文章目录
- 概述
- 第一步 : 聚合获取原始数据并分页
- 知识点:bucket_sort实现分页
- 知识点:获取 total -----> cardinality 去重
- 小结
- 第二步 分页并支持模糊查询
- 方式一 query 方式
- 方式二: 脚本
- cardinality 的 script

概述
ES版本: 7.6.
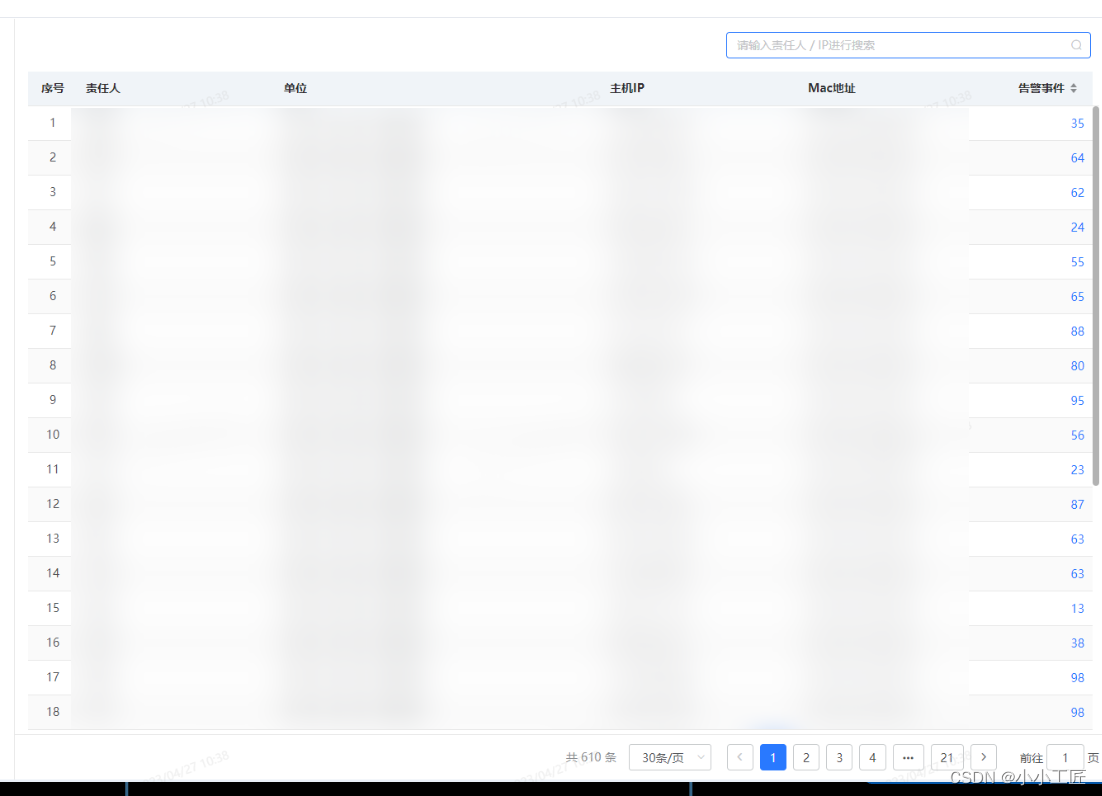
需要按照主机ID 进行告警时间的汇总,并且还得把主机相关的信息展示出来。
注: 所有的数据都存在索引中, 通过一个DSL查询展示
实际上就是将terms聚合的结果以列表形式分页展示。

第一步 : 聚合获取原始数据并分页
GET index_name/_search
{
"size": 0,
"query": {
"match_all": {}
},
"aggs": {
"getAlarmStatistByHostId": {
"terms": {
"field": "host_id",
"size": 100000,
"order": {
"_count": "desc"
}
},
"aggs": {
"host_details": {
"top_hits": {
"size": 1,
"_source": {
"include": [
"host_nameame",
"host_ip",
"host_mac"
]
}
}
},
"myBucketSort": {
"bucket_sort": {
"from": 0,
"size": 2,
"gap_policy": "SKIP"
}
}
}
},
"termsCount": {
"cardinality": {
"field": "host_id",
"precision_threshold": 40000
}
}
}
}
知识点:bucket_sort实现分页
- bucket_sort中 from不是pageNum,如想实现pageNum效果,from=pageNum*size即可;
- terms聚合的size,实际上size可以尽可能的设置大一点,具体大小按实际情况来看;
"myBucketSort": {
"bucket_sort": {
"from": 0,
"size": 2,
"gap_policy": "SKIP"
}
}
在 bucket_sort 中,可以指定以下其他参数:
- from: 从哪个桶开始排序,默认是0,表示从第一个桶开始
- size: 每个桶有多少个桶,默认是2,表示每个桶有2个桶 (其实就是每页展示多少条数据)
- gap_policy: 桶之间的策略,可选值有:
- SKIP: 跳过空桶,默认值
- INTERPOLATE: 使用非空桶的最小和最大值来填充空桶
- FAIL: 如果遇到空桶,直接失败
所以上述的配置的意思是
- 从第一个桶开始排序
- 每个桶有2个子桶
- 遇到空桶时跳过空桶
这可以让我们更加精细地控制桶的划分和处理。
知识点:获取 total -----> cardinality 去重
"termsCount": {
"cardinality": {
"field": "host_id",
"precision_threshold": 40000
}
}
- field: 指定要计算基数的字段,这里是 host_id
- precision_threshold: 基数的精度 threshold,默认为 40000。高于这个阈值,返回的基数为 estimated 值,低于这个阈值,返回 exact 值。
在 Elasticsearch 中,cardinality 算法用来计算字段的基数(不重复的值的个数).
cardinality 算法是通过 HyperLogLog 算法实现的,所以它很高效,可以支持大规模数据的基数统计,并且精度很高。 缺省值为3000

精度阈值选项允许用内存交换精度,并定义了一个唯一的计数,在该计数低于此值时,预计计数接近准确。超过这个值,计数可能会变得有点模糊。支持的最大值是40000,高于这个数字的阈值将具有与40000阈值相同的效果。缺省值为3000。
默认情况下,如果基数超过 40000,cardinality 会返回 estimated 值(估算值),否则返回 exact 值(精确值)。如果文档个数远大于40000,那么会返回estimated值,比如50000, 可以通过 precision_threshold 参数控制这个阈值。
所以,cardinality 很适合用于:
- 统计网站的访问设备/IP 数量
- 统计不同产品的数量
- 统计不同用户的数量
- …
它可以提供近实时的统计,对性能影响很小。
小结
利用bucket_sort来分页,cardinality来获取total
第二步 分页并支持模糊查询
方式一 query 方式
GET attack/_search
{
"size": 0,
"query": {
"bool": {
"must": [
{
"bool": {
"should": [
{
"match_phrase": {
"host_userName": "guo"
}
},
{
"match_phrase": {
"host_ip": "192.168.198.132"
}
}
]
}
},
{
"bool": {
"filter": [
{
"terms": {
"host_id": [
"f261cd4b-8922-4c1f-bb24-72eec4f4245c",
"89bd8783-9cbf-4c8d-9160-da4588ee73d7"
]
}
}
]
}
}
]
}
},
"aggs": {
"getAlarmStatistByHostId": {
"terms": {
"field": "host_id",
"size": 100000,
"order": {
"_count": "desc"
}
},
"aggs": {
"host_details": {
"top_hits": {
"size": 1,
"_source": {
"include": [
"host_id",
"host_userName",
"host_orgPath",
"host_ip",
"host_mac"
]
}
}
},
"myBucketSort": {
"bucket_sort": {
"from": 0,
"size": 2,
"gap_policy": "SKIP"
}
}
}
},
"termsCount": {
"cardinality": {
"field": "host_id",
"precision_threshold": 40000
}
}
}
}
返回
{
"took" : 19,
"timed_out" : false,
"_shards" : {
"total" : 8,
"successful" : 8,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"getAlarmStatistByHostId" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "f261cd4b-8922-4c1f-bb24-72eec4f4245c",
"doc_count" : 10,
"host_details" : {
"hits" : {
"total" : {
"value" : 10,
"relation" : "eq"
},
"max_score" : 9.781191,
"hits" : [
{
"_index" : "zfattack-202305",
"_type" : "_doc",
"_id" : "b19af55c-33ec-4e50-93c2-8ae028d96c5c",
"_score" : 9.781191,
"_source" : {
"host_ip" : "192.168.198.132",
"host_mac" : "00-0C-29-CA-E9-4C",
"host_orgPath" : """112赣州\ztj单位\ztj部门""",
"host_userName" : "guo",
"host_id" : "f261cd4b-8922-4c1f-bb24-72eec4f4245c"
}
}
]
}
}
}
]
},
"termsCount" : {
"value" : 1
}
}
}
方式二: 脚本
GET zfattack-*/_search
{
"size": 0,
"query": {
"match_all": {}
},
"aggs": {
"getAlarmStatistByHostId": {
"terms": {
"script": {
"source": "if(doc['host_id'].value.contains('f261cd4b-8922-4c1f-bb24-72eec4f4245c')) {doc['host_id'].value }"
},
"size": 100000,
"order": {
"_count": "desc"
}
},
"aggs": {
"host_details": {
"top_hits": {
"size": 1,
"_source": {
"include": [
"host_id",
"host_userName",
"host_orgPath",
"host_ip",
"host_mac"
]
}
}
},
"myBucketSort": {
"bucket_sort": {
"from": 0,
"size": 2,
"gap_policy": "SKIP"
}
}
}
},
"termsCount": {
"cardinality": {
"script": {
"source": "if(doc['host_id'].value.contains('f261cd4b-8922-4c1f-bb24-72eec4f4245c')) {doc['host_id'].value }"
},
"precision_threshold": 40000
}
}
}
}
返回
#! Deprecation: Deprecated field [include] used, expected [includes] instead
{
"took" : 15,
"timed_out" : false,
"_shards" : {
"total" : 8,
"successful" : 8,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"getAlarmStatistByHostId" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "f261cd4b-8922-4c1f-bb24-72eec4f4245c",
"doc_count" : 10,
"host_details" : {
"hits" : {
"total" : {
"value" : 10,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "zfattack-202305",
"_type" : "_doc",
"_id" : "7b761eaa-8b65-4608-b3d9-89a82c9b1784",
"_score" : 1.0,
"_source" : {
"host_ip" : "192.168.198.132",
"host_mac" : "00-0C-29-CA-E9-4C",
"host_orgPath" : """112赣州\ztj单位\ztj部门""",
"host_userName" : "guo",
"host_id" : "f261cd4b-8922-4c1f-bb24-72eec4f4245c"
}
}
]
}
}
}
]
},
"termsCount" : {
"value" : 1
}
}
}
cardinality 的 script
可以通过 cardinality 的 script 参数来达到过滤的效果。
语法是:
"cardinality": {
"field": "field_name",
"script": "condition"
}
这会统计 field_name 字段中满足 script 条件的基数。
例如,有文档:
{ "age": 10 }
{ "age": 20 }
{ "age": 30 }
{ "age": 40 }
如果我们要统计 age > 30 的基数,可以使用:
"cardinality": {
"field": "age",
"script": "doc['age'].value > 30"
}
这会返回 2,因为只有 age = 40 的文档满足条件。
再比如,要统计同时满足 age > 30 和 gender = “male” 的用户基数,可以使用:
"cardinality": {
"field": "age",
"script": "doc['age'].value > 30 && doc['gender'].value == 'male'"
}
这里的 script 使用 Elasticsearch 的 Painless 脚本语言,可以非常灵活地设置过滤逻辑。
所以,通过 script 参数,我们可以实现一些过滤条件,然后统计满足这些条件的字段基数,这给我们带来很大灵活性。
除了 cardinality 聚合,在 termsCount 查询中也可以使用 script 过滤:
"termsCount": {
"cardinality": {
"field": "age",
"script": "doc['age'].value > 30"
}
}
这会返回一个 filtered 基数,代表 age 大于 30 的值有多少个。
所以 script 参数让 cardinality 和 termsCount 变得更加强大和灵活。









![[学习笔记] [机器学习] 4. [上]线性回归(正规方程、梯度下降、岭回归)](https://img-blog.csdnimg.cn/62e9be8d52124d538393508f4250cd40.png#pic_center)