文章目录
- 动态字符串SDS
- 字符串编码类型
- intset
- Dict
- ZipList
- ZipList的连锁更新问题
- QuickList
- SkipList
- RedisObject
- String
- List
- Set结构
- ZSET
- Hash
Redis 共有 5 种基本数据结构:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
这 5 种数据结构是直接提供给用户使用的,是数据的保存形式,其底层实现主要依赖这 8 种数据结构:简单动态字符串(SDS)、LinkedList(双向链表)、Hash Table(哈希表)、SkipList(跳跃表)、Intset(整数集合)、ZipList(压缩列表)、QuickList(快速列表)。
Redis 基本数据结构的底层数据结构实现如下:

Redis 3.2 之前,List 底层实现是 LinkedList 或者 ZipList。 Redis 3.2 之后,引入了 LinkedList 和 ZipList 的结合 QuickList,List 的底层实现变为 QuickList。
动态字符串SDS
我们都知道Redis中保存的Key是字符串,value往往是字符串或者字符串的集合。可见字符串是Redis中最常用的一种数据结构。
不过Redis没有直接使用C语言中的字符串,因为C语言字符串存在很多问题:
- 获取字符串长度的需要通过运算
- 非二进制安全
- 不可修改
什么是非二进制安全?
二进制安全是一种主要用于字符串操作函数相关的计算机编程术语。一个二进制安全功能(函数),其本质上将操作输入作为原始的、无任何特殊格式意义的数据流。对于每个字符都公平对待,不特殊处理某一个字符。
大多数的函数当其使用任何特别的或标记字符,如转义码,那些期望 null 结尾的字符串(如C语言中的字符串),不是二进制安全的。一个可能的例外是该函数的明确的目的是在某二进制字符串搜索某特定字符。
我们举个例子:
C语言的字符串中的字符必须符合某种编码(如:ASCII),并且除了字符串末尾的空字符,其他位置不能包含空字符,否则,会出现数据被截断的情况,比如:
如果使用C字符串所用的函数来识别,只能读取到“hello”,后面的“world”会被忽略,这个限制使得C字符串只能保存文本数据,而不能保存图片、视频、压缩文件等二进制数据。
SDS的API都会以二进制的方式来处理SDS存放在buf数组里的数据,Redis使用这个数组保存的是一系列二进制数据,而不是保存字符。SDS使用len属性的值判断字符串是否结束,而不是空字符,即SDS是二进制安全的。

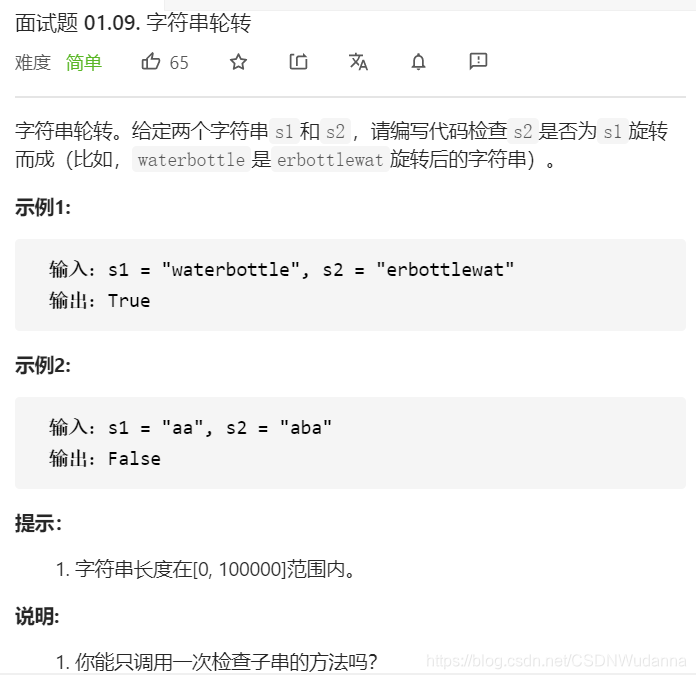
Redis构建了一种新的字符串结构,称为简单动态字符串(Simple Dynamic String),简称SDS。
例如,我们执行命令:

那么Redis将在底层创建两个SDS,其中一个是包含“name”的SDS,另一个是包含“虎哥”的SDS。
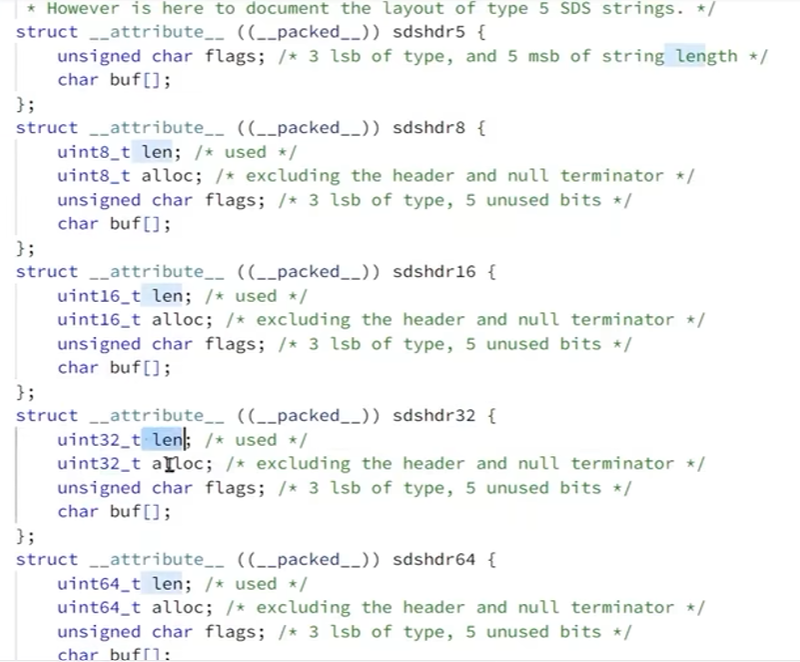
Redis是C语言实现的,其中SDS是一个结构体,源码如下:

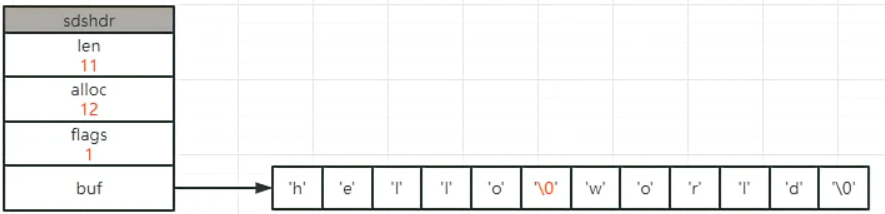
这里的sds根据长度类型,分为五类,比如我们看到sdshdr8中len属性的类型为uint8_t代表无符号8比特位,len最大为255,也就是说这种类型的sds长度最大为255字节。struct __attribute__ ((__packed__)) sdshdr8 { uint8_t len; // 已经使用的字节数 uint8_t alloc; // 实际可以存储的字节最大长度,不包括SDS头部和结尾的空字符 unsigned char flags; // flags中的低3个bit决定使用哪种结构存储字符串,高5bit未使用 char buf[]; // 柔性数组,用来保存实际的字符串 };sdshdrxx会根据字符串的实际长度,选取合适的结构,最大化节省内存空间。获取字符串长度时间复杂度O(1)。
例如,一个包含字符串“name”的sds结构如下:

SDS之所以叫做动态字符串,是因为它具备动态扩容的能力,例如一个内容为“hi”的SDS:

假如我们要给SDS追加一段字符串“,Amy”,这里首先会申请新内存空间:
-
如果新字符串小于1M,则新空间为扩展后字符串长度的两倍+1Byte;
-
如果新字符串大于1M,则新空间为扩展后字符串长度+1M+1Byte。称为内存预分配。

申请内存的动作非常消耗资源,而通过内存的预分配可以适当地减少申请内存的次数。

字符串编码类型
字符串类型的内部编码有三种:
-
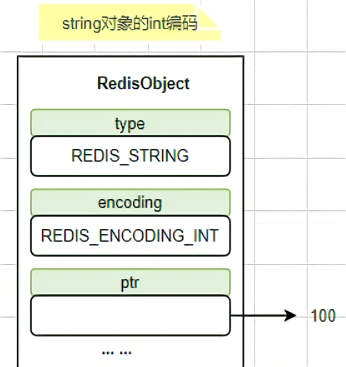
int:存储 8 个字节的长整型(long,2^63-1),如果 value 是 long 类型的整数,则使用此编码。
-
embstr:代表 embstr 格式的 SDS,存储小于 44 个字节的字符串3.2 版本之前是 39 个字节),只分配一次内存空间(因为 Redis Object 和 SDS 是连续的)。
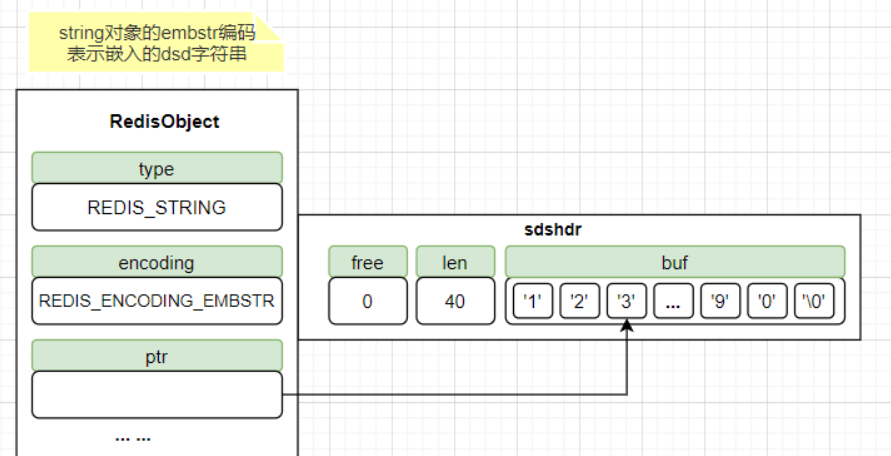
- embstr 分配的是连续的一块内存,包含 robj 和 sds,robj 占用了16个字节,3.2 版本之前 sds 占用 8 个字节,3.2 及之后版本 占用 3 个字节。因此,
- 在 3.2 版本之前,如果字符串存储小于等于 39 个字节,编码为 embstr,超过 39 个字节,编码为 raw;
- 在 3.2 及之后,如果字符串存储小于等于 44 个字节,编码为 embstr,超过 44 个字节,编码为 raw。
- 优点:只需要一次内存分配,数据比较小的时候使用的是这种编码,数据更紧凑,效率更高。
- 缺点:没有提供修改的函数,所以是只读的,如果要对此编码数据进行修改,会变成 raw 再执行修改,然后结束。
- embstr 分配的是连续的一块内存,包含 robj 和 sds,robj 占用了16个字节,3.2 版本之前 sds 占用 8 个字节,3.2 及之后版本 占用 3 个字节。因此,
-
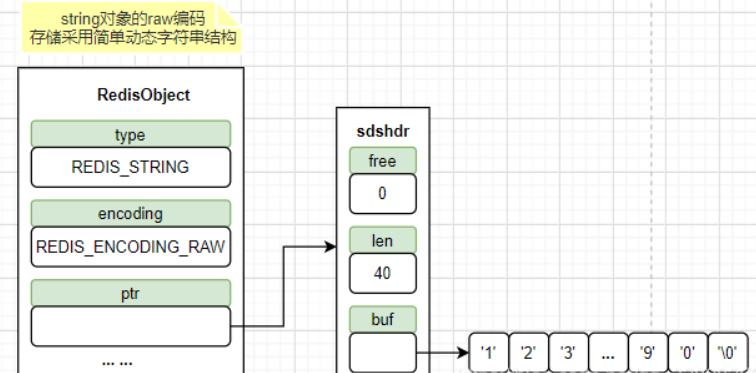
raw:存储大于 44 个字节的字符串(3.2 版本之前是 39 个字节),需要分配两次内存空间(分别为 Redis Object 和 SDS 分配空间)。raw 分配的不是连续的内存,需要调用两次内存分配函数来分别创建 robj 和 sds。
intset
IntSet是Redis中set集合的一种实现方式,基于整数数组来实现,并且具备长度可变、有序等特征。
结构如下:

其中的encoding包含三种模式,表示存储的整数大小不同:

分析:
contents数组是整数集合的底层实现:整数集合中的每一个元素就是contents数组中的一个元素,每个元素在数组中按照从小到大的顺序排列,并且没有重复元素。
虽然,contents数组被声明为 int8_t 类型的数组,但实际上contents数组并不保存任何int8_t 类型的值,contents数组实际存储的类型取决于encoding的值。encoding的取值可以是:INTSET_ENC_INT16、INTSET_ENC_INT32 或 INTSET_ENC_INT64,每种编码的取值范围如下:
- INTSET_ENC_INT16 取值范围:[−2^15 ,2^15−1] 即:[-32768, 32767 ]
- INTSET_ENC_INT32 取值范围:[−2^31 ,2^31−1] 即:[-2147483648, 2147483647]
- INTSET_ENC_INT64 取值范围:[−2^63 ,2^63−1] 即:[-9223372036854775808, 9223372036854775807]
为了方便查找,Redis会将intset中所有的整数按照升序依次保存在contents数组中,结构如图:

通过右边的寻址公式可以得到每一个整数的位置,这也反映了为什么要将数组中的数字编码类型进行统一。因为是连续的内存地址,方便寻找数组中每个元素的地址。
现在,数组中每个数字都在int16_t的范围内,因此采用的编码方式是INTSET_ENC_INT16,每部分占用的字节大小为:
- encoding:4字节
- length:4字节
- contents:2字节 * 3 = 6字节

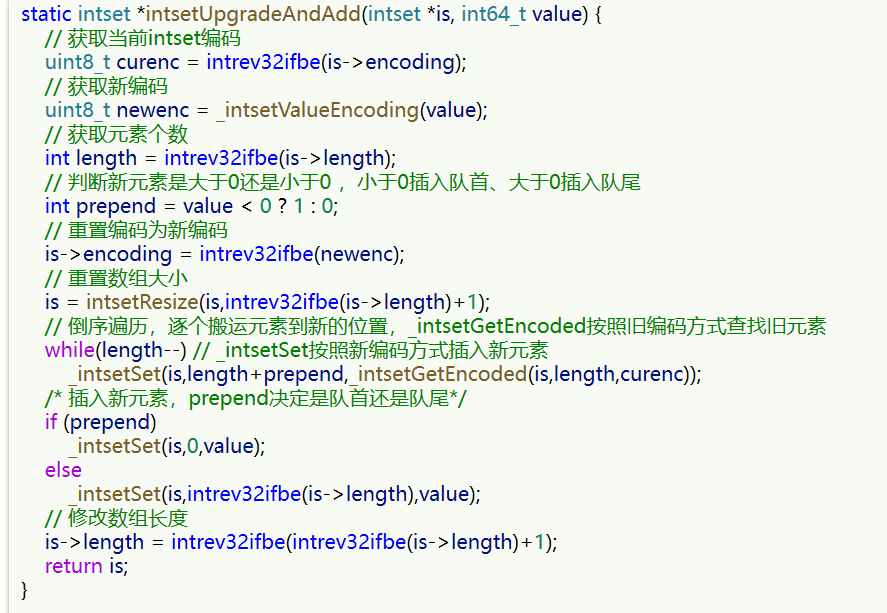
我们向该其中添加一个数字:50000,这个数字超出了int16_t的范围,intset会自动升级编码方式到合适的大小。
以当前案例来说流程如下:
- 升级编码为INTSET_ENC_INT32, 每个整数占4字节,并按照新的编码方式及元素个数扩容数组
- 倒序依次将数组中的元素拷贝到扩容后的正确位置
- 将待添加的元素放入数组末尾
- 最后,将inset的encoding属性改为INTSET_ENC_INT32,将length属性改为4

源码如下:

小总结:
Intset可以看做是特殊的整数数组,具备一些特点:
- Redis会确保Intset中的元素唯一、有序
- 具备类型升级机制,可以节省内存空间
- 底层采用二分查找方式来查询
Dict
我们知道Redis是一个键值型(Key-Value Pair)的数据库,我们可以根据键实现快速的增删改查。而键与值的映射关系正是通过Dict来实现的。
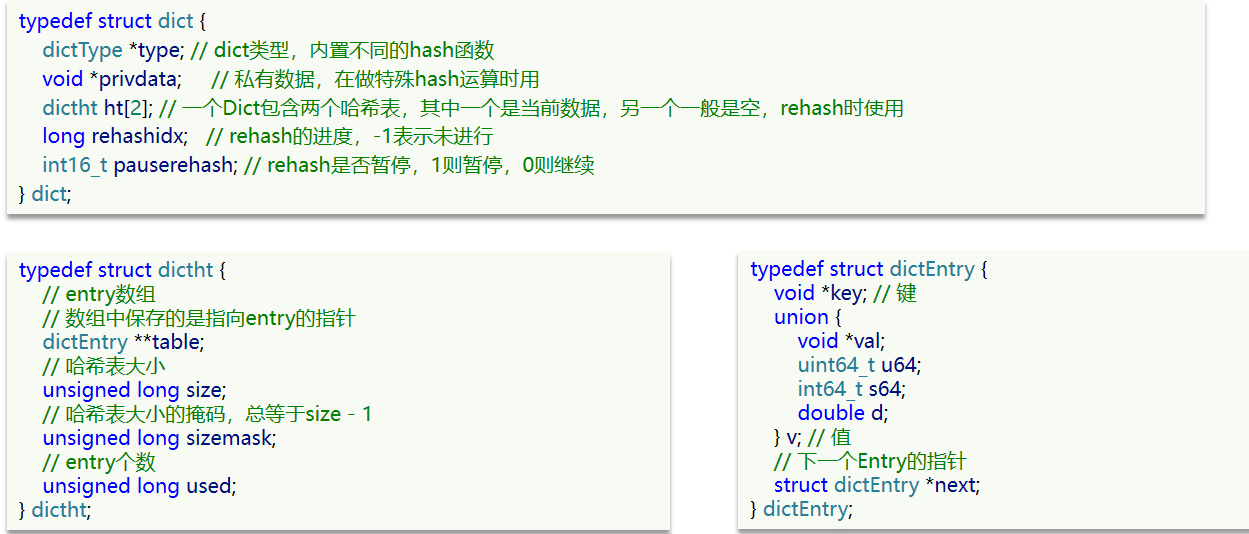
Dict由三部分组成,分别是:哈希表(DictHashTable)、哈希节点(DictEntry)、字典(Dict)

当我们向Dict添加键值对时,Redis首先根据key计算出hash值(h),然后利用 h & sizemask来计算元素应该存储到数组中的哪个索引位置。我们存储k1=v1,假设k1的哈希值h =1,则1&3 =1,因此k1=v1要存储到数组角标1位置。

Dict由三部分组成,分别是:哈希表(DictHashTable)、哈希节点(DictEntry)、字典(Dict)
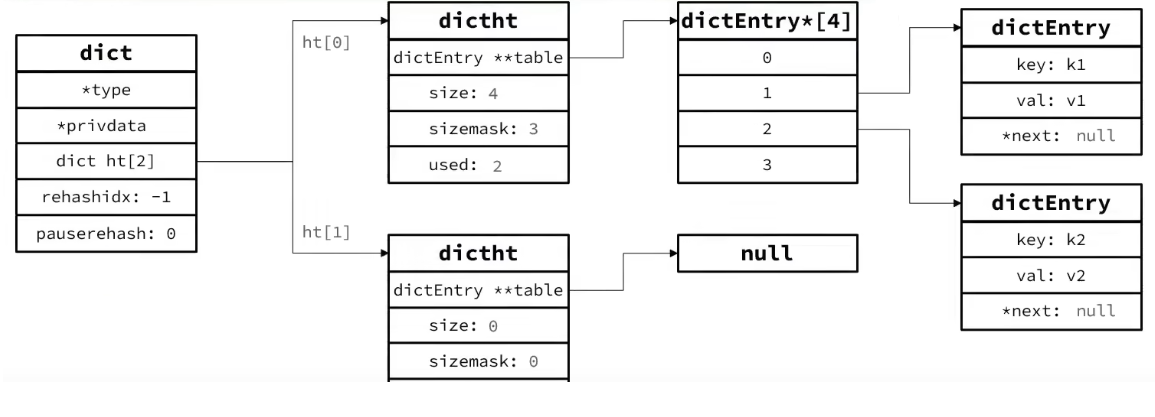
Dict的扩容
Dict中的HashTable就是数组结合单向链表的实现,当集合中元素较多时,必然导致哈希冲突增多,链表过长,则查询效率会大大降低。
Dict在每次新增键值对时都会检查负载因子(LoadFactor = used/size) ,满足以下两种情况时会触发哈希表扩容:
- 哈希表的 LoadFactor >= 1,并且服务器没有执行 BGSAVE 或者 BGREWRITEAOF 等后台进程;
- 哈希表的 LoadFactor > 5 ;

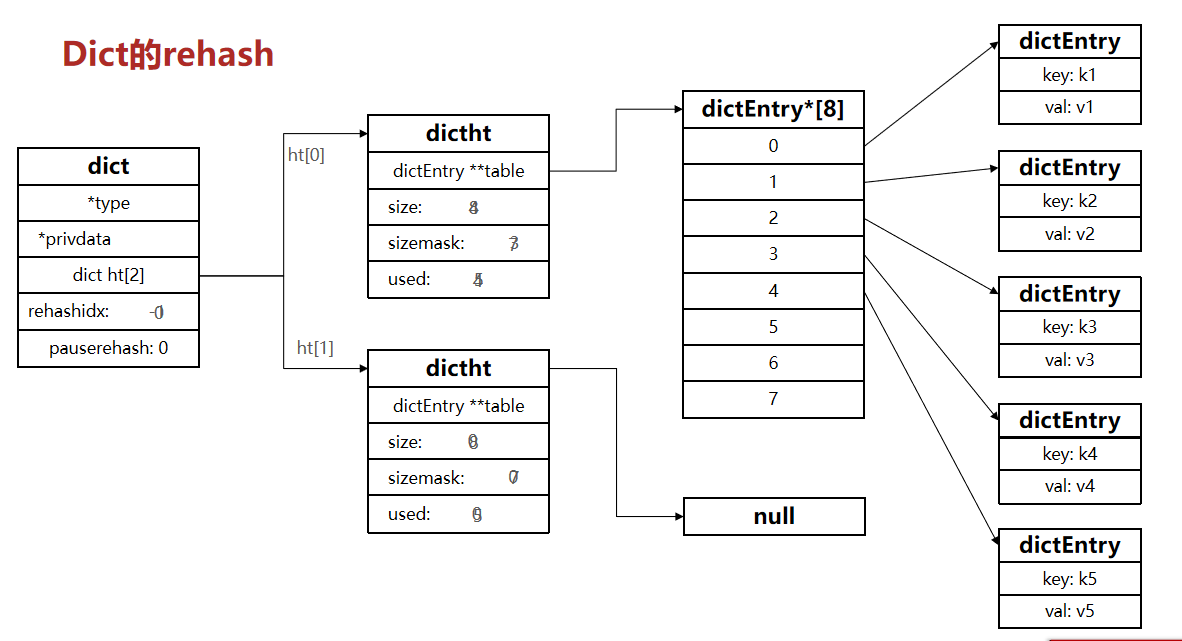
Dict的rehash
不管是扩容还是收缩,必定会创建新的哈希表,导致哈希表的size和sizemask变化,而key的查询与sizemask有关。因此必须对哈希表中的每一个key重新计算索引,插入新的哈希表,这个过程称为rehash。过程是这样的:
-
计算新hash表的realeSize,值取决于当前要做的是扩容还是收缩:
- 如果是扩容,则新size为第一个大于等于dict.ht[0].used + 1的2^n
- 如果是收缩,则新size为第一个大于等于dict.ht[0].used的2^n (不得小于4)
-
按照新的realeSize申请内存空间,创建dictht,并赋值给dict.ht[1]
-
设置dict.rehashidx = 0,标示开始rehash
-
将dict.ht[0]中的每一个dictEntry都rehash到dict.ht[1]
-
将dict.ht[1]赋值给dict.ht[0],给dict.ht[1]初始化为空哈希表,释放原来的dict.ht[0]的内存
-
将rehashidx赋值为-1,代表rehash结束
-
在rehash过程中,新增操作,则直接写入ht[1],查询、修改和删除则会在dict.ht[0]和dict.ht[1]依次查找并执行。这样可以确保ht[0]的数据只减不增,随着rehash最终为空
整个过程可以描述成:
小总结:
Dict的结构:
- 类似java的HashTable,底层是数组加链表来解决哈希冲突
- Dict包含两个哈希表,ht[0]平常用,ht[1]用来rehash
Dict的伸缩:
- 当LoadFactor大于5或者LoadFactor大于1并且没有子进程任务时,Dict扩容
- 当LoadFactor小于0.1时,Dict收缩
- 扩容大小为第一个大于等于used + 1的2^n
- 收缩大小为第一个大于等于used 的2^n
- Dict采用渐进式rehash,每次访问Dict时执行一次rehash
- rehash时ht[0]只减不增,新增操作只在ht[1]执行,其它操作在两个哈希表
ZipList
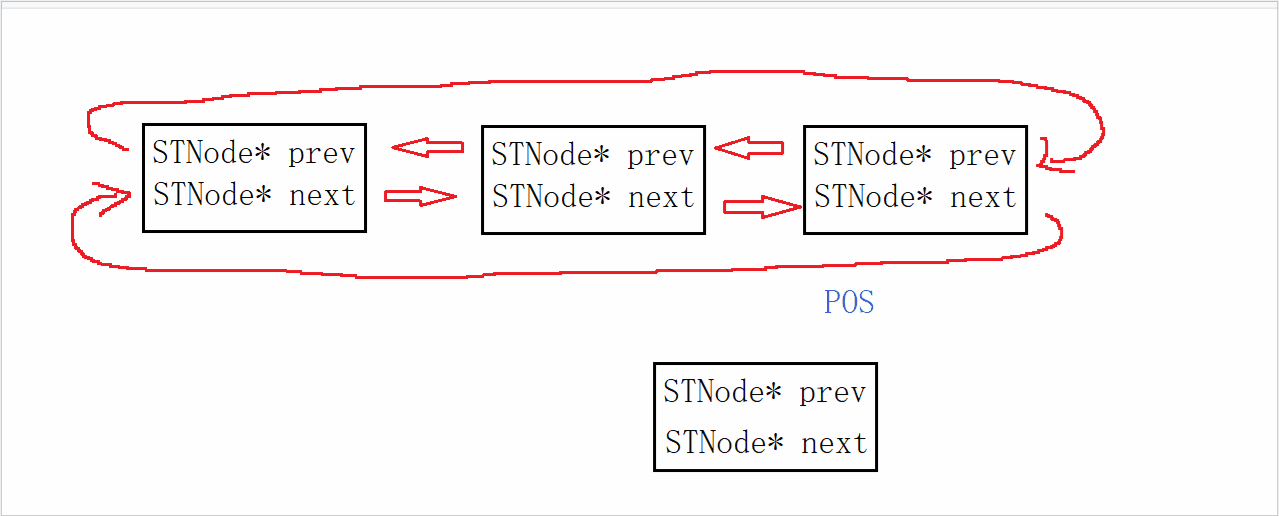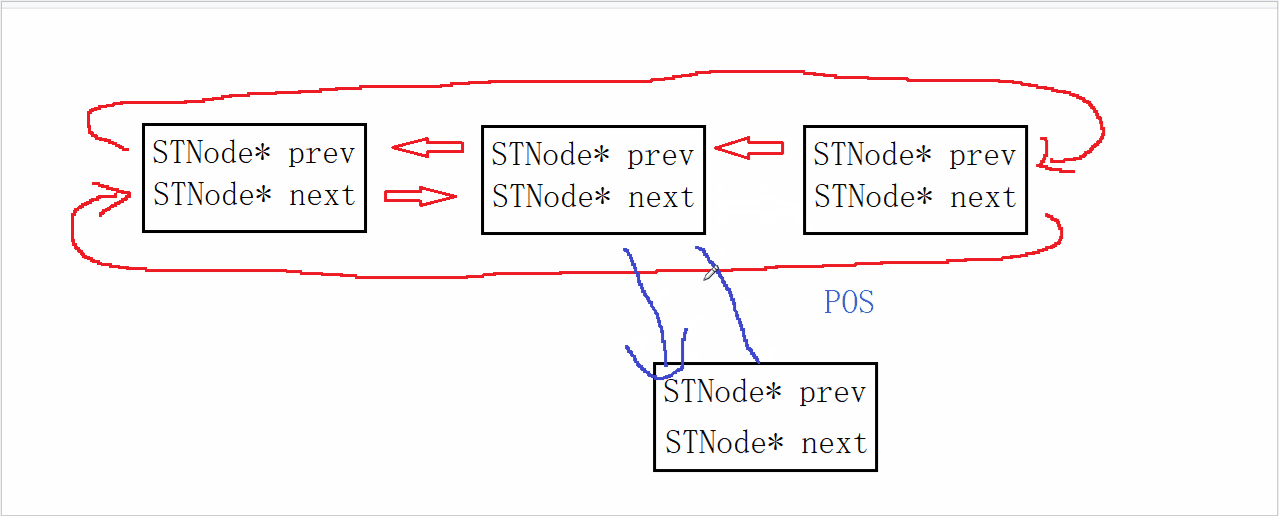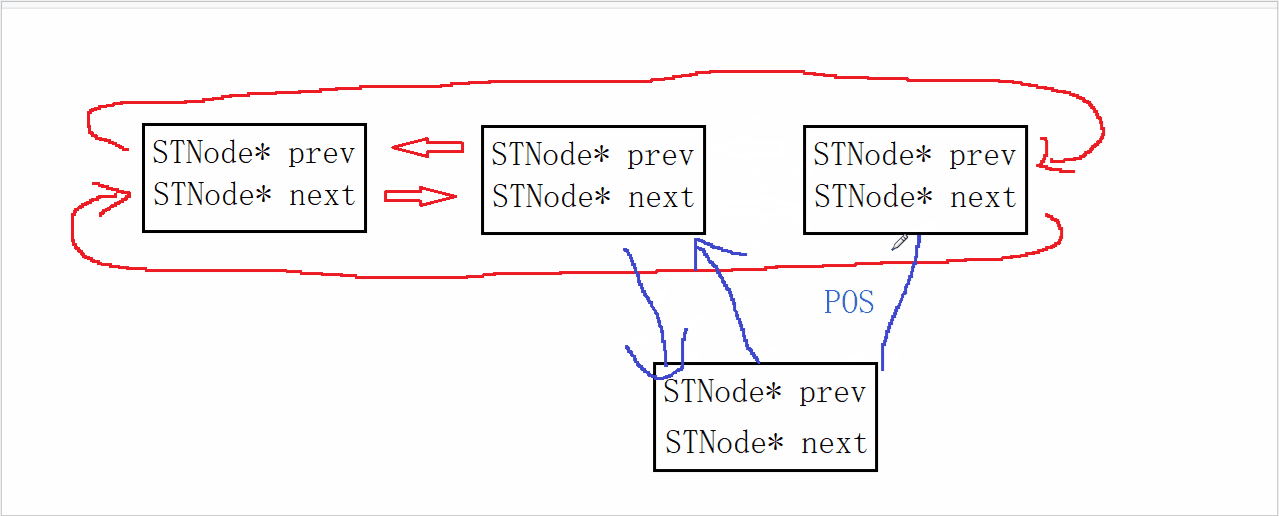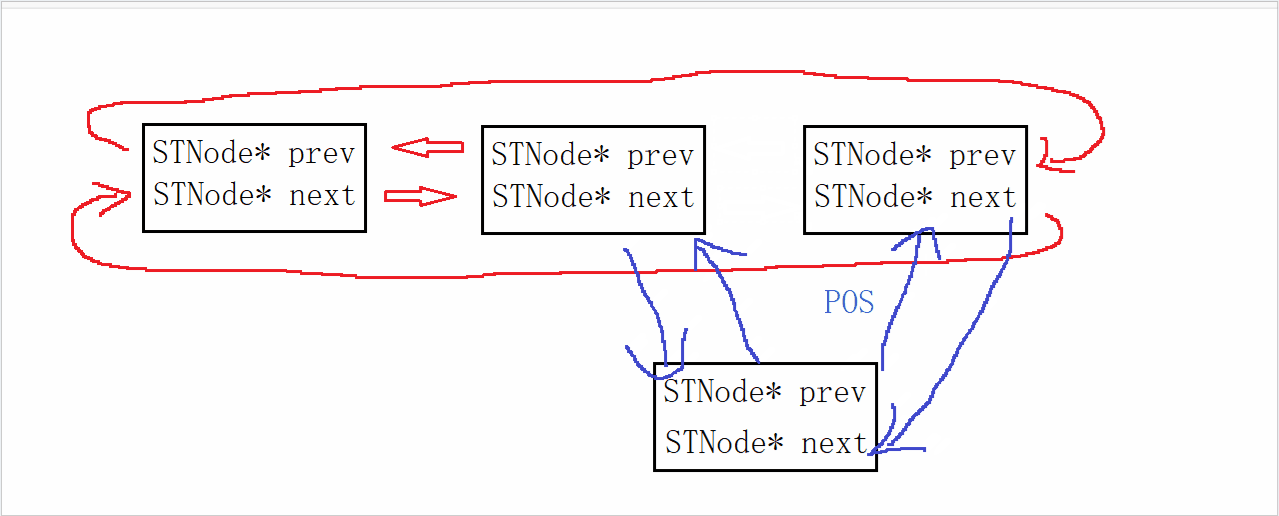
ZipList 是一种特殊的“双端链表” ,由一系列特殊编码的连续内存块组成。可以在任意一端进行压入/弹出操作, 并且该操作的时间复杂度为 O(1)。
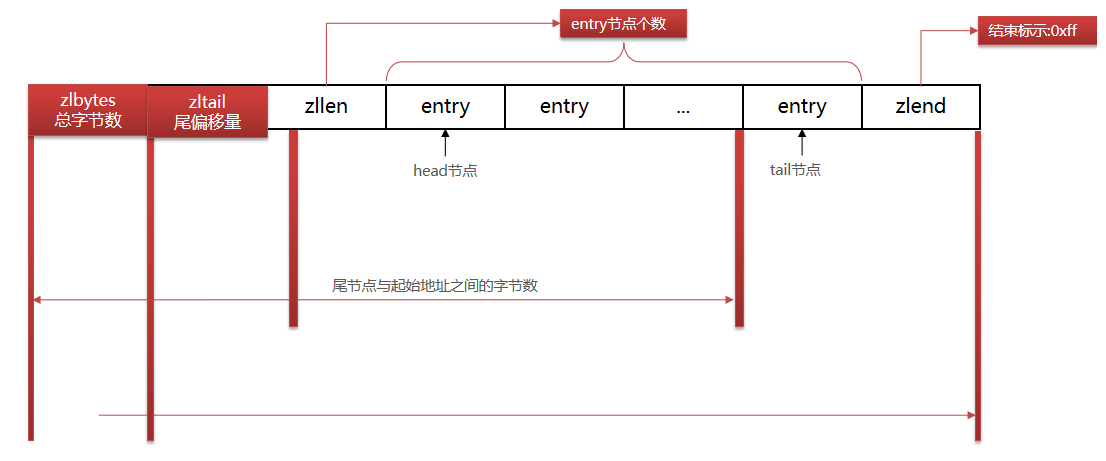

| 属性 | 类型 | 长度 | 用途 |
|---|---|---|---|
| zlbytes | uint32_t | 4 字节 | 记录整个压缩列表占用的内存字节数 |
| zltail | uint32_t | 4 字节 | 记录压缩列表表尾节点距离压缩列表的起始地址有多少字节,通过这个偏移量,可以确定表尾节点的地址。 |
| zllen | uint16_t | 2 字节 | 记录了压缩列表包含的节点数量。 最大值为UINT16_MAX (65534),如果超过这个值,此处会记录为65535,但节点的真实数量需要遍历整个压缩列表才能计算得出。 |
| entry | 列表节点 | 不定 | 压缩列表包含的各个节点,节点的长度由节点保存的内容决定。 |
| zlend | uint8_t | 1 字节 | 特殊值 0xFF (十进制 255 ),用于标记压缩列表的末端。 |
例如:
说明:ziplist 的总长度为96字节(0x60的十进制),最后一个entry距离ziplist起始位置偏移了75字节(0x4B的十进制),ziplist中此时有3(0x03的十进制)个entry。
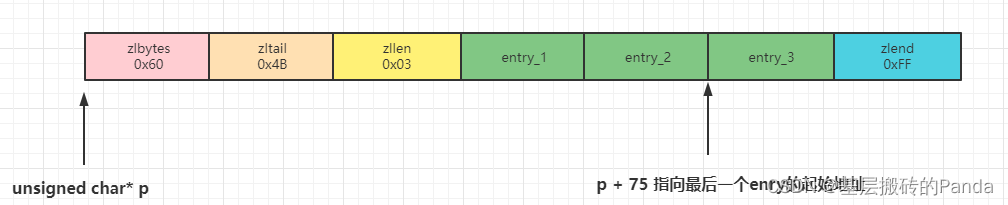
ZipListEntry
ZipList 中的Entry并不像普通链表那样记录前后节点的指针,因为记录两个指针要占用16个字节,浪费内存。而是采用了下面的结构:

-
previous_entry_length:前一节点的长度,占1个或5个字节。
- 如果前一节点的长度小于254字节,则采用1个字节来保存这个长度值
- 如果前一节点的长度大于254字节,则采用5个字节来保存这个长度值,第一个字节为0xfe,后四个字节才是真实长度数据
-
encoding:编码属性,记录content的数据类型(字符串还是整数)以及长度,占用1个、2个或5个字节
-
contents:负责保存节点的数据,可以是字符串或整数
ZipList中所有存储长度的数值均采用小端字节序,即低位字节在前,高位字节在后。例如:数值0x1234,采用小端字节序后实际存储值为:0x3412
Encoding编码
ZipListEntry中的encoding编码分为字符串和整数两种:
字符串:如果encoding是以“00”、“01”或者“10”开头,则证明content是字符串
| 编码 | 编码长度 | 字符串大小 |
|---|---|---|
| |00pppppp| | 1 bytes | <= 63 bytes |
| |01pppppp|qqqqqqqq| | 2 bytes | <= 16383 bytes |
| |10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| | 5 bytes | <= 4294967295 bytes |
例如,我们要保存字符串:“ab”和 “bc”

整数:如果encoding是以“11”开始,则证明content是整数,且encoding固定只占用1个字节
| 编码 | 编码长度 | 整数类型 |
|---|---|---|
| 11000000 | 1 | int16_t(2 bytes) |
| 11010000 | 1 | int32_t(4 bytes) |
| 11100000 | 1 | int64_t(8 bytes) |
| 11110000 | 1 | 24位有符整数(3 bytes) |
| 11111110 | 1 | 8位有符整数(1 bytes) |
| 1111xxxx | 1 | 直接在xxxx位置保存数值,范围从0001~1101,减1后结果为实际值 |

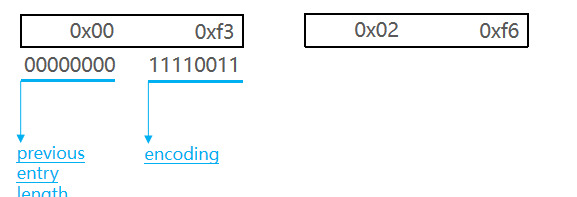
ZipList的连锁更新问题
ZipList的每个Entry都包含previous_entry_length来记录上一个节点的大小,长度是1个或5个字节:
- 如果前一节点的长度小于254字节,则采用1个字节来保存这个长度值
- 如果前一节点的长度大于等于254字节,则采用5个字节来保存这个长度值,第一个字节为0xfe,后四个字节才是真实长度数据
现在,假设我们有N个连续的、长度为250~253字节之间的entry,因此entry的previous_entry_length属性用1个字节即可表示,如图所示:

ZipList这种特殊情况下产生的连续多次空间扩展操作称之为连锁更新(Cascade Update)。新增、删除都可能导致连锁更新的发生。
举一个例子:
如上图,有 entryX-1 512字节,entryX 128字节,entryX+1 253字节,entryX+2 253 字节。
由于 entryX 元素长度为 128 字节,那么 entryX + 1 元素的 prevlen 的元素的长度就只要 1 个字节就可以了。
这个时候,在 entryX 和 entryX+1 之间加了一个 entryNew 元素,这个元素长度是 1024 字节,那么,这个时候 entryX+1 中的 prevlen 就需要变成 5 个字节了。注意:后面的元素可能也要进行更新。
当删除 entryX 的时候,entryX+1 的 prevlen 就变成了 5 字节,那么 entryX+1 的长度就变成了 257 字节;又导致后面进行更新,这种叫做连锁更新。
由于,每次扩展都将重新分配内存,导致效率很低,当更新到一次不变时,那么就不向后检查了。比如说后面有一个 entryX+3 为 100 字节,那么就不会进行检查了。

小总结:
ZipList特性:
- 压缩列表的可以看做一种连续内存空间的"双向链表"
- 列表的节点之间不是通过指针连接,而是记录上一节点和本节点长度来寻址,内存占用较低
- 如果列表数据过多,导致链表过长,可能影响查询性能
- 增或删较大数据时有可能发生连续更新问题
QuickList
问题1:ZipList虽然节省内存,但申请内存必须是连续空间,如果内存占用较多,申请内存效率很低。怎么办?
答:为了缓解这个问题,我们必须限制ZipList的长度和entry大小。
问题2:但是我们要存储大量数据,超出了ZipList最佳的上限该怎么办?
答:我们可以创建多个ZipList来分片存储数据。
问题3:数据拆分后比较分散,不方便管理和查找,这多个ZipList如何建立联系?
答:Redis在3.2版本引入了新的数据结构QuickList,它是一个双端链表,只不过链表中的每个节点都是一个ZipList。
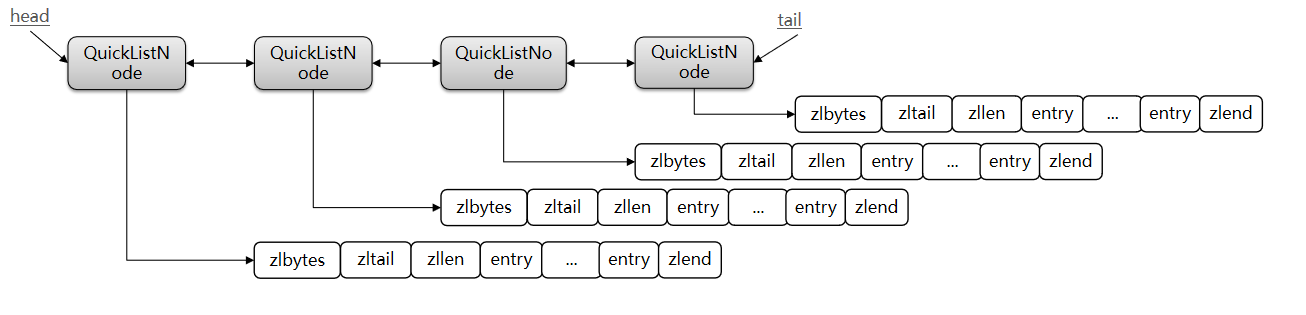
为了避免QuickList中的每个ZipList中entry过多,Redis提供了一个配置项:list-max-ziplist-size来限制。
-
如果值为正,则代表ZipList的允许的entry个数的最大值
-
如果值为负,则代表ZipList的最大内存大小,分5种情况:
- -1:每个ZipList的内存占用不能超过4kb
- -2:每个ZipList的内存占用不能超过8kb
- -3:每个ZipList的内存占用不能超过16kb
- -4:每个ZipList的内存占用不能超过32kb
- -5:每个ZipList的内存占用不能超过64kb
其默认值为 -2:

以下是QuickList的和QuickListNode的结构源码:
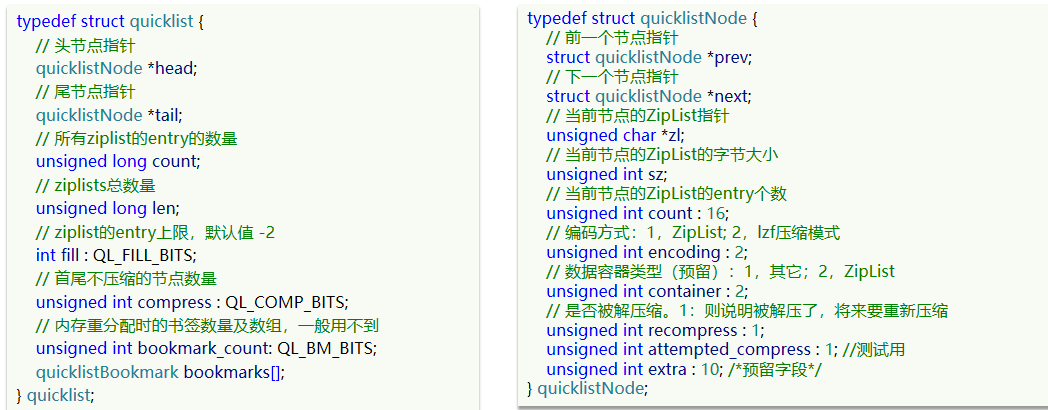
我们接下来用一段流程图来描述当前的这个结构

总结:
QuickList的特点:
- 是一个节点为ZipList的双端链表
- 节点采用ZipList,解决了传统链表的内存占用问题
- 控制了ZipList大小,解决连续内存空间申请效率问题
- 中间节点可以压缩,进一步节省了内存
SkipList
SkipList(跳表)首先是链表,但与传统链表相比有几点差异:
- 元素按照升序排列存储
- 节点可能包含多个指针,指针跨度不同。
如何理解跳表?在了解跳表之前,我们先从普通链表开始,一点点揭开跳表的神秘面纱~
首先,普通单链表来说,即使链表是有序的,我们要查找某个元素,也需要从头到尾遍历整个链表。这样效率很低,时间复杂度是O(n)。

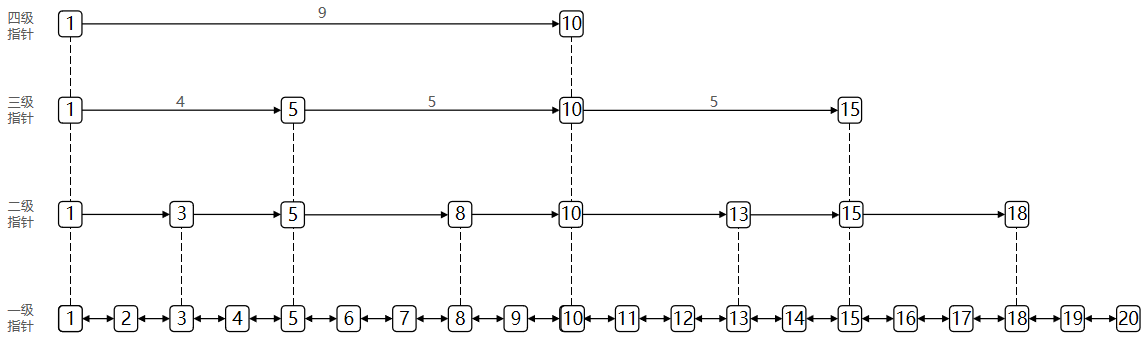
那么有没有方法提升查询效率呢?我们可以尝试为链表建立“索引”来提升查询效率。如下图,我们在原始链表的基础上,每两个元素提取一个索引,down指向原始链表的节点:

此时,假如我们要查询值为19的节点,我们从索引层开始遍历,当遍历到16时,下个节点的值为23,所以,19一定在这两个节点之间。我们通过16节点的down指针来到原始链表,将继续遍历,直到找到值为19的节点。在没有建“索引”之前,我们需要遍历8次,才能找到19,而在建立“索引”后,需要6次就能找到,也就是,索引帮我们减少了查询的次数。
那如果我们再建一级索引呢?哈哈哈,没想到吧也是6次,这是因为我们的数据量太少,即便加了两级索引,优化效果也不是很明显。在数据量大时,优化效果还是很明显的,有兴趣可以自己动手画一画。
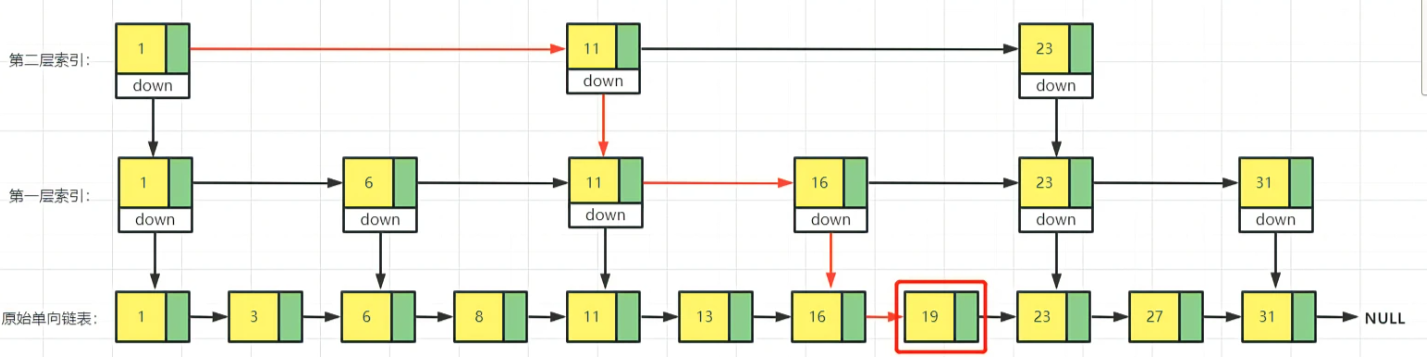
这种查找跟二分查找的时间复杂度一样O(log2n)。换句话说,我们是基于单链表实现了二分查找。但是,这种查询效率的提升是有代价的,也就是我们需要维护多层级索引,才能实现。这也是一种空间换时间的思路。
跳表的插入和删除
- 我们想在跳表中插入和删除一个节点,第一步是要找到插入和删除的位置,然后再执行插入或者删除,因为跳表的查询时间复杂度是O(log2n),插入和删除的时间复杂度也是O(log2n)。
- 插入
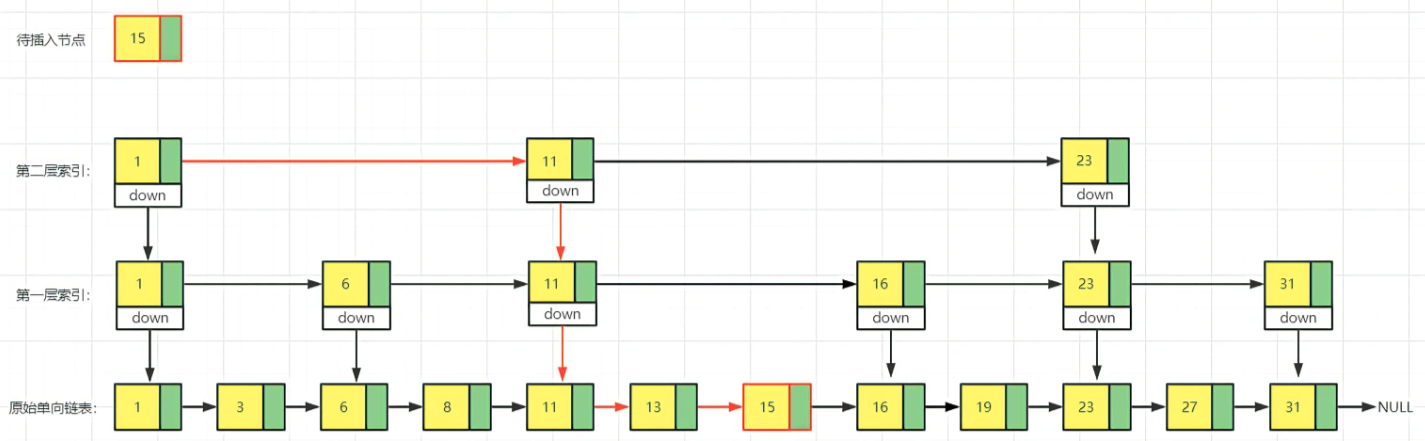
- 删除操作就需要注意一下,如果删除的节点也存在于索引节点中,那么,索引中的节点也要删除。单链表中的删除,需要拿到前驱节点的指针,如果是双向链表就不用考虑了。
跳表索引的动态更新
当我们一直往跳表中添加元素,如果不更新索引就可能出现,某2个索引之间的索引数过多,极端情况下,会退化为单向链表。
作为一种动态数据结构,我们需要某种手段作为索引节点和原始链表大小的平衡,也就是说,当链表中的节点数增多时,也响应的增加一些索引节点,避免复杂度的退化。红黑树和AVL树是通过左旋和右旋来维持左右子树的平衡。
而跳表是一种 probabilistic 数据结构,它通过随机决定每个元素的层数,来保证整个跳表的平衡。具体做法是:
当插入一个新元素时,Redis会随机决定它的层数,层数可以是1层,2层,3层,直到最大层数。层数的随机分布遵循几何分布,层数越高,其出现的概率越低。
举例来说,如果我们设置最大层数为5,那么:
- 层数为1的概率50%
- 层数为2的概率25%
- 层数为3的概率12.5%
- 层数为4的概率6.25%
- 层数为5的概率3.125%
从这个分布可以看出,层数越高的元素出现的概率会显著下降。这就使得高层元素较为“稀疏”,而低层较为“密集”。
这样,高层元素就像是跳表的快速通道,用于快速遍历和查找。而低层则包含更丰富的元素,可以精确查找每一个元素。
这种随机分布的层数,显著减少了跳表的倾斜几率,使其总体来说是均衡的。因为高层元素较稀疏,所以遍历和查找能够快速跳过大量低层元素,获得较高性能。
而相比AVL树和红黑树等平衡树,跳表的随机性使其逻辑更简单,无须进行频繁旋转来维持平衡,这也使其性能更高。这也是Redis选择跳表的一个重要原因。
总之,跳表通过为每个新元素随机分配层数,来保证其总体平衡。层数遵循几何分布,高层较稀疏,低层较密集。这使得跳表既有快速查找的能力,也可以精确访问每个元素。
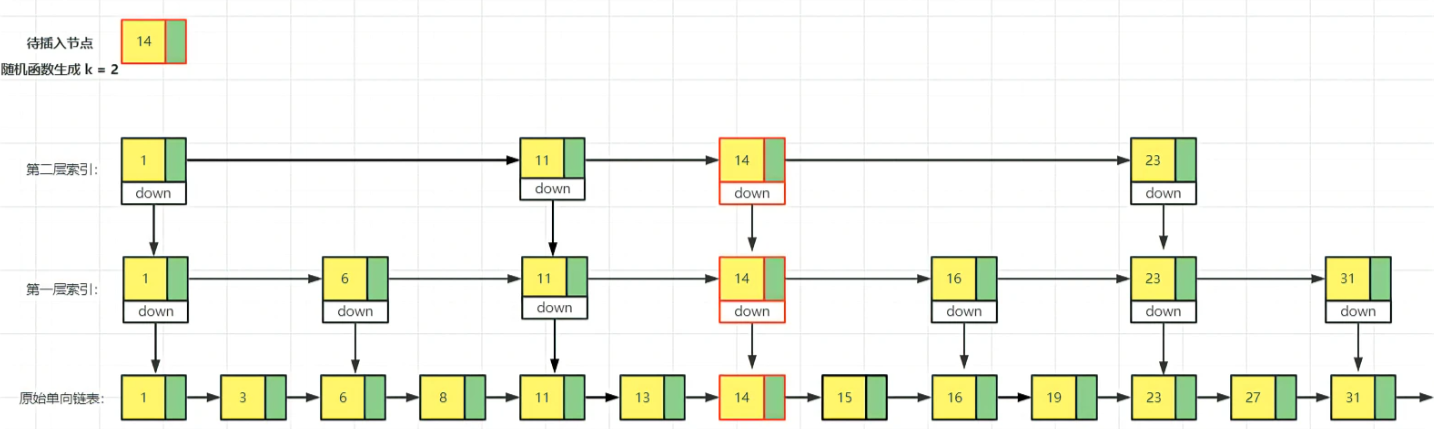
跳表源码结构


小总结:
SkipList的特点:
- 跳跃表是一个双向链表,每个节点都包含score和ele值
- 节点按照score值排序,score值一样则按照ele字典排序
- 每个节点都可以包含多层指针,层数是1到32之间的随机数
- 不同层指针到下一个节点的跨度不同,层级越高,跨度越大
- 增删改查效率与红黑树基本一致,实现却更简单
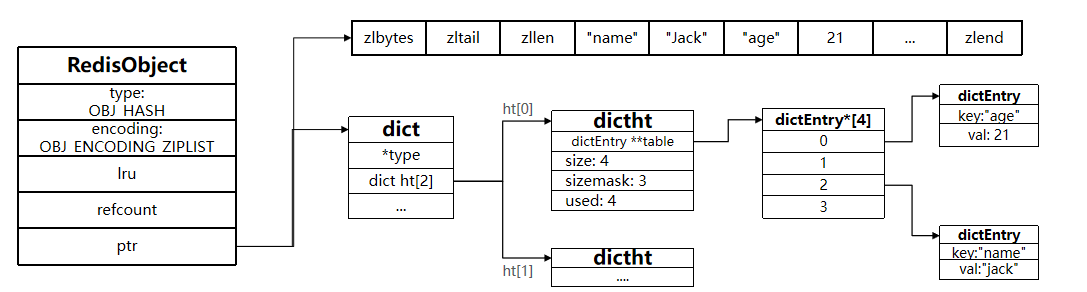
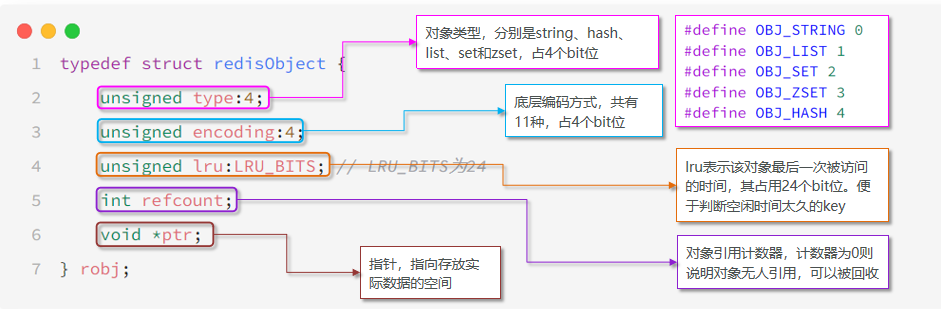
RedisObject
redisObject是一个C语言构造,所有的Redis对象的数据类型以及值都存储在这个结构中。我们平时操作的字符串、列表、散列等对象,其内部实现全部用redisObject来构造的。
举个例子,一个Redis字符串对象在内存中大致结构如下:
redisObject
- type: REDIS_STRING
- encoding: REDIS_ENCODING_EMBSTR
- ptr: 指向embstr字符串结构
embstr
- size: 字符串长度
- buf: char数组,保存字符串值
redisObject是一个非常轻量级的结构,里面只包含必要的字段,这使得Redis可以创建和销毁对象的代价非常低,这也是Redis可以达到亚秒级响应的原因之一。
同时,将不同对象通过type字段区分,encoding字段指定值的具体存储结构,这使得Redis的对象系统非常灵活和易扩展。Redis可以很容易地添加新的数据类型。
redisObject源码
Redis的编码方式
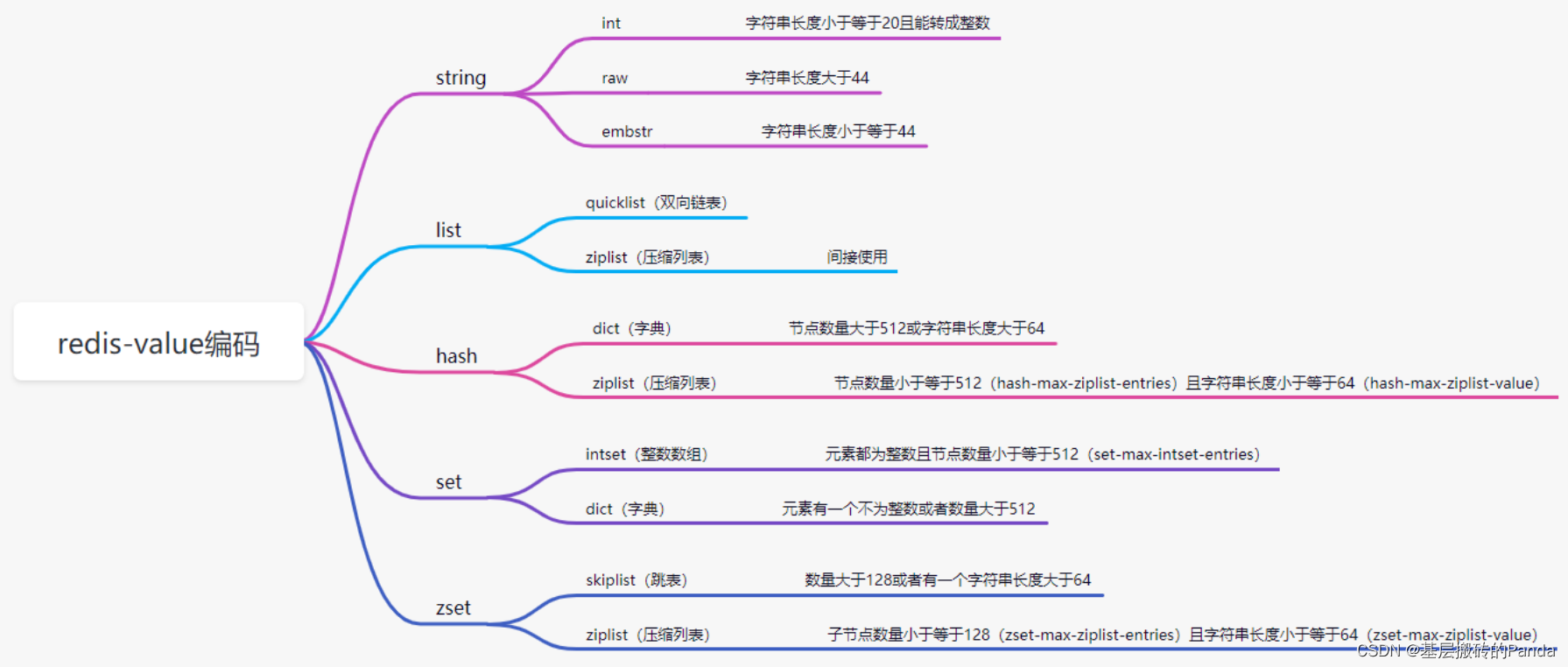
Redis中会根据存储的数据类型不同,选择不同的编码方式,共包含11种不同类型:
| 编号 | 编码方式 | 说明 |
|---|---|---|
| 0 | OBJ_ENCODING_RAW | raw编码动态字符串 |
| 1 | OBJ_ENCODING_INT | long类型的整数的字符串 |
| 2 | OBJ_ENCODING_HT | hash表(字典dict) |
| 3 | OBJ_ENCODING_ZIPMAP | 已废弃 |
| 4 | OBJ_ENCODING_LINKEDLIST | 双端链表 |
| 5 | OBJ_ENCODING_ZIPLIST | 压缩列表 |
| 6 | OBJ_ENCODING_INTSET | 整数集合 |
| 7 | OBJ_ENCODING_SKIPLIST | 跳表 |
| 8 | OBJ_ENCODING_EMBSTR | embstr的动态字符串 |
| 9 | OBJ_ENCODING_QUICKLIST | 快速列表 |
| 10 | OBJ_ENCODING_STREAM | Stream流 |
五种数据结构
Redis中会根据存储的数据类型不同,选择不同的编码方式。每种数据类型的使用的编码方式如下:
| 数据类型 | 编码方式 |
|---|---|
| OBJ_STRING | int、embstr、raw |
| OBJ_LIST | LinkedList和ZipList(3.2以前)、QuickList(3.2以后) |
| OBJ_SET | intset、HT |
| OBJ_ZSET | ZipList、HT、SkipList |
| OBJ_HASH | ZipList、HT |
String
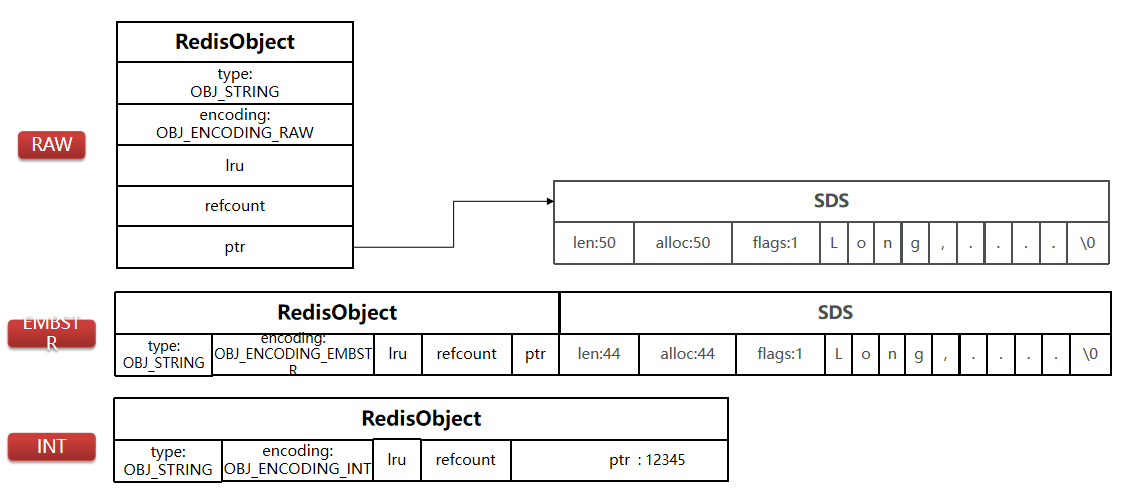
String是Redis中最常见的数据存储类型
底层实现⽅式:动态字符串SDS或者 Long
-
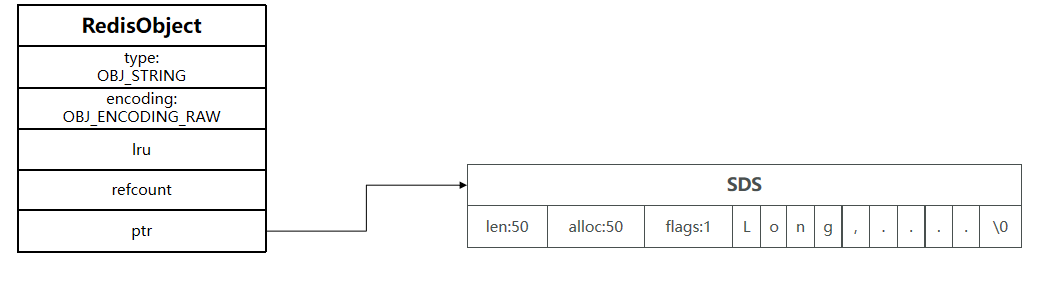
其基本编码方式是RAW,基于简单动态字符串(SDS)实现,存储上限为512MB。
-
如果存储的SDS长度小于44字节,则会采用EMBSTR编码,此时object head与SDS是一段连续空间。申请内存时只需要调用一次内存分配函数,效率更高。
-
如果存储的字符串是整数值,并且大小在LONG_MAX范围内,则会采用INT编码:直接将数据保存在RedisObject的ptr指针位置(刚好8字节),不再需要SDS了。
确切地说,String在Redis中是⽤⼀个robj来表示的。
用来表示String的robj可能编码成3种内部表⽰:OBJ_ENCODING_RAW,OBJ_ENCODING_EMBSTR,OBJ_ENCODING_INT。
其中前两种编码使⽤的是SDS来存储,最后⼀种OBJ_ENCODING_INT编码直接把string存成了Long型。
在对string进行incr, decr等操作的时候,如果它内部是OBJ_ENCODING_INT编码,那么可以直接行加减操作;如果它内部是OBJ_ENCODING_RAW或OBJ_ENCODING_EMBSTR编码,那么Redis会先试图把SDS存储的字符串转成Long型,如果能转成功,再进行加减操作。
对⼀个内部表示成Long型的string执行append, setbit, getrange这些命令,针对的仍然是string的值(即十进制表示的字符串),而不是针对内部表⽰的long型进⾏操作。
比如字符串”32”,如果按照字符数组来解释,它包含两个字符,它们的ASCII码分别是0x33和0x32。当我们执行命令setbit key 7 0的时候,相当于把字符0x33变成了0x32,这样字符串的值就变成了”22”。⽽如果将字符串”32”按照内部的64位long型来解释,那么它是0x0000000000000020,在这个基础上执⾏setbit位操作,结果就完全不对了。因此,在这些命令的实现中,会把long型先转成字符串再进行相应的操作。
List
Redis的List类型可以从首、尾操作列表中的元素:
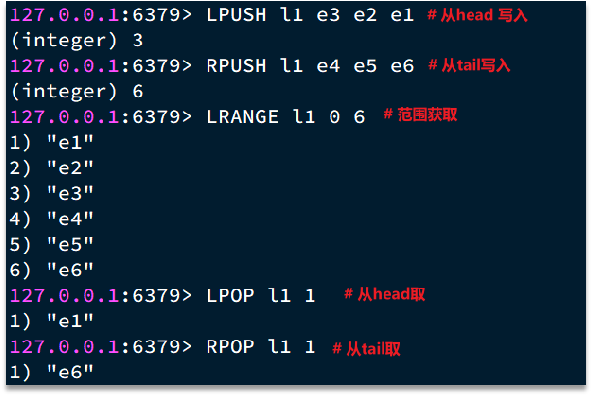
哪一个数据结构能满足上述特征?
- LinkedList :普通链表,可以从双端访问,内存占用较高,内存碎片较多
- ZipList :压缩列表,可以从双端访问,内存占用低,存储上限低
- QuickList:LinkedList + ZipList,可以从双端访问,内存占用较低,包含多个ZipList,存储上限高
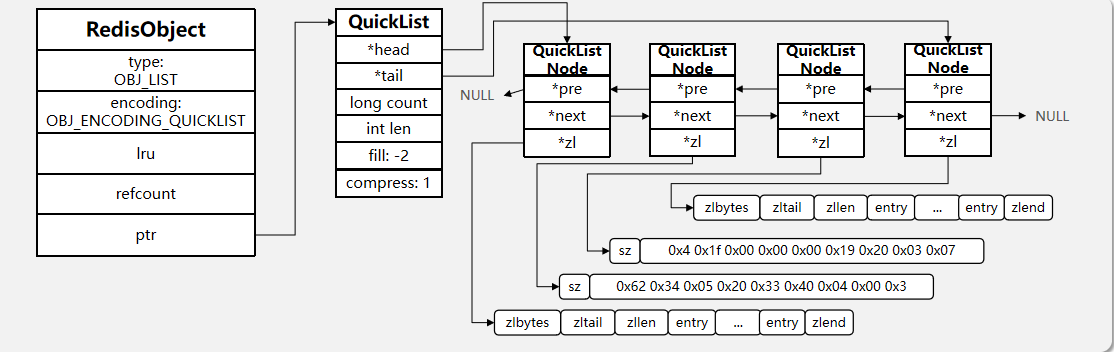
Redis的List结构类似一个双端链表,可以从首、尾操作列表中的元素:
在3.2版本之前,Redis采用ZipList和LinkedList来实现List,当元素数量小于512并且元素大小小于64字节时采用ZipList编码,超过则采用LinkedList编码。
在3.2版本之后,Redis统一采用QuickList来实现List:
Set结构
Set是Redis中的单列集合,满足下列特点:
- 不保证有序性
- 保证元素唯一
- 求交集、并集、差集
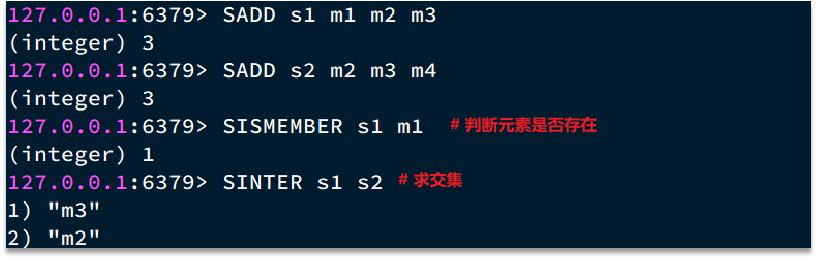
可以看出,Set对查询元素的效率要求非常高,思考一下,什么样的数据结构可以满足?
HashTable,也就是Redis中的Dict,不过Dict是双列集合(可以存键、值对)
Set是Redis中的集合,不一定确保元素有序,可以满足元素唯一、查询效率要求极高。
为了查询效率和唯一性,set采用HT编码(Dict)。Dict中的key用来存储元素,value统一为null。
当存储的所有数据都是整数,并且元素数量不超过set-max-intset-entries时,Set会采用IntSet编码,以节省内存
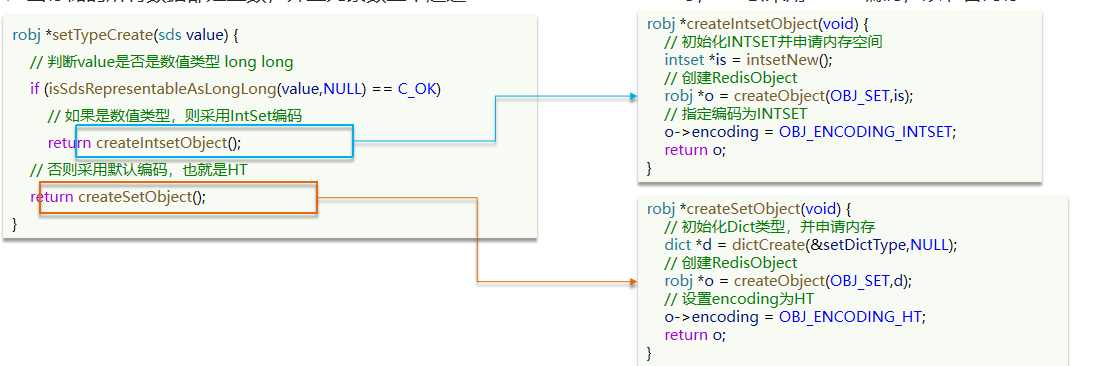
结构如下:
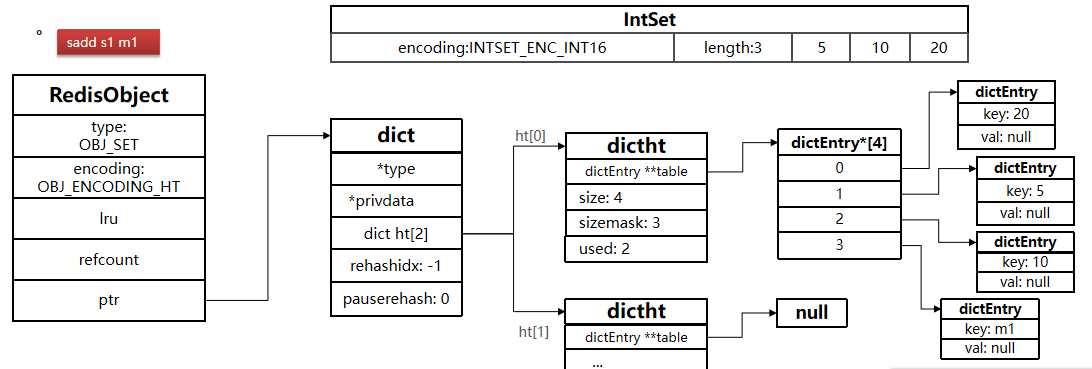
ZSET
ZSet也就是SortedSet,其中每一个元素都需要指定一个score值和member值:
- 可以根据score值排序后
- member必须唯一
- 可以根据member查询分数

因此,zset底层数据结构必须满足键值存储、键必须唯一、可排序这几个需求。之前学习的哪种编码结构可以满足?
- SkipList:可以排序,并且可以同时存储score和ele值(member)
- HT(Dict):可以键值存储,并且可以根据key找value

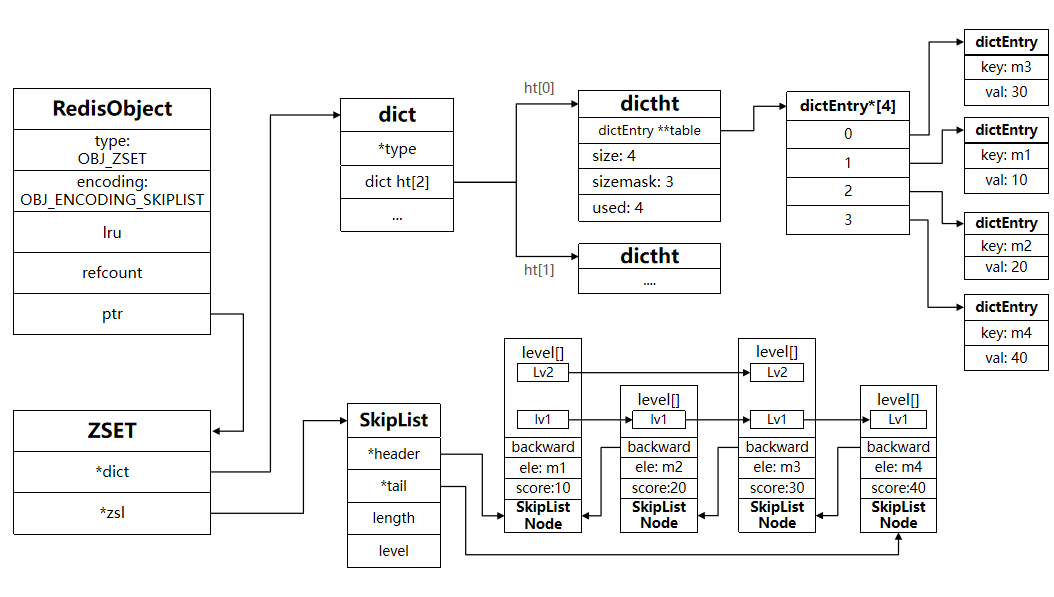
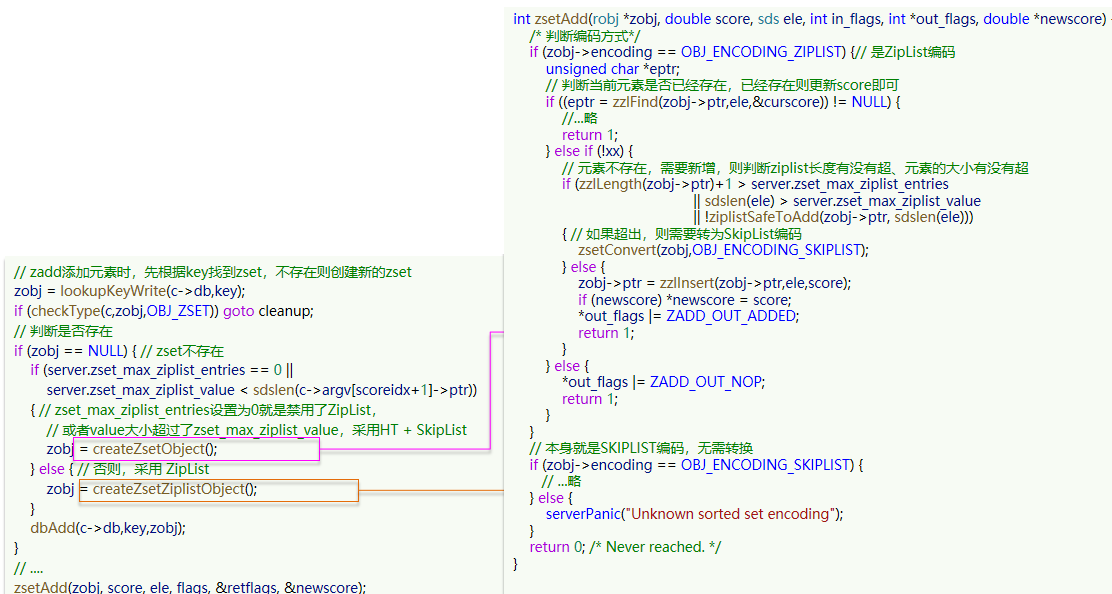
当元素数量不多时,HT和SkipList的优势不明显,而且更耗内存。因此zset还会采用ZipList结构来节省内存,不过需要同时满足两个条件:
- 元素数量小于zset_max_ziplist_entries,默认值128
- 每个元素都小于zset_max_ziplist_value字节,默认值64
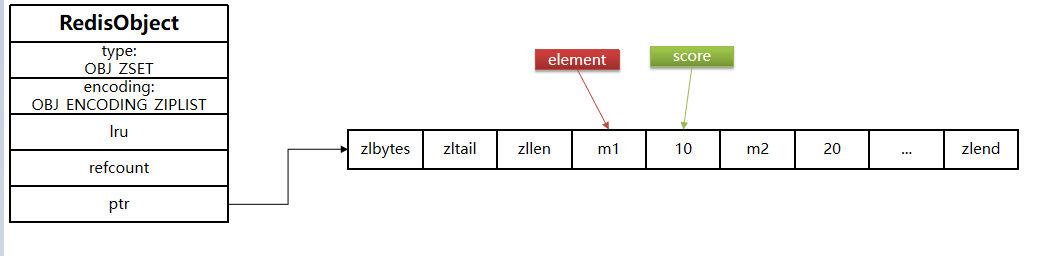
ziplist本身没有排序功能,而且没有键值对的概念,因此需要有zset通过编码实现:
- ZipList是连续内存,因此score和element是紧挨在一起的两个entry, element在前,score在后
- score越小越接近队首,score越大越接近队尾,按照score值升序排列
Hash
Hash结构与Redis中的Zset非常类似:
- 都是键值存储
- 都需求根据键获取值
- 键必须唯一
区别如下:
- zset的键是member,值是score;hash的键和值都是任意值
- zset要根据score排序;hash则无需排序
(1)底层实现方式:压缩列表ziplist 或者 字典dict
当Hash中数据项比较少的情况下,Hash底层才⽤压缩列表ziplist进⾏存储数据,随着数据的增加,底层的ziplist就可能会转成dict,具体配置如下:
-
hash-max-ziplist-entries 512
-
hash-max-ziplist-value 64
当满足上面两个条件其中之⼀的时候,Redis就使⽤dict字典来实现hash。
Redis的hash之所以这样设计,是因为当ziplist变得很⼤的时候,它有如下几个缺点:
- 每次插⼊或修改引发的realloc操作会有更⼤的概率造成内存拷贝,从而降低性能。
- ⼀旦发生内存拷贝,内存拷贝的成本也相应增加,因为要拷贝更⼤的⼀块数据。
- 当ziplist数据项过多的时候,在它上⾯查找指定的数据项就会性能变得很低,因为ziplist上的查找需要进行遍历。
总之,ziplist本来就设计为各个数据项挨在⼀起组成连续的内存空间,这种结构并不擅长做修改操作。⼀旦数据发⽣改动,就会引发内存realloc,可能导致内存拷贝。
hash结构如下:
zset集合如下:

因此,Hash底层采用的编码与Zset也基本一致,只需要把排序有关的SkipList去掉即可:
Hash结构默认采用ZipList编码,用以节省内存。 ZipList中相邻的两个entry 分别保存field和value
当数据量较大时,Hash结构会转为HT编码,也就是Dict,触发条件有两个:
- ZipList中的元素数量超过了hash-max-ziplist-entries(默认512)
- ZipList中的任意entry大小超过了hash-max-ziplist-value(默认64字节)