1.工作目录,如:mnt/d/work,下载源代码,并安装依赖
git clone https://github.com/THUDM/ChatGLM-6Bcd ChatGLM-6B
pip install -r requirement.txt2. 从拥抱脸下载chatglm-6b-int4-qe到本地(GPU环境搭建参考浪潮服务器 Tesla T4 16G GPU 环境配置_wxl781227的博客-CSDN博客)
3. 安装docker及nvidia-docker2环境(自行百度知乎)
4. docker下载nvidia容器(强烈推荐使用nvidia容器,省去很多麻烦)
sudo docker pull nvcr.io/nvidia/pytorch:23.01-py35. 在工作目录下,启动nvidia容器,多开放几个端口,方便映射。
sudo docker run --name gpt --gpus=all --ipc=host --ulimit memlock=-1 --rm -it -p 6006:6006 -p 8500:8500 -p 8501:8501 -p 8502:8502 -v $PWD:/gpt -v /etc/localtime:/etc/localtime:ro -d nvcr.io/nvidia/pytorch:23.01-py36. 整理催收问答对训练train.json及验证文件val.json
7. 在gpt容器中启动jupyter lab,方便修改代码
jupyter lab --port=6006 --allow-root8. 打开localhost:6006/lab,输入token,这样就可以方便的上传文件,修改代码了。
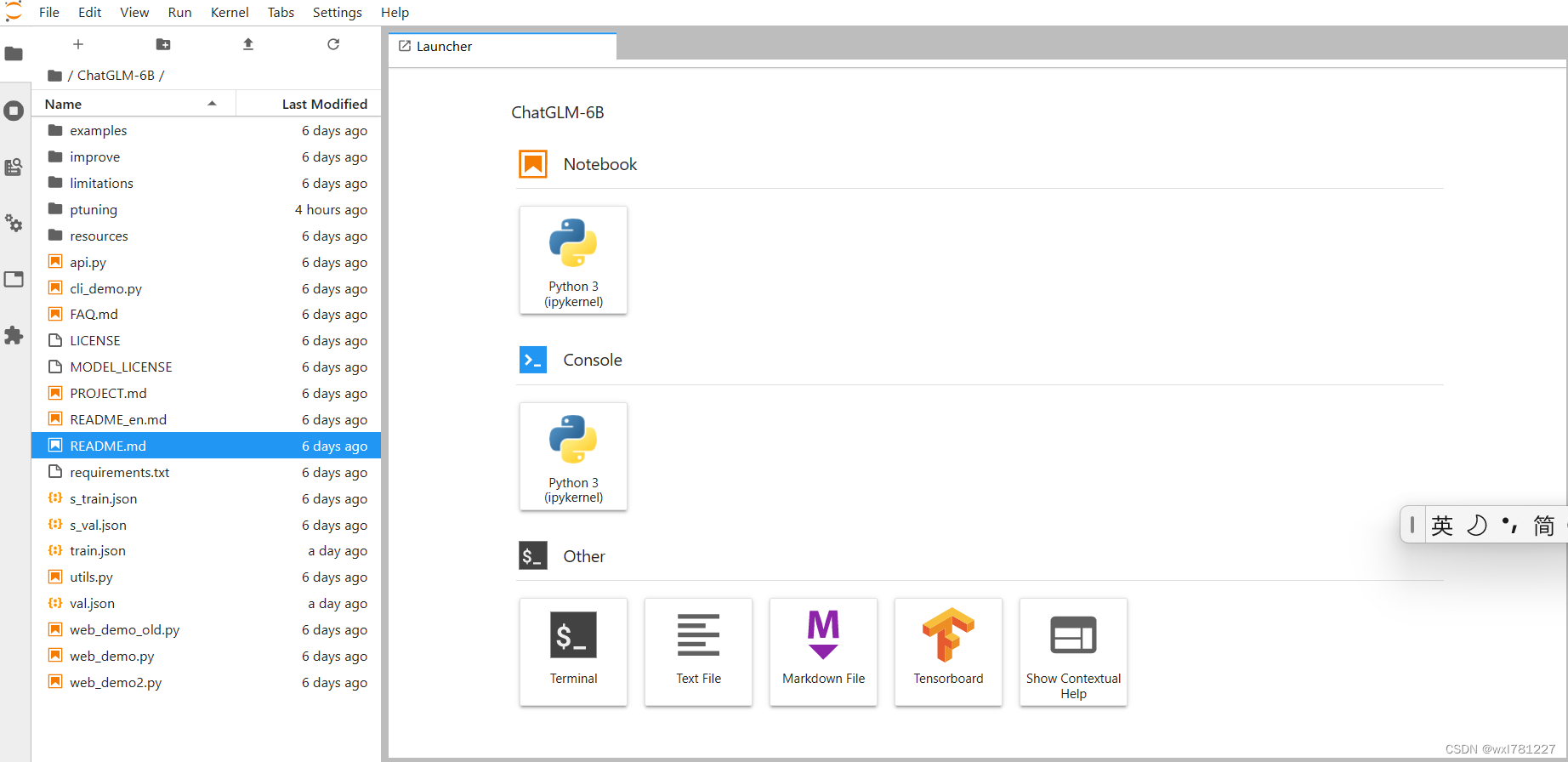
9. 进入ptuning修改训练脚本train.sh
PRE_SEQ_LEN=128
LR=2e-2
CUDA_VISIBLE_DEVICES=0 python3 main.py \
--do_train \
--train_file /gpt/ChatGLM-6B/train.json \
--validation_file /gpt/ChatGLM-6B/val.json \
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path /gpt/chatglm-6b-int4-qe \
--output_dir check_point/chatglm-6b-int4-qe-pt-$PRE_SEQ_LEN-$LR \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 64 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 16 \
--predict_with_generate \
--max_steps 3000 \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate $LR \
--pre_seq_len $PRE_SEQ_LEN \
--quantization_bit 4
per_device_train_batch_size根据GPU大小进行调整,如:1,2,4,8,16等。
max_source_length及max_target_length 可以根据实际情况调整,对应的是输出和输出的长度。
10.在gpt容器中启动微调训练,根据数据量不同及GPU大小,有所不同,tesla T4 16 G 30个问答对大概要24小时。
sh train.sh11. 评估训练的效果(修改evaluate.sh,并执行)
PRE_SEQ_LEN=128
CHECKPOINT=adgen-chatglm-6b-pt-128-2e-2
STEP=3000
CUDA_VISIBLE_DEVICES=0 python3 main.py \
--do_predict \
--validation_file /gpt/val.json \
--test_file /gpt/val.json \
--overwrite_cache \
--prompt_column content \
--response_column summary \
--model_name_or_path /gpt/chatglm-6b-int4-qe \
--ptuning_checkpoint check_point/$CHECKPOINT/checkpoint-$STEP \
--output_dir output/$CHECKPOINT \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 64 \
--per_device_eval_batch_size 1 \
--predict_with_generate \
--pre_seq_len $PRE_SEQ_LEN \
--quantization_bit 4sh evaluate.sh12. 启动微调后的模型(修改web_demo.sh,并运行,默认端口7860,web_demo.py中修改为server_port=8500)
# web_demo.py
# demo.queue().launch(share=False, inbrowser=True)
demo.queue().launch(share=False, inbrowser=True, server_port=8500)PRE_SEQ_LEN=128
CUDA_VISIBLE_DEVICES=0 python3 web_demo.py \
--model_name_or_path /gpt/chatglm-6b-int4-qe \
--ptuning_checkpoint check_point/chatglm-6b-int4-qe-pt-128-2e-2/checkpoint-3000 \
--pre_seq_len $PRE_SEQ_LENsh web_demo.sh13. 打开界面实际测试
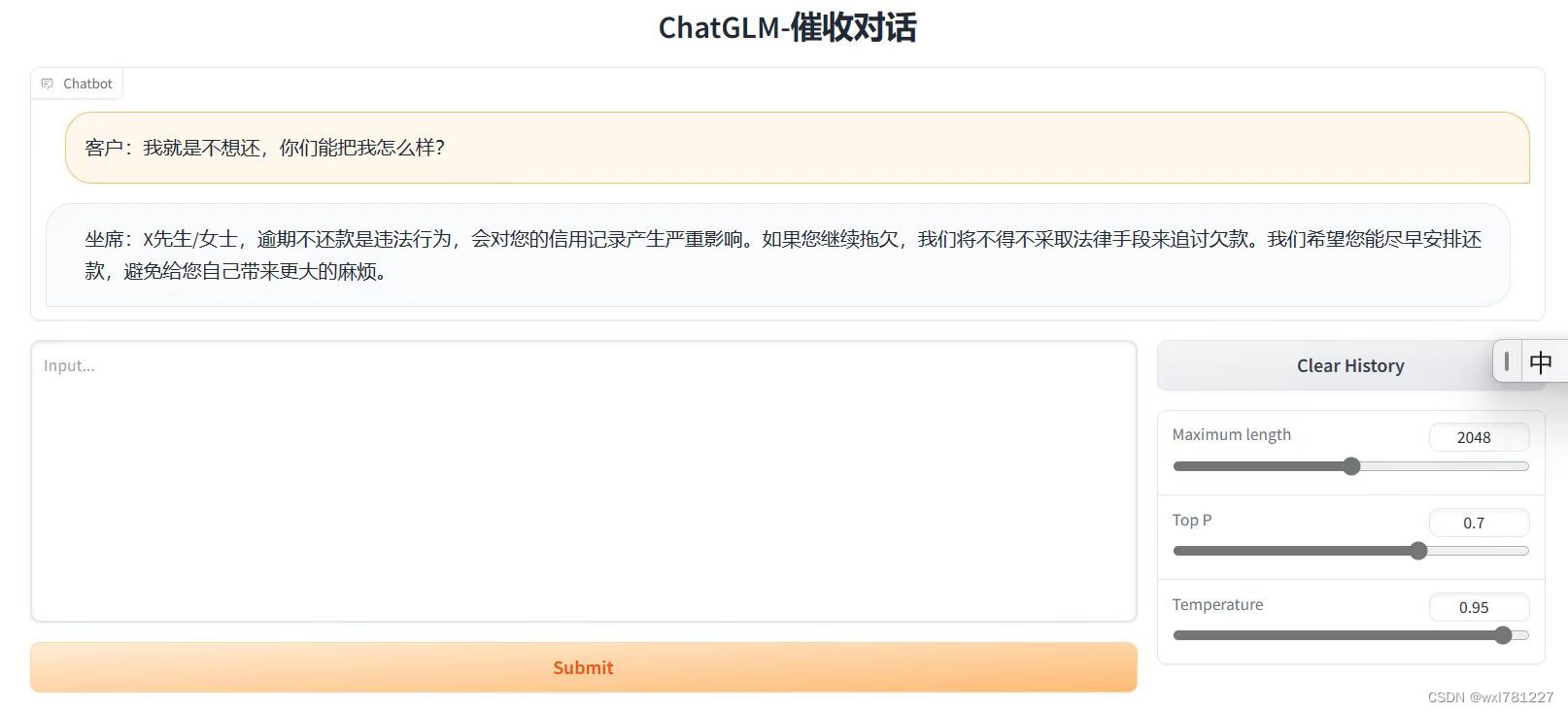
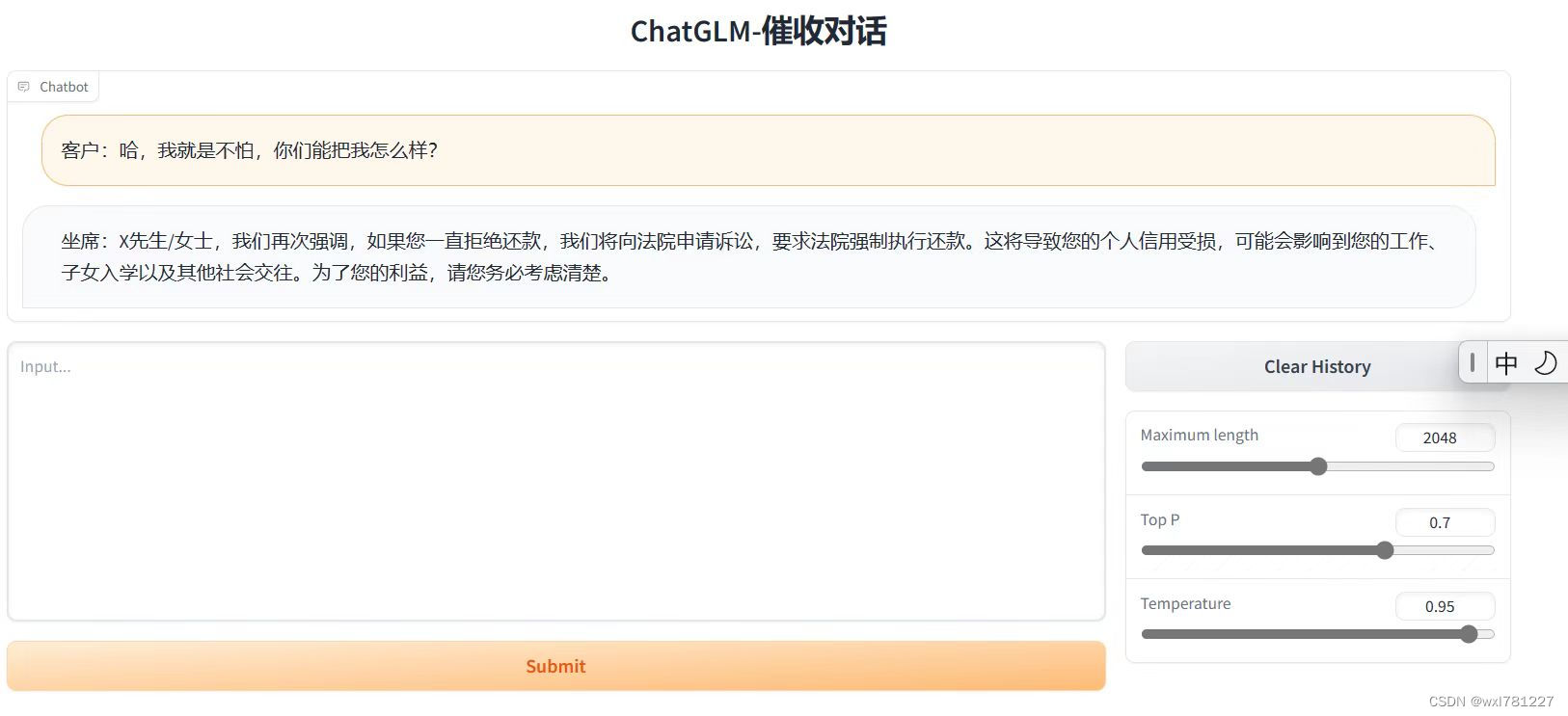
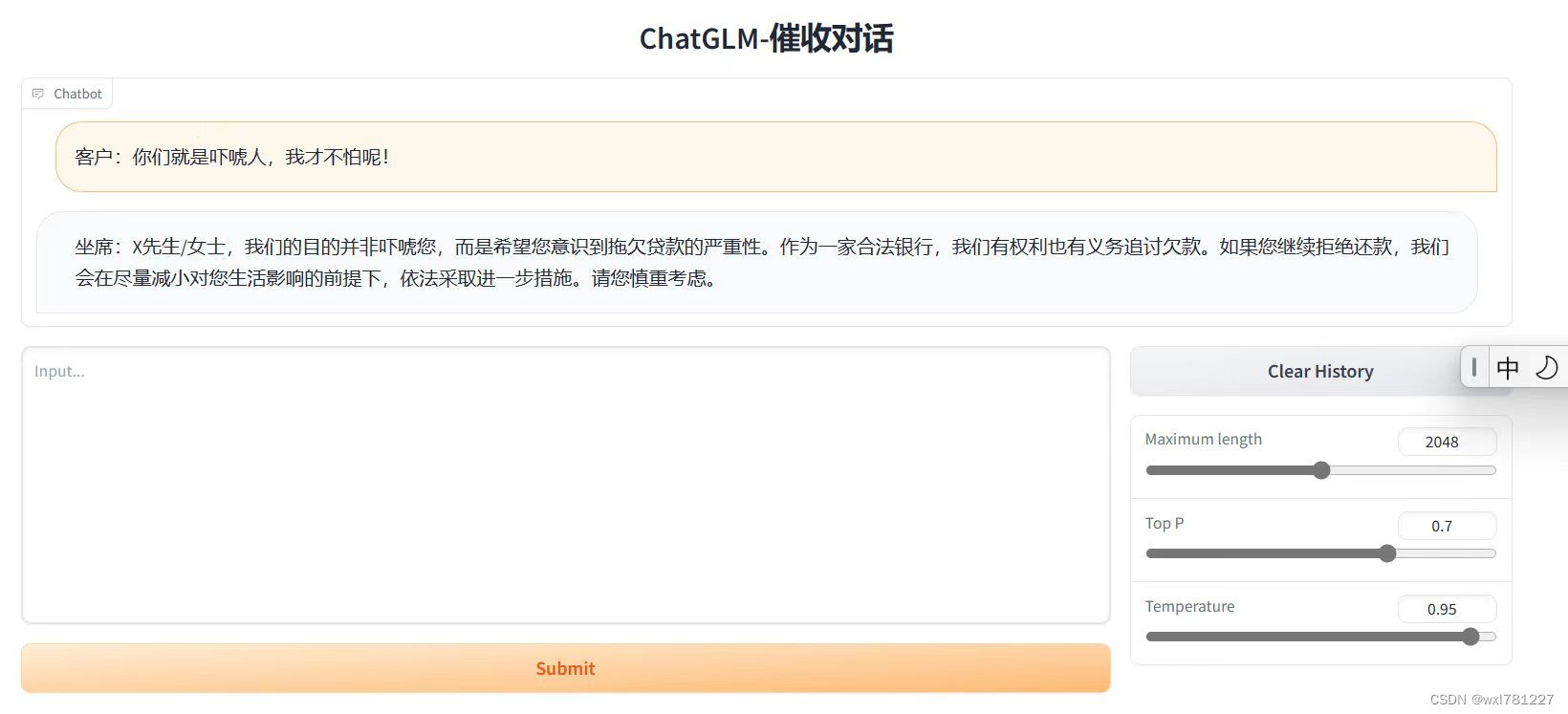
14.结论
微调后的效果与预期一致,能够有效控制输出结果,即输出完全按照问答对训练预料来输出的。