前言
之前的笔记提到了《Power BI 数据模型的核心概念》,本文继续深入讨论数据模型的设计架构,同时介绍两种常用的数据模型:星型模型和雪花模型
BI 的数据模型和数仓模型有什么不同?
数据仓库和Power BI中使用的数据架构模型有一些相似之处,但也有一些关键区别。
- 数据仓库模型更加专业化和复杂化,针对数据加载和历史记录保留进行了优化。
- BI模型更简单,侧重于易用性和性能,通常使用汇总或聚合数据。BI模型还可以合并来自多个来源的数据。
- 数据详细程度不同,数据仓库模型存储细粒度数据,而BI模型通常汇总或聚合数据。
规范化& 非规范化
这里引入两个术语:
规范化,指以减少重复数据的存储方式, 反之,没有减少重复数据的数据存储表,就是非规范化。
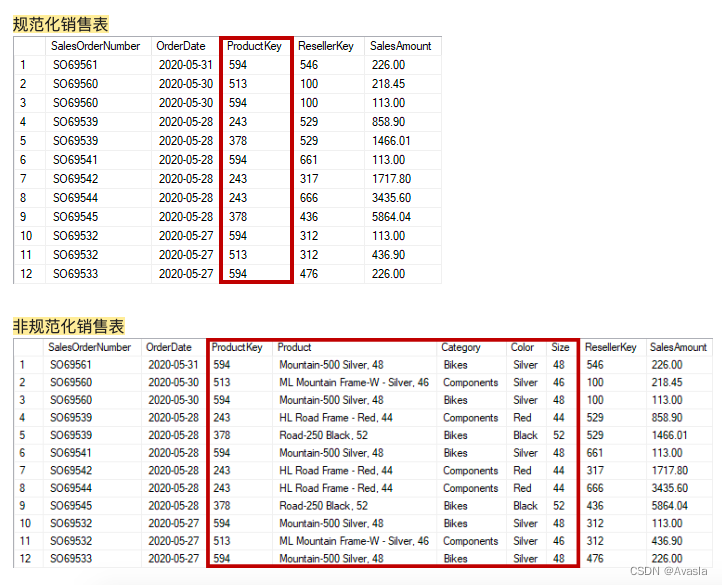
产品表中有唯一的产品编号列(ProductKey)和产品特征列(产品名称、类别、颜色、尺寸)。在规范化的销售表中,仅存储ProductKey,只有 ProductKey 列记录产品信息;而非规范化的表格,还包括了产品的详细信息,多了许多重复的产品信息。
在实际应用中,我们只需要通过ProductKey 将销售表和产品表关联起来,即可得到每一单的商品详细信息。所以在开发和优化数据模型时,分析师可以通过将非规范化的数据转换成规范化表,进而提高数据模型的效率。
星型模型
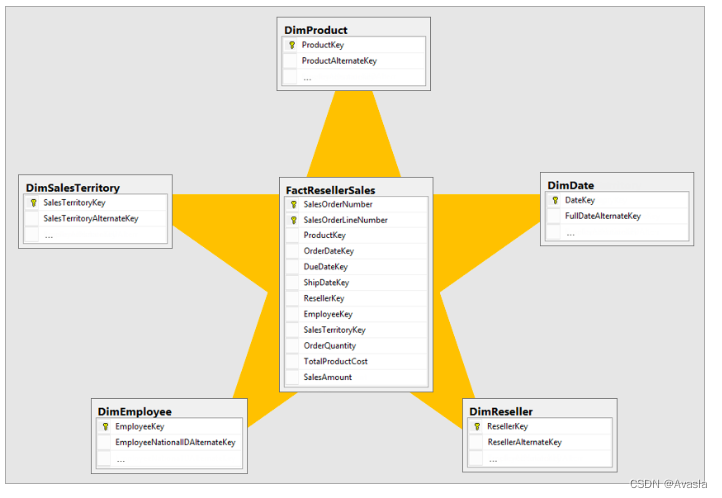
星型模型由一个事实数据表和多个非规范化的维度表构成,可以帮助分析人员简化数据表格,是由关系数据仓库广泛采用的成熟建模方法 。
通常情况下,维度表包含的行数相对较少。 另一方面,事实数据表可能包含非常多的行,并行数会随着时间的推移不断增长。
雪花模型
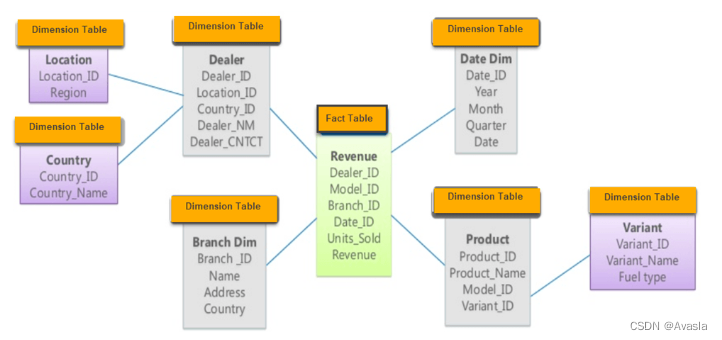
雪花模式是星型模式的变体,其中维度表是规范化的,这意味着它们被拆分为多个相关的表以减少冗余。这可能使模式更复杂,但也更适用于某些类型的查询,例如涉及跨多个维度过滤或聚合数据的查询。
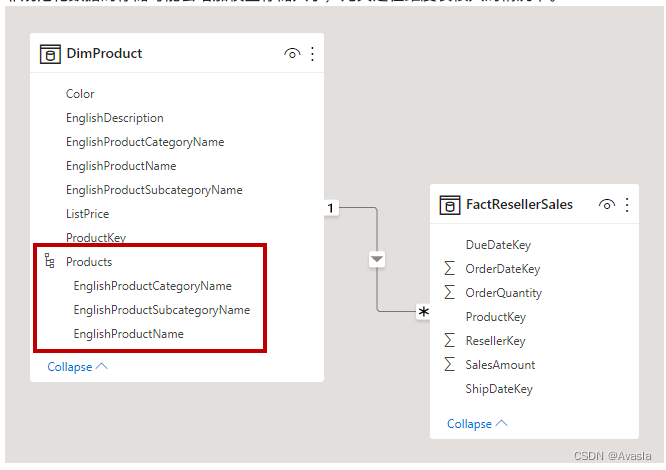
雪花维度
在 Power BI中,完全使用雪花模型可能导致模型过大,效率降低,因此,分析师可以根据需求模拟雪花维度的设计,将部分维度表规范化。
例如,Adventure Works (官方提供的案例数据 ) 按类别和子类别将产品分类。 产品分配给子类别,而子类别又相应地分配给类别。 在 Adventure Works 关系数据仓库中,“产品”维度经过了规范化并存储在三个相关表中:DimProductCategory 、DimProductSubcategory 和 DimProduct 。
![![[Pasted image 20230508191141.png]]](https://img-blog.csdnimg.cn/73cfb2df9ceb4cd99cb9300f581f1529.png)
处理非规范数据的方式
1. 定义层次结构
在选择集成到一个模型表中时,还可以定义一个层次结构,其中包含维度的最高和最低粒度。 冗余非规范化数据的存储可能会增加模型存储大小,尤其是在维度表很大的情况下。
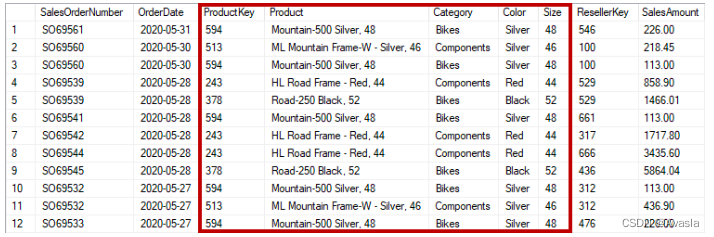
2. 通过Power Query提取维度表
比如前面提到的销售表,包括了所需的产品信息详情,可以通过PQ对销售表进行操作,复制原数据表格,删除冗余信息及重复项,生成规范化的产品信息表。
3. 通过DAX公式提取维度表
可以根据现有的数据字段,提取需要的维度表,根据上面的合并表,如果需要一个商品名称的维度表,在DAX编辑框中输入:
产品表 = DISTINCT('销售表'[产品名称])
DISTINCT函数可以提取一列中不重复的值。