论文总结
以下是我阅读完整篇论文做的个人总结,基本包含了chatGPT1设计的完整框架思路,可以仅看【论文总结】章节。
在GPT1实现的核心架构中,包含两个阶段。
第一阶段
在第一阶段基于一个包含7000本书籍内容的海量未标注文本数据集进行无监督预训练,该阶段引入了一种Transformer模型的变形,GPT1增加了Transformer模型的中间层,并调整了部分模型结构和参数。
第二阶段
在第二阶段,实验组引入12个更加具体的标注文本数据集(诸如中学学校问答文本、政府工作报告文档、文本隐含情感标注文档)进行参数微调。基于第一阶段的模型输出,实验组基于标注数据再训练一个二阶段的线性学习模型。一、二两个阶段模型相加,就得到了最终的GPT1模型。
第二阶段的辅助目标学习
对于GPT1模型的架构,还有很重要的一步,就是在第二阶段参数微调的过程中,还要引入特定的辅助目标学习,具体实现方式是将输入文本进行特定的转化,例如修改分类文本输入的数学表示格式(加入特定的分隔符用于标注分词含义)、修改相似语义句型的词汇先后顺序,这种辅助目标学习可以显著提升模型的泛化能力。
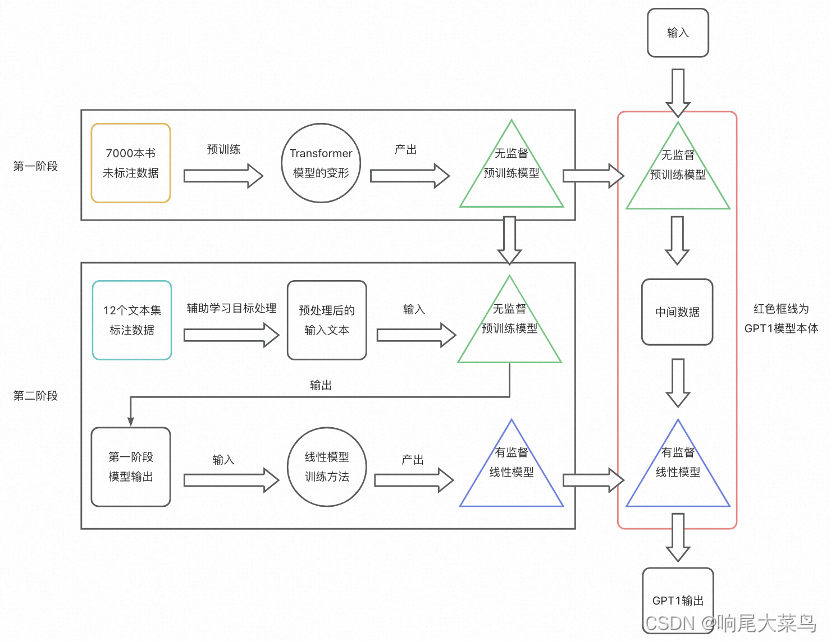
最终实验产生了几个重要结论
第一,预训练阶段增加Transformer中间层可以显著提升效果;
第二,整个模型在12个数据集中的9个取得了更好的效果,说明该模型架构设计很不错,值得继续深入研究;
第三,辅助目标学习对于数据量越大的场景,可以越提升模型 的泛化能力。
论文原文解读
注:原文中的公式在这篇解读文里基本上都没有引入,因为那些公式基本都是需要依赖于前置知识,并不是基础的数学公式。例如集合表示、Transformer相关函数、线性回归算法、softmax函数等。这篇论文解读仅以阐述思想为主,以下内容开始为原本的细致解读。
原论文地址:https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
一、综述
过去的很多NLP(nature language processing)模型需要大量人工标注的数据进行训练,这些数据是人工标注含义和目标结果的文本数据。因此过去的模型训练常常限制在标注数据层面,标注数据决定了模型的好坏。基于这种局限性,本文提出一种新型的、可直接通过未标注数据进行训练的模型就可以获得巨大的收益。
基于未标注数据训练的NLP模型需要解决两个最重要的问题。第一,采用何种模型加速优化手段是未知的,这也是近期研究的热点,最近有很多研究方向是探讨诸如机器翻译、文本连贯性问题的性能优化方案。第二,没有高效的方法将这种模型学习到的表征转化为目标任务,现有技术包括对模型体系结构进行特定任务的更改、使用复杂的学习方案和添加辅助学习目标。
本文探讨了一种半监督实现,用于语言理解任务,这种实现结合了无监督预训练和有监督微调方法。实验方法是用未标注数据进行训练,用标注数据进行测试。本方案采用两个阶段进行训练,首先使用未标注数据训练一组神经网络参数,之后再用适当的标注数据进行参数微调。
在模型架构中,本方案采用了Transformer模型,该模型在机器翻译、文档生成、句法分析领域表现优异。最终得到的模型方案相比于传统模型,效果更好,总共在自然语言推理,问题回答,语义相似度和文本分类的12个测试中,9个测试胜出。
二、涉及到的相关研究有
NLP半监督学习模型
半监督学习模型在序列标注、文本分类。过去几年,研究者发现单词嵌套可以提升未标注数据的训练效果,但该方案仅在单词信息理解层面取得一定的进步。最近的研究已经开始解决更长句子的理解,利用语法、语句级别的嵌套方法。
无监督预训练模型
无监督训练模型属于一种特殊的半监督学习模型,它提供了一种解决对应问题的初始模型。早起的无监督训练模型解决了图片分类和回归任务。近期,无监督训练模型辅助深度神经网络,在图片分类、语音识别、文本消除歧义和机器翻译。本方案中最直接的使用形式就是基于一个无监督预训练的神经网络模型之上,进行有监督的参数微调,从而提升文本分类效果。鉴于LSTM模型只能在较短的语句上有一定效果,本方案采用Transformer网络模型来识别长语句结构。之后,我们还研究了本方案在语言推理、转述检测和编写完整故事。但这种方案会导致针对每个不同目标的大量参数产生。
辅助训练目标
辅助训练目标是一种半监督学习模型的替代方案,过去的研究使用了大量的辅助NLP任务对文本进行标注、打包、命名歧义来提升语言识别效果。本方案也采用了辅助目标进行训练。
三、模型架构设计
本模型有两个阶段,第一阶段会基于海量的文本集学习一个大容量的语言模型,第二阶段基于标注数据进行参数微调。
3.1无监督预训练
对一个超大的文本集,使用随机梯度下降算法训练先获得一部分参数。在本实验中,我们使用多层Transformer解码器(multi-layer Transformer decoder)处理语言模型,这是一种Transformer的变种模型,它实现了一种多目标自关注操作。这里省略了大量公式,详情需要先前置学习Transformer模型。
3.2有监督参数微调
首先提供一个打过标的数据集C,这个数据集中每个输入x都有一个对应的标签y。将数据集输入通过预训练模型,得到一个中间过程值。再将过程值进行线性模型训练,最终回归到标签y上。我们发现这种调参方法可以大大提升模型的泛化能力。
3.3特定于任务的输入转换
上述过程可以很好的应用于文本分类模型,但是对于语言问答、文本的内涵等等具有结构化和乱序的复杂语言处理上,需要再对模型进行修改。本实验使用了一个遍历方案,将输入转化成一个预训练模型可以很好处理的顺序序列。对于每一种不同的输入类型,本方案处理如下。
文本的内涵
通过在模型中,前提p和假设h之间加入一个变量t。
相似文本
对于相似文本的判断,我们改变了输入文本内词之间的顺序。
问答类
一个问题q,一段文档z,一组可能的答案{ak…}。我们将问题q和文档z进行连接,并标注答案{ak…},得到一组输入{z, q, $, ak}。随后通过Sofrmax层进行归一化,形成一个答案分布矩阵。
四、实验
4.1设置
我们使用BooksCorpus数据集用来训练模型,该模型包含7000本未发表的书籍,内容包含冒险、幻想、浪漫等题材,这些书籍中包含大量的长句来训练模型。我们还有另一个替代数据集1B Word Benchmark,该数据集合前者在数据量上是差不多的,但是后者相比于前者缺少了大量的长句素材。
在预训练模型中主要还是沿用了Transformer模型的架构。在参数微调阶段采用了线性回归模型进行训练。
4.2有监督参数微调
自然语言推理(Natural Language Inference, NLI)
自然语言推理就是研究文本的内涵的方法,他分析的是词汇、语句之间的关系以及隐式含义。我们在大量数据集上验证了模型的效果,包括图片说明、记录演讲、热销小说、政府报告、维基百科、科学实验、新闻报道等题材。实验结果表明本方案的模型在5项测试维度下的4项取得了更好的效果。
问答类
我们使用最新的RACE数据集进行实验,该数据集包含大量中学学校的问答文本,并且该数据集在问题和答案之间做了更好的标注关联,更有利于我们的模型进行学习。该数据集的实验结果也表明我们的模型效果更优,问答填空率提升8.9%。
语义相似度
语义相似度用于预测两句话是否表达相同的含义,该领域的研究难点在于概念重述、理解否定、处理句法歧义等。我们使用3个数据集进行实验,包括微软文本集MRPC、问答集QQP和相似文本数据集STS-B,最终显示我们的模型在准确度上提升4.2%。
分类
分类实验中,我们用模型去判断一组单词是符合语法的还是随意的词组组合(使用数据集CoLA),同时也要判断语法的情感分析(使用二分类数据集SST-2)。最终测试结果显示,我们的模型在CoLA数据集测试中将分类效果分数从35提升到了45.4。在SST-2数据集测试中取得91.3%的准确率,该准确率已达到工业应用级别。
总而言之,我们的模型在12项数据集测试中,9项取得了更好的数据效果,这显示我们的模型在NLP处理能力取得了较大的进步。
五、分析
模型中间层数量的影响
我们尝试增加Transformer中间层,数据结果显示增加中间层,可以显著的提升模型精准度,平均每增加一个中间层,可以带来9%的提升。这说明预训练模型的每一个中间层都包含了对于最终结果有价值的信息。
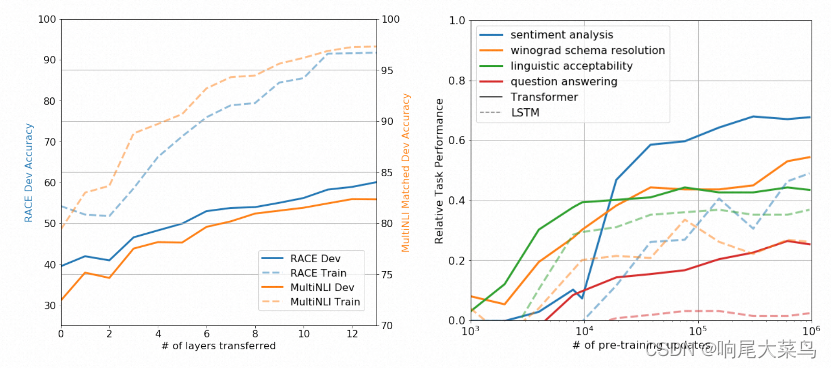
消融实验
我们尝试了在第二步参数微调中去除辅助学习目标,结果表明整体模型效果下降很多。这说明在进行更海量的数据集实验时,模型会更受益于辅助学习目标。
其次,我们还尝试了将Transformer模型替换成一个长短期记忆人工神经网络模型(Long Short-Term Memory, LSTM),替换之后,模型效果平均下降了5.6分,LSTM模型仅仅在MRPC数据集上表现好于Transformer模型(MRPC数据集是语义相似度实验中用到的一个数据集)。
六、总结
我们引入一个预训练模型,并对他进行辅助训练目标的参数微调,最终得到了一个更有效果的NLP模型。该模型显著提升了机器处理长依赖关系的文本能力,更好的解决歧义性任务,实验过程表明在12项数据集测试中9项数据集取得了更好成绩。我们的实验还表明,使用无监督预训练来提高文本辨别任务,给NLP模型带来显著效果提升是完全可行的。我们希望这项研究可以有促进对自然语言理解和其他领域无监督预训练学习模型的更多研究。