Redis进阶

Redis事务_事务的概念与ACID特性
Redis的事物不保证原子性
数据库层面事务
在数据库层面,事务是指一组操作,这些操作要么全都被成功执行,要么全都不执行。
数据库事务的四大特性
A:Atomic,原子性,将所有SQL作为原子工作单元执行,要么全部执行,要么全部不执行;
C:Consistent,一致性,事务完成后,所有数据的状态都是一致的,即A账户只要减去了100,B账户则必定加上了100;
I:Isolation,隔离性,如果有多个事务并发执行,每个事务作出的修改必须与其他事务隔离;
D:Duration,持久性,即事务完成后,对数据库数据的修改被持久化存储。
Redis事务
Redis事务是一组命令的集合,一个事务中的所有命令都将被序列化,按照一次性、顺序性、排他性的执行一系列的命令。

Redis事务三大特性
1. 单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断;
2. 没有隔离级别的概念:队列中的命令没有提交之前都不会实际的被执行,因为事务提交前任何指令都不会被实际执行,也就不存在”事务内的查询要看到事务里的更新,在事务外查询不能看到”。
3. 不保证原子性:redis同一个事务中如果有一条命令执行失败,其后的命令仍然会被执行,没有回滚
Redis事务执行的三个阶段:
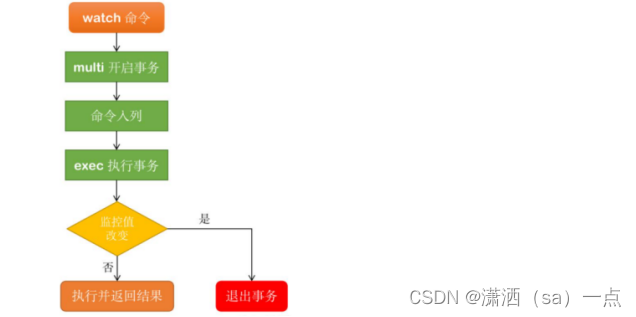
开启:以 MULTI 开始一个事务;
入队:将多个命令入队到事务中,接到这些命令并不会立即执行,而是放到等待执行的事务队列里面;
执行:由 EXEC 命令触发事务;
Redis事务基本操作:

Multi、Exec、discard 事务从输入Multi命令开始,输入的命令都会依次压入命令缓冲队列中,并不会执行,直到输入Exec后, Redis会将之前的命令缓冲队列中的命令依次执行。组队过程中,可以通过discard来放弃组队。
下面进行命令的执行操作
正常的事物的操作

不正常的操作:取消事物操作(discard)

还有一种情况如果我们操作语法不当,会造成事物中的所有操作都失败:

还有一种情况是在整个事物中哪一个命令出错哪个命令不能执行成功
注意:运行时错误,即非语法错误,正确命令都会执行,错误命令返回错误

Redis集群_Cluster模式概述:

Redis有三种集群模式
主从模式
Sentinel模式
Cluster模式
哨兵模式的缺点:

缺点:
当master挂掉的时候,sentinel 会选举出来一个 master,选举的时候是没有办法去访问Redis的,会存在访问瞬断的情况;
哨兵模式,对外只有master节点可以写,slave节点只能用于读。尽管Redis单节点最多支持10W的QPS,但是在电商大促的时候,写数据的压力全部在master上;
Redis的单节点内存不能设置过大,若数据过大在主从同步将会很慢;在节点启动的时候,时间特别长;
Cluster模式概述:

Redis集群是一个由多个主从节点群组成的分布式服务集群,它具有复制、高可用和分片特性
Redis集群的优点
Redis集群有多个master,可以减小访问瞬断问题的影响
Redis集群有多个master,可以提供更高的并发量
Redis集群可以分片存储,这样就可以存储更多的数据
Redis集群_Cluster模式搭建

Redis的集群搭建最少需要3个master节点,我们这里搭建3个master,每个下面挂一个slave节点,总 共6个Redis节点;

环境准备:
第1台机器:192.168.205.130 8001端口 8002端口
第2台机器:192.168.205.129 8001端口 8002端口
第3台机器:192.168.205.131 8001端口 8002端口
我们先在第1台机器上进行操作即可,然后我们克隆服务器过去就可以了
在目录/usr/local下上传我们redis文件redis-6.2.6.tar.gz
通过rz命令上传
然后我们通过 tar –zxvf redis-6.2.6.tar.gz 对redis文件进行解压缩
如果没有安装gcc先安装yum install gcc
进入到redis的目录cd redis-6.2.6/
使用make命令进行安装
安装完成抽使用mv命令进行移动:
mv redis-6.2.6 redis 把文件移动到redis中
然后创建文件夹:
| mkdir -p /usr/local/redis/redis-cluster/8001 /usr/local/redis/redis-cluster/8002 |
拷贝配置文件
将redis安装目录下的 redis.conf 文件分别拷贝到8001目录下
| cp /usr/local/redis/redis.conf /usr/local/redis/redis-cluster/8001 |
修改redis.conf文件以下内容
| port 8001 daemonize yes pidfile "/var/run/redis_8001.pid" #指定数据文件存放位置,必须要指定不同的目录位置,不然会丢失数据 dir /usr/local/redis/redis-cluster/8001/ #启动集群模式 cluster-enabled yes #集群节点信息文件,这里800x最好和port对应上 cluster-config-file nodes-8001.conf # 节点离线的超时时间 cluster-node-timeout 5000 #去掉bind绑定访问ip信息 #bind 127.0.0.1 #关闭保护模式 protected-mode no #启动AOF文件 appendonly yes #如果要设置密码需要增加如下配置: #设置redis访问密码 #requirepass 123 #设置集群节点间访问密码,跟上面一致 #masterauth 123 |
对上面内容挨个搜索进行修改,修改完成后保存并退出即可
文件拷贝到8002文件夹
| cp /usr/local/redis/redis-cluster/8001/redis.conf /usr/local/redis/redis-cluster/800 |
进入到8002目录修改redis.conf
我在配置文件中进行全局修改即可
在编辑模式下输入:%s/8001/8002/g
然后保存并退出即可
然后我们把防火墙全部关闭掉即可:
| systemctl stop firewalld.service systemctl disable firewalld.service |
操作完成后我们先把第1台服务器关机进行克隆操作,然后我们同时启动就可以了
我们进入到redis目录的src目录进行启动
在xshell中的左下角有个全部回话同时发布命令操作3台服务器启动redis即可
操作:


cd etc
vim hostname //修改名
下面所有命令都要进行全部会话操作
首先进入到src目录,然后输入下面的命令
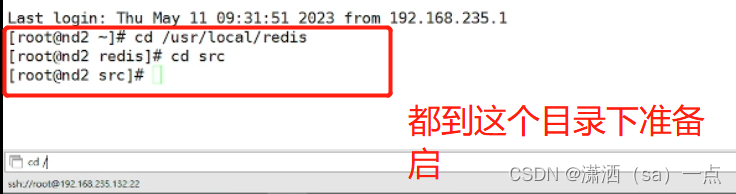
输入命令:
| 启动8001 ./redis-server ../redis-cluster/8001/redis.conf 启动8002 ./redis-server ../redis-cluster/8002/redis.conf |
查看3台服务器的redis是否运行:

至此我们的环境基本准备完成
当然我们在准备环境的时候也可以进行把文件拷贝的操作第1台服务的redis拷贝到第2台和第3台服务
| # 第二台机器 scp /usr1/redis/redis-cluster/8001/redis.conf root@192.168.205.129:/usr1/redis/redis-cluster/8001/ scp /usr1/redis/redis-cluster/8002/redis.conf root@192.168.205.129:/usr1/redis/redis-cluster/8002/ # 第三台机器 scp /usr1/redis/redis-cluster/8001/redis.conf root@192.168.205.131:/usr1/redis/redis-cluster/8001/ scp /usr1/redis/redis-cluster/8002/redis.conf root@192.168.205.131:/usr1/redis/redis-cluster/8002/ |
换上自己的ip
然后通过命令构建集群
注意:这里一定要把 hostname下的主机名称改掉否则不能构建集群
在第一台服务器上进行操作:
| 在src目录下完成 完整写法 ./redis-cli -a 123 --cluster create --cluster-replicas 1 192.168.205.130:8001 192.168.205.130:8002 192.168.205.129:8001 192.168.205.129:8002 192.168.205.131:8001 192.168.205.131:8002 不需要密码写法 ./redis-cli --cluster create --cluster-replicas 1 192.168.205.130:8001 192.168.205.130:8002 192.168.205.129:8001 192.168.205.129:8002 192.168.205.131:8001 192.168.205.131:8002 |
回车即可:

输入yes即可

说明集群创建成功
下面我们进入客户端,输入命令:
| ./redis-cli -c -h 192.168.205.130 -p 8001 |

查看集群状态:cluster info命令、

Redis集群_Cluster模式原理分析:

Redis Cluster将所有数据划分为16384个slots(槽位),每个节点负责其中一部分槽位。槽位的信息存储 于每个节点中。只有master节点会被分配槽位,slave节点不会分配槽位。
PS:
| 槽位定位算法: k1 = 127001 Cluster 默认会对 key 值使用 crc16 算法进行 hash 得到一个整数值,然后用这个整数值对 16384 进行取模来得到具体槽位。 HASH_SLOT = CRC16(key) % 16384 |
槽位主要是负责把数据保存到哪里服务集群中,或者提取数据时去哪个槽位中去获取数据从而分摊了服务器器的压力
在我们插入数据的时候就会返回我们插入数据所对应的槽位数据
如添加数据 set k1 v1

| 根据k1计算出的槽值进行切换节点,并存入数据。不在一个slot下的键值,是不能使用mget、 mset等多建操作。 |
我们可以通过{}来定义组的概念,从而是key中{}内相同内容的键值对放到同一个slot中。
| mset k1{test} v1 k2{test} v2 k3{test} v3 |
故障恢复
查看节点:
| 192.168.205.131:8001> cluster nodes |

我们看到上面的节点中有3台master和3台slave节点
比如我们现在想要一个干掉一个主节点,看看他是否给我们在找一个主节点:
Ctrl + c 退出客户端
输入命令lsof -i:8001

输入命令:kill -9 17696
然后切换到第2台服务器输入命令再次进入客户端: ./redis-cli -c -h 192.168.205.129 -p 8001
输入命令:cluster info

输入命令:cluster nodes

Redis集群_Java操作Redis集群

创建项目:

Jedis整合Redis
引入jedis的maven坐标:
| <?xml version="1.0" encoding="UTF-8"?> |
代码进行测试:
| package com.vv.demo; |

SpringBoot 整合 Redis

引入坐标:
| <dependency> |
application.properties:
| ##单服务器 192.168.205.133:8001,192.168.205.133:8002 |
创建controller进行测试即可:
| package com.vv.demo.controller; |

Redis企业级解决方案_Redis脑裂:
什么是Redis的集群脑裂
Redis的集群脑裂是指因为网络问题,导致Redis Master节点跟Redis slave节点和Sentinel集群处于不同
的网络分区,此时因为sentinel集群无法感知到master的存在,所以将slave节点提升为master节点。

注意:
此时存在两个不同的master节点,就像一个大脑分裂成了两个。集群脑裂问题中,如果客户端还在基于原来的master节点继续写入数据,那么新的Master节点将无法同步这些数据,当网络问题解决之后,sentinel集群将原先的Master节点降为slave节点,此时再从新的master中同步数据,将会造成大量的数据丢失。
解决方案 redis.conf配置参数:
| min-replicas-to-write 1 min-replicas-max-lag 5 参数: 第一个参数表示最少的slave节点为1个 第二个参数表示数据复制和同步的延迟不能超过5秒 配置了这两个参数:如果发生脑裂原Master会在客户端写入操作的时候拒绝请求。这样可以避免大量数据丢失。 |
Redis企业级解决方案_缓存预热
缓存冷启动:
缓存中没有数据,由于缓存冷启动一点数据都没有,如果直接就对外提供服务了,那么并发量上来 Mysql就裸奔挂掉了。
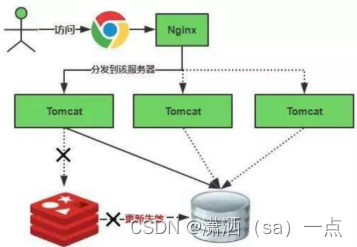
缓存冷启动场景:
新启动的系统没有任何缓存数据,在缓存重建数据的过程中,系统性能和数据库负载都不太好,所以最 好是在系统上线之前就把要缓存的热点数据加载到缓存中,这种缓存预加载手段就是缓存预热。

解决思路:
提前给redis中灌入部分数据,再提供服务如果数据量非常大,就不可能将所有数据都写入redis,因为数据量太大了,第一是因为耗费的时间太长了,第二根本redis容纳不下所有的数据需要根据当天的具体访问情况,实时统计出访问频率较高的热数据然后将访问频率较高的热数据写入redis中,肯定是热数据也比较多,我们也得多个服务并行数据去写,并行的分布式的缓存预热

Redis企业级解决方案_缓存穿透:

概念
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。

解释:
缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时 候,在缓存中找不到,每次都要去数据库再查询一遍,然后返回空(相当于进行了两次无用的查 询)。这样请求就绕过缓存直接查数据库,这也是经常提的缓存命中率问题。
解决方案
1. 对空值缓存:如果一个查询返回的数据为空(不管数据是否存在),我们仍然把这个空结果缓存,设置空结果的过期时间会很短,最长不超过5分钟。
2. 布隆过滤器:如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定。
布隆过滤器
什么是布隆过滤器
布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效 地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。【可以处理上亿甚至几十亿的数据】

注意:
布隆说不存在一定不存在,布隆说存在你要小心了,它有可能不存在
代码实现:
引入hutool包:
| <dependency> |
测试:
| package com.vv.demo; |
Redis企业级解决方案_缓存击穿

概念
某一个热点 key,在缓存过期的一瞬间,同时有大量的请求打进来,由于此时缓存过期了,所以请求最 终都会走到数据库,造成瞬时数据库请求量大、压力骤增,甚至可能打垮数据库。
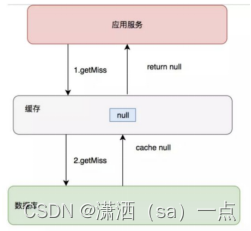
解决方案
1. 互斥锁:在并发的多个请求中,只有第一个请求线程能拿到锁并执行数据库查询操作,其他的线程拿不到锁就阻塞等着,等到第一个线程将数据写入缓存后,其他线程直接查询缓存。
2. 热点数据不过期:直接将缓存设置为不过期,然后由定时任务去异步加载数据,更新缓存
代码实现:
| private Jedis jedis; |
Redis企业级解决方案_缓存雪崩
概念
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。
缓存正常从Redis中获取,示意图如下:

缓存失效瞬间示意图如下:

解决方案
过期时间打散:既然是大量缓存集中失效,那最容易想到就是让他们不集中失效。可以给缓存的过期时间时加上一个随机值时间,使得每个 key 的过期时间分布开来,不会集中在同一时刻失效。
热点数据不过期:该方式和缓存击穿一样,也是要着重考虑刷新的时间间隔和数据异常如何处理的情况。
加互斥锁: 该方式和缓存击穿一样,按 key 维度加锁,对于同一个 key,只允许一个线程去计算, 其他线程原地阻塞等待第一个线程的计算结果,然后直接走缓存即可。
加锁排队代码如下:
| public Object GetProductListNew(String cacheKey) { |




![[JAVA数据结构]堆](https://img-blog.csdnimg.cn/d397a5a0e2444038bf048690b33f674c.png)