什么是OpenCL
OpenCL是面向由CPU、GPU和其他处理器组合构成的计算机进行编程的行业标准框架。这些所谓的 “异构系统” 已经成为一类重要的平台,OpenCL是直接满足这些异构系统需求的第一个行业标准。OpenCL于2008年12月首次发布,早期产品则在2009年秋天才推出,因此OpenCL是一项相当新的技术。
利用OpenCL,可以编写一款能够在各类系统上成功运行的程序,这些系统包括移动电话、笔记本电脑,甚至是大规模超计算机中的节点。
OpenCL通过公布硬件来提供高度的可移植性,而不是将硬件隐藏在精巧的抽象之下。这说明OpenCL程序员必须显式地定义平台、上下文,以及在不同设备上调度工作。并不是所有程序员都需要(或者希望得到)OpenCL提供的详细控制。没关系,如果可以做其他选择,高层编程模型往往是更好的方法。不过,即使是高层编程模型,也需要一个牢固(而且可移植)的基础,OpenCL就可以作为这个基础。
多核的未来:异构平台
在过去十年间,计算机界发生了显著的变化。早年间总是由原始性能驱动革新。不过,从最近几年开始,关注点已经转向每瓦特功耗提供的性能。半导体公司还将继续把越来越多的晶体管压缩在一个芯片上,不过这些生产商竞争的方向不再是原始性能,而是功耗效能。
这种转变很大程度上改变了这个行业生产的计算机。首先,由多个低功耗核构建计算机中的微处理器。多核的概念首先由 A.P.Chandrakasan 等人在他们的文章“Optimizing Power UsingTransformations”中提出。他们的观点如图1-1所示。
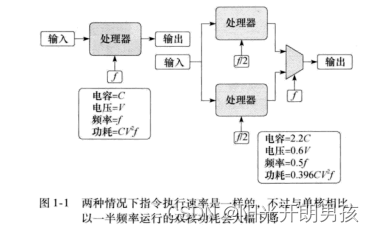
CPU中门切换消耗的能量为电容(C)乘以电压(V)的平方。这些门在1秒内切换的次数等于频率。因此一个微处理的功耗计算为P=CV2f。如果将一个频率为f、电压为V的单核处理器与一个类似的双核处理器(每个核芯的频率为f/2)进行比较,芯片中的回路数会提高。按照文章“Optimizing Power Using Transformations"中描述的模型,理论上这会将电容提高2.2倍。不过电压会显著减少到0.6V。所以在这两种情况下,每秒执行的指令数是一样的,但是双核处理器中的功耗是单核处理器的0.396倍。就是这个基本关系促使了微处理器向多核芯片过渡。低频率运行的多核在功耗效能上会有显著提高。
下一个问题是“这些核是一样的(同构)还是不一样的?” 要理解这个趋势,需要考虑专用与通用逻辑的功耗效能。通用处理器本质上必须包括大量功能单元来响应计算需求。芯片也因此成为一个通用处理器。不过,专用于某个特定功能的处理器就不会浪费那么多晶体管,因为它们只包含特定功能所需要的功能单元。结果如图1-2所示
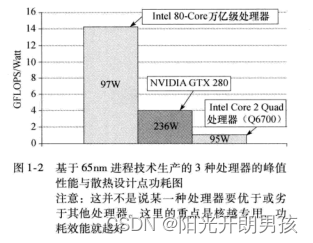
这里对一个通用CPU (IntelCore 2 Quad 处理器(Q6700))、一个GPU (NVIDIA GTX 280) 和一个相当专用的研究处理器 (Intel 80-Core万亿级处理器,其内核是一对浮点加乘算术单元) 进行比较。为了让比较过程尽可能公平,各芯片都采用65nm进程技术制造,另外,我们使用了生产商发布的峰值性能与散热设计点功耗。从图1-2中可以清楚地看出,只要任务与处理器很好地匹配,芯片越专用,功耗效能就越好。
因此,有理由相信,在一个充分强调最大化每瓦特性能的世界里,完全可以相信系统会越来越依赖于多核,并且在可行的条件下会越来越多地利用专用芯片。这对于移动设备尤其重要,因为移动设备中电量的节省至关重要。不过,异构的趋势已经摆在我们面前。可以考虑一个现代PC的原理图(见图1-3)。
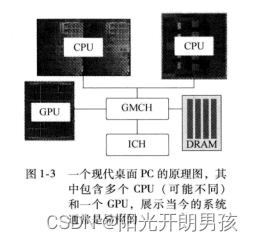
这里有两个插座(socket),各个插座可以安装不同的多核CPU,连接到系统内存(DRAM) 的图形/内存控制器(GMCH),以及图形处理单元 (GraphicsProcessing Unit, CPU)。这是一个异构平台,提供多个指令集和多级并行性,必须充分利用才能最大限度地发挥系统的能力。
不论是现在还是将来,从高层次来讲,基本平台是明确的。尽管繁杂的细节和众多的新观念肯定会让我们吃惊,但硬件趋势很明朗。未来肯定是异构多核平台的天下。我们面对的问题是,软件如何适应这些平台。
多核世界中的软件
并行硬件通过同时运行多个操作来提高性能。为了更有用,并行硬件要求软件执行时能够作为多个操作流同时运行,换句话说,我们需要并行软件。
为了理解并行软件,必须先搞清楚一个更一般的概念:并发性 (concurrency)。并发性是计算机科学中我们都很熟悉的一个古老概念。软件系统包含多个活动的操作流时,如果这些操作流同时向前推进,则称这个软件系统是并发的。并发性在所有现代操作系统中都很重要。一些操作流 (线程) 等待某些资源时,允许另外一些操作流继续推进,这样能够最大化资源的利用率。通过并发,与系统交互的用户还会有一种错觉,认为与系统的交互是连续的,而且几乎是即时的。
当并发软件在拥有多个处理单元的计算机上运行时,线程实际上可以同时运行,从而可以实现并行计算。硬件支持的并发性就是并行性。
对于程序员来说,要找出问题中的并发性,并在软件中表述这种并发性,然后运行得到的程序,从而通过并发来提供所需要的性能,这是很有难度的。找出一个问题中的并发性可能很简单,如为一个图像中的各个像素分别执行一个独立的操作流。或者也可能极其复杂,有多个共享信息的操作流,必须密切协调这些操作流的执行。
一旦找出问题中的并发性,程序员必须在他们的源代码中表述这种并发性。具体来讲,必须定义并发执行的操作流,并为它们关联执行时间,还要管理这些操作流之间的依赖性,保证并行运行这些操作流时可以生成正确的结果。这正是并行程序设计的核心问题。
大多数人都没有能力处理并行计算机底层细节。即使是专家级的并行程序员也不堪管理每一个内存冲突或调度单个线程带来的重负。因此,并行程序设计的关键是一个高层抽象或模型 (model),使并行程序设计问题更可管理。
目前有太多的编程模型,通常划分为不同的类别,但这些类别存在重叠,而且类别名往往含混不清,容易混淆。对我们而言,我们将考虑两个并行程序设计模型:任务并行 (task paral-lelism) 和数据并行 (data parallelism)。从高层来讲,这两个模型的基本思想很简单。
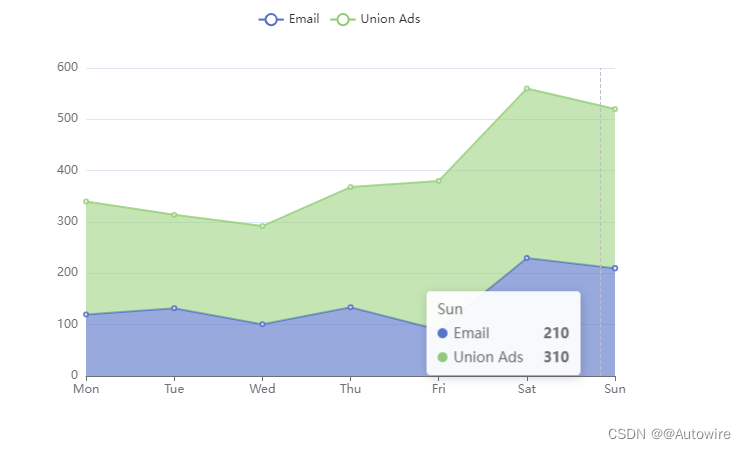
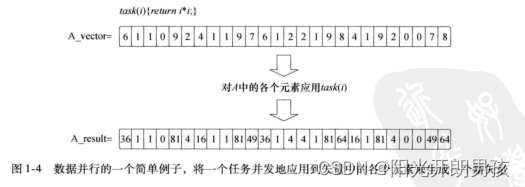
在数据并行程序设计模型中,程序员从可以并发更新的数据元素集合角度来考虑问题。并行性表述为将相同的指令流(一个任务)并发地应用到各个数据元素,并行性体现在数据中。我们在图1-4中提供了数据并行的一个简单例子。考虑一个简单的任务:返回一个输入数字矢量(A_vector)的平方。使用数据并行程序设计模型,通过将任务应用到矢量中的每一个元素来并行地更新矢量,生成一个新的结果矢量。当然,这个例子非常简单。在实际中,任务中的操作数必然很大,从而能分摊数据移动的开销并管理并行计算。不过,图1-4中的这个简单例子完全可以说明这个编程模型的核心思想。
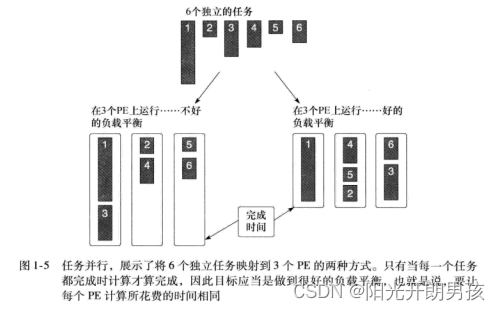
在任务并行程序设计模型中,程序员直接定义和处理并发任务。问题分解为可以并发运行的任务,然后再映射到一个并行计算机的处理单元 (Processing Element,PE) 来执行。如果任务是完全独立的,使用这个模型最为容易,不过这个模型也可以用于共享数据的任务。如果要利用一组任务来计算,只有当最后一个任务完成时这个计算才算完成。因为任务的计算需求差别很大,合理地分布任务使它们能够在大致相同的时间完成可能很困难。这是一个负载平衡的问题。考虑图1-5中的例子,这里有6个独立的任务在3个处理单元上并发执行。在第一种情况下,第一个处理单元有太多的工作要做,运行的时间远远大于其他处理单元。第二种情况采用了一种不同的任务分布,这里给出了一个更理想的情况,各个处理单元几乎同时完成。这是并行计算中一个核心思想的例子,即负载平衡 (load balancing)。
在数据并行和任务并行之间做何选择,这要由所解决问题的具体需要来确定。例如,与网格上节点更新有关的问题就可以立即对应到数据并行模型。另一方面,表述为图遍历的问题就可以很自然地考虑采用任务并行模型。因此,一个全面的并行程序员需要对这两种编程模型都很熟悉。另外,作为通用的编程框架(如OpenCL),也必须同时支持这两种模型。
除了编程模型之外,并行程序设计过程的下一步是将程序映射到真正的硬件。这里,异构计算机就会带来特有的问题。系统中的计算单元可能有不同的指令集和不同的内存体系结构,而且可能以不同的速度运行。一个有效可行的程序必须了解这些差别,并能适当地将并行软件映射到最合适的OpenCL设备。
通常,程序员要处理这个问题,需要把他们的软件想象成一组模块,分别实现问题的不同部分。这些模块显式地绑定到异构平台中的组件。例如,图形软件在GPU上运行,其他软件在CPU上运行。
通用GPU (General-Purpose GPU,GPGPU)编程打破了这个模型。图形以外的算法会修改为适合于GPU处理。CPU完成计算并管理VO,不过所有“实质性的”计算都“分摊”给GPU。基本上,异构平台会被忽略,而把重点放在系统中的一个组件上:GPU。
OpenCL不建议采用这种方法。实际上,既然用户已经为系统中的“所有OpenCL设备”付了钱,有效的程序就应当使用所有这些设备。这正是OpenCL鼓励程序员采用的做法,也是我们对异构平台设计编程环境的期望。
硬件异构性很复杂。程序员越来越依赖于隐藏硬件复杂性的高层抽象。异构编程语言则是公布异构性,与增加抽象的趋势背道而驰。
这并没有问题。一种语言不必解决每一个程序员群体的需求。简化编程问题的高层框架可以对应到高层语言,它进一步映射到底层硬件抽象层来保证可移植性。OpenCL正是这个硬件抽象层。