目录
- 1. 线程池和进程池解决的是调度问题
- 2. 线程池
- 3. 线程池实战:爬取西游记的标题
- 总结
欢迎关注 『python爬虫』 专栏,持续更新中
欢迎关注 『python爬虫』 专栏,持续更新中
1. 线程池和进程池解决的是调度问题
⽹站的数据太多了,有⼀万多⻚,⼀万多个url.,我们设计多线程的时候如果每个url对应⼀个线程就,会浪费资源,可能2个url对应一个线程,可能有些url爬取的数据少,3个url对应一个线程,这种调度的问题很麻烦。
线程池: 一次性开辟一些线程. 我们用户直接给线程池子提交任务. 线程任务的调度交给线程池来完成。
进程池的内容和线程池类似,下面只介绍线程池。
2. 线程池
# 线程池: 一次性开辟一些线程. 我们用户直接给线程池子提交任务. 线程任务的调度交给线程池来完成
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
def fn(name):
for i in range(1000):
print(name, i)
if __name__ == '__main__':
# 创建线程池
with ThreadPoolExecutor(50) as t:#50个线程
for i in range(100):#100个任务由线程池分配给50个线程执行
t.submit(fn, name=f"线程{i}")#把任务提交给线程池t
# 等待线程池中的任务全部执行完毕. 才继续执行(守护)
print("执行结束")
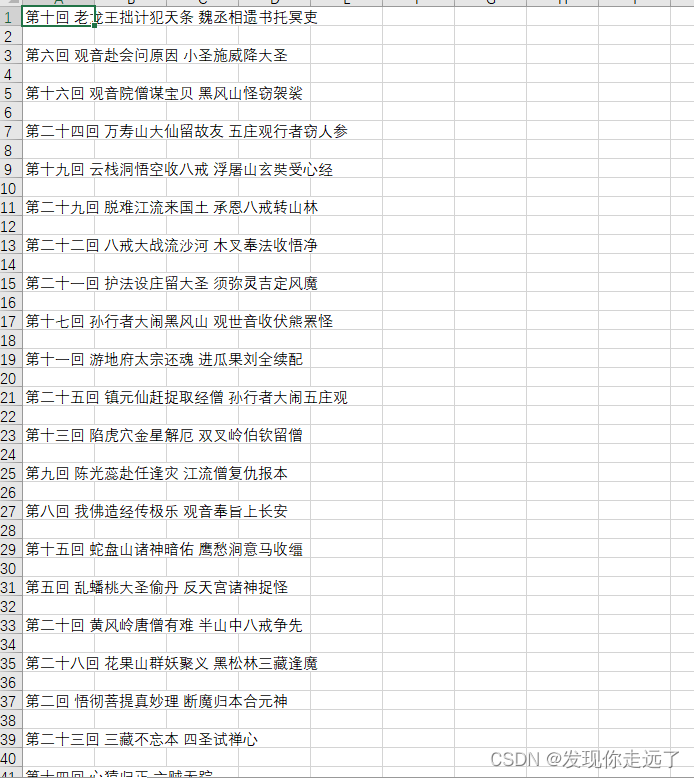
3. 线程池实战:爬取西游记的标题
其实这种有先后顺序要求的内容,线程池无法保证正确序列,还需要一些方法保证顺序,其实这里用线程池有点不恰当,仅供学习参考。
# 1. 如何提取单个页面的数据
# 2. 上线程池,多个页面同时抓取
import codecs
import requests
from lxml import etree
import csv
from concurrent.futures import ThreadPoolExecutor
f = open("data.csv", mode="w", encoding="gbk")#gbk防止乱码中文
csvwriter = csv.writer(f)
def download_one_page(url):
# 拿到页面源代码
resp = requests.get(url)
#print(resp.apparent_encoding)#utf-8
resp.encoding = "utf-8"#解析时得到的数据是utf-8
html = etree.HTML(resp.text)
title = html.xpath("/html/body/div[2]/div[1]/main/section/header/h2/text()")
print(title)
csvwriter.writerow(title)
print(url, "提取完毕!")
if __name__ == '__main__':
# for i in range(1, 14870): # 效率及其低下
# download_one_page(f"http://www.xinfadi.com.cn/marketanalysis/0/list/{i}.shtml")
# 创建线程池
with ThreadPoolExecutor(50) as t:
for i in range(0, 100): # 199 * 20 = 3980
# 把下载任务提交给线程池
t.submit(download_one_page, f"https://xiyouji.5000yan.com/{19830+i}.html")
print("全部下载完毕!")

总结
大家喜欢的话,给个👍,点个关注!给大家分享更多计算机专业学生的求学之路!
版权声明:
发现你走远了@mzh原创作品,转载必须标注原文链接
Copyright 2023 mzh
Crated:2023-3-1
欢迎关注 『python爬虫』 专栏,持续更新中
欢迎关注 『python爬虫』 专栏,持续更新中
『未完待续』