Hbase入门篇01---基本概念和部署教程
- HBase基本概念
- Hadoop
- Hadoop的局限
- HBase 与 NoSQL
- HBase应用场景
- 发展历程
- HBase特点
- RDBMS与HBase的对比
- 关系型数据库
- HBase
- HDFS对比HBase
- Hive对比Hbase
- 总结Hive与HBase
- HBase集群搭建
- HBASE_MANAGES_ZK属性的作用
- 安装报错,解决思路是什么
- zk集群通信异常 ?
- HBase RegionServer 节点连接 HMaster 节点出现无效参数异常?
- WebUI访问测试
- hbase安装目录
- hbase参考硬件配置
HBase基本概念
Hadoop
从 1970 年开始,大多数的公司数据存储和维护使用的是关系型数据库,大数据技术出现后,很多拥有海量数据的公司开始选择像Hadoop的方式来存储海量数据。
Hadoop使用分布式文件系统HDFS来存储海量数据,并使用 MapReduce 来处理。Hadoop擅长于存储各种格式的庞大的数据,任意的格式甚至非结构化的处理
Hadoop的局限
Hadoop主要是实现批量数据的处理,并且通过顺序方式访问数据,要查找数据必须搜索整个数据集, 如果要进行随机读取数据,效率较低。
HBase 与 NoSQL

-
NoSQL是一个通用术语,泛指一个数据库并不是使用SQL作为主要语言的非关系型数据库。
-
HBase是BigTable的开源java版本。是建立在HDFS之上,提供高可靠性、高性能、列存储、可伸缩、实时读写NoSQL的数据库系统。
学习HBase之前可以先阅读一下Gfs,MapReduce,BigTable三篇论文,然后再阅读HBase的论文。
- Hadoop入门篇01—基础概念和部署教程
- Hadoop入门篇02—HDFS学习与简单使用
- HBase仅能通过主键(row key)和主键的range来检索数据,仅支持单行事务,主要用来存储结构化和半结构化的松散数据
- Hbase查询数据功能很简单,不支持join等复杂操作,不支持复杂的事务(行级的事务),从技术上来说,HBase更像是一个「数据存储」而不是「数据库」,因为HBase缺少RDBMS中的许多特性,例如带类型的列、二级索引以及高级查询语言等。
- Hbase中支持的数据类型:byte[]
- 与Hadoop一样,Hbase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加存储和处理能力,例如,把集群从10个节点扩展到20个节点,存储能力和处理能力都会加倍
- HBase中的表一般有这样的特点
- 大:一个表可以有上十亿行,上百万列
- 面向列:面向列(族)的存储和权限控制,列(族)独立检索
- 稀疏:对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏
HBase应用场景
- 对象存储
- 不少的头条类、新闻类的的新闻、网页、图片存储在HBase之中,一些病毒公司的病毒库也是存储在HBase之中
- 时序数据
- HBase之上有OpenTSDB模块,可以满足时序类场景的需求
- 推荐画像
- 用户画像,是一个比较大的稀疏矩阵,蚂蚁金服的风控就是构建在HBase之上
- 时空数据
- 主要是轨迹、气象网格之类,滴滴打车的轨迹数据主要存在HBase之中,另外在技术所有大一点的数据量的车联网企业,数据都是存在HBase之中
- CubeDB OLAP
- Kylin一个cube分析工具,底层的数据就是存储在HBase之中,不少客户自己基于离线计算构建cube存储在hbase之中,满足在线报表查询的需求
- 消息/订单
- 在电信领域、银行领域,不少的订单查询底层的存储,另外不少通信、消息同步的应用构建在HBase之上
- Feeds流
- 典型的应用就是xx朋友圈类似的应用,用户可以随时发布新内容,评论、点赞。
- NewSQL
- 之上有Phoenix的插件,可以满足二级索引、SQL的需求,对接传统数据需要SQL非事务的需求
- 其他
- 存储爬虫数据
- 海量数据备份
- 短网址
发展历程
| 年份 | 重大事件 |
|---|---|
| 2006年11月 | Google发布BigTable论文. |
| 2007年10月 | 发布第一个可用的HBase版本,基于Hadoop 0.15.0 |
| 2008年1月 | HBase成为Hadoop的一个子项目 |
| 2010年5月 | HBase成为Apache的顶级项目 |
HBase特点
- 强一致性读/写
- HBASE不是“最终一致的”数据存储
- 它非常适合于诸如高速计数器聚合等任务
- 自动分块
- HBase表通过Region分布在集群上,随着数据的增长,区域被自动拆分和重新分布
- 自动RegionServer故障转移
- Hadoop/HDFS集成
- HBase支持HDFS开箱即用作为其分布式文件系统
- MapReduce
- HBase通过MapReduce支持大规模并行处理,将HBase用作源和接收器
- Java Client API
- HBase支持易于使用的 Java API 进行编程访问
- Thrift/REST API
- 块缓存和布隆过滤器
- HBase支持块Cache和Bloom过滤器进行大容量查询优化
- 运行管理
- HBase为业务洞察和JMX度量提供内置网页。
RDBMS与HBase的对比
关系型数据库
结构:
- 数据库以表的形式存在
- 支持FAT、NTFS、EXT、文件系统
- 使用主键(PK)
- 通过外部中间件可以支持分库分表,但底层还是单机引擎
- 使用行、列、单元格
功能:
- 支持向上扩展(买更好的服务器)
- 使用SQL查询
- 面向行,即每一行都是一个连续单元
- 数据总量依赖于服务器配置
- 具有ACID支持
- 适合结构化数据
- 传统关系型数据库一般都是中心化的
- 支持事务
- 支持Join
HBase
结构:
- 以表形式存在
- 支持HDFS文件系统
- 使用行键(row key)
- 原生支持分布式存储、计算引擎
- 使用行、列、列蔟和单元格
功能:
- 支持向外扩展
- 使用API和MapReduce、Spark、Flink来访问HBase表数据
- 面向列蔟,即每一个列蔟都是一个连续的单元
- 数据总量不依赖具体某台机器,而取决于机器数量
- HBase不支持ACID(Atomicity、Consistency、Isolation、Durability)
- 适合结构化数据和非结构化数据
- 一般都是分布式的
- HBase不支持事务,支持的是单行数据的事务操作
- 不支持Join
HDFS对比HBase
HDFS:
- HDFS是一个非常适合存储大型文件的分布式文件系统
- HDFS它不是一个通用的文件系统,也无法在文件中快速查询某个数据
HBase:
- HBase构建在HDFS之上,并为大型表提供快速记录查找(和更新)
- HBase内部将大量数据放在HDFS中名为「StoreFiles」的索引中,以便进行高速查找
- Hbase比较适合做快速查询等需求,而不适合做大规模的OLAP应用
Hive对比Hbase
Hive:
- 数据仓库工具
- Hive的本质其实就相当于将HDFS中已经存储的文件在Mysql中做了一个双射关系,以方便使用HQL去管理查询
- 用于数据分析、清洗
- Hive适用于离线的数据分析和清洗,延迟较高
- 基于HDFS、MapReduce
- Hive存储的数据依旧在DataNode上,编写的HQL语句终将是转换为MapReduce代码执行
HBase:
- NoSQL数据库
- 是一种面向列存储的非关系型数据库。
- 用于存储结构化和非结构化的数据
- 适用于单表非关系型数据的存储,不适合做关联查询,类似JOIN等操作。
- 基于HDFS
- 数据持久化存储的体现形式是Hfile,存放于DataNode中,被ResionServer以region的形式进行管理
- 延迟较低,接入在线业务使用
- 面对大量的企业数据,HBase可以直线单表大量数据的存储,同时提供了高效的数据访问速度
总结Hive与HBase
- Hive和Hbase是两种基于Hadoop的不同技术
- Hive是一种类SQL的引擎,并且运行MapReduce任务
- Hbase是一种在Hadoop之上的NoSQL 的Key/value数据库
- 这两种工具是可以同时使用的。就像用Google来搜索,用FaceBook进行社交一样,Hive可以用来进行统计查询,HBase可以用来进行实时查询,数据也可以从Hive写到HBase,或者从HBase写回Hive
HBase集群搭建
HBase的安装是建立在Hadoop之上的,所以请先简单学习一下Hadoop的使用和安装教程:
- Hadoop入门篇01—基础概念和部署教程
- Hadoop入门篇02—HDFS学习与简单使用
- 放行HBase通信占用的相关端口
HBase集群内的不同组件之间需要进行通信,因此需要放行一些端口,具体如下:
- HMaster和HRegionServer之间的通信:默认使用60000端口。
- HBase客户端和HBase集群之间的通信:默认使用2181端口的ZooKeeper端口。
- HBase的Web界面:默认使用16010端口。
- HBase的Thrift服务:默认使用9090端口。
如果你启用了HBase的Kerberos安全认证,还需要放行以下端口:
- 88端口:Kerberos认证服务端口。
- 749端口:Kerberos管理服务端口。
- 464端口:Kerberos密码改变服务端口。
请注意,上述端口是HBase的默认端口,如果你在配置HBase时更改了某些端口,则需要放行相应的端口。
在ZooKeeper集群中,以下是需要放行的端口:
- ZooKeeper客户端连接ZooKeeper服务器的端口,默认为2181(TCP)
- ZooKeeper服务器之间的通信端口,默认为2888(TCP),用于服务器之间的互相通信
- 用于Leader选举的端口,默认为3888(TCP)
这三个端口是ZooKeeper集群通信的必要端口,确保这些端口在防火墙中正确地打开,以确保ZooKeeper集群能够正常通信。
最暴力的方法就是放行全部端口,省得麻烦。
- 上传解压HBase安装包
# -C 指定解压后的文件存放目录
tar -xvzf hbase-2.1.0.tar.gz -C ../server/
- 修改hbase-env.sh配置文件(JDK环境请提前配置好)
cd /export/server/hbase-2.1.0/conf
vim hbase-env.sh
# 第28行
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HBASE_MANAGES_ZK=false
- 修改hbase-site.xml配置文件
<configuration>
<!-- HBase数据在HDFS中的存放的路径 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://node1:8020/hbase</value>
</property>
<!-- Hbase的运行模式。false是单机模式,true是分布式模式。若为false,Hbase和Zookeeper会运行在同一个JVM里面 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- ZooKeeper的地址 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>node1,node2,node3</value>
</property>
<!-- ZooKeeper快照的存储位置 -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/export/server/apache-zookeeper-3.6.0-bin/data</value>
</property>
<!-- V2.1版本,在分布式情况下, 设置为false -->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
HBASE_MANAGES_ZK属性的作用
export HBASE_MANAGES_ZK=false 是一个HBase环境变量的设置,用于告诉HBase不要启动自己的ZooKeeper服务。如果你的HBase集群中已经有一个独立的ZooKeeper集群在运行,你就可以将该变量设置为false,从而避免HBase再次启动ZooKeeper服务,节省资源和避免冲突。
具体来说,当HBASE_MANAGES_ZK环境变量的值为true时,HBase会在启动时自动启动一个ZooKeeper服务,用于协调和管理HBase的分布式服务;当该值为false时,HBase则不会启动自己的ZooKeeper服务,而是依赖于已有的ZooKeeper服务。
需要注意的是,在设置该环境变量时,需要确保你的HBase集群中已经有一个可用的ZooKeeper集群,并且HBase的配置文件中也已经正确指定了该ZooKeeper集群的地址。否则,将该变量设置为false可能会导致HBase服务无法正常工作。
当将HBASE_MANAGES_ZK属性设置为false后,HBase将不会启动自己的ZooKeeper服务,而是依赖于一个外部的ZooKeeper集群。在这种情况下,你需要在HBase的配置文件中指定外部ZooKeeper集群的地址。
具体来说,你需要在HBase的配置文件中设置以下属性:
<!-- 指定使用的ZooKeeper集群的地址 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>zk1:2181,zk2:2181,zk3:2181</value>
</property>
在上面的配置中,hbase.zookeeper.quorum属性用于指定外部ZooKeeper集群的地址。该属性的值为一个逗号分隔的ZooKeeper服务器列表,每个服务器都包含服务器的主机名和客户端连接端口号,格式为hostname:port。在上面的示例中,zk1:2181,zk2:2181,zk3:2181表示一个由3个ZooKeeper服务器组成的集群,分别运行在zk1、zk2和zk3这三台主机上,客户端连接端口号均为2181。
需要注意的是,当将HBASE_MANAGES_ZK属性设置为false时,确保你的HBase集群中已经有一个可用的ZooKeeper集群,并且在HBase的配置文件中正确指定了该集群的地址。如果指定的ZooKeeper集群无法访问,或者配置文件中的地址有误,可能会导致HBase无法正常工作。
在HBASE_MANAGES_ZK=true的情况下,HBase会自动管理ZooKeeper的启动和关闭,并默认将hbase.zookeeper.quorum设置为localhost。因此,在这种情况下,不需要显式地配置hbase.zookeeper.quorum参数。但是,如果您想将ZooKeeper配置为运行在不同的节点上,那么仍然需要显式地配置hbase.zookeeper.quorum参数。
这里的坑在于,如果hbase.zookeeper.quorum未指定,则HBase将使用本地默认的Zookeeper,它只在启动HBase集群的节点上启动,并监听127.0.0.1地址。此时,只有在单节点或伪分布式模式下才能正常工作,无法在分布式集群中正常工作。因此,在分布式集群中,建议指定hbase.zookeeper.quorum参数,以确保HBase可以连接到正确的Zookeeper集合。即便,我们将HBASE_MANAGES_ZK设置为true,启用HBase默认的zk集群,我们依然需要在分布式部署时,指定hbase.zookeeper.quorum参数,指明zk需要部署在哪几台节点上。
hbase.zookeeper.property.dataDir配置是用来指定HBase使用ZooKeeper时,ZooKeeper数据快照的存储位置的。
具体来说,HBase在使用ZooKeeper时,需要将ZooKeeper的快照和事务日志存储在本地文件系统上,以保证ZooKeeper的数据持久性和可靠性。这些数据存储的位置可以通过HBase的配置文件来指定,其中hbase.zookeeper.property.dataDir属性用于指定ZooKeeper快照的存储位置。
在上面的配置中,hbase.zookeeper.property.dataDir属性被设置为/export/server/apache-zookeeper-3.6.0-bin/data,表示ZooKeeper的快照将会被存储在/export/server/apache-zookeeper-3.6.0-bin/data目录下。如果该目录不存在,HBase会尝试自动创建该目录。需要注意的是,这个目录必须有足够的空间来存储ZooKeeper的快照和事务日志。
- 配置环境变量
# 配置Hbase环境变量
vim /etc/profile
export HBASE_HOME=/export/server/hbase-2.1.0
export PATH=$PATH:${HBASE_HOME}/bin:${HBASE_HOME}/sbin
#加载环境变量
source /etc/profile
- 复制jar包到lib
cp $HBASE_HOME/lib/client-facing-thirdparty/htrace-core-3.1.0-incubating.jar $HBASE_HOME/lib/
- 修改regionservers文件
vim regionservers
node1
node2
node3
- 分发安装包与配置文件
cd /export/server
scp -r hbase-2.1.0/ node2:$PWD
scp -r hbase-2.1.0/ node3:$PWD
scp -r /etc/profile node2:/etc
scp -r /etc/profile node3:/etc
#在node2和node3加载环境变量
source /etc/profile
- 启动HBase
cd /export/onekey
# 启动ZK -- 如果使用habse内嵌的zk,则这里我们无需手动另开一个zk集群
./start-zk.sh
# 启动hadoop --- 参考上面给出的hadoop搭建教程
start-dfs.sh
# 启动hbase
start-hbase.sh

使用Jps命令,查看hadoop,zk,hbase相关进程是否都已经启动了:

- 验证HBase是否启动
# 启动hbase shell客户端
hbase shell

安装报错,解决思路是什么
我的HBase集群部署在三台云服务器上,并且处于不同的局域网中,两台阿里云,一台华为云,由于HBase默认集群处于同一个内网中,所以对于我的部署环境而言,如果直接启动HBase集群,会出现很多问题。
下面我将列举我安装过程中出现的通信问题,以及如何解决这些问题,解决思路是什么。
zk集群通信异常 ?
通过查看zk日志,会发现集群间通信存在异常:
2023-05-10 00:25:30,128 ERROR [main] regionserver.HRegionServer: Failed construction RegionServer
org.apache.hadoop.hbase.ZooKeeperConnectionException: master:160000x0, quorum=node1:2181,node2:2181,node3:2181, baseZNode=/hbase Unexpected KeeperException creating base node
- ZooKeeper客户端连接ZooKeeper服务器的端口,默认为2181(TCP)
- ZooKeeper服务器之间的通信端口,默认为2888(TCP),用于服务器之间的互相通信
- 用于Leader选举的端口,默认为3888(TCP)
这三个端口是ZooKeeper集群通信的必要端口,确保这些端口在防火墙中正确地打开,以确保ZooKeeper集群能够正常通信。
防火墙明明放开了呀!为啥还是不行呀!
- 查看zk进程是否在所有地址上监听相关端口,如果通信有问题,这里大概率是因为zk进程只在127.0.0.1本地地址上监听相关端口
netstat -nltp | grep 3888
netstat -nltp | grep 2888
netstat -nltp | grep 2181

- 如果zk监听的是127.0.0.1怎么解决 ?考虑到我们的部署环境,我们肯定希望能够外网访问,需要改成0.0.0.0
hbase自动启动的zk,3888端口默认监听的是127.0.0.1,如何通过设置让其监听0.0.0.0?
quorumListenOnAllIPs是一个 ZooKeeper 配置参数,用于指定是否在所有 IP 地址上监听 quorum 端口。- 当这个参数设置为 true 时,ZooKeeper 会在所有 IP 地址上监听 quorum 端口,包括本机的所有 IP 地址以及其他机器的 IP 地址。
- 当这个参数设置为 false 时,ZooKeeper 只会在默认地址上监听 quorum 端口,这个默认地址可以通过
zookeeper.serverCnxnFactory.address参数进行配置。 - 在 HBase 中,通过设置
hbase.zookeeper.property.quorumListenOnAllIPs=true可以让自动启动的 ZooKeeper 监听 quorum 端口时在所有 IP 地址上监听。同时,也可以通过在 hbase-site.xml 中添加以下配置来指定 quorumListenOnAllIPs 参数的值:
<property>
<name>hbase.zookeeper.property.quorumListenOnAllIPs</name>
<value>true</value>
</property>
HBase RegionServer 节点连接 HMaster 节点出现无效参数异常?
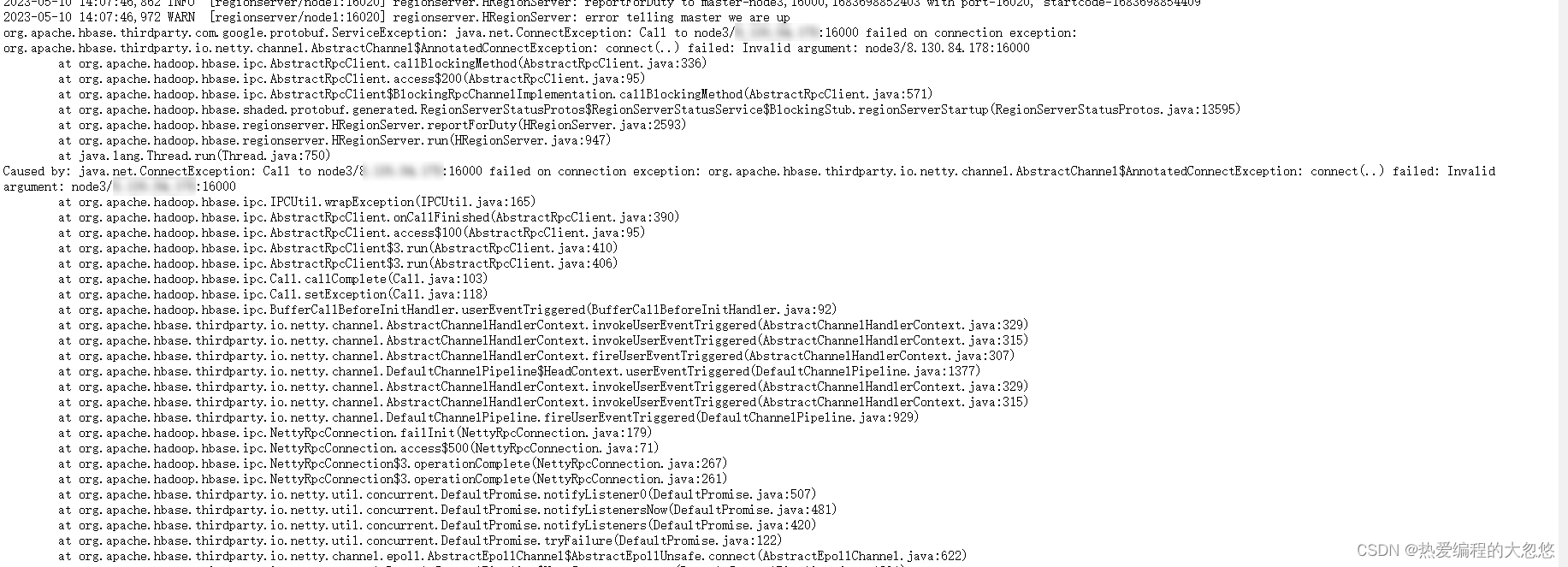
Caused by: java.net.ConnectException: Call to node3/xxx:16000 failed on connection exception: org.apache.hbase.thirdparty.io.netty.channel.AbstractChannel$AnnotatedConnectException: connect(..) failed: Invalid argument: node3/xxx:16000
出现这个异常时,我首先排查是否因为node3节点只监听127.0.0.1地址上的16000端口所致:
[root@node3 logs]# netstat -nltpa | grep 16000
tcp6 0 0 127.0.0.1:16000 :::* LISTEN 244188/java
tcp6 0 0 127.0.0.1:16000 127.0.0.1:44959 ESTABLISHED 244188/java
从上面给出的结果可以看到,HBase进程正在监听本地127.0.0.1地址的16000端口,表示该端口只能在本地进行访问,而不对外开放。
默认情况下,HBase的HMaster进程会监听本地主机的16000端口,如果要让HBase监听所有地址上的16000端口,可以通过修改HMaster的配置文件实现。具体操作如下:
- 打开hbase-site.xml文件,在其中添加如下配置:
<property>
<name>hbase.master.ipc.address</name>
<value>0.0.0.0</value>
</property>
重启HBase集群,再次尝试,发现错误依然存在,这是为什么呢?
[root@node3 logs]# netstat -nltpa | grep 16000
tcp6 0 0 :::16000 :::* LISTEN 282806/java
tcp6 0 0 127.0.0.1:16000 127.0.0.1:56183 ESTABLISHED 282806/java
tcp6 0 0 127.0.0.1:56183 127.0.0.1:16000 ESTABLISHED 282909/java
通过再次查看16000端口的监听情况可知,此时HBase会监听16000端口上所有地址,所以这里应该没有问题了。
root@node2:/export/server/hbase-2.1.0/logs# telnet node3 16000
Trying 8.130.84.178...
Connected to node3.
Escape character is '^]'.
在node2节点上通过telnet 访问node3的16000端口,发现可以正常访问,说明也不是网络或者防火墙问题。
其实对于上面这个错误,我们应该把目光集中到日志中下面这部分来:
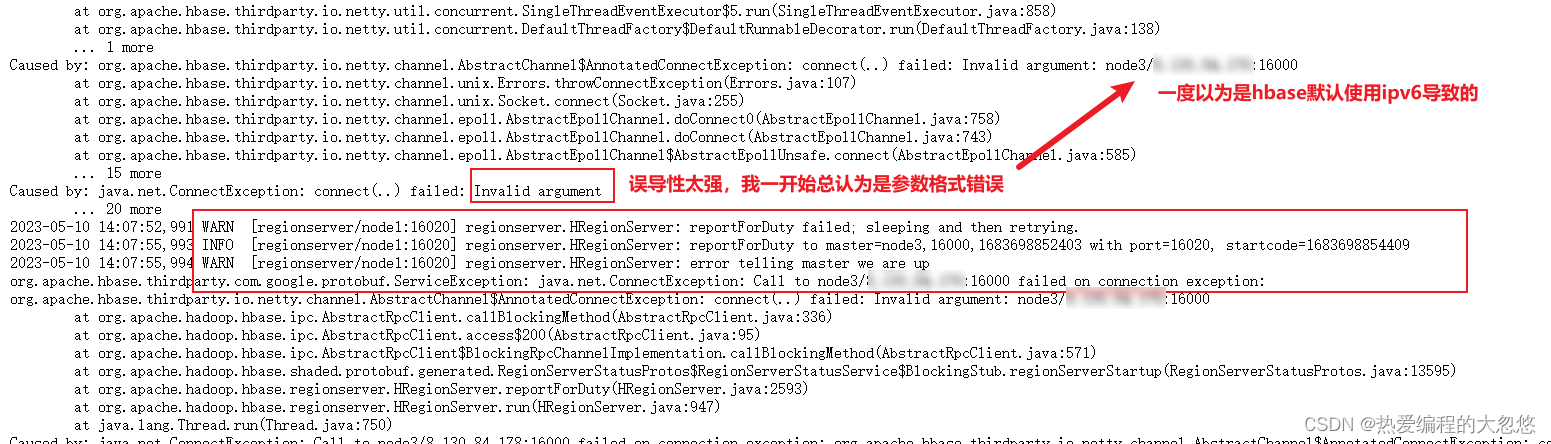
其实问题出在红色框框圈出来的两条WRAN日志中,首先我们需要知道:
- HRegionServer是HBase中用于存储和管理HBase表数据的服务。
- 16020端口是HRegionServer服务的RPC端口,用于与客户端和HMaster之间进行通信。
- 客户端可以通过此端口向HRegionServer发送数据读写请求,HMaster也可以通过此端口向HRegionServer发送命令和指令。
- HRegionServer服务在启动时会监听16020端口,以便能够与其他节点进行通信。
因此,我们需要先确定16020端口是否只在本地地址进行监听:
root@node1:/export/server/hbase-2.1.0/logs# netstat -nltpa | grep 16020
tcp6 0 0 127.0.0.1:16020 :::* LISTEN 8419/java
- 端口 16020 只监听在 127.0.0.1 上,即只接受本地的连接请求。
- 这很可能是导致 HRegionServer 无法连接到 HMaster 的原因之一。
- 要设置RegionServer监听所有地址0.0.0.0,需要在HBase的配置文件hbase-site.xml中添加以下配置:
<configuration>
<property>
<name>hbase.regionserver.ipc.address</name>
<value>0.0.0.0</value>
</property>
</configuration>
这样就可以让RegionServer监听所有可用的网络接口,而不仅仅是localhost。保存修改后,需要重启HBase RegionServer才能使配置生效。
但是,很不幸,启动后会发现错误依旧存在,难道问题不是出在这里吗?
- 查看HBase集群运行情况会发现
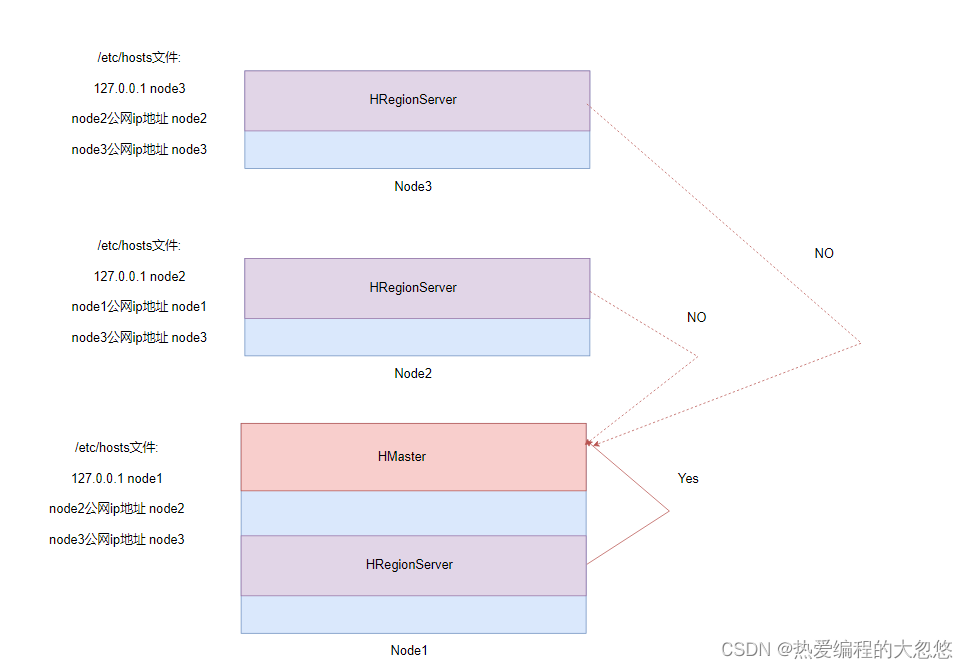
只有node1节点上的HRegionServer可以与HMaster正常通信,Node2和Node3上的HRegionServer无法与HMaster正常通信。
再次回顾上面的日志,会发现抛出的是无效参数异常:
这里的无效参数到底指啥?
- 是node3的地址为无效参数吗?
- 还是node1或者node2的本地配置有问题呢?
node1和node2节点处于不同的局域网下,node1节点上部署的HRegionServer可以与HMaster正常通信,并且/etc/hosts文件中配置127.0.0.1映射到node1,但是node2上部署的HRegionServer无法与HMaster正常通信。
这里直接给出答案:
- 这是因为node2节点上将/etc/hosts文件中配置127.0.0.1映射到node2,改成内网地址映射到node2就可以了
- node3上也进行修订即可
这里不能改成公网地址,否则Hadoop和HBase运行都会报错,这里只能填写内网地址。
Hadoop部署的时候没有这个要求,127.0.0.1映射不会报错,HBase存在这个要求,不能采用127.0.0.1,而需要采用内网地址。
- 我猜测是因为HBase再建立连接前,会检查通过主机名获取的地址是否为127.0.0.1本地回环地址,如果是,则抛出无效参数异常,具体为什么,这里我还没有搞清楚,如果有清楚的小伙伴,可以评论区指出原因。
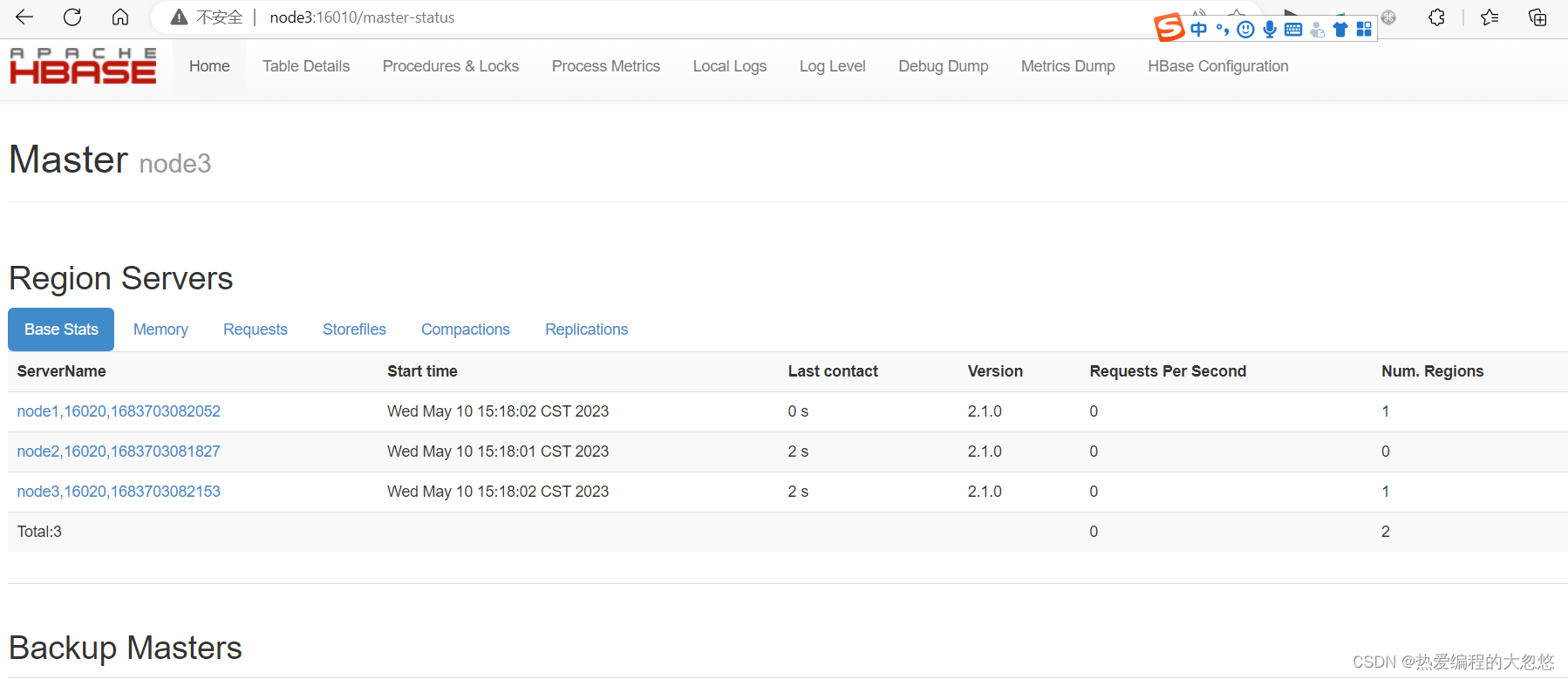
WebUI访问测试
- http://node3:16010/master-status
hbase安装目录
hbase参考硬件配置
针对大概800TB存储空间的集群中每个Java进程的典型内存配置:
| 进程 | 堆 | 描述 |
|---|---|---|
| NameNode | 8 GB | 每100TB数据或每100W个文件大约占用NameNode堆1GB的内存 |
| SecondaryNameNode | 8GB | 在内存中重做主NameNode的EditLog,因此配置需要与NameNode一样 |
| DataNode | 1GB | 适度即可 |
| ResourceManager | 4GB | 适度即可(注意此处是MapReduce的推荐配置) |
| NodeManager | 2GB | 适当即可(注意此处是MapReduce的推荐配置) |
| HBase HMaster | 4GB | 轻量级负载,适当即可 |
| HBase RegionServer | 12GB | 大部分可用内存、同时为操作系统缓存、任务进程留下足够的空间 |
| ZooKeeper | 1GB | 适度 |
推荐:
- Master机器要运行NameNode、ResourceManager、以及HBase HMaster,推荐24GB左右
- Slave机器需要运行DataNode、NodeManager和HBase RegionServer,推荐24GB(及以上)
- 根据CPU的核数来选择在某个节点上运行的进程数,例如:两个4核CPU=8核,每个Java进程都可以独立占有一个核(推荐:8核CPU)
- 内存不是越多越好,在使用过程中会产生较多碎片,Java堆内存越大, 会导致整理内存需要耗费的时间越大。例如:给RegionServer的堆内存设置为64GB就不是很好的选择,一旦FullGC就会造成较长时间的等待,而等待较长,Master可能就认为该节点已经挂了,然后移除掉该节点