单线程模型
Redis 自诞生以来,一直以高性能著称。很多人好奇,Redis 为什么早期采用单线程模型,它真的比多线程还快吗? 其实,Redis 的“快”并不在于并发线程,而在于其整体架构设计极致简单高效,主要体现在:
-
基于内存(最主要的原因),性能瓶颈不在 CPU:Redis 的数据全部存储在内存中,访问不涉及磁盘 I/O,CPU 在大多数情况下并不是瓶颈,因此不需要多线程分摊计算压力。
-
数据存取非常快:
-
Redis 存储在内存中,读写速度接近极限;
-
不需要频繁的上下文切换、内核态与用户态的转换;
-
执行效率高,每个请求处理成本低。
-
-
避免多线程带来的复杂性:
-
单线程模型可以避免加锁、解锁、死锁等多线程并发问题;
-
无需线程上下文切换,节省 CPU 时间;
-
更容易实现和维护。
-
-
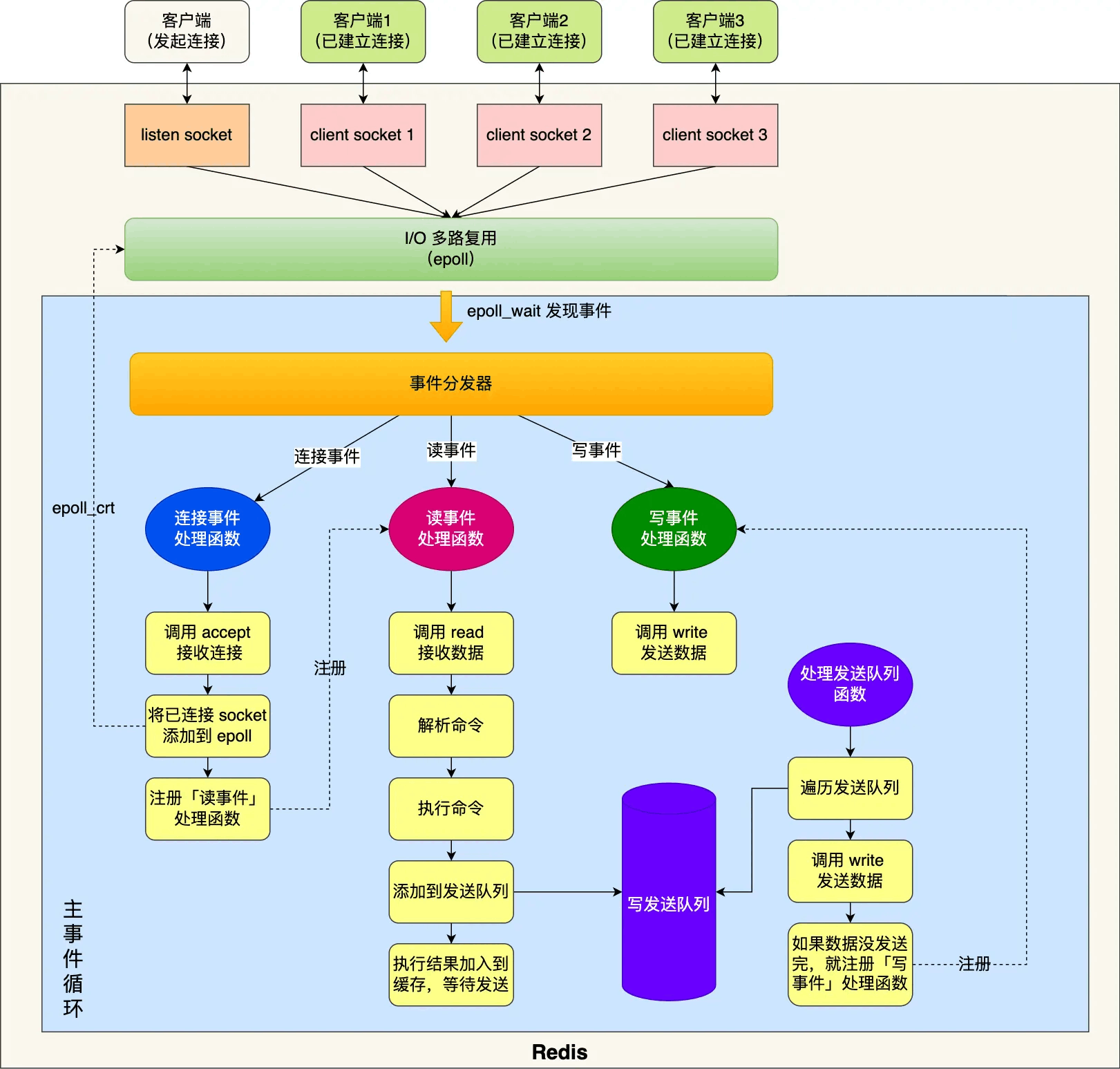
多路复用机制:Redis 使用了基于事件驱动的
epoll(Linux)实现的I/O 多路复用模型,能够高效地处理大量客户端连接请求。 -
高效数据结构:非常适合内存操作的高效数据结构:SDS(简单动态字符串),ziplist,listpack,quicklist,跳表 skiplist; 这些结构可以保证极快的插入、查询、遍历效率。
引入多线程的原因
随着 Redis 用户量剧增、业务规模扩大,Redis 面临了一些新的挑战,也就是Redis的性能瓶颈:
网络 I/O,当连接数剧增(特别是高并发大请求的场景),网络数据的读取/写入成为瓶颈:
-
虽然命令执行依然快速;
-
但主线程需要花费大量时间在“读 socket、写 socket、解析协议”上。
为了解决网络瓶颈问题,Redis 从 6.0 开始引入 I/O 多线程机制:
- 仍然保留主线程执行命令的模型;
- 引入多个后台 I/O 线程负责读写 socket 数据;
- 实现真正意义上的读写分离、I/O 解耦。
I/O 线程只做纯粹的网络数据传输,不涉及数据结构修改,不会产生线程安全问题,也不会破坏原有的单线程执行语义。
无法充分利用多核资源:多核时代,单线程只能用一个 CPU 核心,处理海量并发请求时能力不足。
三个核心后台线程
Redis 除了主线程之外,还有 3 个重要的后台线程,称为 BIO(Background I/O)线程,用于异步处理阻塞或耗时任务:
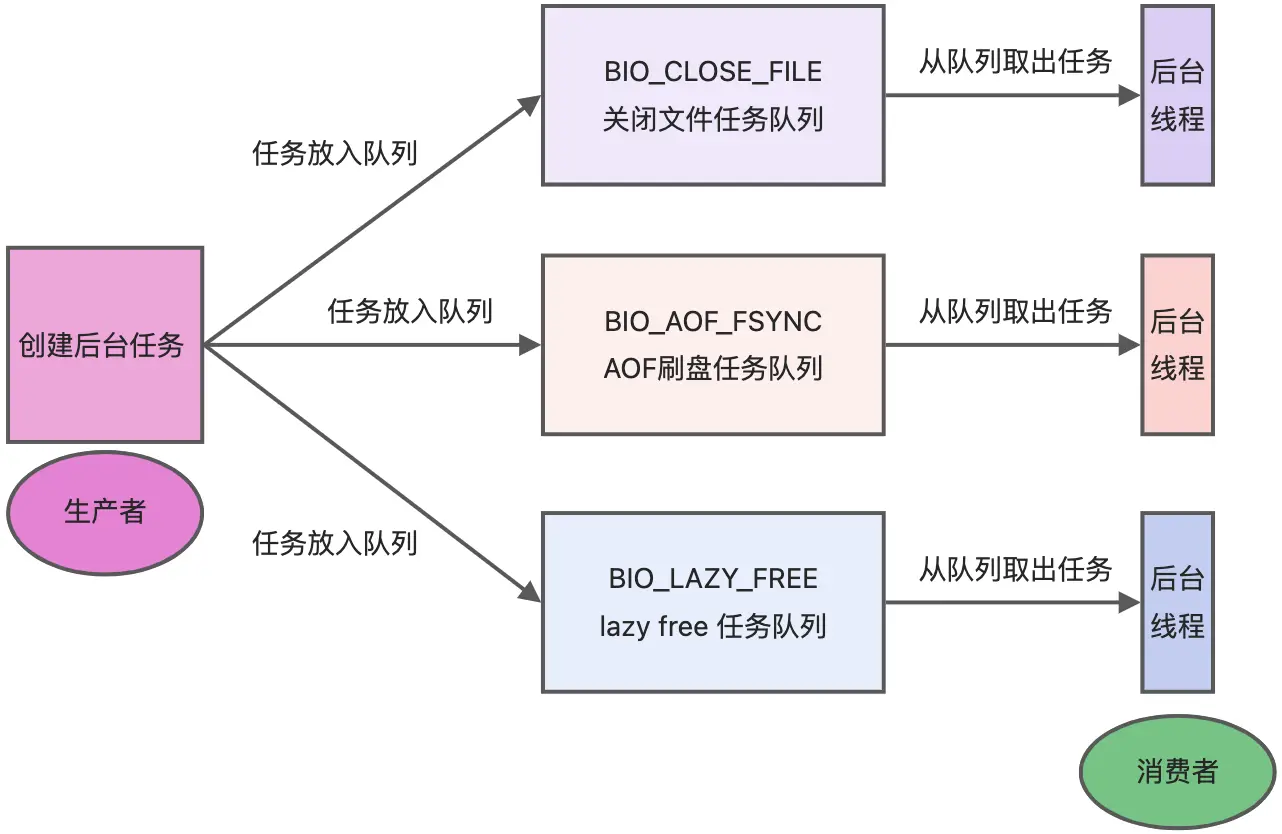
释放内存线程
- 异步释放内存:Redis 执行删除、淘汰数据操作时,释放内存线程在后台异步释放内存,避免主线程卡顿,尤其处理大量数据删除时,能分散内存释放压力,保证系统并发处理能力。
- 内存碎片整理:定期检查内存,整理碎片,合并不连续空闲内存块,提高内存利用率,降低内存分配失败概率,增强服务器稳定性。
AOF 刷盘线程
- 日志重写:AOF 文件随时间和写操作增多会变大,AOF 重写线程在后台重写,依据数据库状态将键值对操作重记为命令,生成更小 AOF 文件,缩短服务器启动和数据恢复时间。
- 数据一致性保证:重写时对数据库快照,记录开始状态,依据重写期间命令更新快照,合并更新后快照和命令记录成新 AOF 文件,确保数据一致性。
处理关闭文件线程
- 大对象释放:删除或过期大对象时,Redis 将其放入待释放队列,由线程在后台逐步释放,避免主线程长时间阻塞,提升系统整体可用性。
- 资源合理利用:根据系统负载和内存使用情况,合理安排大对象释放时间和频率,业务高峰期减慢释放,低谷期加快释放。
| BIO 线程 | 功能 |
|---|---|
| AOF 刷盘线程 | 在 everysec 策略下,每秒由后台线程执行 fsync 持久化 |
| 释放内存线程 | 删除大 key 或触发过期淘汰时,为避免阻塞主线程,异步执行 |
| 处理关闭文件线程 | 在 AOF 重写、RDB 持久化结束后,异步关闭文件描述符,释放资源 |
三个或多个 I/O 线程
Redis 在 6.0 之后支持配置若干个 I/O 线程,用于处理网络读取和写入:
| 类型 | 描述 |
|---|---|
| 读线程 | 从客户端连接读取请求数据、解析协议 |
| 写线程 | 将主线程处理完的响应结果写回客户端 |
| 默认配置 | 默认只开启“写多线程”,读仍然由主线程处理 |
配置方式(redis.conf):
io-threads 4 # 开启 4 个 I/O 线程(建议2-8之间)
io-threads-do-reads yes # 启用读请求的多线程处理(默认关闭)
注意:即便开启多线程,命令解析和执行仍然是由 主线程 完成!
参考资料:小林coding




![[数据结构]排序 --2](https://i-blog.csdnimg.cn/direct/4fb02329afd54ebcade86b194165ffd5.png)