weight,mode='fan_out', nonlinearity="relu")
def forward(self, x):
# 三层卷积 一层全连接
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
# 展平
x = self.flatten(x)
x = self.fc(x)
# 分类是否人脸的全连接输出层
class_out = self.class_fc(x)
# 人脸box的回归全连接输出层
bbox_out = self.bbox_fc(x)
# 5个关键点的回归全连接输出层
landmark_out = self.landmark_fc(x)
return class_out, bbox_out, landmark_out
pass
ONet.py
import torch
import torch.nn as nn
class ONet(nn.Module):
def __init__(self):
super(ONet, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3,32,3),nn.PReLU(),
nn.MaxPool2d(3,2,ceil_mode=True)
)
self.conv2 = nn.Sequential(
nn.Conv2d(32, 64, 3), nn.PReLU(),
nn.MaxPool2d(3,2,ceil_mode=True)
)
self.conv3 = nn.Sequential(
nn.Conv2d(64,64,3),nn.PReLU(),
nn.MaxPool2d(2,2,ceil_mode=True)
)
self.conv4 = nn.Sequential(
nn.Conv2d(64, 128, 2),nn.PReLU()
)
self.flatten = nn.Flatten() # 展平
# 全连接层
self.fc = nn.Linear(in_features=1152, out_features=256)
# 三个输出层
self.class_fc = nn.Linear(256, 2)
self.bbox_fc = nn.Linear(256, 4)
self.landmark_fc = nn.Linear(256, 10)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.flatten(x)
x = self.fc(x)
# 分类是否人脸的 全连接输出层
class_out = self.class_fc(x)
# 人脸box的回归 全连接输出层
bbox_out = self.bbox_fc(x)
# 5个关键点的回归 全连接输出层
landmark_out = self.landmark_fc(x)
return class_out, bbox_out, landmark_out