flink cdc原理与使用
- 1 cdc 介绍
- 1.1 cdc简介与对比
- 1.2 基于日志的 CDC 方案介绍
- 2 基于 Flink SQL CDC 的数据同步方案实践
- 2.1 案例 1 : Flink SQL CDC + JDBC Connector
- 2.2 案例 2 : CDC Streaming ETL
- 2.3 案例 3 : Streaming Changes to Kafka
- 3 Flink SQL CDC 的更多应用场景
- 4 Flink SQL CDC : 打通更多场景
1 cdc 介绍
1.1 cdc简介与对比
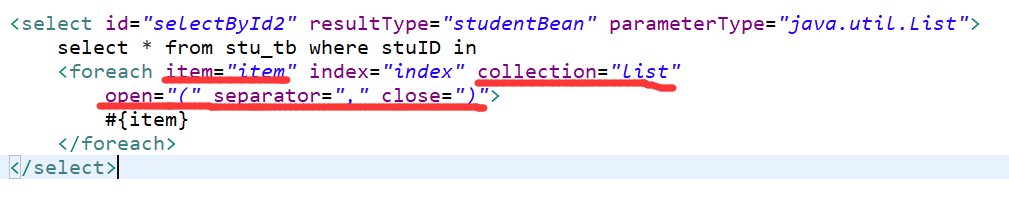
CDC 是(Change Data Capture 变更数据获取)的简称。
核心思想是,监测并捕获数据库的变动(包括数据 或 数据表的插入 INSERT、更新 UPDATE、删除 DELETE 等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅 及消费。
像是常用来同步mysql binlog的canal 就是一个cdc工具。
CDC 全称是 Change Data Capture ,它是一个比较广义的概念,只要能捕获变更的数据,我们都可以 称为 CDC 。业界主要有基于查询的 CDC 和基于日志的 CDC ,可以从下面表格对比他们功能和差 异点。
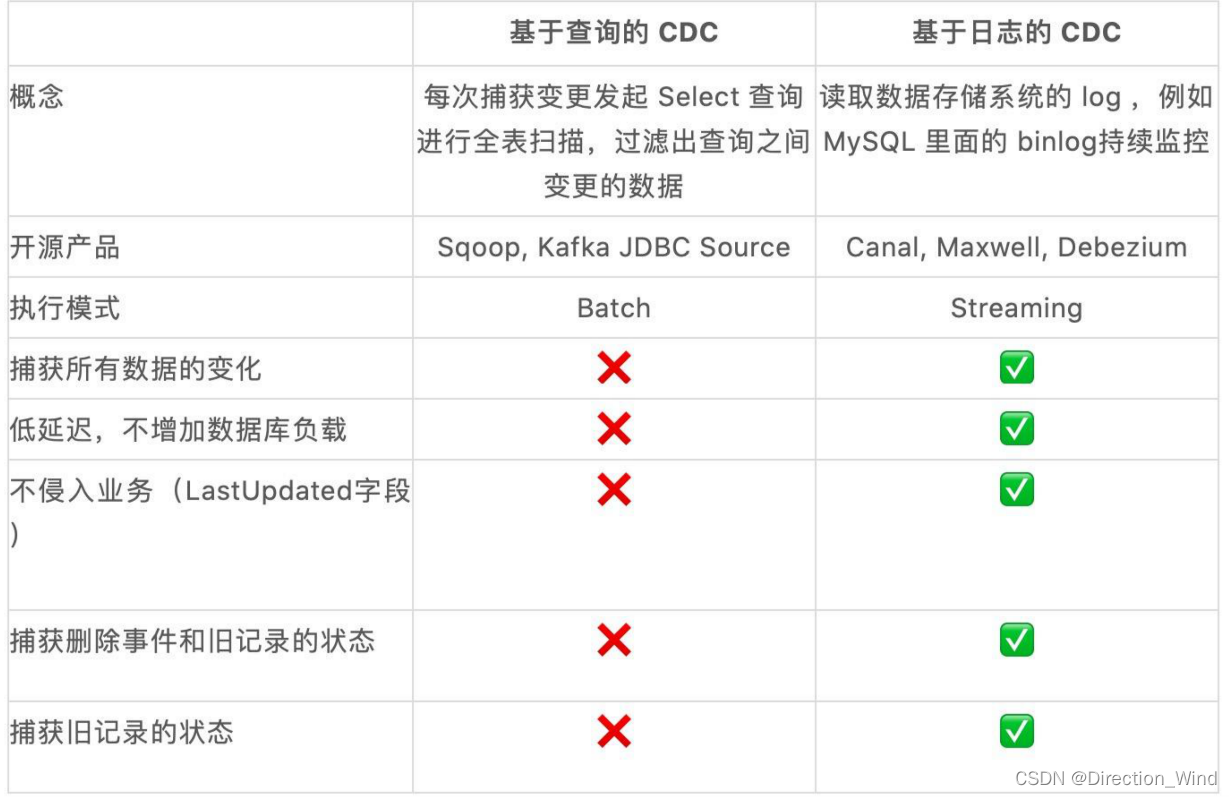
经过以上对比,我们可以发现基于日志 CDC 有以下这几种优势:
- · 能够捕获所有数据的变化,捕获完整的变更记录。在异地容灾,数据备份等场景中得到广泛应用, 如果是基于查询的 CDC 有可能导致两次查询的中间一部分数据丢失
- · 每次 DML 操作均有记录无需像查询 CDC 这样发起全表扫描进行过滤,拥有更高的效率和性能, 具有低延迟,不增加数据库负载的优势
- · 无需入侵业务,业务解耦,无需更改业务模型
- · 捕获删除事件和捕获旧记录的状态,在查询 CDC 中,周期的查询无法感知中间数据是否删除
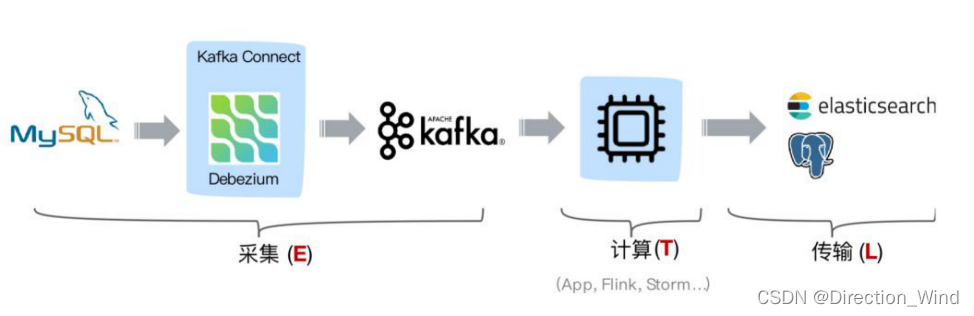
在实时性、吞吐量方面占优,如果数据源是 MySQL、PostgreSQL、MongoDB 等常见的数据库实现,
建议使用 Debezium 来实现变更数据的捕获(下图来自 Debezium 官方文档)。如果使用的只有 MySQL,则可以用 Canal。
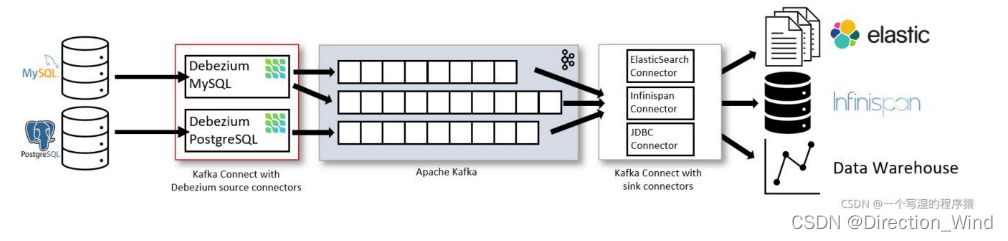
1.2 基于日志的 CDC 方案介绍
从 ETL 的角度进行分析,一般采集的都是业务库数据,这里使用 MySQL 作为需要采集的数据库, 通过 Debezium 把 MySQL Binlog 进行采集后发送至 Kafka 消息队列,然后对接一些实时计算引擎 或者 APP 进行消费后把数据传输入 OLAP 系统或者其他存储介质。
Flink 希望打通更多数据源,发挥完整的计算能力。我们生产中主要来源于业务日志和数据库日志, Flink 在业务日志的支持上已经非常完善,但是在数据库日志支持方面在 Flink 1.11 前还属于一片空 白,这就是为什么要集成 CDC 的原因之一。
Flink SQL 内部支持了完整的 changelog 机制,所以 Flink 对接 CDC 数据只需要把 CDC 数据转换 成 Flink 认识的数据,所以在 Flink 1.11 里面重构了 TableSource 接口,以便更好支持和集成 CDC。
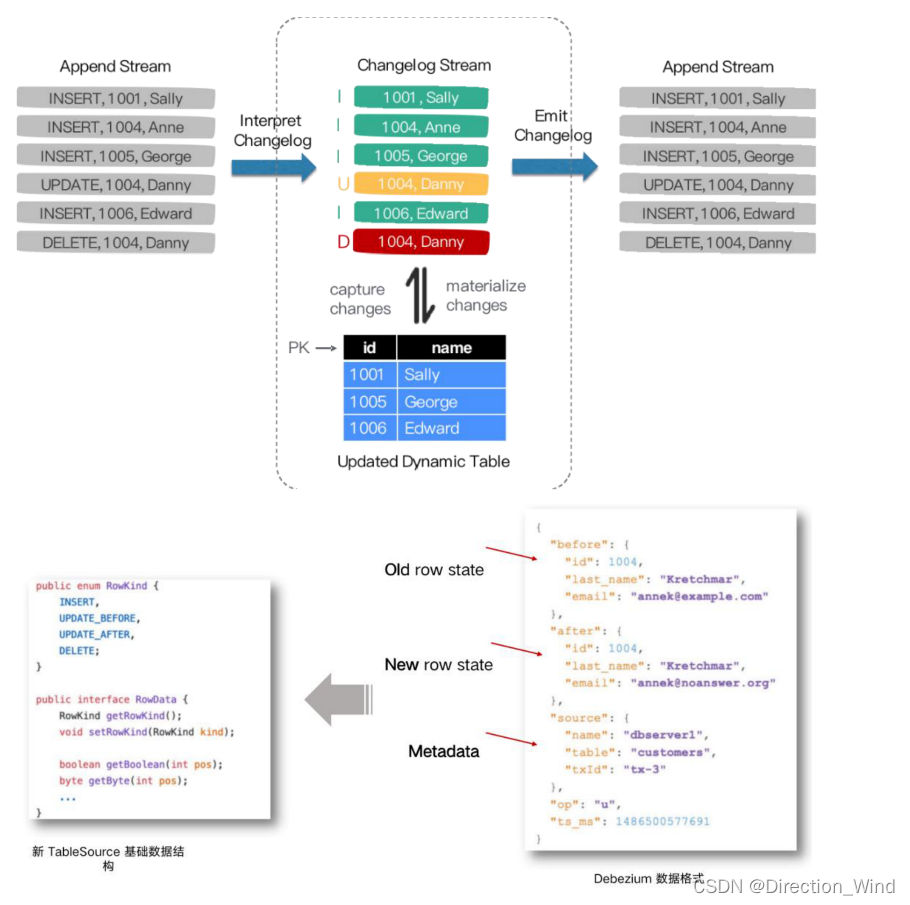
重构后的 TableSource 输出的都是 RowData 数据结构,代表了一行的数据。在 RowData 上面会有 一个元数据的信息,我们称为 RowKind 。RowKind 里面包括了插入、更新前、更新后、删除,这 样和数据库里面的 binlog 概念十分类似。通过 Debezium 采集的 JSON 格式,包含了旧数据和新数 据行以及原数据信息,op 的 u 表示是 update 更新操作标识符,ts_ms 表示同步的时间戳。因此, 对接 Debezium JSON 的数据,其实就是将这种原始的 JSON 数据转换成 Flink 认识的 RowData。 选择 Flink 作为 ETL 工具。
当选择 Flink 作为 ETL 工具时,在数据同步场景,如下图同步结构:
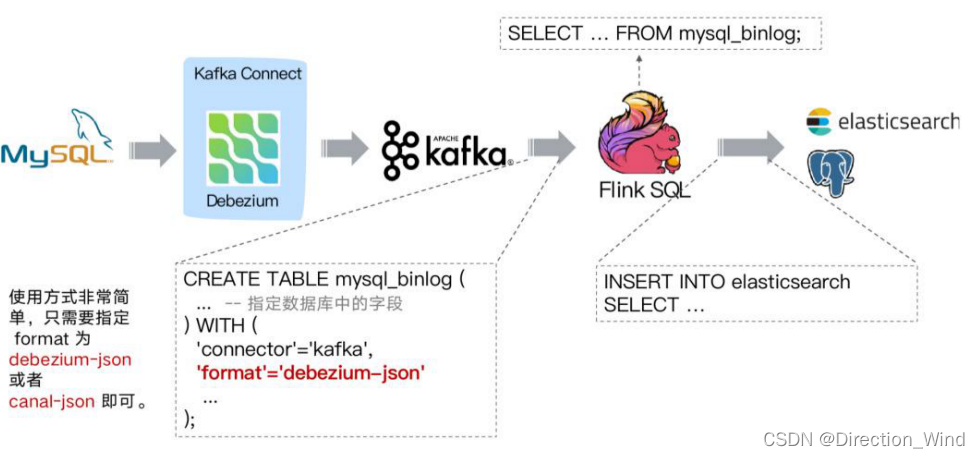
通过 Debezium 订阅业务库 MySQL 的 Binlog 传输至 Kafka ,Flink 通过创建 Kafka 表指定 format 格式为 debezium-json ,然后通过 Flink 进行计算后或者直接插入到其他外部数据存储系统, 例如图中的 Elasticsearch 和 PostgreSQL。
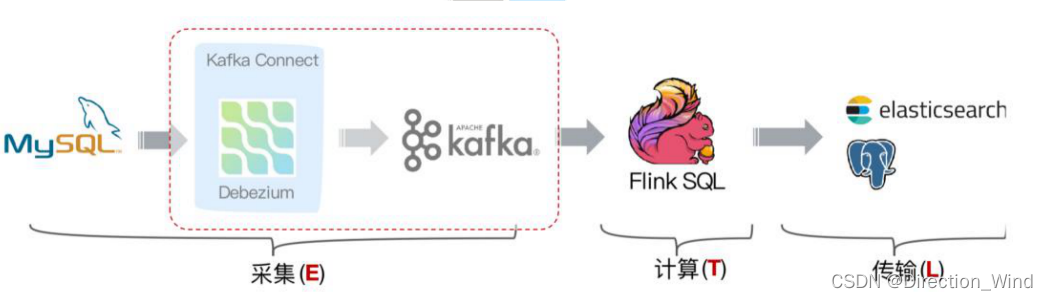
但是这个架构有个缺点,我们可以看到采集端组件过多导致维护繁杂,这时候就会想是否可以用 Flink SQL 直接对接 MySQL 的 binlog 数据呢,有没可以替代的方案呢? 答案是有的!经过改进后结构如下图:
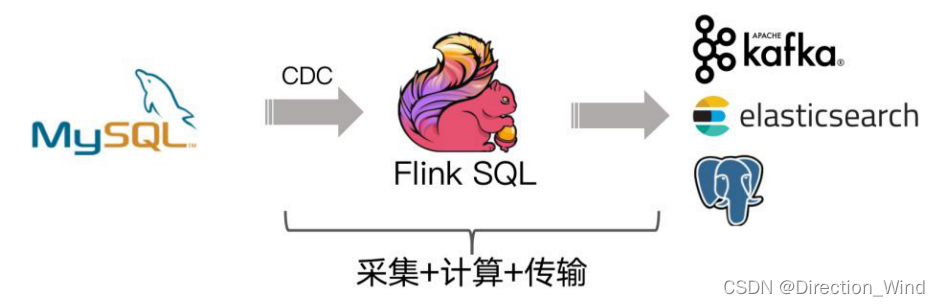
社区开发了 flink-cdc-connectors 组件,这是一个可以直接从 MySQL、PostgreSQL 等数据库直接读
取全量数据和增量变更数据的 source 组件。目前也已开源,开源地址: https://github.com/ververica/flink-cdc-connectors
flink-cdc-connectors 可以用来替换 Debezium+Kafka 的数据采集模块,从而实现 Flink SQL 采集+计 算+传输(ETL)一体化,这样做的优点有以下:
- 开箱即用,简单易上手
- 减少维护的组件,简化实时链路,减轻部署成本
- 减小端到端延迟
- Flink 自身支持 Exactly Once 的读取和计算
- 数据不落地,减少存储成本
- 支持全量和增量流式读取
- binlog 采集位点可回溯
2 基于 Flink SQL CDC 的数据同步方案实践
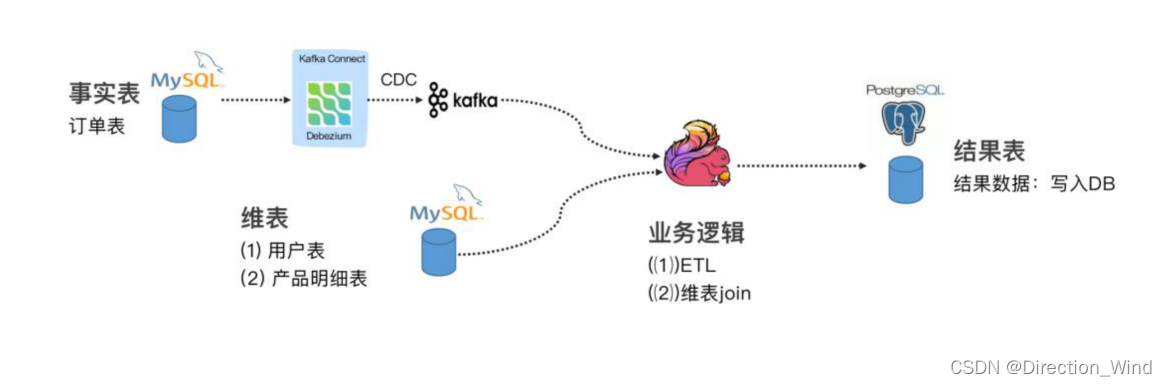
2.1 案例 1 : Flink SQL CDC + JDBC Connector
这个案例通过订阅我们订单表(事实表)数据,通过 Debezium 将 MySQL Binlog 发送至 Kafka, 通过维表 Join 和 ETL 操作把结果输出至下游的 PG 数据库。
2.2 案例 2 : CDC Streaming ETL
模拟电商公司的订单表和物流表,需要对订单数据进行统计分析,对于不同的信息需要进行关联后续 形成订单的大宽表后,交给下游的业务方使用 ES 做数据分析,这个案例演示了如何只依赖 Flink 不 依赖其他组件,借助 Flink 强大的计算能力实时把 Binlog 的数据流关联一次并同步至 ES 。

例如如下的这段 Flink SQL 代码就能完成实时同步 MySQL 中 orders 表的全量+增量数据的目的。
CREATE TABLE orders ( order_id INT, order_date TIMESTAMP(0), customer_name STRING, price DECIMAL(10, 5), product_id INT, order_status BOOLEAN ) WITH ( 'connector' = 'mysql-cdc', 'hostname' = 'localhost', 'port' = '3306', 'username' = 'root', 'p@assw@ord' = '1@23456', 'database-name' = 'mydb', 'table-name' = 'orders' );SELECT * FROM orders
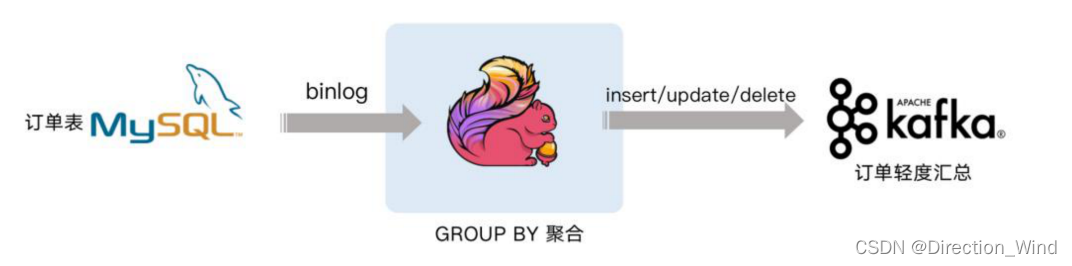
2.3 案例 3 : Streaming Changes to Kafka
下面案例就是对 GMV 进行天级别的全站统计。包含插入/更新/删除,只有付款的订单才能计算进入 GMV ,观察 GMV 值的变化。
3 Flink SQL CDC 的更多应用场景
Flink SQL CDC 不仅可以灵活地应用于实时数据同步场景中,还可以打通更多场景提供给用户选择。 Flink 在数据同步场景中的灵活定位
- 如果已有 Debezium/Canal + Kafka 的采集层 (E),可以使用 Flink 作为计算层 (T) 和传输层 (L)
- 也可用 Flink 替代 Debezium/Canal ,由 Flink 直接同步变更数据到 Kafka,Flink 统一 ETL 流程
- 如果不需要 Kafka 数据缓存,可以由 Flink 直接同步变更数据到目的地,Flink 统一 ETL 流程
4 Flink SQL CDC : 打通更多场景
- 实时数据同步,数据备份,数据迁移,数仓构建 优势:丰富的上下游(E & L),强大的计算(T),易用的 API(SQL),流式计算低延迟
- 数据库之上的实时物化视图、流式数据分析
- 索引构建和实时维护
- 业务 cache 刷新
- 审计跟踪
- 微服务的解耦,读写分离
- 基于 CDC 的维表关联
下面介绍一下为何用 CDC 的维表关联会比基于查询的维表查询快。
-
基于查询的维表关联
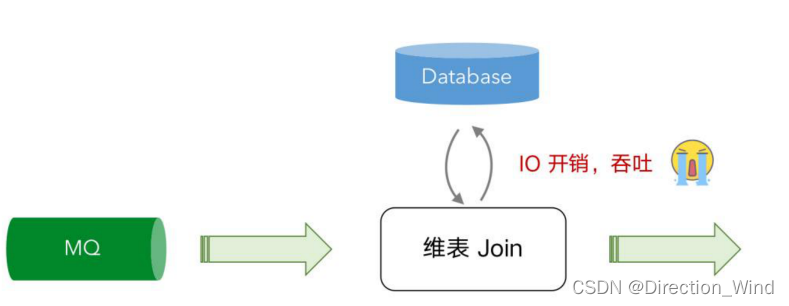
目前维表查询的方式主要是通过 Join 的方式,数据从消息队列进来后通过向数据库发起 IO 的请 求,由数据库把结果返回后合并再输出到下游,但是这个过程无可避免的产生了 IO 和网络通信的消 耗,导致吞吐量无法进一步提升,就算使用一些缓存机制,但是因为缓存更新不及时可能会导致精确 性也没那么高。 -
■ 基于 CDC 的维表关联
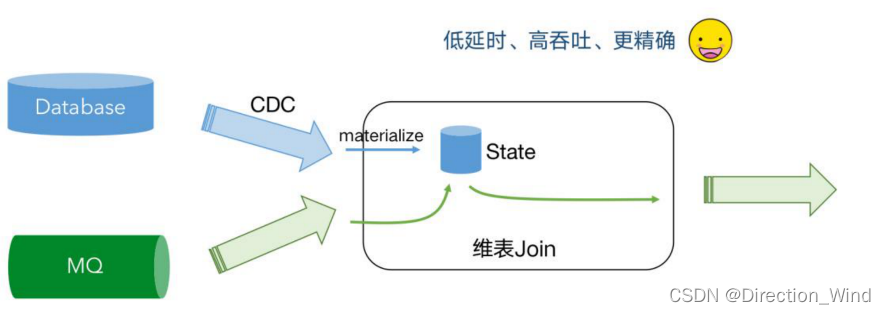
我们可以通过 CDC 把维表的数据导入到维表 Join 的状态里面,在这个 State 里面因为它是一个分 布式的 State ,里面保存了 Database 里面实时的数据库维表镜像,当消息队列数据过来时候无需再 次查询远程的数据库了,直接查询本地磁盘的 State ,避免了 IO 操作,实现了低延迟、高吞吐,更 精准。