本文通过拆解原始问题、发散思路优化等方式,记录了扫一扫从单码到多码识别的技术框架改造及多码识别率优化方案。其中涉及解码SDK的能力、码处理技术链路、码转换算法、降低漏检率策略等设计与实现。

背景与挑战
多码即在同一个界面中同时存在多个条码或二维码, 其在现实场景中广泛存在,如服饰吊牌、饮料瓶身、快递单等。然而对于拍立淘的扫一扫场景来说,最初只支持单码能力,用户对于在多码场景识别到的是哪个码毫无感知,影响体验。基于上述现状,在淘宝现有的条件下,是否具备改造成识别多码的能力;进一步地,是否能够进行码位置的锚定,并将该能力同时应用于单码场景。

多码实现
要实现单码到多码的转变,需要从逻辑层、视图层进行重新设计。下面分别阐述。
▐ 逻辑层:单码识别到多码识别
我们通过对逻辑层梳理,把对单码的处理全部改为对码数组的依次处理。扫一扫解码层需要处理的内容如下,改动是由单数据处理切换为批量处理。在第五步中,因为在展示层后续需要有多码场景的展示,因此这里特地缓存了一帧当前帧。
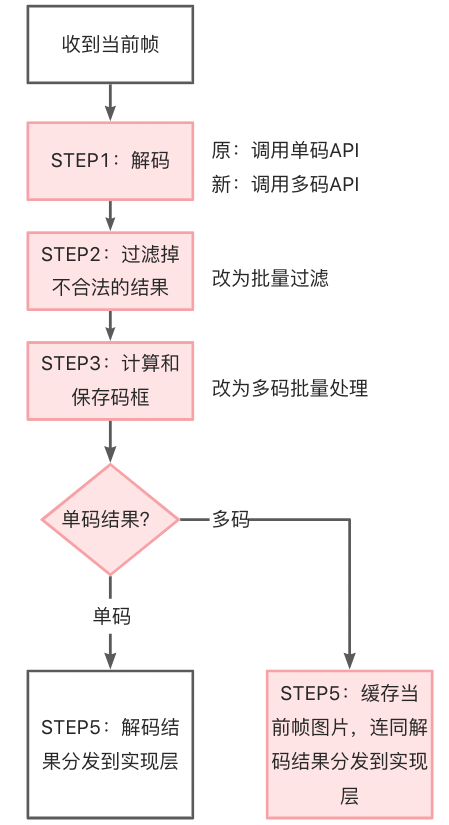
▐ 展示层:单码展示到多码展示
当识别到多码之后,需要让用户保持所见即所得:即覆盖缓存帧在镜头页上,通过箭头锚定码框的中心点。等待用户的操作后再进行进一步的响应。考虑到要展示当前帧的实现方式有下述两种方案:
方案一、将相机会话数据输入停止,则屏幕不会刷新新的帧数据,停留在当前帧,镜头页盖蒙层展示锚点。
方案二、将当前帧缓存图添加在镜头页上,镜头页盖蒙层展示锚点。
两种方案各有利弊。方案一不额外消耗内存,但需要控制相机会话的开启和停止,在重新启动相机时状态切换导致画面有明显切换痕迹。方案二不影响相机启停,但帧缓存图需要额外消耗的内存。解法是通过对分辨率控制来实现对内存的控制,并在用户操作后及时回收内存。
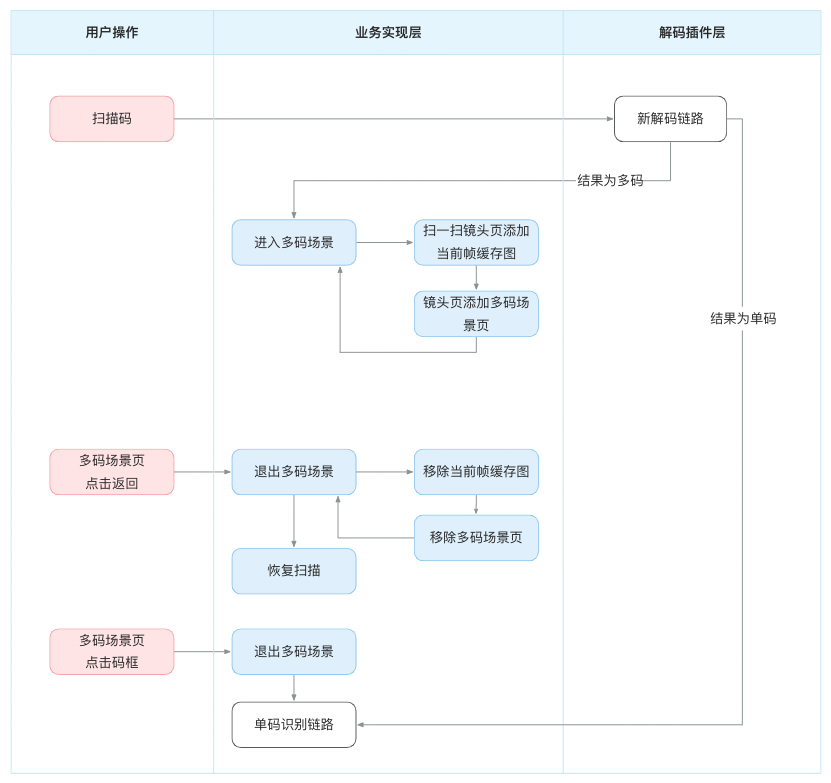
改造后的层级如下所示。同时为了严格枚举不同状态(正常、单码、多码)的流转,使用了状态机模式。
- 镜头页容器
- 扫一扫镜头页
- 当前帧缓存图(新增)
- 多码场景页(新增)
- 蒙层(新增)
- 导航栏(新增)
- 码框(新增)
- 提示文本框(新增)扫一扫业务实现层需要处理的内容如下,蓝色部分为改动点。
▐ 二维码码框转换算法
实现多码视觉展示的一个重要内容,是要在条码/二维码的中心展示箭头。这里涉及到解码SDK返回的原始数据映射到设备屏幕的码框的计算。对于二维码,整体三步走文字描述及伪代码如下,主要包含三步处理:
第一步、原图(即相机输入帧) 0° → 顺时针90°。原图为横屏的图,需要将原始rect顺时针旋转90°
第二步、将旋转后的图,缩放到和设备屏幕同一个尺寸
第三步、将码框坐标变换:原图坐标点 → 屏幕坐标点
码框旋转rect = CGRect(x: 原图宽 - (原码框.y + 原码框.height),
y: 原码框.x,
width: 原码框.height,
height: 原码框.width);
BOOL 是否长屏幕 = 图片宽/图片高 > 屏幕宽/屏幕高 ? YES : NO;
缩放比例 = 是否长屏幕 ? 屏幕高/图片高 : 屏幕宽/相机宽;
码框缩放rect = CGRect(x: 图片旋转rect.x * scale,
y: 图片旋转rect.y * scale,
width: 图片旋转rect.width * scale,
height: 图片旋转rect.height * scale);
码框坐标变换rect = null;
if(长屏幕) {
CGFloat xOffset = (图片宽*scale - 屏幕宽)/2.0;
码框坐标变换rect = CGRectMake(x:码框缩放rect.x-xOffset,
y:码框缩放rect.y,
width:码框缩放rect.width,
height:码框缩放rect.height);
}else {
CGFloat yOffset = (图片高*scale - 屏幕高)/2.0;
码框坐标变换rect = CGRectMake(x:码框缩放rect.x,
y:码框缩放rect.y-yOffset,
width:码框缩放rect.width,
height:码框缩放rect.height);
}
return 码框坐标变换rect;整体三步走图示:


降低漏检率
在上述章节中,直观地看起来,要支持多码识别只要将解码SDK切换并开发上层链路就解决了,但是现实中情况并不如此。
单帧数据的解码成功率会受到很多因素的影响,比如当前帧的模糊程度、传输给解码SDK的帧图像压缩比例、解码算法等等。在完成完成上述内容后,我们发现在多码识别的场景中,多码解码漏检率是比较高的。但是核心解码SDK的改动是比较难的。因此这时候我们考虑从别的角度入手来解决问题。
▐ Vision解码
基于iOS13以上的Vision解码能力,我们能够进行大多是码类型的解码。同时,在多数场景中,Vision能够解码SDK的漏检问题进行补充,下图为帧数据增加Vision解码的链路:
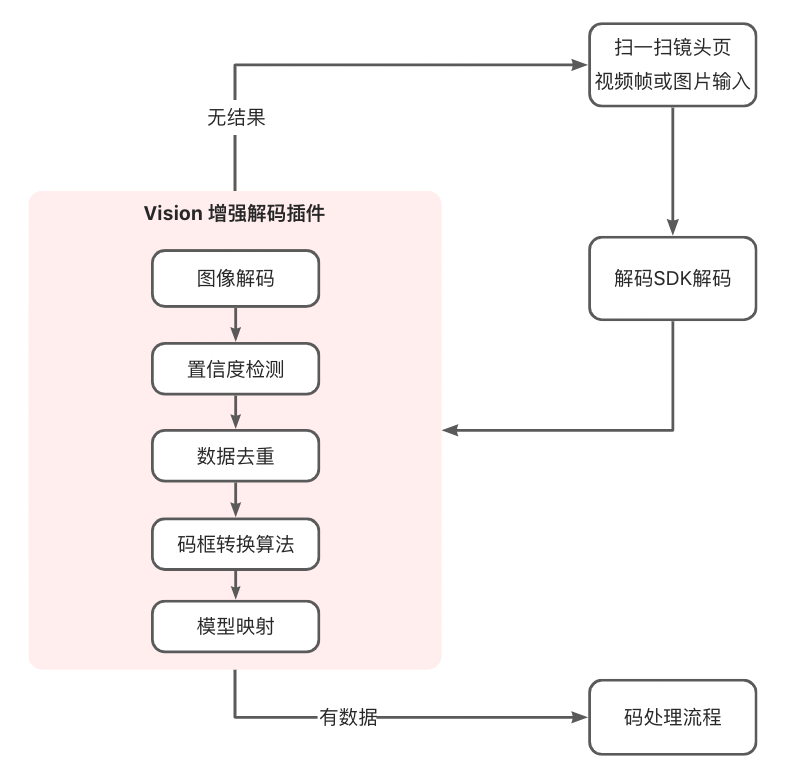
使用Visioin方案设计的核心关键点如下:
图像串行解码
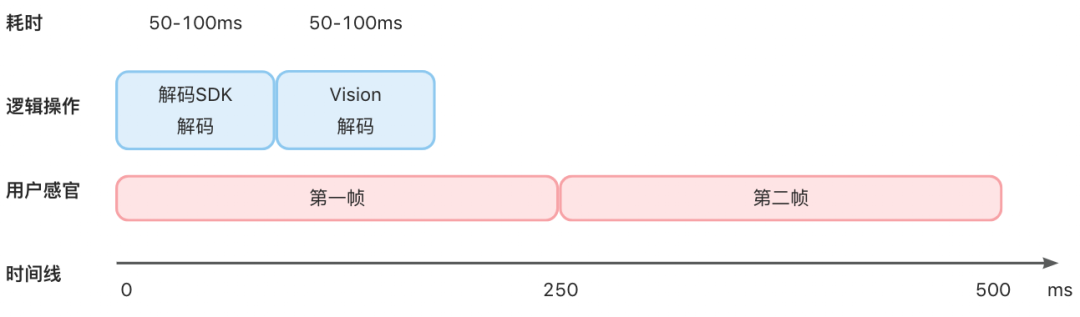
通过测算,扫一扫中解码SDK 和 Vision 解码耗时均在 50-100ms 左右,采用串行的解码能够满足业务要求。因此,在不阻塞单帧处理的情况下,使用 Vision 可以提高准确度。
从结果(VNRequest.results)当中,我们核心要获取的原始数据包括(和现有解码SDK对齐的数据,即最终数据格式要能够统一):
码类型(symbology.rawValue)
码内容(payloadStringValue)
置信度(confidence)
原始码框(boundingBox)
置信度检测
增加置信度检测,是为了保证用户取得的码框是符合预期的。通过参数调优,我们设定了 0.9 作为可接受的置信度(confidence)最小值。
数据去重
在条形码的解码场景中,因为码竖条长度的不确定性以及底层算法的实现不同。存在一个条形码出现多个返回结果的情况,这些返回结果的中心点沿着条形码的中轴线纵向分布。基于用户的意图和常规操作场景,我们把位置重合且同样的码内容(payloadStringValue),只去重展示一个数据。去重策略上,选择置信度(confidence)最高的数据。
模型映射
进行码展示和码处理都是使用解码SDK原有的模型(Model),我们需要把 Vision 输出的结果进行转换。最重要的是将码类型(symbology.rawValue)转化成扫一扫需要的码类型和码子类型。
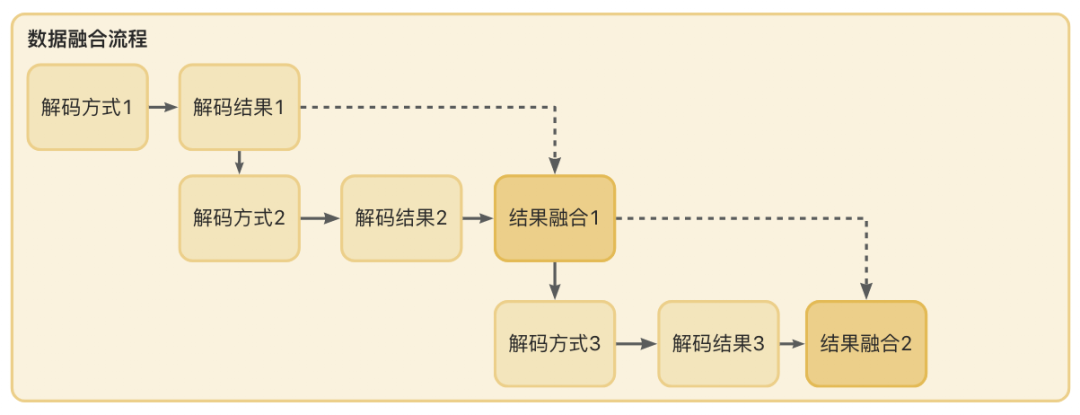
▐ 数据融合
有了Vision的数据之后,我们后续需要对解码数据做融合。融合的意思就是去重后合并,这就要求不同解码方式输出的解码结果是能够比较的。有了模型映射这个步骤,融合就比较简单了:我们把位置重合且同样的码内容,只去重展示一个数据。去重策略上,选择置信度(confidence)最高的数据。
▐ 端智能
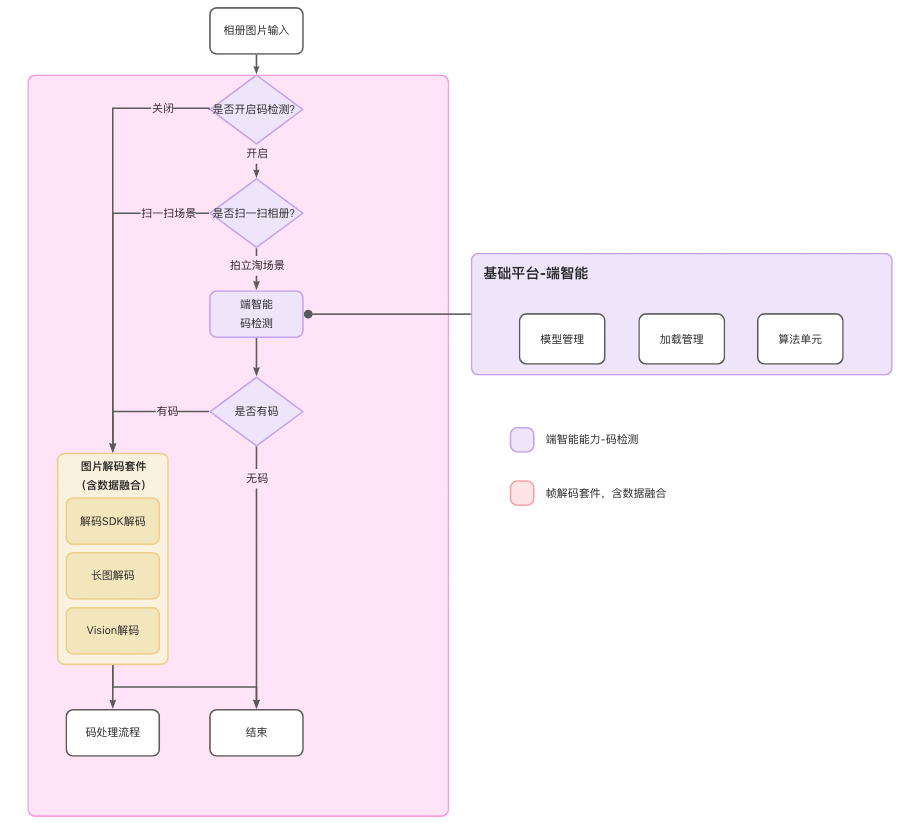
有了Vision的帮助,我们能够对解码SDK解不出来的码做一次融合。但有没有办法提高解码SDK的成功率?前面说到,对于原图的压缩、码过小等场景都会影响解码SDK的解码率。那么有没有办法预先识别出当前图片的码框范围并抠图解码?
通过拍立淘的端智能架构,我们增加了码检测算法。码检测能力的提供,让我们不再是“摸黑”地进行解码了。而是有目的、有预期的进行解码。当码检测模型检测到当前帧具备一个或多个码,同时能够返回码框的位置。针对这个码框的位置,我们就能够进行抠图解码,能够增加解码SDK的解码成功率。

效果展示
左图为相册链路的多码识别,右图为镜头链路的多码识别。通过应用降低漏检率的策略,我们在多码场景上的识别率有非常显著提升。


总结和展望
本篇是从真实场景入手,在优化用户体验的维度发现问题,并尝试解决问题。但解决了问题(完成了多码实现)并不代表完成,因为始终能够有提升的空间(降低漏检率,提高解码率)。可以说,解决问题只是一个新的开始,是一个可以展开更广泛想象力,使用更广泛工具去不断优化的开始。
扫一扫作为手淘主要解码能力的载体,对扫码能力相关的优化是永无止境的。除了解码SDK本身对算法的不断升级之外,借助iOS系统和端智能技术,也能够对解码成功率起到正向的促进作用。扫一扫在经过多次迭代后,相册解码成功率提升了30pt+。同时,全屏识别、多码识别、药品码物流码的识别能力,也都是我们的优势所在。后续我们将会不断优化扫码解码的用户体验,缩短码识别时间,提高码识别场景的图片稳定性,做到

团队介绍
我们是大淘宝技术搜索终端团队,负责手机淘宝搜索,拍立淘等核心业务的研发和技术创新,同时打造了端侧的搜索终端通用框架,提供搜索领域端到端解决方案,以平台化能力支撑了手机淘宝等多个集团电商和本地生活业务,同时我们和算法技术紧密结合,将端智能和边缘计算充分应用于我们的文本和图像搜索业务,我们研发的产品为亿级消费者提供服务,期待您的加入。
感兴趣的同学可将简历发送到 taozi.ly@taobao.com
¤ 拓展阅读 ¤
3DXR技术 | 终端技术 | 音视频技术
服务端技术 | 技术质量 | 数据算法