笔记整理:杜苗增,东南大学硕士,研究方向为多模态信息抽取
链接:https://aclanthology.org/2022.emnlp-main.401.pdf
动机
开放信息提取(OIE)是信息提取(IE)的一个分支,专注于从非结构化自然语言文本中提取结构化信息。几种OIE方法将OIE作为序列标记或序列生成问题。对于OIE的任务,使用词性和依赖标记作为合并语法信息的方式是一种常见的做法。在使用这些标记的工作中,标记的嵌入只连接到相应文本标记的嵌入,这种表述没有充分利用语法信息。序列生成方法容易生成经常表达冗余信息的事实,也容易在事实中生成重复的文本。
本文使用序列生成方法从自然语言文本中逐字生成事实。在依赖树结构的指导下计算输入文本标记的语法丰富的向量表示。根据其依赖树的结构构造其标记的可见性矩阵。还介绍了一种训练神经OIE模型的新方法,添加了一个额外的模块(discriminator)将生成的元组作为输入,将其令牌分类为“真”或“假”。使用覆盖向量来监视输入文本中的单词所接收到的覆盖程度。让当前的注意力机制的决策了解了之前的决策,并更容易避免重复关注输入文本中的相同单词,从而避免在事实中产生重复的文本。此外, 使用模型的上下文向量显式地计算从词汇表或输入文本中选择单词的概率。
贡献
本文的主要贡献有:
(1)一种利用依赖树和图注意力网络结构计算语法丰富的文本嵌入新方法。
(2)一种新的OIE判别训练方法,在生成事实的模型之上提出了一个鉴别器,生成的事实中的令牌被分类为“真实”或“伪造”。
(3)提出了CaRB、OIE201和LSOIE数据集的转述版本。
方法
总体框架如图1所示,主要由生成器模块(generator)和判别器模块(discriminator)组成。generator使用指针-生成网络来从文本中生成事实元组,discriminator使用二分类器来对生成的元组中的词进行真假判断。generator包括嵌入模块、编码模块和解码模块。Embedding使用预训练的语言模型或其他神经网络来将词序列映射为词嵌入向量,并结合词性和依存关系标签。Encoding使用图注意力网络或Transformer编码器来计算输入序列的向量表示,考虑到依存树的结构。Decoding使用BiLSTM网络、Transformer或反馈Transformer来逐词生成元组,并使用生成概率和覆盖机制来控制生成或复制词的概率,以及避免重复词的出现。
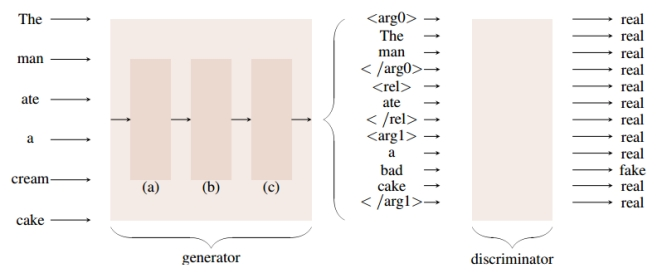
图1 总体框架图
为了计算整个词汇表 的分布,计算encoder上下文向量 和解码器上下文向量 的加权平均值,然后将得到的向量输入一个线性层:
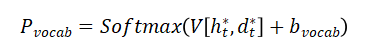
其中 和 是可学习参数, 是词汇表中所有单词的概率分布。 给出了从词汇表中预测下一个单词w的最终概率: 。
模型loss为generator loss和discriminator loss之和。使用生成下一个单词 的概率和覆盖机制来计算生成器的损失:
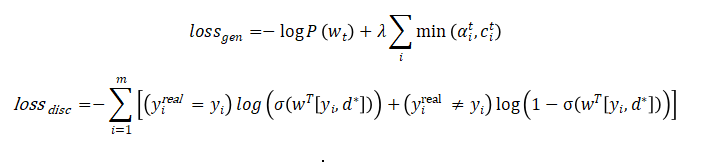
其中 为覆盖向量, 为注意力得分, 是生成元组中第i个令牌的向量表示, 是输入上下文向量。
实验
实验部分使用了三个基准数据集(OIE2016,CaRB和LSOIE)来训练和评估的模型,并使用了CaRB评估框架来计算F1值和AUC-PR值。
共设计了15种不同的神经网络模块组合,并在6种不同的实验设置下进行了对比实验,分别是:
(a)默认设置,只有嵌入模块和解码模块;
(b)+判别器设置,给默认设置添加了一个判别器模块;
(c)+Transformer编码器设置,给默认设置添加了Transformer编码器模块;
(d)+GNN编码器设置,给默认设置添加了一个基于图注意力网络的编码器模块;
(e)+Transformer编码器+判别器设置,给默认设置添加了一个Transformer编码器模块和一个判别器模块;
(f)+GNN编码器+判别器设置,给默认设置添加了一个基于图注意力网络的编码器模块和一个判别器模块。
表1显示在实验设置下评估CaRB上的模型。在所有的实验设置下,使用预训练的ELECTRA模型作为嵌入模块和反馈Transformer作为解码模块的组合都取得了最好的性能。在CaRB数据集上,这种组合在+GNN编码器+判别器设置下达到了0。747的F1值和0。740的AUC-PR值,超过了之前的最佳结果。表2给出当在混合数据集上训练时的结果。

表1: CaRB数据集上不同模块组合结果,粗体结果表示每种设置下的最佳性能
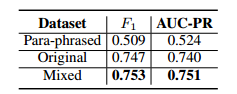
表2:最佳模型(ELECTRA + GNN编码器+鉴别器)在转述、原始和混合版本CaRB上训练时的性能
进行分析和消融实验发现使用依存树结构来计算输入序列的向量表示和使用判别式训练方法都能显著提高模型的性能,此外还发现使用生成概率和覆盖机制能有效地减少生成元组中的重复词,并提高生成隐含事实的能力。
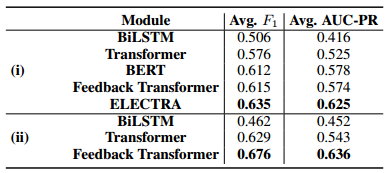
表3: 在CaRB的所有实验中,不同模块在不同区块的平均性能。(i)嵌入器(ii)解码器
从实验结果来看,作者的方法在各项指标上都优于现有的神经网络OIE模型,与传统的序列标注或序列生成方法相比,充分利用了依存树的语法和语义信息,有效地区分了生成事实中的真或假词,减少了重复词的生成,并提高了生成隐含事实的能力。同时,作者还展示了使用改写数据集进行数据增强可以显著提升模型的性能,尤其是在最新的CaRB数据集上达到了最先进的水平。
总结
本文研究了神经网络开放信息抽取问题,提出了一种新的训练方法,结合依存树结构计算语法丰富的文本嵌入,设计了一个判别器对生成事实中的词进行真或假的分类,并使用覆盖机制和生成概率控制重复词的生成和隐含事实的生成。实验结果表明,本文提出的方法在各项指标上都优于现有的神经网络OIE模型,能够生成更准确和更完整的事实,尤其是在最新的CaRB数据集上达到了最先进的水平。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。