ML之FE:基于波士顿房价数据集利用LightGBM算法进行模型预测然后通过3σ原则法(计算残差标准差)寻找测试集中的异常值/异常样本
目录
基于波士顿房价数据集利用LiR和LightGBM算法进行模型预测然后通过3σ原则法(计算残差标准差)寻找测试集中的异常值
# 1、定义数据集
# 2、数据预处理/特征工程
# 2.1、分离特征与标签
# 3、模型训练与预测
# 3.1、切分数据集
# 3.2、建立模型
# 3.3、模型预测
# 3.4、模型评估
# 4、利用3σ原则寻找测试集中的异常值
# 4.1、计算残差和3σ并可视化
# 4.2、输出异常值的索引及其对应数据
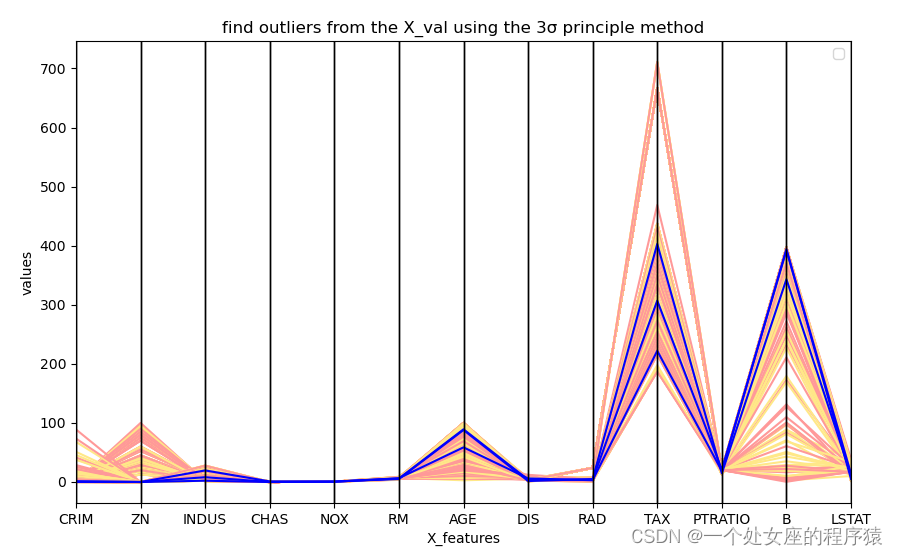
# 4.3、可视化异常样本数据
# 绘制验证集中的异常数值索引所在的样本数据
相关文章
ML之FE:基于波士顿房价数据集利用LightGBM算法进行模型预测然后通过3σ原则法(计算残差标准差)寻找测试集中的异常值/异常样本
ML之FE:基于波士顿房价数据集利用LightGBM算法进行模型预测然后通过3σ原则法(计算残差标准差)寻找测试集中的异常值/异常样本实现代码
基于波士顿房价数据集利用LiR和LightGBM算法进行模型预测然后通过3σ原则法(计算残差标准差)寻找测试集中的异常值
# 1、定义数据集
CRIM ZN INDUS CHAS NOX ... TAX PTRATIO B LSTAT target
0 0.00632 18.0 2.31 0.0 0.538 ... 296.0 15.3 396.90 4.98 24.0
1 0.02731 0.0 7.07 0.0 0.469 ... 242.0 17.8 396.90 9.14 21.6
2 0.02729 0.0 7.07 0.0 0.469 ... 242.0 17.8 392.83 4.03 34.7
3 0.03237 0.0 2.18 0.0 0.458 ... 222.0 18.7 394.63 2.94 33.4
4 0.06905 0.0 2.18 0.0 0.458 ... 222.0 18.7 396.90 5.33 36.2
[5 rows x 14 columns]
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 506 entries, 0 to 505
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 CRIM 506 non-null float64
1 ZN 506 non-null float64
2 INDUS 506 non-null float64
3 CHAS 506 non-null float64
4 NOX 506 non-null float64
5 RM 506 non-null float64
6 AGE 506 non-null float64
7 DIS 506 non-null float64
8 RAD 506 non-null float64
9 TAX 506 non-null float64
10 PTRATIO 506 non-null float64
11 B 506 non-null float64
12 LSTAT 506 non-null float64
13 target 506 non-null float64
dtypes: float64(14)
memory usage: 55.5 KB# 2、数据预处理/特征工程
# 2.1、分离特征与标签
# 3、模型训练与预测
# 3.1、切分数据集
# 自定义构造异常样本,并新增到验证数据集的最后一行
[[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
CRIM ZN INDUS CHAS NOX ... RAD TAX PTRATIO B LSTAT
0 51.13580 0.0 18.10 0.0 0.5970 ... 24.0 666.0 20.2 2.60 10.11
1 0.05735 0.0 4.49 0.0 0.4490 ... 3.0 247.0 18.5 392.30 6.53
2 0.03578 20.0 3.33 0.0 0.4429 ... 5.0 216.0 14.9 387.31 3.76
3 12.04820 0.0 18.10 0.0 0.6140 ... 24.0 666.0 20.2 291.55 14.10
4 0.03150 95.0 1.47 0.0 0.4030 ... 3.0 402.0 17.0 396.90 4.56
.. ... ... ... ... ... ... ... ... ... ... ...
148 0.03932 0.0 3.41 0.0 0.4890 ... 2.0 270.0 17.8 393.55 8.20
149 1.49632 0.0 19.58 0.0 0.8710 ... 5.0 403.0 14.7 341.60 13.28
150 12.24720 0.0 18.10 0.0 0.5840 ... 24.0 666.0 20.2 24.65 15.69
151 3.56868 0.0 18.10 0.0 0.5800 ... 24.0 666.0 20.2 393.37 14.36
152 1.00000 1.0 1.00 1.0 1.0000 ... 1.0 1.0 1.0 1.00 1.00
[153 rows x 13 columns]
[15. 26.6 45.4 20.8 34.9 21.9 28.7 7.2 20. 32.2 24.1 18.5 13.5 27.
23.1 18.9 24.5 43.1 19.8 13.8 15.6 50. 37.2 46. 50. 21.2 14.9 19.6
19.4 18.6 26.5 32. 10.9 20. 21.4 31. 25. 15.4 13.1 37.6 37. 18.9
27.9 50. 14.4 22. 19.9 21.6 15.6 15. 32.4 29.6 20.4 12.3 19.1 14.9
17.8 8.8 35.4 11.5 19.6 20.6 15.6 19.9 23.3 22.3 24.8 16.1 22.8 30.5
20.4 24.4 16.6 26.2 16.4 20.1 13.9 19.4 22.8 13.8 31.6 10.5 23.8 22.4
19.3 22.2 12.6 19.4 22.2 29.8 9.6 34.9 21.4 25.3 32.9 26.6 14.6 31.5
23.3 33.3 17.5 19.1 48.5 17.1 23.1 28.4 18.9 13. 17.2 24.1 18.5 21.8
13.3 23. 14.1 23.9 24. 17.2 21.5 19.1 20.8 36. 20.1 8.7 13.6 22.
22.2 21.1 13.4 17.4 20.1 10.2 23.1 10.2 13.1 14.3 14.5 7.2 19.6 20.6
22.7 26.4 7.5 20.3 50. 8.5 20.3 16.1 22. 19.6 10.2 23.2 1. ]# 3.2、建立模型
# 3.3、模型预测
# 3.4、模型评估
R2: 0.7008826511832902
MAE: 2.7382901265894115
MSE: 24.875537390523984# 4、利用3σ原则寻找测试集中的异常值
# 4.1、计算残差和3σ并可视化
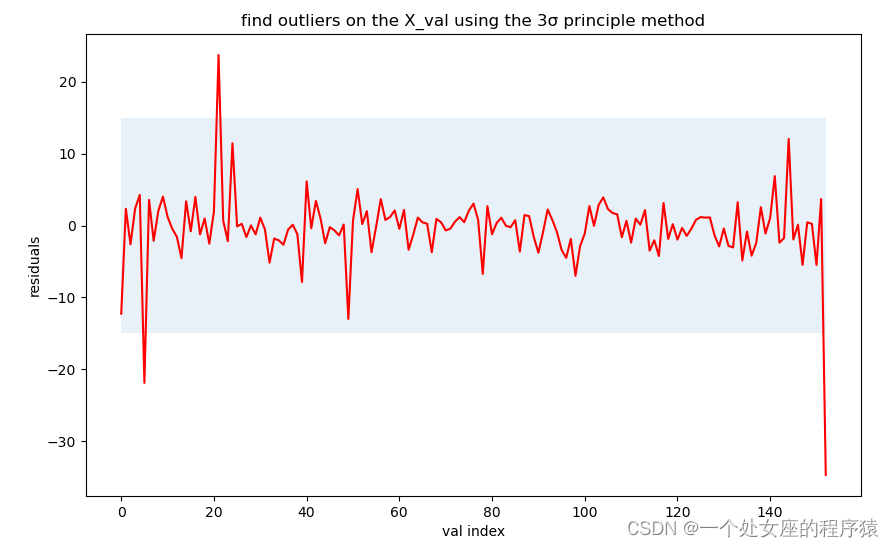
# 4.2、输出异常值的索引及其对应数据
异常值在val数据集中的索引: [5, 21, 152]
异常值所对应的样本数据:
CRIM ZN INDUS CHAS NOX ... RAD TAX PTRATIO B LSTAT
5 3.47428 0.0 18.1 1.0 0.718 ... 24.0 666.0 20.2 354.55 5.29
21 8.26725 0.0 18.1 1.0 0.668 ... 24.0 666.0 20.2 347.88 8.88
152 1.00000 1.0 1.0 1.0 1.000 ... 1.0 1.0 1.0 1.00 1.00
[3 rows x 13 columns]
异常值的残差: [-21.89520378 23.73853433 -34.71056917]# 4.3、可视化异常样本数据
# 绘制验证集中的异常数值索引所在的样本数据