目录
一、混淆矩阵
二、分类指标
1、Accuracy(准确率)
2、Precision(查准率)
3、Recall (查全率)
4、F1-score
三、语义分割的评价指标
1、MPA(类别平均像素准确率)
2、IoU(交并比)
3、MIoU(平均交并比)
4、CPA(类别像素准确率)
5、PA(像素准确率)
四、代码实现(基于混淆矩阵)
一、混淆矩阵
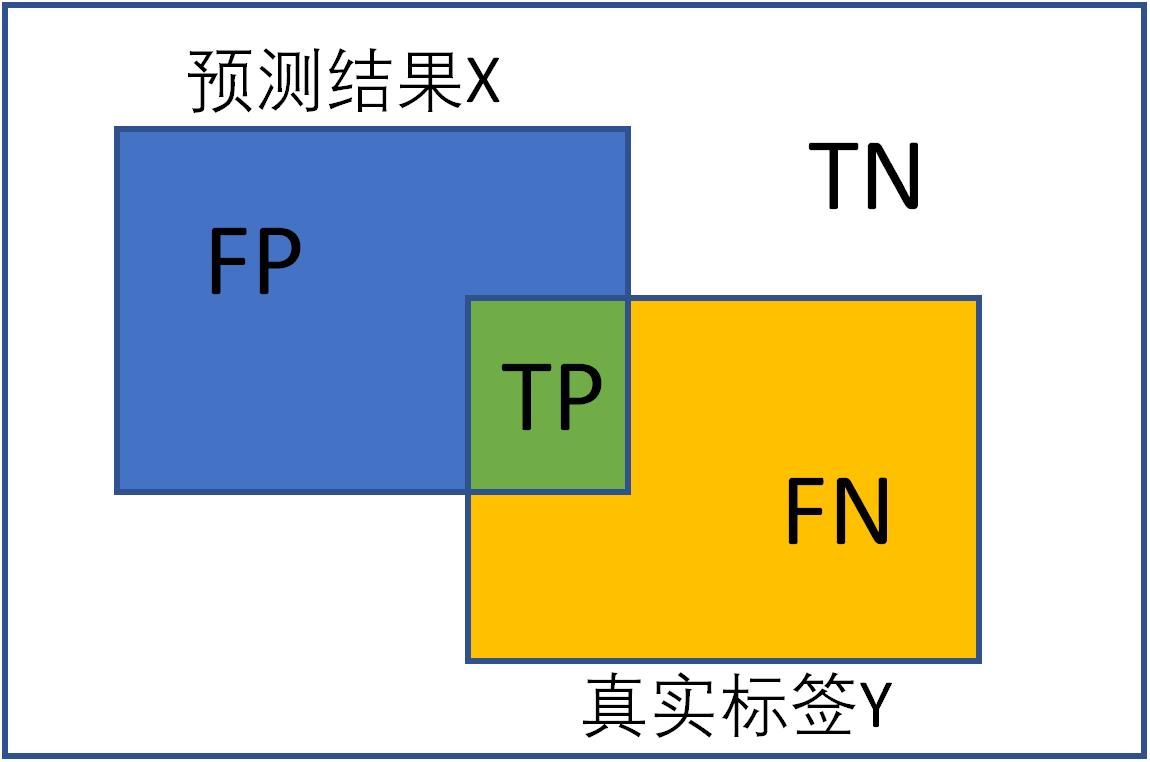
混淆矩阵(confusion matrix)是一种特定的矩阵用来呈现算法性能的可视化效果,其每一列代表预测值,每一行代表的是实际的类别。这个名字来源于它可以非常容易的表明多个类别是否有混淆(也就是一个class被预测成另一个class)。下面是二分类的混淆矩阵:

预测值与真实值相同为True,反之则为False。混淆矩阵的对角线是判断正确的,期望TP和TN越大越好,FN和FP越小越好。
二、分类指标
1、Accuracy(准确率)
表示预测正确的样本数量占全部样本的百分比。

缺点:当数据类别分布不平衡时,不能评价模型的好坏。
2、Precision(查准率)
表示模型预测为正例的所有样本中,预测正确(真实标签为正)样本的占比:

3、Recall (查全率)
表示所有真实标签为正的样本,有多大百分比被预测出来

4、F1-score
表示precision和recall的调和平均数,具体公式如下:

三、语义分割的评价指标
1、MPA(类别平均像素准确率)
所有类别像素准确率之和的平均。首先求得每个类别的像素准确率,然后对它们求和再平均。

2、IoU(交并比)
IoU(Intersection-over-Union)即是预测样本和实际样本的交并比,表达式如下:

3、MIoU(平均交并比)
Mean IoU是在所有类别的IoU上取平均值。
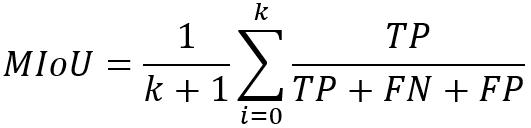
4、CPA(类别像素准确率)
类别像素准确率,是一种衡量每个类别中正确分类像素占该类别总像素数的比例。CPA等于混淆矩阵中第i行第i列元素除以混淆矩阵中第i行所有元素之和。
5、PA(像素准确率)
像素准确率,是一种衡量分割结果中正确分类像素占总像素数的比例。PA等于混淆矩阵中对角线元素之和除以混淆矩阵中所有元素之和。
四、代码实现(基于混淆矩阵)
import numpy as np
from collections import Counter
# 计算混淆矩阵
def cal_confu_matrix(label, predict, class_num):
confu_list = []
for i in range(class_num):
c = Counter(predict[np.where(label == i)])
single_row = []
for j in range(class_num):
single_row.append(c[j])
confu_list.append(single_row)
return np.array(confu_list).astype(np.int32)
# 计算指标
def metrics(confu_mat_total, save_path=None):
'''
:param confu_mat: 总的混淆矩阵
save_path:保存txt的路径
:return: txt写出指标
'''
class_num = confu_mat_total.shape[0]
confu_mat = confu_mat_total.astype(np.float32)
col_sum = np.sum(confu_mat, axis=1) # 按行求和
raw_sum = np.sum(confu_mat, axis=0) # 每一列的数量
pe_fz = 0
PA = 0 # 像素准确率
CPA = [] # 类别像素准确率
TP = [] # 识别中每类分类正确的个数
for i in range(class_num):
pe_fz += col_sum[i] * raw_sum[i]
PA = PA + confu_mat[i, i]
CPA.append(confu_mat[i, i]/col_sum[i])
TP.append(confu_mat[i, i])
pe = pe_fz / (np.sum(confu_mat) * np.sum(confu_mat))
kappa = (PA - pe) / (1 - pe) # Kappa系数
PA = PA / confu_mat.sum()
CPA = np.array(CPA)
MPA = np.mean(CPA) # 类别平均像素准确率
# 计算f1-score
TP = np.array(TP)
FN = col_sum - TP
FP = raw_sum - TP
# 计算并写出f1_score,IOU,Mf1,MIOU
f1_score = [] # 每个类别的f1_score
IOU = [] # 每个类别的IOU
for i in range(class_num):
# 写出f1-score
f1 = TP[i] * 2 / (TP[i] * 2 + FP[i] + FN[i])
f1_score.append(f1)
iou = TP[i] / (TP[i] + FP[i] + FN[i])
IOU.append(iou)
f1_score = np.array(f1_score)
Mf1 = np.mean(f1_score) # f1_score的平均值
IOU = np.array(IOU)
MIOU = np.mean(IOU) # IOU的平均值
if save_path is not None:
with open(save_path + 'accuracy.txt', 'w') as f:
f.write('PA:\t%.4f\n' % (PA * 100))
f.write('kappa:\t%.4f\n' % (kappa * 100))
f.write('Mf1-score:\t%.4f\n' % (Mf1 * 100))
f.write('MIOU:\t%.4f\n' % (MIOU * 100))
# 写出f1-score
f.write('f1-score:\n')
for i in range(class_num):
f.write('%.4f\t' % (float(f1_score[i]) * 100))
f.write('\n')
# 写出 IOU
f.write('Iou:\n')
for i in range(class_num):
f.write('%.4f\t' % (float(IOU[i]) * 100))
f.write('\n')
# 写出MPA
f.write('MPA:\n')
for i in range(class_num):
f.write('%.4f\t' % (float(MPA[i]) * 100))
f.write('\n')
# 写出precision
f.write('precision:\n')
for i in range(class_num):
f.write('%.4f\t' % (float(TP[i] / raw_sum[i]) * 100))
f.write('\n')
# 写出recall
f.write('recall:\n')
for i in range(class_num):
f.write('%.4f\t' % (float(TP[i] / col_sum[i]) * 100))
f.write('\n')
if __name__ == '__main__':
y_test = np.array([0, 1, 1, 2, 2, 0, 0, 1, 2, 3, 3, 2, 3, 1, 0, 3, 1, 2, 3, 3, 2, 0, ])
y_predict = np.array([1, 1, 0, 2, 2, 2, 0, 2, 0, 3, 0, 2, 3, 1, 0, 2, 1, 2, 1, 3, 1, 3, ])
ma = cal_confu_matrix(y_test,y_predict,4)
metrics(ma,save_path="")