(预测未来最好的方法就是把它创造出来——尼葛洛庞帝)

V8
官方链接
NodeJs8.3之前的代码优化建议
NodeJs8.3版本之后的turbofan虚拟机引擎
编写性能更高的JavaScript代码
chromium 优化博客
chrom v8版本发布路线图
V8 是 Google 的开源高性能 JavaScript 和 WebAssembly 引擎,用 C++ 编写。它用于 Chrome 和 Node.js 等。它实现了ECMAScript和WebAssembly,并运行在 Windows 7 或更高版本、macOS 10.12+ 和使用 x64、IA-32、ARM 或 MIPS 处理器的 Linux 系统上。V8 可以独立运行,也可以嵌入到任何 C++ 应用程序中。
接下来整理的主要是nodejs后端业务常涉及到的更新,其他更新不会记录或记录的不详细。更详细的,请直接查看官网。在此记录的只方便后期回顾。
9.3
2021 年 8 月 9 日发布
Sparkplug编译器
在了解Sparkplug之前,我们先简单了解v8编译器的历史,分为三个部分
CrankShaft
早期的v8在将代码解析成语法树后直接全部编译为机器码来执行。对于执行次数较多的代码会编译成经过优化的汇编代码。正常访问对象属性的过程是:首先获取隐藏类的地址,然后根据属性名查找偏移值,然后计算该属性的地址。但经过多次执行代码,会通过隐藏类和内联缓存等方式加载访问对象的速度从而提升性能。
TurboFan
但在2016年,有人发现重复关闭打开facebook时,v8打开速度反而越来越慢。这说明v8对浏览器缓存内容的处理依然存在问题。可是也不能将所有代码都进行缓存,这样占用的内存空间又太大了,所以之前的优化方式是只解析声明部分,执行部分在用到的时候再进行解析。有一些初始化类的递归函数会导致执行速度变慢。直接全部编译成机器码也会造成启动速度过慢。CrankShaft虽然能做缓存,但也是从源代码进行解析,就造成了重复解析的问题。CrankShaft无法对部分代码进行优化,比如trycatch,finally等。
基于这些主要的原因,V8团队做了以下优化
- 不再全部编译为机器码,而是由Ignition解释器将语法树转换成字节码。这样就大量节省了内存孔间
- 热点代码由TurboFan编辑器直接从字节码编译成经过优化后的汇编代码,并且能对trycatch,finally等代码进行优化
Sparkplug
相关视频
上一个版本依然存在一些问题,比如非热点函数,每次都要从源代码转换成字节码再转换成汇编代码。那么Sparkplug为了解决这个问题,将所有代码都直接转成非热点的汇编代码,如果多次执行,则再从字节码转换为经过优化后的汇编代码以提高性能。
9.0
2021 年 3 月 17 日发布
更快的super访问
更详细的解释
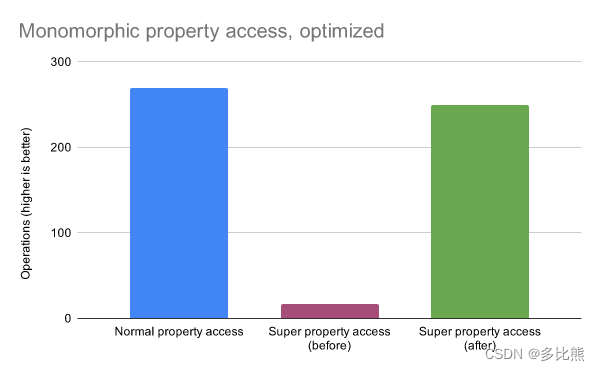
访问super属性(例如,super.x)已通过使用 V8 的内联缓存系统和 TurboFan 中的优化代码生成进行了优化。通过这些更改,super属性访问现在更接近于常规属性访问,如下图所示。
比如有以下代码
class A { }
A.prototype.x = 100;
class B extends A {
m() {
return super.x;
}
}
const b = new B();
b.m();
然后我们分析b的原型链。而实际上b.m()的查找过程也是此原型链进行查找。这也是此次性能优化的主要依据。
b ->
b.__proto__ === B.prototype ->
B.prototype.__proto__ === A.prototype ->
A.prototype.__proto__ === Object.prototype ->
Object.prototype.__proto__ === null
在此之前每次使用super进行属性或者方法的查找都是基于原型链,那么现在,对于热点(经常被调用)的属性或者方法v8会生成缓存,不再依赖原型链,而是直接通过缓存进行查找,性能更佳。
8.9
2021 年 2 月 4 日发布
参数大小不匹配的更快调用
JavaScript 允许使用与预期参数数量不同的参数调用函数,即可以传递比声明的形式参数更少或更多的参数。前者称为应用不足,后者称为应用过度。
在应用程序不足的情况下,其余参数将分配给该undefined值。在过度应用的情况下,剩余的参数可以通过使用 rest 参数和属性来访问Function.prototype.arguments,或者它们只是多余的并被忽略。现在许多 Web 和 Node.js 框架都使用此 JS 功能来接受可选参数并创建更灵活的 API。
直到最近,V8 才有一个特殊的机制来处理参数大小不匹配:参数适配器框架。不幸的是,参数适配是以性能为代价的,并且在现代前端和中间件框架中通常需要。事实证明,通过巧妙的设计(比如颠倒堆栈中参数的顺序),我们可以删除这个额外的框架,简化 V8 代码库,并几乎完全消除开销。
console.time();
function f(x, y, z) {}
for (let i = 0; i < N; i++) {
f(1, 2, 3, 4, 5);
}
console.timeEnd();
8.6
2020 年 9 月 21 日发布
Number.prototype.toString提升性能
在一般情况下,将 JavaScript 数字转换为字符串可能会非常复杂,必须考虑浮点精度、科学计数法、NaN、无穷大、舍入等。在计算之前,甚至不知道结果字符串的大小。因此,V8 对 Number.prototype.toString 的实现将提供给 C++ 运行时函数。
但很多时候,你可能只想打印一个简单的小整数(“Smi”)。这是一个简单得多的操作,不再需要调用 C++ 运行时函数的开销。因此,V8 团队为使用 Torque 编写的 Number.prototype.toString 添加了一个小整数的简单快速路径,以减少这种常见情况的开销。
8.3
2020 年 5 月 4 日发布
ArrayBuffer垃圾收集器中的更快的回收
ArrayBufferV8 v8.3 有一个新的跟踪ArrayBuffers 及其后备存储的机制,允许垃圾收集器迭代并释放后备存储并发给应用程序
8.0
2019 年 12 月 18 日发布
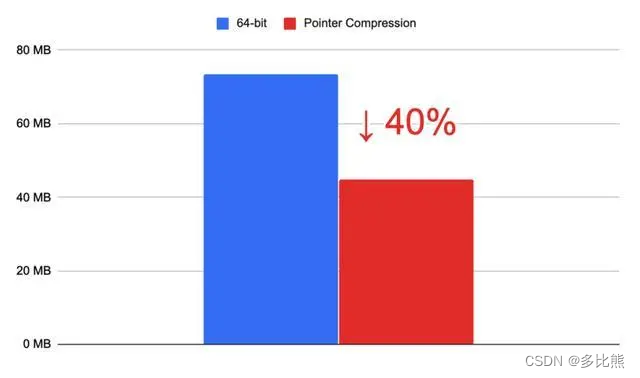
指针压缩
指针压缩用于在V8和Oilpan(DOM 对象的垃圾收集器)中节省内存。我们对压缩和解压缩指针的方式进行了优化,并避免压缩高流量字段。考虑到这些操作的执行频率,它会对性能产生广泛的影响。我们还将经常访问的对象(如 JavaScript 的“undefined”)移动到内存基址的开头,从而允许使用更快的机器代码访问它们。
改进的功能和高效的指针压缩共同使我们在三个月内将Apple 的Speedometer 2.1 浏览器基准测试提高了 10% 。
优化高阶内置函数
删除了 TurboFan 优化管道中的一个限制,该限制阻止了对高阶内置函数的积极优化。
const charCodeAt = Function.prototype.call.bind(String.prototype.charCodeAt);
charCodeAt(string, 8);
到目前为止,对 TurboFan 的调用charCodeAt是完全不透明的,这导致生成对用户定义函数的通用调用。有了这个变化,我们现在能够认识到我们实际上是在调用内置String.prototype.charCodeAt函数,因此能够触发 TurboFan 现有的所有进一步优化以改进对内置函数的调用,从而获得与以下相同的性能
string.charCodeAt(8);
此更改会影响许多其他内置函数,例如Function.prototype.apply、Reflect.apply和许多高阶数组内置函数(例如Array.prototype.map)