2023 年 4 月,StarRocks 3.0 版本正式发布,正式开启了 StarRocks 极速统一的新篇章。从 OLAP 到 Lakehouse,从存算一体到存算分离,从 ETL 到 ELT,经过两个大版本后 StarRocks 在为用户创造极速统一的数据分析新范式上有了更深一层的思考。
本文主要从存算分离架构、极速数据湖分析和数据应用三个大方向全面解读 StarRocks 3.0 版本。最后,我们会对 3.x 后续的规划做一个分享。
StarRocks 社区发展
自2021年9月正式开源以来,StarRocks 社区一直保持着快速迭代的节奏。目前,StarRocks 在 GitHub 上已获得了4300+个 star,超过200名贡献者提交了15000+个 PR,并且有上万人通过 GitHub、微信社群、论坛等方式参与社区建设。同时,超过两百家10亿美金估值的大型企业在线上业务使用 StarRocks 。

在过去的两年时间,StarRocks 完成了 1.x、2.x 大版本的迭代。
-
在 1.x 系列版本,StarRocks 主打极速 OLAP 分析,通过 CBO、向量化引擎、Runtime Filer 等技术做到性能业界领先。
-
在 2.x 系列版本,StarRocks 支持主键模型提升实时分析场景的能力、支持 Pipeline、Query Cache 来提升高并发场景的查询能力,支持极速数据湖分析简化湖上数据分析,帮助用户实现极速统一的湖仓分析。
StarRocks 3.0 简介

3.0 是 StarRocks 的一个里程碑式的大版本,实现了从计算 OLAP 分析到统一 Lakehouse 的重大产品能力升级。数据可以批量或者流式的写入到 StarRocks 进行极速分析,也可以在数据湖上直接使用 StarRocks 分析加速,并通过一系列技术加强湖仓融合,实现 Lakehouse 一体化。
数据仓库 vs. 数据湖

StarRocks 要成为一个 Lakehouse,核心就是要同时具备数仓和数据湖的各项优势。
数据仓库核心优势主要包含:数据质量高(进到数仓的数据都是经过 ETL 处理)、查询性能高、具备实时分析的能力、数据治理功能完善等。而数据湖的核心优势则在于开放的生态(数据湖通常采用开放的存储格式)、支持存储各种类型的数据、作为统一存储确保 single source of truth、扩展性强且存储成本低。
StarRocks 3.0 版本主要升级了存算分离架构,以提高系统的可扩展性和降低成本。此外,该版本还引入了湖仓融合的概念,旨在为用户提供一站式的 Lakehouse 产品能力。
存算分离
从 shared-nothing 到 shared-data
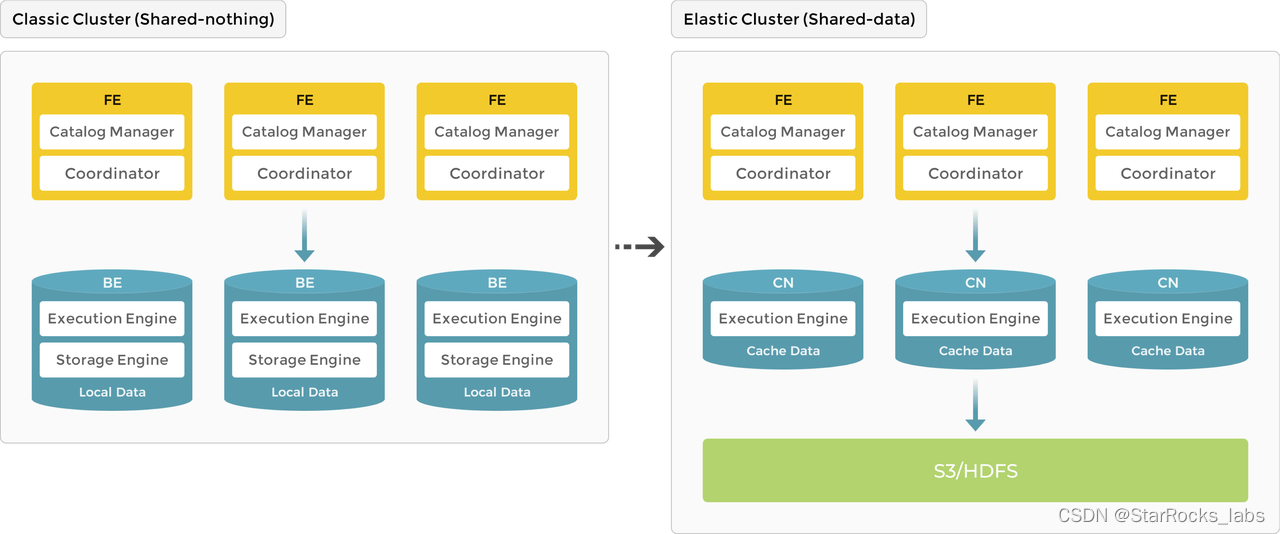
在存算一体(shared-nothing) 的架构里,StarRocks 由 FE、BE 组成,FE 负责元数据管理,执行计划构建;BE 负责实际执行以及数据存储管理,BE 采用本地存储,通过多副本的机制保证高可用。
StarRocks 3.0 提供了存算分离的架构,BE 节点升级为无状态的 Compute Node(CN) 节点,数据存储从本地存储升级为共享存储,例如采用 S3 或者 HDFS 来存储数据。
存算分离架构
存算分离架构的核心价值在于:
-
存储采用 S3 等更低成本的共享存储,计算存储独立扩展,降低整体的成本
-
针对计算和存储系统分别进行独立设计和优化,提升数据的可靠性,服务可用性
-
计算节点无状态,增强系统弹性扩展的能力
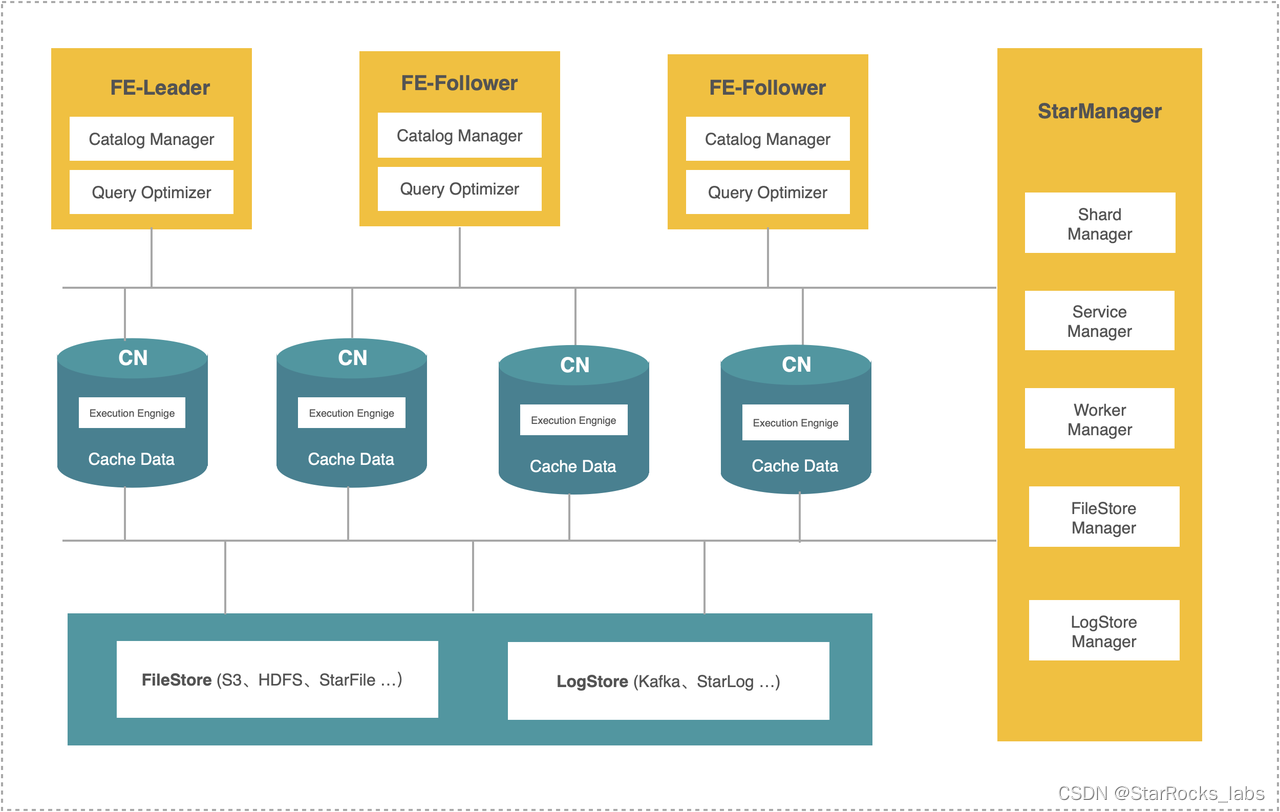 StarRocks 的存算分离架构的特色在于基于 StarOS 抽象层构建,具备很强的扩展性,能同时支持 Cloud、On-premise 的部署模式;StarOS 封装了包括 Shard 调度、Log/File 对象的管理能力,让上层应用能更加简单的构建云原生分布式的能力。
StarRocks 的存算分离架构的特色在于基于 StarOS 抽象层构建,具备很强的扩展性,能同时支持 Cloud、On-premise 的部署模式;StarOS 封装了包括 Shard 调度、Log/File 对象的管理能力,让上层应用能更加简单的构建云原生分布式的能力。
存算分离价值
存算分离架构下,StarRocks 的存储从三副本的 EBS(或本地盘)存储,降低为一副本的 S3 对象存储;同时 EBS 的成本一般为 S3 的 4-10 倍,综合计算升级到存算分离架构,存储成本可以下降 90%。
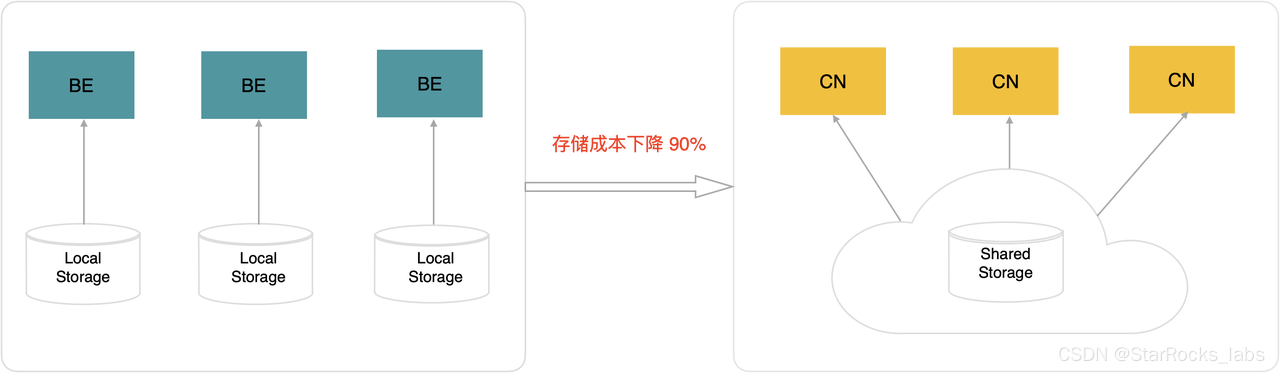
存算分离后,计算和存储系统可以分别根据各自的需求进行针对性的优化。通常,存储采用 S3 对象存储,可以提供 99.999999999%的数据可靠性;而计算节点则因为无状态,可以通过快速弹性、跨可用区部署等方式来提高计算的可用性。
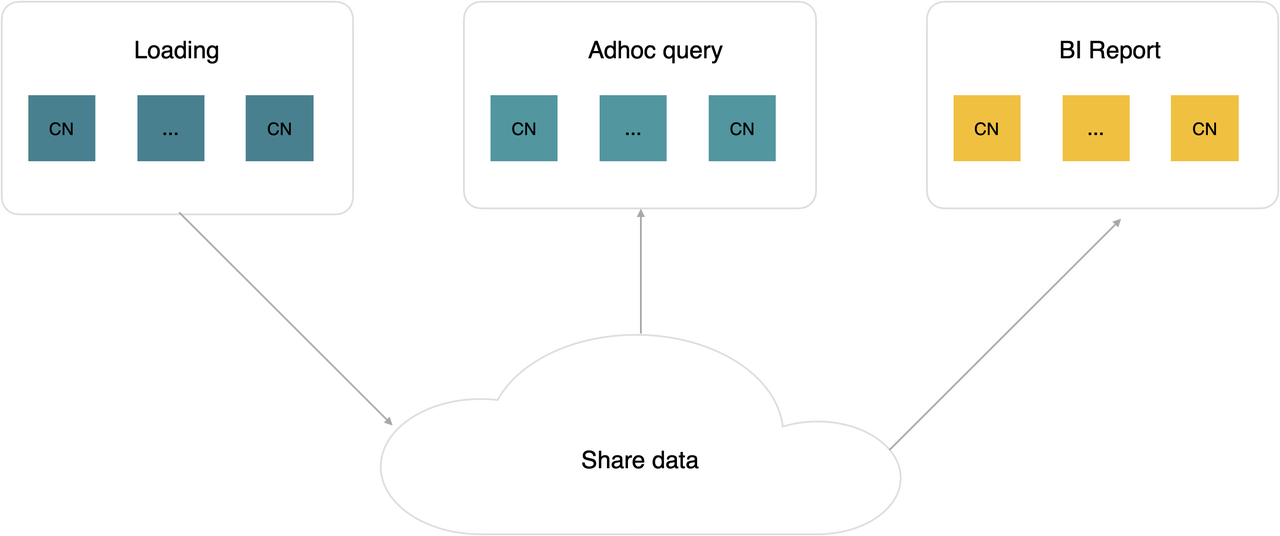
另外,在存算分离架构下,StarRocks 可以方便的支持 Multi-warehouse 的能力;多个 Warehouse 共享一份数据,不同 Warehouse 应用在不同的 Workload,计算资源可以进行物理隔离,并且可以按需独立弹性伸缩。
存算分离性能
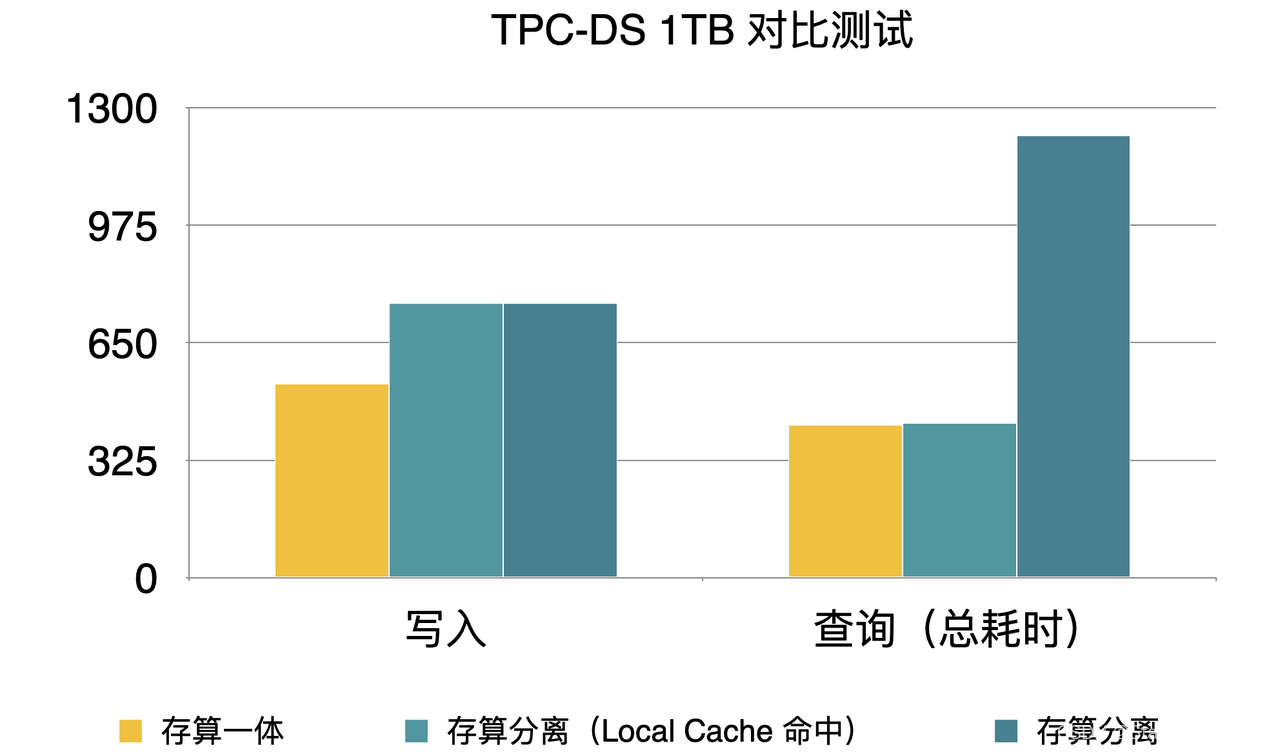
存算分离架构能带来很多好处,但因为访问远端存储比访问本地存储的延时要高很多,通常会带来一些性能的损失。可以通过 Cache 来加速热数据的查询,做到接近本地存储的效果。以 TPC-DS 1TB 的数据集为例:
-
导入的延时相比存算一体增加 30%
-
查询的总耗时是存算一体的 3 倍;开启 local cache 命中的情况下与存算一体性能持平
湖仓融合
极速统一的湖仓新范式
StarRocks 3.0 另外一个重要的能力升级就是湖仓融合一体化的能力,用户可以选择多种分析范式来简化数据分析。数据可以直接入仓分析,也可以写入数据湖后由 StarRocks 直接分析湖上数据,无需做数据迁移;通过物化视图的能力,可以将湖上的数据写入到数仓里加速查询,数仓的计算结果可以再写回数据湖,实现湖仓的无缝融合。
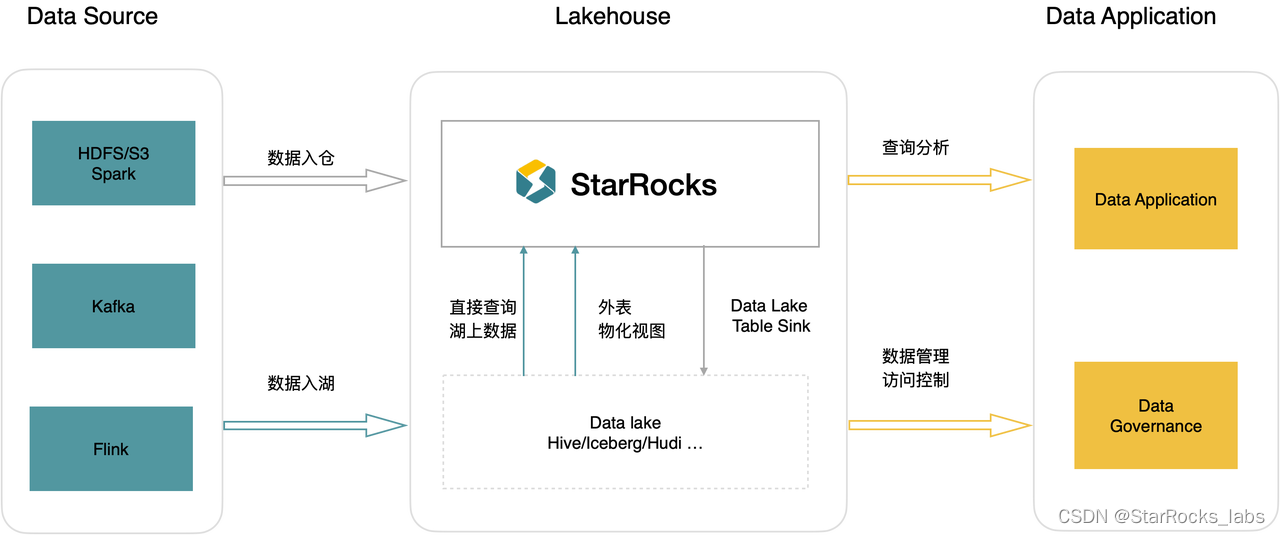
统一 Catalog 管理
为了更简单地直接分析开放数据湖上的数据,StarRocks 提供了统一 Catalog 管理的能力,用户可以通过一键创建 Apache Hive/Apache Hudi/Apache Iceberg(以下简称 Hive/Hudi/Iceberg) 的 Catalog,轻松地分析湖上的所有数据,而无需逐个表进行 schema 建模。此外,通过统一的 Catalog,StarRocks 可以实现对湖上数据的统一管理。
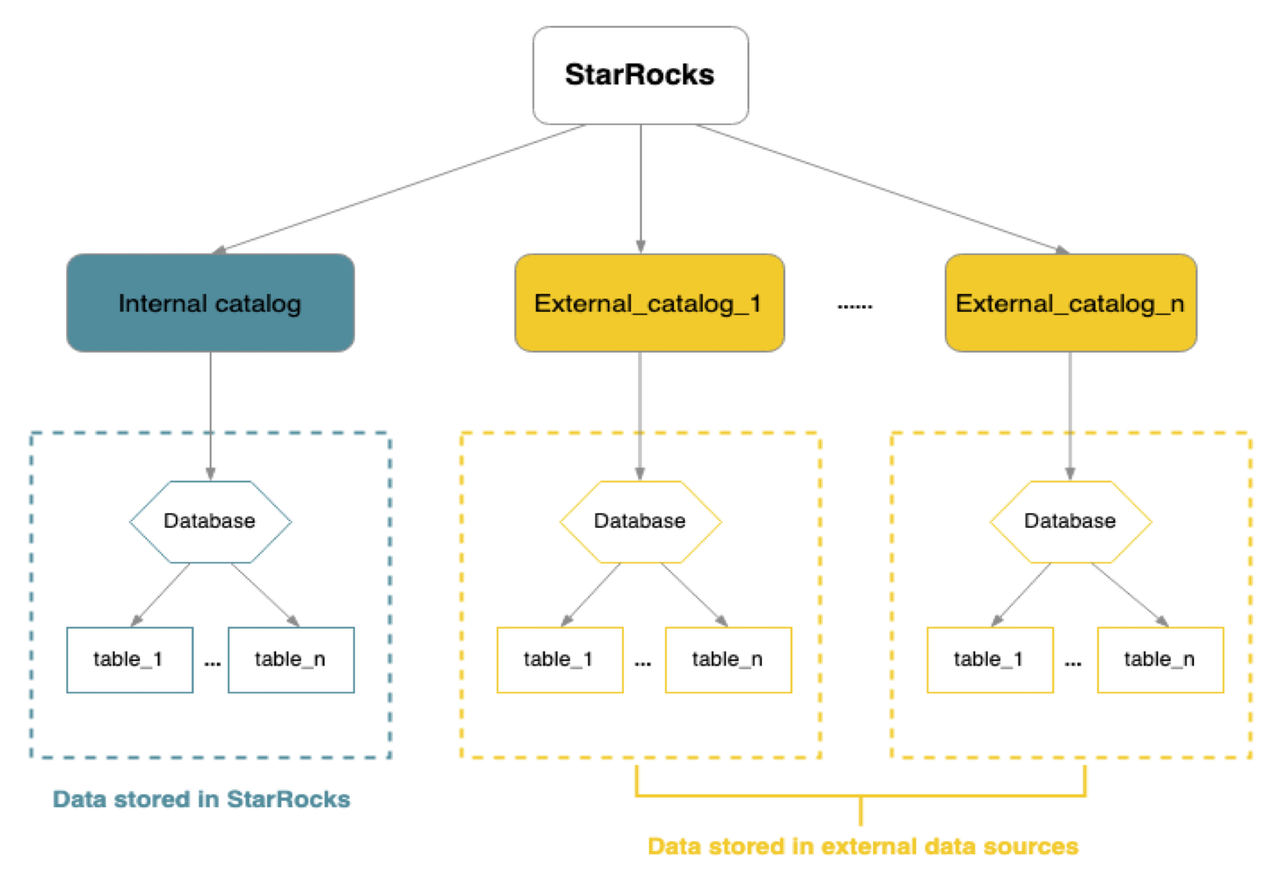
极速数据湖分析
湖上数据分析的主要挑战在于:
-
未经优化的数据组织,例如文件小、row group、column 大小设置不合理等
-
I/O 延迟高,无法利用 page cache 加速访问
StarRocks 通过下面一系列的关键技术来加速湖上数据分析性能:
-
CBO、向量化引擎、Runtime Filter 等一系列查询层的技术都可以应用到湖上数据分析
-
I/O 合并,减少 I/O 次数:StarRocks 实现 Column 读取合并、row group 读取合并、小文件读取合并等多级 I/O 合并机制,提升访问湖上数据的效率,降低 I/O
-
延迟物化,根据带查询条件的部分列过滤结果,再读取其他需要访问的列,减少 I/O 总量
-
Local cache 降低 I/O 延迟,延迟达到访问本地存储的水平
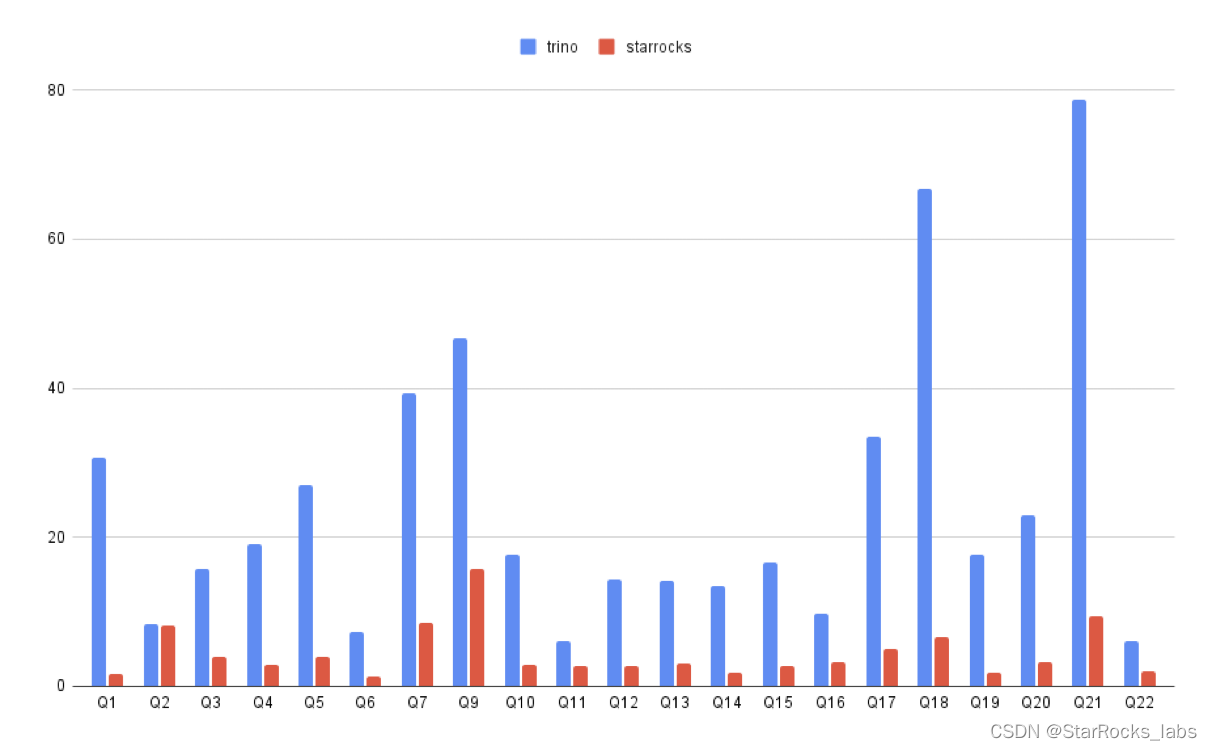
通过上面一系列技术,StarRocks 直接分析数据比 Trino 平均快 3-5 倍,大幅提升整体的性价比。为了让用户能更方便的从 Trino 到 StarRocks 升级,降低其分析成本,StarRocks 提供了 Trino SQL 语法兼容的能力(3.0 为预览版功能),将 Trino SQL 自动改写成 StarRocks 的 AST,充分利用 StarRocks 的高性能执行引擎。
开放 Lakehouse 架构
StarRocks 具备存算分离和数据湖分析能力之后,StarRocks 本身已经形成了一个分层结构的 Lakehouse 的架构。
-
存储层,统一采用 S3、HDFS 等共享存储系统
-
在 File format 层,数据湖采用 Parquet、ORC 等开放格式,StarRocks 则有对应的 Segment 文件格式
-
在 Table format 层,数据湖有 Hudi、Iceberge 的组织格式,对应 StarRocks Table 的组织
-
在 Catalog 层,数据湖采用 HMS,StarRocks 采用 FE 来统一管理元数据
-
在计算层,数据湖采用开源的 Spark、Flink 等组件,而 StarRocks CN 节点提供统一的计算
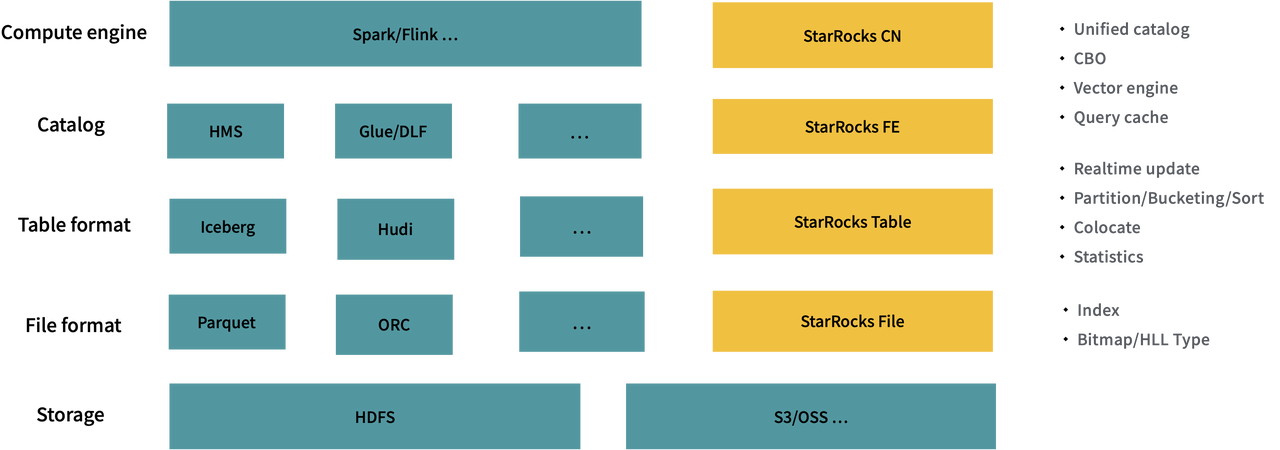
虽然架构理念一致,但 StarRocks 相比数据湖在数据格式访问优化,数据更新的能力上提供了更好的支持。
-
StarRocks Segment 文件支持 Bloomfilter、Bitmap 等各种索引来加速查询
-
StarRocks Table 支持通过分区、分桶、排序、colocate 等策略优化数据组织,并提供实时更新的能力
-
StarRocks CN 通过 CBO、向量化、Query Cache 等技术来提升查询性能
物化视图连接湖仓
借助 StarRocks 的开放 Lakehouse 架构,将数据写入 StarRocks 可以提供比在数据湖上更出色的查询性能。同时,为了更好地连接湖仓数据,StarRocks 支持通过物化视图简化数据的 ETL,简化湖仓分层建模。例如,在业务上可以将数据湖作为 ODS 层,并通过建立物化视图将数据加速的数据直接存储在 StarRocks 内部。然后,进一步使用物化视图对数据进行加工处理,形成 DWS、ADS 层的数据,以便不同层级的数据为不同的应用程序提供查询服务。

StarRocks 物化视图的核心价值在于简化湖仓建模,并利用物化视图实现查询加速。StarRocks 3.0 已经支持了比较完备的物化视图能力:
-
在物化视图的构建上,支持所有复杂查询,支持基于外部 Catalog 建物化视图以及嵌套物化视图。同时,物化视图可以当一张普通的表进行查询管理。
-
在物化视图刷新方面,采用异步刷新方式,支持周期性或修改触发式的刷新模式,并支持细粒度的刷新控制,以尽量减小物化视图的维护代价。
-
在查询改写上,Scan、Filter、Aggregation、Join、Union 等都支持利用物化视图来自动改写查询加速。
开放数据湖构建
StarRocks 除了支持通过物化视图将湖上数据写入 StarRocks 内部存储进行加速,在后续的 3.x 版本中还会提供直接构建数据湖的能力。通过 StarRocks 写入的数据可以直接存储为 Iceberg 等开放数据湖格式。这个能力使得热数据可以存储在 StarRocks 中,提供实时 OLAP 查询服务;而冷数据则可以归档到数据湖中进行管理,并通过 StarRocks 提供的统一查询入口进行查询。
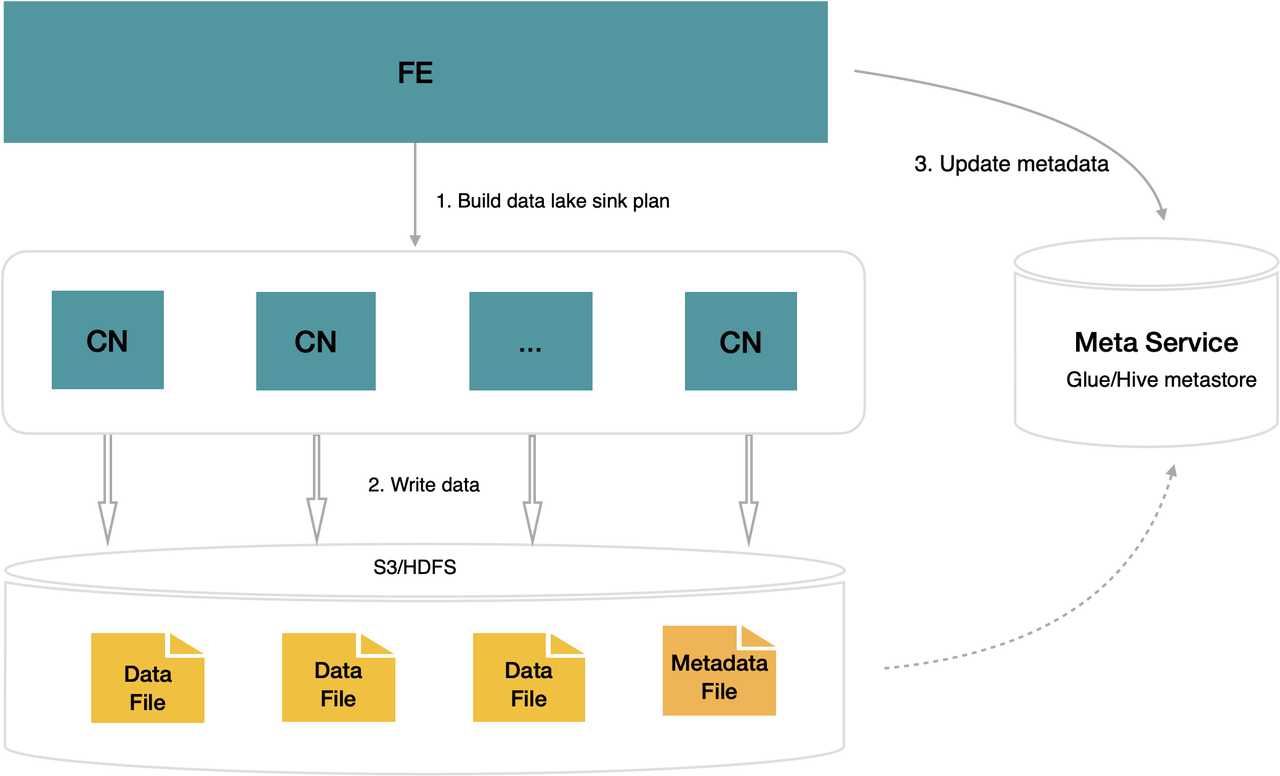
一站式云原生湖仓
StarRocks 在支持一系列湖仓融合的能力之后,结合存算分离架构,具备湖仓一体化的能力。用户可以直接将 StarRocks 作为一个 Lakehouse 使用,兼具数据仓库与数据湖的优势:
-
无需维护两套独立的数据仓库与数据湖系统
-
支持灵活的存储格式,采用开放存储格式或者 StarRocks 针对实时分析优化的存储格式
-
采用计算存储分离架构,实现 Workload 资源隔离,提供独立按需弹性
-
通过 local cache 机制,实现冷热数据的自动管理

数据应用
除了提供一站式湖仓能力,StarRocks 在数据管理、写入、查询等方面做了很多提升,目标是让用户构建数据应用更安全、更简单、更高效。
Role Based Access Control
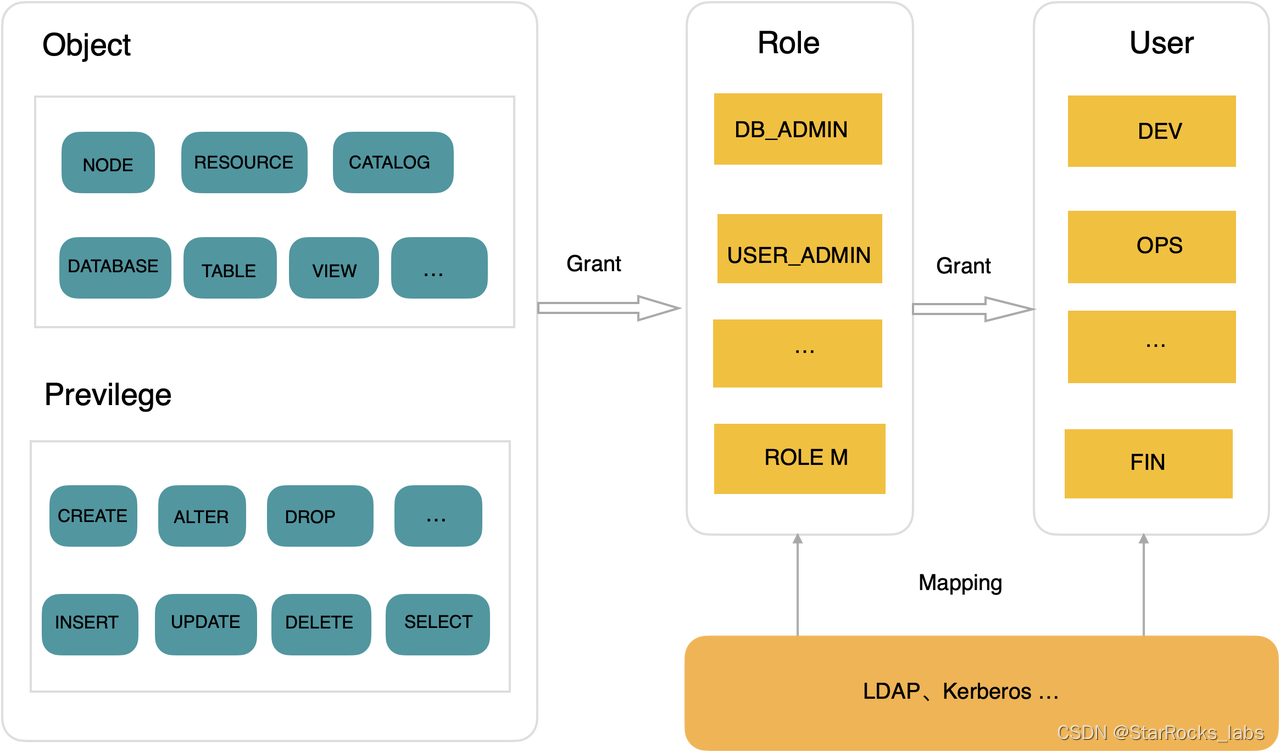
数据进入到 StarRocks,首先要解决的就是数据访问权限管理的问题。StarRocks 在 2.x 提供了简单的权限管理机制,在 3.0 版本,StarRocks 推出全新的 Role Based Access Control(RBAC) 权限机制。
RBAC 简化了权限的授权、变更、回收等。RBAC 支持细粒度权限控制,定义了 40+ 对象,10+ 操作类型,用于灵活定义 Role,比如数据湖上的表和 StarRocks 内表可以通过 Catalog 对象进行统一的权限管理。同时为了简化管理操作,系统内置一些常见的 Role,比如 DB_ADMIN、USER_ADMIN 等。
RBAC 采用最小权限原则,当用户拥有多个 Role 时,支持设置默认的 Role,也可以在不同的 Session 里设置使用不同的 Role,避免权限误用,提升安全性。
优化数据分布策略简化建表
StarRocks 的表会根据分区(PARTITION BY)键,切分为多个分区,每个分区会根据分桶(DISTRIBUTED BY)键,再切成多个分桶以利用 MPP 的能力。在过去我们遇到的主要问题是分区策略表达比较复杂以及分桶数量难以合理设置。
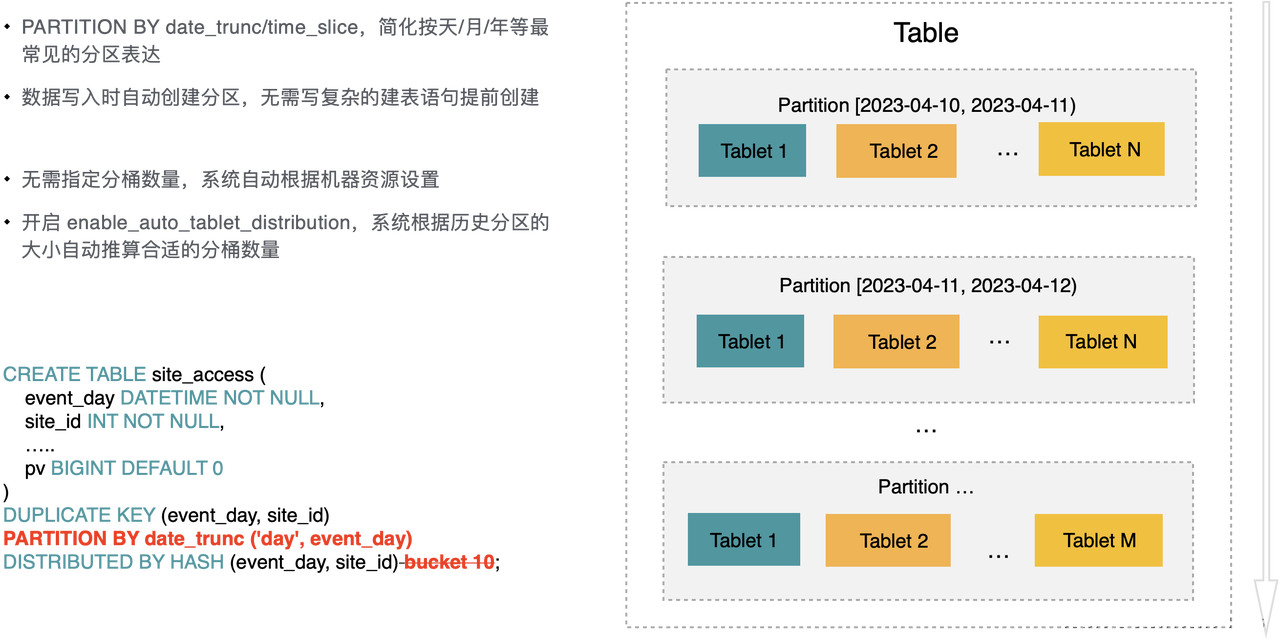 在 3.0 版本中,StarRocks 在分区分桶管理上做了优化,简化建表语句:
在 3.0 版本中,StarRocks 在分区分桶管理上做了优化,简化建表语句:
-
引入 PARTITION BY 表达式的分区能力,简化按年、月、日分区的表达,用户无需提前规划分区,而是在导入数据时,系统按需创建分区。
-
无需指定分桶的数量,建表的时候会自动根据节点资源推算,同时随着数据不断导入,还具备根据历史分区动态调整新分区分桶数量的能力。
在后续版本,我们还会继续对建表做简化,支持自适应的数据分布策略,以及自动的数据源类型推断等能力,让 StarRocks 的数据建模更简单。
主键模型 update 语法支持
StarRocks 通过 delete + insert 的方式支持 OLAP 场景的实时 update 能力,在过去的2.0系列版本里,主要围绕功能、性能持续进行提升。在功能方面,支持了 partial update、conditional update 的能力,通过数据列的字段来标识数据操作;在性能方面,从全内存的主键索引升级为持久化的主键索引,解决主键模型内存占用的问题。
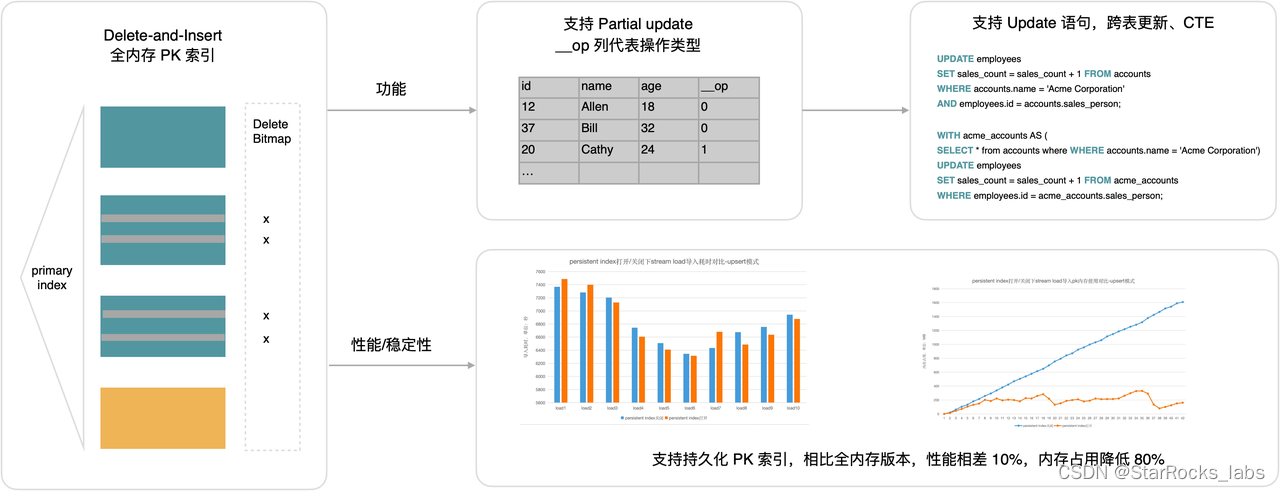
在 3.0 版本,StarRocks 更进一步,提供了 Update 语法的支持,包括跨表更新、CTE 等语法的能力,使得 StarRocks 的更新使用起来更加简单。
优化复制链路,提升写入性能
StarRocks 原来写入时的数据复制机制时 是 Leaderless replication 的方式,写入的数据由一个 coordinator 节点分发给多个副本,每个副本独立的写 memtable、排序、刷盘写成 segment 文件。在 3.0 版本,StarRocks 支持了 Single Leader Replication 策略,写入时先写到一个主副本,主副本写 memtable、排序、刷盘写成 segment 文件,然后直接将 segment 文件同步给其他的副本。
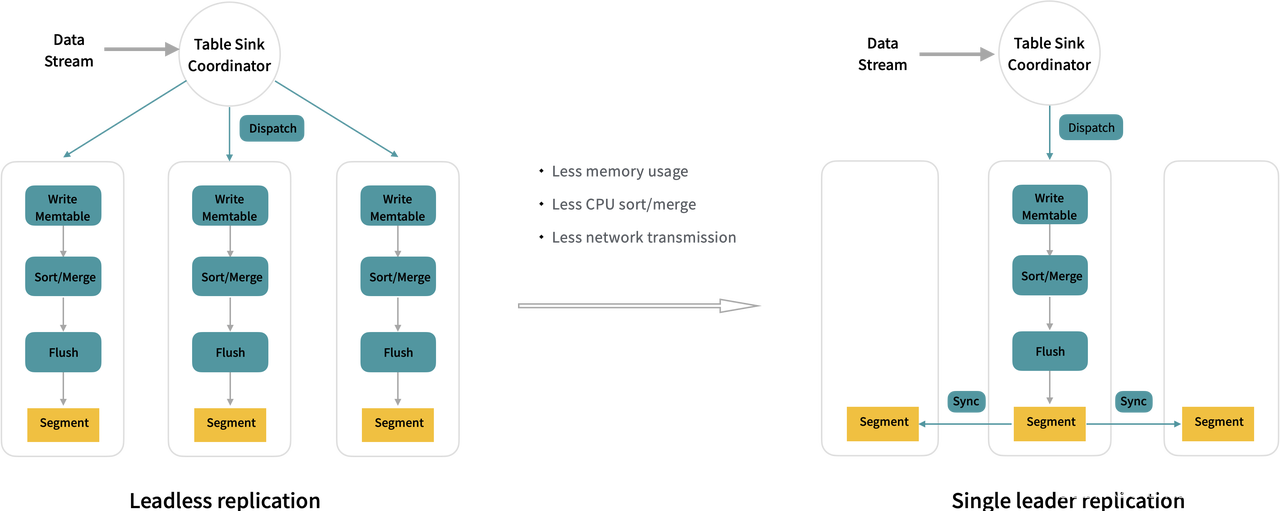
新的数据复制方式,Memtable 内存占用、数据排序、编码的开销下降到原来的1/3。此外,在网络传输上,从传输原始数据到传输压缩后的 Segment 文件数据,网络传输量下降到原来的 1/3 ~ 1/5。在大部分场景下,新的复制方式能提升一倍的写入性能。
Query Cache 加速高并发查询
StarRocks 3.0 进一步完善了 Query Cache 的能力,用于加速高并发的实时聚合场景。在很多场景下,用户需要频繁查询最近一段时间的聚合结果,每次查询,相比上一次查询,变化的只有最近一段时间的增量;如果是分区表,分区的数据一旦不再写入,分区的聚合结果也就不再变化,将历史查询结果进行缓存可以有效的复用。在 SSB 场景下的测试中,额外的 Cache 维护开销很小,部分查询加速效果可达 5-10 倍。

算子落盘,优化内存密集型查询
StarRocks 在过去版本里,查询过程中中间结果需要全部在内存,比如 Aggregate、Join 使用的 Hash 表、ORDER BY 的中间结果。对于分布式 memory-intensive 的查询,可能就会因为内存不足而执行失败。StarRocks 3.0 支持了算子落盘的预览版功能,将计算时候的内存分成多个 Partition,查询过程中遇到内存不足时,可以将部分 Partition 内存换出到磁盘,保证查询能够顺利进行,不会因为内存不足而失败。
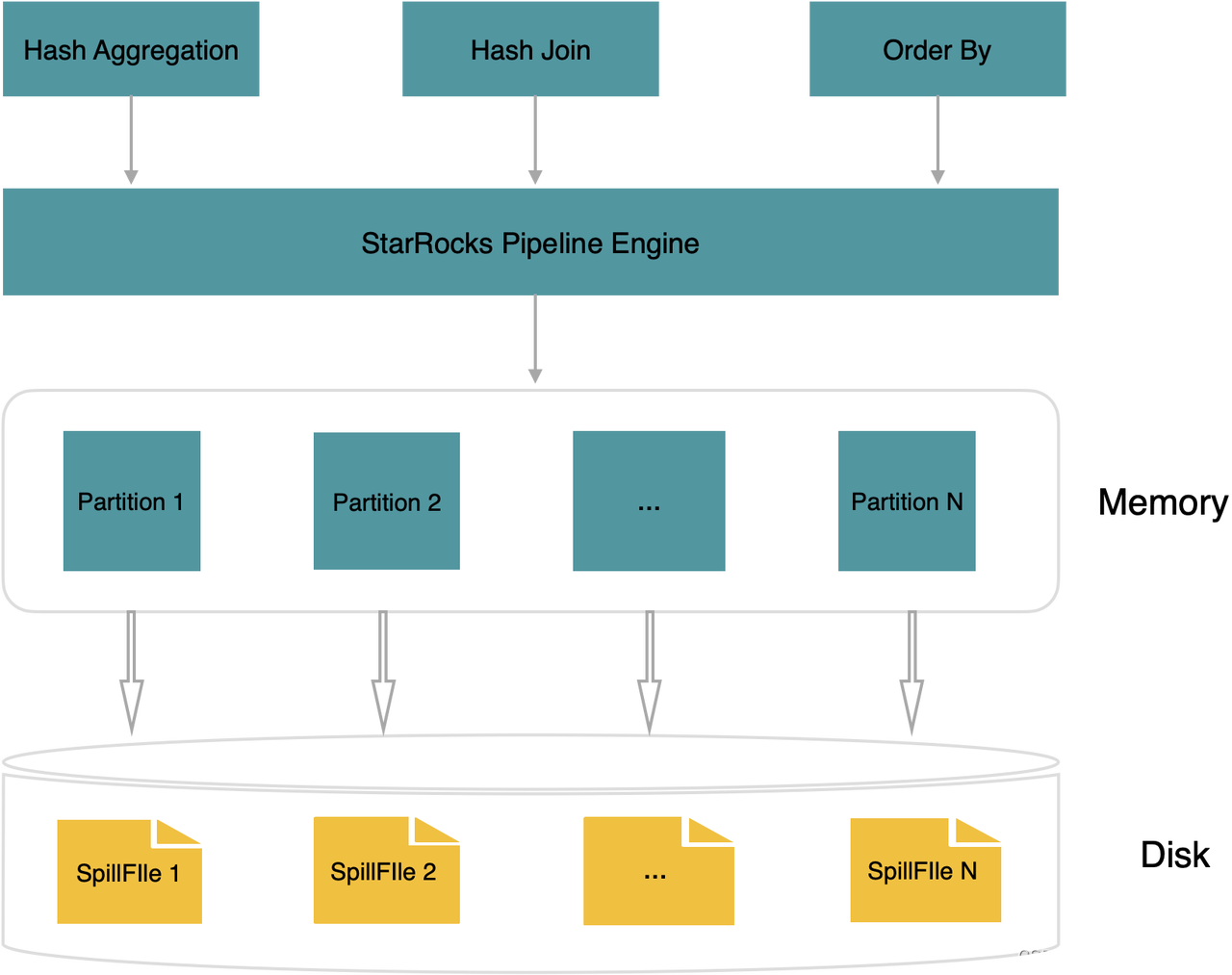
算子落盘的能力,提升了物化视图构建的稳定性。此外,除了 OLAP 分析使用 StarRocks,用户还可以将一些简单的批处理 Job、ETL 等工作放到 StarRocks 里完成,实现极速统一的数据处理。
3.x 版本后续计划

在今年后续的3.x系列版本里,StarRocks 会继续在云原生、湖仓融合、极速统一等方向上提升。云原生架构将提升弹性伸缩和实时分析的综合能力;同时, StarRocks 将进一步提升查询性能、完善算子落盘,并增强半/非结构化数据的处理来适应更多的数据应用场景。在批量调度的物化视图基础上,StarRocks 还将支持实时物化视图,以进一步简化实时分析链路的构建,打造极速统一的湖仓新范式。
相关链接:
Release Notes 3.0 :https://docs.starrocks.io/zh-cn/main/release_notes/release-3.0 二进制包下载地址:https://www.starrocks.io/download/community