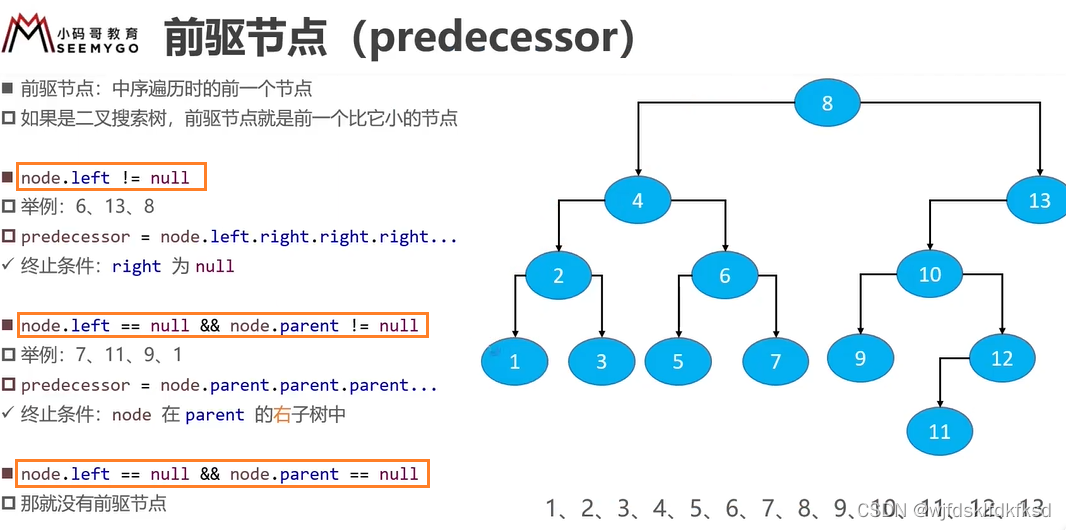
Redis分布式锁
单机版 关于 synchronized 和trylock的区别
前者 是 不见不散 我一定要等到你
后者是 过时不候 我尝试一下 获取不到就算了 可以设置一个时间 这个时间范围内获取不到就算了
用缓存两个目的:高性能与高并发
高性能:减少了查询时间,比如一些热点数据就可以放进缓存中。
高并发:数据库承载的请求过多可能会宕机, 我们可以把一些热点数据放进缓存中,用户查询 某条数据,如果缓存中有,就直接从缓存中拿,没有再查数据库,这样就为数据库分担了很多请求
缓存天然就可以支撑高并发 因为缓存是基于内存的
Redis与Memcached有什么区别?为什么单线程的redis比多线程的memcached效率高得多?
1.redis拥有的数据类型和操作更多
2.内存使用效率,redis更高,他是基于key-value来存储的
3.集群模式 memcached没有原生的集群模式
4.redis是单线程 memcached是多线程
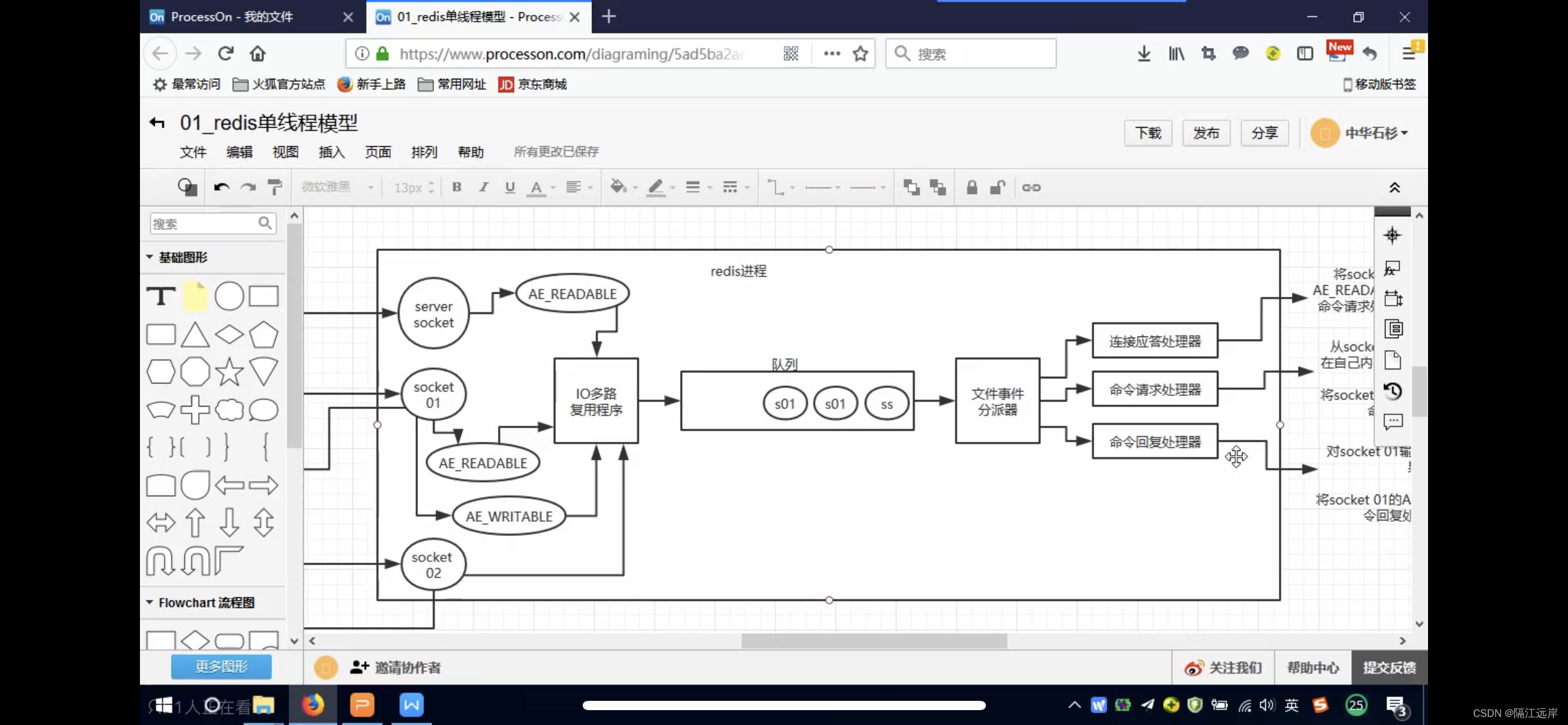
Redis线程模型:
文件事件处理器:
客户端与redis通信的流程:就是每个客户端都通过一个soket来与redis建立通信,通过IO多路复用程序来将请求压入队列,然后redis一个个去处理这些请求
为什么能支撑高并发? 一秒钟可以处理一万个请求
1.是非阻塞的IO多路复用模型,它监听到请求并不直接处理,而是将请求压入队列
2.文件事件分派器是基于纯内存的 单线程反而避免了多线程的频繁上下文切换问题
Redis分别在哪些场景下比较合适?
比如他的list数据类型,可以用来存储 key为某个大V的名字,value为{zhangsan,lisi}他的粉丝
set
可以玩交集并集这些 看两个人的共同好友
sorttedset 去重并且可以排序
可以做排行榜
redis的过期策略,能不能手写一个LRU代码?
内存中的数据过多,redis会自动把一些数据干掉。
定期删除与惰性删除
定期删除:他会每隔一段时间去检查哪些数据过期了 然后将其删除
惰性删除:不是key到时见就会被删除掉,而是你查询这个key的时候,redis再懒惰的检查一下
通过这两种来保证过期key一定被删除。
为什么会出现,很多键过期了但是内存依然被大量占用呢?
这就说明很多key没有靠定期删除给删除掉,还停留在内存中,占用着内存,除非你的系统去查一下那个key,才会被redis删除掉
如果定期删除漏掉了很多过期key,然后你也没有及时去查,也就没走惰性删除,此时可能会导致大量过期key堆积,导致redis内存块耗尽了
走内存淘汰机制!
如果redis内存占用过多,会进行内存淘汰,有以下机制:
比如 移除最近使用最少的key
手写lru(内存淘汰机制)算法:

怎么保证Redis高并发与高可用?
Redos跟整个系统的高并发关联性是非常大的
redis不能支撑高并发的瓶颈是在哪?
单机redis最多承载的qps大概在上万到几万不等,如果说你单机模式下,你的客户量是上千万,那直接一下就把redis给打死了。
单机不太可能超过十万。
高可用(持久化)
Redis replication->主从架构->读写分离->水平扩容支撑读高并发
master持久化:一个master是可以配置多个slave的
redis会异步的复制数据到slave节点,slave会周期性的确认自己每次复制的数据量
slave 在做复制的时候 并不会阻塞maser的正常工作 也不会阻塞掉对自己的查询,他会用旧的数据集来提供服务,复制完成后会删除旧的数据集,加载新数据集,这个过程会暂停服务
slave主要是来做读写分离和横向扩容。
对于主从架构来说,master是必须要做持久化的,因为如果不做持久化,一但master宕机,是没有本地数据可以恢复的,会认为自己的数据是空的,然后slave也会在master上去拉取空数据
造成100%的数据丢失
slave复制master的过程:
第一次是生成一个RDB快照,slave会先将其写入磁盘,然后从磁盘中加载到内存中。
后面master收到一条写命令就会发一条给slave同步
主从复制的断点续传:可以接着上一次复制的地方,继续复制下去
因为master 会在内存中存储一个backlog,这里面记录了上次传到了哪个位置
如果找不到对应的offeset 也就是上次传到的位置,那么会执行一次全量复制
无磁盘化复制:master在内存中直接创建rdb,然后发送给slave,不会自己本地落地磁盘了
过期key处理:slave不会过期key,如果master过期了一个key,或者通过lru淘汰了一个key,那么会模拟一条del命令发送给slave
masternode与slaveNode之间有心跳检测机制
Redis怎么做到高可用?
sentinal node 哨兵 会自动监测master有没有挂 如果过了会将slave node变成master node
通过哨兵来完成redis高可用 是redis中一个很关键的组件
不能保证数据零丢失 但是可以保证redis集群的高可用性
经典的3节点哨兵集群
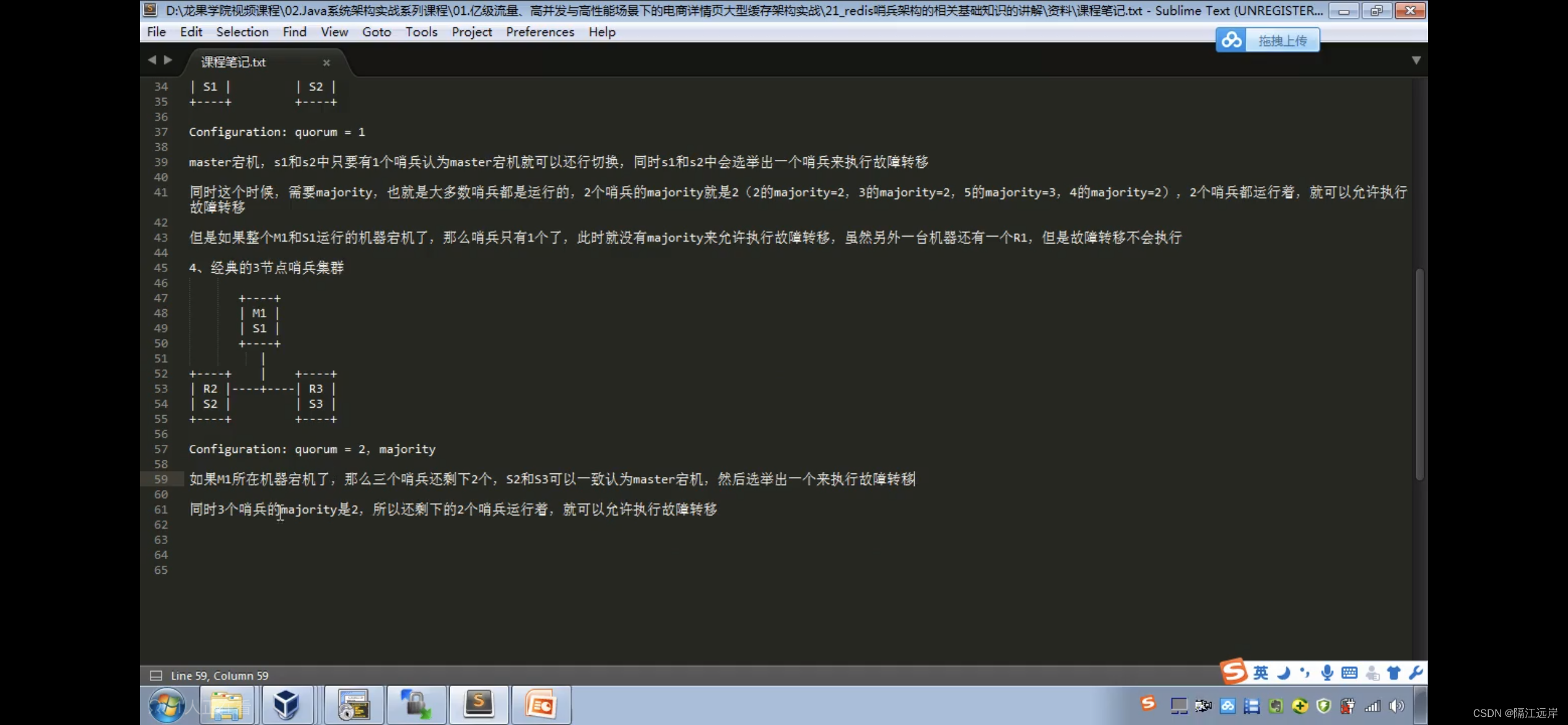
Redis主备切换时数据丢失问题:异步复制、集群脑裂
异步复制:有部分数据还没有复制到slave master就宕机了,此时这部分数据就丢失了
集群脑裂:master其实并没有死,但是因为网络问题,哨兵很长时间没有检测到master,从而选举了新的master 导致此时存在两个master
大脑一分为二,都想指挥同一个人。
但是因为原本的masterNode是接收了客户端数据的,当网络恢复后,他变成了slave节点,所以这一块数据丢失了
怎么解决?
两个参数,要求至少有一个slave,数据复制和同步的延迟不能超过10秒,如果说一但所有slave 数据复制与同步的延迟超过十秒,那么这个时候master不会接收任何请求了
然后这些请求会放到一个地方暂存
这样就解决了异步复制和脑裂问题
Redis哨兵多个底层原理
Sdown 主观宕机 只有一个哨兵觉得一个master宕机了
Odown 客观宕机 quorum数量的哨兵觉得一个master宕机了
slave->master选举算法
1跟master连接断开时长
2slave优先级
3复制offeset
4run id
怎么保证redis持久化?
Redis持久化主要在于故障恢复
通过持久化搞一份儿在磁盘上,定期同步和备份到一些云存储服务器上去,那么就不会导致数据的全部丢失,只是丢失部分数据
RDB与AOF两种持久化机制的工作原理?
RDB是定期生成内存中的一份完整快照,有可能是几分钟也可能是几小时
AOF呢,redis中每拿到一条数据就往内存中写 首先是存到os cache 然后每隔一秒调用一次操作系统中fsync操作,强制将oscache中的数据刷到磁盘文件中
redis不是会有lru缓存清除算法么 可能redis中清除了50万 变成100w 但是此时AOF中还是150万
那么此时会执行rewrite操作 重新生成一个AOF,这个AOF存的是redis现在的100w条数据,而旧的AOF就废弃掉了
RDB是一次性 AOF是追加
AOF保存的数据更加完整
-RDB容易导致几分钟到几小时的数据丢失 但是他可以保证Redis的性能是最高的
RDB每次写都是写进Redis内存的 只是在一定的时候才会将数据写入到磁盘中
AOF 每次都是要写文件的,虽然可以快速写进os cache中 但是速度还是比RDB慢 会导致Redis支持的写qps更低 存储的数据量太大了 比较大的缺点是做数据恢复的时候比较慢,还有做冷备,定期的备份不太方便,可能要自己手写复杂的脚本去做
RDB与AOF如何选择:可以两种都开启。AOF来保证数据不丢失,作为数据恢复的第一选择。RDB来做不同程度的冷备,在AOF文件都丢失或者损坏不可用的时候,还可以用RDB来进行快速数据恢复
Redis集群模式的工作原理
如果要支撑更大的数据量缓存,那就横向扩容更多master节点
如果数据量很大 就用redis cluster
数据量并没有那么大 那么 一主多从加上sentinal集群即可
那么现在如果有三个master 那数据要如何分布呢?
数据分布算法:最简单的就是取模 会导致大部分请求全部无法拿到有效缓存
一致性hash算法(自动缓存迁移->某个master如果宕机 顺时针找完所有master节点后,那些请求会涌入数据库中来处理)+虚拟节点(自动负载均衡 )
缓存热点问题:涌入某个master的数据特别多 ->解决:可以给每个master都做均匀分布的虚拟节点比如 1附近有2和3的虚拟节点 这样就保证了123是平均承载请求的。在每个区间内,都会均匀的分布到不同的节点上,而不是按照顺时针的顺序去走,全部涌入同一个master内
hash slot算法 总共有一万六千多个slot 然后三个master的话 可能每个会有五千多个slot 一个key来了之后 取模之后其实是去找对应的hashslot 任何一台机器宕机,另外两个节点不受影响,因为key找的是hash slot,找的不是机器 如果某个master宕机,客户端发请求时,另外两个master会完成slot迁移,会在某个master上重新生成该slot
Redis cluster核心原理
redis cluster节点间通信采取gossip协议,小道流言
所有节点都持有一份元数据,不同的节点如果出现了元数据的变更之后,会不断将元数据发送给其他节点,让其他节点也进行元数据的变更
集中式的优点是 时效性非常好,一但元数据发生变更,立即就会更新到集中式的存储中,其他节点读取的时候立刻就可以感知到 缺点是所有元数据更新压力都集中在一个地方,可能会导致元数据的存储有压力
gossip 小道流言的好处是元数据更新比较分散,更新请求陆陆续续,打到所有节点上去更新,有一定延迟,降低了压力。 缺点:元数据更新有延迟,可能导致集群一些操作滞后
面向集群的jedis内部实现原理:
jedis就是redus的java client客户端
基于重定向的客户端,客户端可能会挑选任意一个redis实例去发送命令,如果计算key对应的hashslot 如果有 就在本地处理 找不到就重定向 同一个hashtag 会在同一个hashslot中
想Jedis这种客户端一般用的都是smart模式 因为重定向很耗费网络IO,所以它会在本地维护一个hashslot ->node的映射表 大部分情况下 只需要直接走本地缓存就可以找到对应的 node 不需要进行moved重定向
jedis cluster初始化的时候,首先会随机选择一个node,初始化hashslot表,同时为每个节点创建一个jedispool连接池,每次基于jedisCluster执行操作
反正它会不断更新它所维护的映射表 ,以保证下一次查询的准确性
高可用与主备切换原理:
判断节点宕机:与哨兵非常相似,有主观宕机和客观宕机 一个认为是主观宕机,多个认为是客观宕机,如果一个节点认为某个节点宕机了,就会在gossip ping命令中,ping给其他节点,如果超过半数认为其宕机了,那么他就会变成fail
从节点过滤:断开连接时间过长就没有资格切换成主节点
从节点选举:根据对自己master复制数据的offset来,offeset越大,选举时间越靠前,优先进行选举。所有的master来对slave进行选举,如果大部分(N/2+1)都投给了投个节点,那么通过
如何应对缓存雪崩与缓存穿透?
雪崩:缓存宕机,请求全落到数据库 数据库瞬间挂掉
解决不了 ,只能缓解:1.缓存必须是高可用 配置高可用缓存架构 redis cluster 多主多从
2.系统内部做一个缓存 ehcache
3.做限流与降级限流:本来每秒5000 现在只有2000个进来 进入数据库 降级:返回一些默认的值 至少保证系统不死
4.Redis必须做持久化
穿透:发来5000请求,这5000个请求只有1000个是正常请求,另外四千个缓存中找不到,直接穿透了缓存 就发给数据库里,而数据库中也没有, 那么一下就把数据库打死了
解决:只要数据库中没查到值,就在缓存中写一个key相同,而值为undefined的这样一个值
所以下次来查的时候就可以直接在缓存中拿到
如何保证数据库和缓存双写的一致性问题?
cache aside pattern
读的时候先读缓存,再读数据库,取到后放入缓存
更新的时候先更新
读写并发情况也可能导致缓存出现问题:解决 让读写异步 :让读请求串行化,首先是在更新数据库的之前会删掉缓存嘛,然后删的同时也有人在读,此时我让读现在库存服务里面排队,等数据库里面数据更新了以后再去读并且更新缓存中的数据
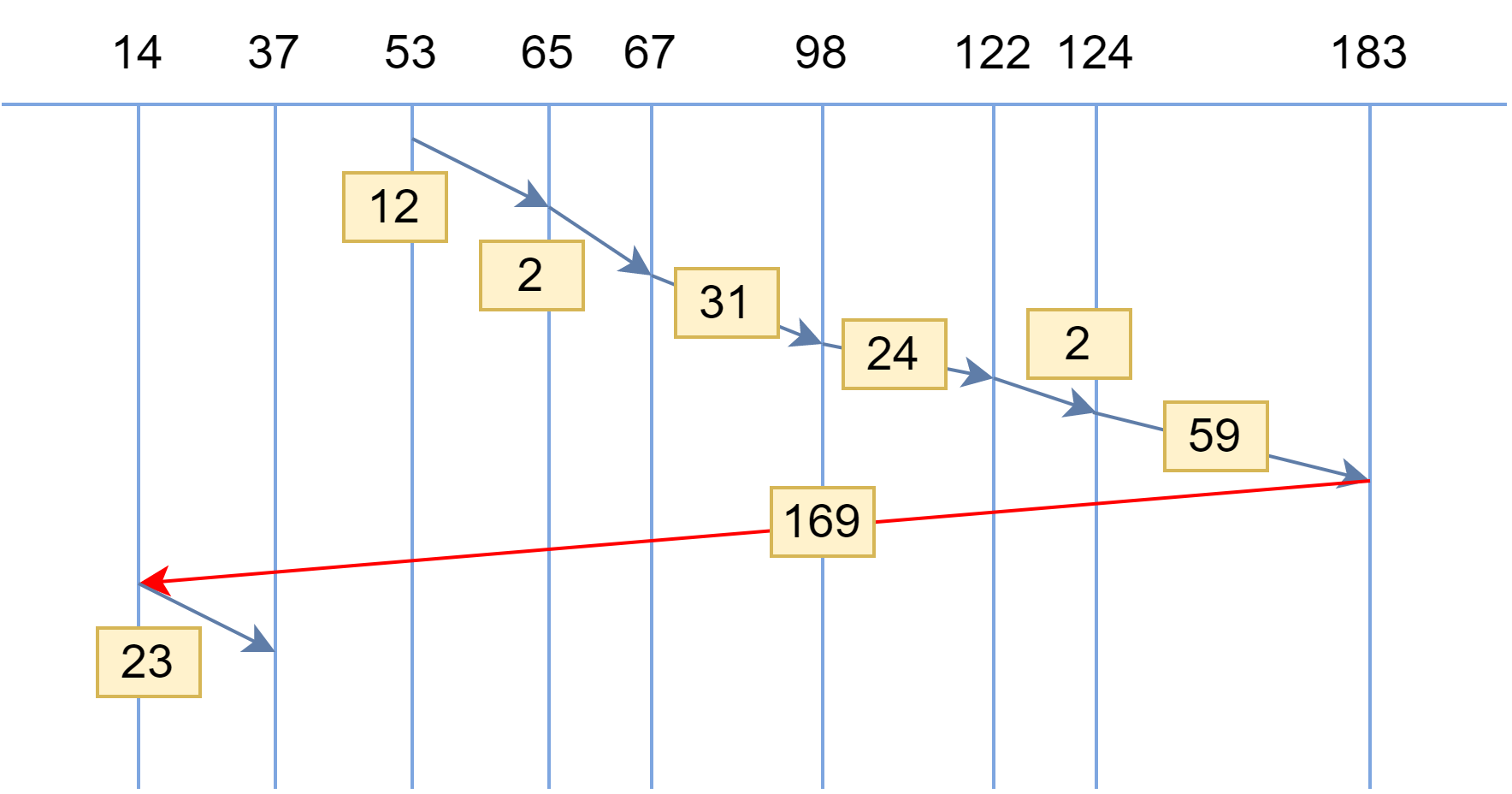
队列排重优化 --------------- 超时(TP99 200ms)直接返回数据库请求
Redis并发竞争:
分布式锁,一个一个来获取锁
你要写入缓存的数据,都是从mysql中查出来的,都得写入mysql中,写入mysql中的时候必须保存一个时间戳,从mysql查出来的时候,时间戳也查出来。 每次在写之前,先判断当前value的时间戳是否比缓存中的value要新,更新的话就可以写 如果更旧,就不能用旧数据覆盖新数据
Redis集群架构师怎么部署的?
说一下线上的情况