文章目录
- Few-shot Medical Image Segmentation Regularized with Self-reference and Contrastive Learning
- 摘要
- 本文方法
- Local Prototype-Based Segmentation
- Self-reference Regularization
- Contrastive Learning
- Superpixel-Based Self-supervised Learning
- 实验结果
Few-shot Medical Image Segmentation Regularized with Self-reference and Contrastive Learning
摘要
尽管深度卷积神经网络(CNN)在医学图像分割方面取得了巨大进展,但它们通常需要大量专家级的精确、密集注释的图像来进行训练,并且很难推广到看不见的对象类别。因此,很少有人提出通过学习从几个带注释的支持样本中转移知识来解决这些挑战。
本文方法
- 提出了一种新的基于原型的Few-shot分割方法
- 与之前的工作不同,在之前的工作中,将查询特征与学习的支持原型进行比较,以在查询图像上生成分割,我们提出了一种自参考正则化,在这里我们进一步将支持特征与学习到的支持原型相比较,以生成在支持图像上的分割。
- 作者认为学习到的支持原型应该对每个语义类具有代表性,同时对不同的类具有区别性,不仅对查询图像,而且对支持图像也是如此。
- 还引入了对比学习,以在支持和查询特征之间施加类内内聚和类间分离
本文方法
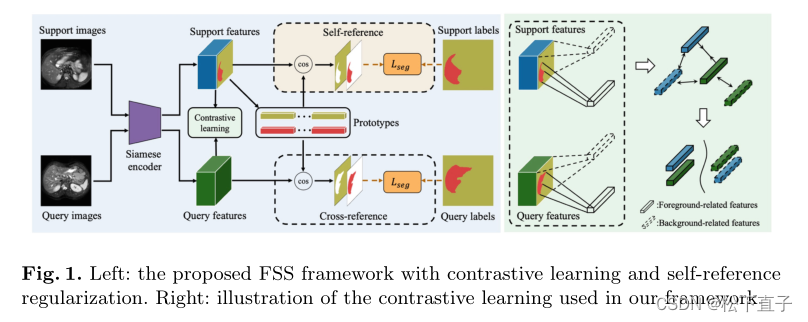
支持集Strain包含K个图像-mask对
查询集包含同一类的N对查询图像和标记的二进制掩码
Local Prototype-Based Segmentation
- 首先通过共享Siamese编码器将支持图像Isk和查询图像Iqj嵌入到特征空间中
- 然后提取前景类c和背景类c0的局部原型
- 根据生成自适应局部原型。具体来说,以前景类为例,我们用池化窗口大小平均池化支持特征
- 然后,将平均池化的前景特征图上的每个像素表示为局部原型
- 然后我们将它们集成到一个原型集合中
在数学上,空间位置(h,w)处的查询特征与背景和前景类的每个局部原型之间的相似性计算为:

通过加权平均进一步计算类相似性
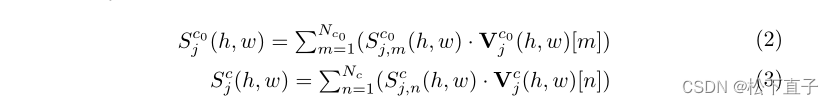
我们使用交叉熵损失Lq j来监督训练过程,计算如下
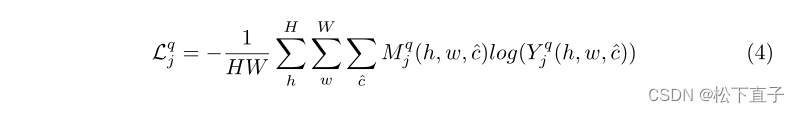
Self-reference Regularization
自我参考的灵感是基于这样一种假设,即更好地表示支持特征的原型有助于在查询图像上获得更好的分割结果。现有的方法只计算学习的原型和查询特征之间的相似性,忽略了来自支持图像的监督。除了学习的支持原型和查询特征之间的交叉参考匹配外,我们还提出了一种自参考正则化,即通过将学习的支持原型机与支持特征匹配来训练模型分割支持图像。通过这一点,我们认为学习到的支持原型应该对每个语义类具有代表性,同时对不同的类具有区别性,不仅对查询图像,而且对支持图像也是如此。这是通过将支持特征的局部相似性图计算为
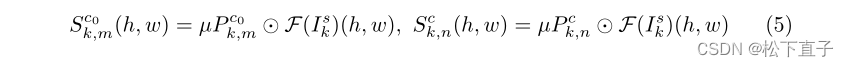
类似地,我们可以计算自参考类的相似性
自参考正则化损失被定义为在支持图像上计算的交叉熵损失:
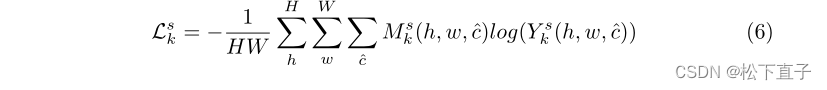
Contrastive Learning
精确的few shot分割依赖于支持特征和查询特征之间的类内相似性和类间区分。为此,利用对比学习来正则化支持图像和查询图像中的前景相关和背景相关特征。这是通过将这些特征分别聚类到一个紧凑的空间来实现的,而不考虑它们的分布,同时减少聚类重叠,如图所示。1(右)。具体来说,我们使用mask平均池化来提取与前景和背景相关的特征。以前景为例,支持和查询特征空间上的前景相关特征分别表示为:
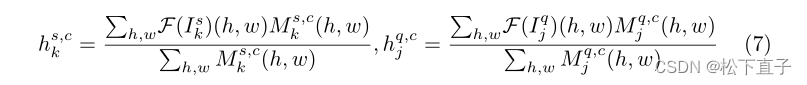
同样,我们可以在支持和查询特征空间上获得与背景相关的特征。将(tu,tv)表示为一对特征,当tu和tv属于同一类别时,这是一对正特征,否则是负特征。我们使用InfoNCE进行对比学习。(tu,tv)的每个正对的InfoNCE损失函数定义为:
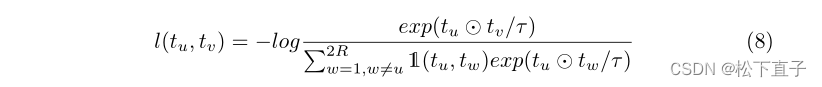
其中R表示前景相关特征和背景相关特征两者的数量;1(tu,tw)对于正对和负对分别为0和1;τ表示温度参数,根据经验设定为0.05。最终对比损失Lc是所有正对上的l(tu,tv)的平均值:
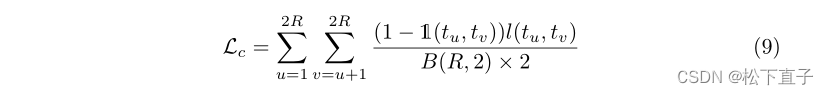
其中B(R,2)是组合的数量。我们方法的总体目标函数如下
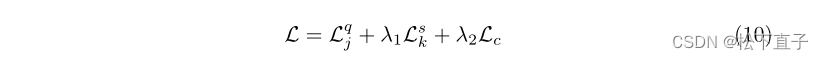 其中{λ1,λ2}是控制不同损失的相对权重的参数,根据经验设置为{1,0.1}
其中{λ1,λ2}是控制不同损失的相对权重的参数,根据经验设置为{1,0.1}
Superpixel-Based Self-supervised Learning
在这项工作中,我们使用基于超像素的自监督学习来训练我们的网络,而不需要任何手动注释来进行训练。具体来说,我们可以为每个支持图像获得基于超像素的伪标签。然后,我们对支持图像和掩码进行几何和强度变换,以获得相应的查询图像和掩码(对于掩码,我们只应用几何变换)。之后,将获得的支持和查询图像及其相关的掩码输入到我们的网络中,用于端训练。训练后,对于每个测试事件,将支持图像及其手动注释一起输入到我们训练的模型中,以预测查询图像的分割
实验结果
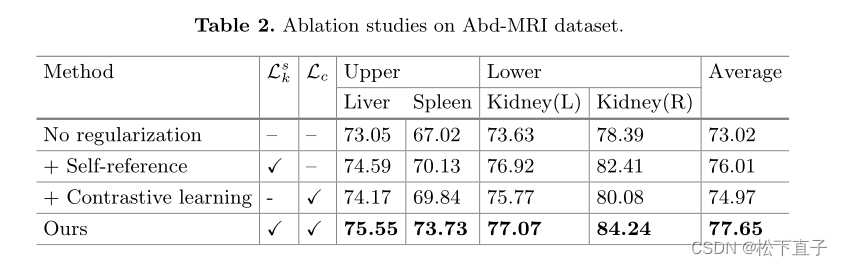
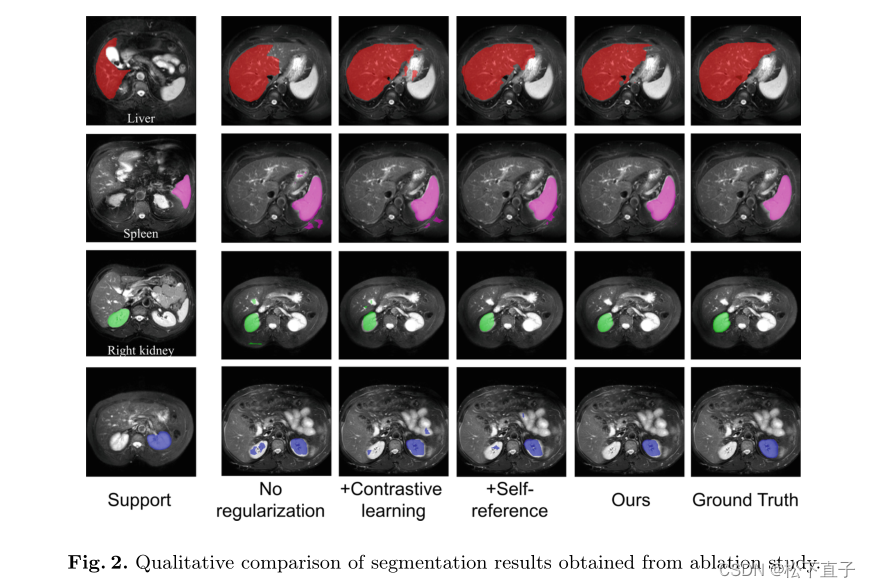







![[JAVA数据结构]堆](https://img-blog.csdnimg.cn/d397a5a0e2444038bf048690b33f674c.png)