-
简介
为了解决 Yarn 中 ResourceManager 的单点故障问题,在 Hadoop 2.4 中新增了 ResourceManager HA 的能力, 该文章基于 Hadoop 3.1.1 进行讲解。
1.1. 名词定义
| 全称 | 简称 | 备注 |
| ResourceManager | Rm | |
| Zookeeper | ZK |
-
ResourceManager Ha 架构
ResourceManager HA 是基于 Active/Standby 架构形态,在集群中任意时刻最多只能有一个 Active 状态的 Rm 一个或多个 Standby 状态的 Rm,当 Active RM 故障时会基于 Zookeeper Watcher 机制从 Standby 状态的 Rm 中选取出一个 Rm 进行接管实现自动的故障转移。
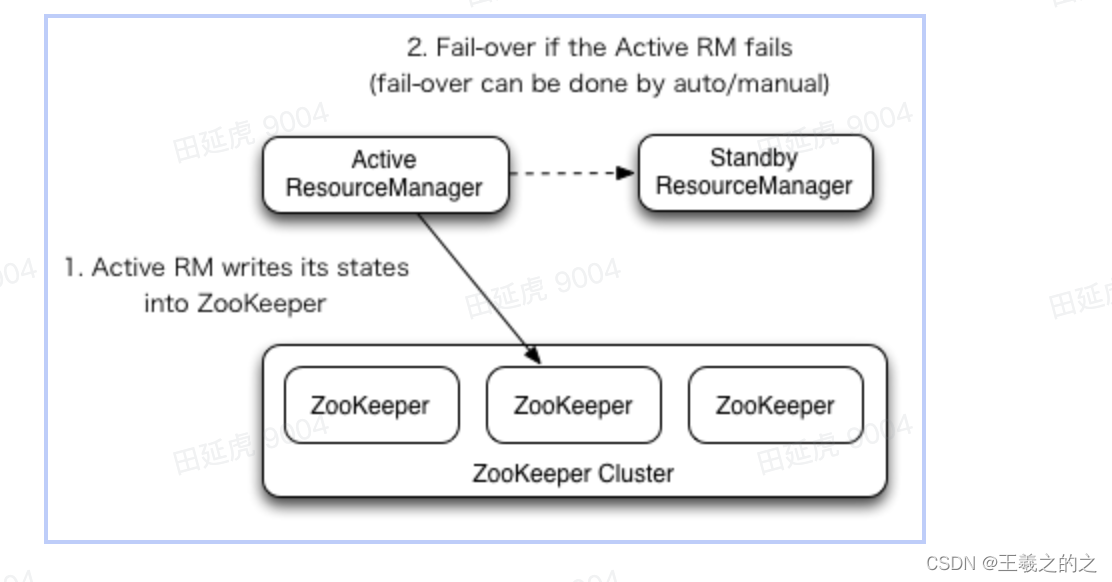
-
ResourceManager 启用 HA
在 yarn-site.xml 新增以下配置并分发重启 Yan 集群即可重启 ResourceManager HA
| 配置名称 | 默认值 | 配置描述 | |
| hadoop.zk.address | 用于 ResourceManager 故障转移和 Yarn 集群元数据存储的 Zk 集群地址 | ||
| yarn.resourcemanager.ha.enabled | FALSE | 是否启用 Rm Ha | |
| yarn.resourcemanager.ha.rm-ids | 集群中多个 ResourceManager 逻辑 Rm-Id 列表eg: rm1 、rm2 | ||
| yarn.resourcemanager.address.rm-id | 指定 rm-id 对应 ClientRMService Rpc 服务地址 host:porteg: offline1:8032 | ||
| yarn.resourcemanager.scheduler.address.rm-id | 指定 rm-id 对应 ApplicationMasterService Rpc 服务地址 host:porteg: offline1:8030 | ||
| yarn.resourcemanager.resource-tracker.address.rm-id | 指定 rm-id 对应 ResourceTrackerService Rpc 服务地址 host:porteg: offline1:8031 | ||
| yarn.resourcemanager.admin.address.rm-id | 指定 rm-id 对应 AdminService Rpc 服务地址 host:porteg: offline1:8033 | ||
| yarn.resourcemanager.webapp.address.rm-id | 指定 rm-id 对应 Http 服务地址 host:porteg: offline1:8088 | ||
| yarn.resourcemanager.webapp.https.address.rm-id | 指定 rm-id 对应 Https 服务地址 host:porteg: offline1:8090 | ||
| yarn.resourcemanager.ha.id | Ha 对应的 Id | ||
| yarn.resourcemanager.ha.automatic-failover.enabled | FALSE | 是否启用自动故障转移 | |
| yarn.resourcemanager.ha.automatic-failover.embedded | TRUE | 是否启用内置的自动故障转移(EmbeddedElector) | |
| yarn.resourcemanager.cluster-id | yarn_cluster | 集群名称 | |
| yarn.client.failover-proxy-provider | 开启 HA 时 Client 、NM 访问 RM 代理类默认值:org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider | ||
| yarn.client.failover-no-ha-proxy-provider | 关闭 HA 时 Client 、NM 访问 RM 代理类默认值:org.apache.hadoop.yarn.client.DefaultNoHARMFailoverProxyProvider | ||
| yarn.client.failover-max-attempts | -1无限制 | Failover 失败最大尝试次数 | |
| yarn.client.failover-sleep-base-ms | 30s | 不配置则使用 yarn.resourcemanager.connect.retry-interval.ms的参数值 | |
| yarn.client.failover-sleep-max-ms | 30s | 不配置则使用 yarn.resourcemanager.connect.retry-interval.ms的参数值 | |
| yarn.client.failover-retries | 30 | 尝试重试链接 RM 的次数rmConnectWaitMS / failoverSleepBaseMs | |
| yarn.client.failover-retries-on-socket-timeouts | 45s | 链接超时时间 | |
| yarn.resourcemanager.zk-timeout-ms | 10000ms | 连接 Zk 超时时间 | |
| yarn.resourcemanager.zk-address | ZK 集群地址 | ||
| yarn.resourcemanager.ha.failover-controller.active-standby-elector.zk.retries | 3 | 选择链接 Zk 重试次数如果不配置则使用:ha.failover-controller.active-standby-elector.zk.op.retries默认值为:3 次 | |
-
ResourceManager 故障转移的两种模式
4.1. 手动模式下的故障转移
-
在没有开启自动故障转移时,使用 Yarn 用户执行命令进行主备切换
yarn.resourcemanager.ha.automatic-failover.enabled = false
-
命令由 Yarn Client 向 ResoceManager 中的 AdminServer 发起执行对应的切主或切备操作
#获取所有 RM 的状态 yarn rmadmin -getAllServiceState #获取指定 RM 状态 yarn rmadmin -getServiceState rm2 #将指定 RM 切换为 Standby 状态 yarn rmadmin -transitionToStandby rm2 #将指定 RM 切换为 Active 状态 yarn rmadmin -transitionToActive --forceactive rm2

4.2. 自动模式下的故障转移
-
当我们将 “yarn.resourcemanager.ha.automatic-failover.enabled” 设置为 true 时 Yarn 就会启用 ResourceManager 自动的故障转移
-
在以下时机会触发自动选住行为
-
当 ResourceManager 启动时选主
-
当 Active ResourceManager 故障时触发选主
-
当 Active ResourceManager 在操作 ZK 上的元数据失败时触发选主
-
4.2.1. ResourceManager 启动时选主
-
开启 HA 的 ResourceManager 启动首先会调用 transitionToStandby 方法让当前 RM 进入 Standby 状态
-
随后会启动 ResourceManager 纳管的各项服务,其中包含 ActiveStandbyElectorBasedElectorService
-
ActiveStandbyElectorBasedElectorService 会调用内部的选主服务(ActiveStandbyElector)参与选主,会尝试在选主目录下创建 ActiveStandbyElectorLock 临时节点
private void createLockNodeAsync() { zkClient.create(zkLockFilePath, appData, zkAcl, CreateMode.EPHEMERAL, this, zkClient); }
-
并注册对应的监听器(ActiveStandbyElector)监听创建的结果
-
响应结果是临时节点创建成功则会调用 becomeActive() 方法将当前 ResourceManager 转换为 Active RM 对外提供服务
-
响应结果是是临时节点已经存在,则调用 becomeStandby( ) 将当前 RM 转换为 Standby RM
-
最后都会调用 monitorActiveStatus() 方法对选主的临时节点状态(exists)进行监控
-
其它响应结果则尝试重试选主
-
/** * 处理 Client 执行 create 函数结果的回调函数 */ public synchronized void processResult(...) { ... if (isSuccess(code)) { if (becomeActive()) { //对节点进行监听 monitorActiveStatus(); } else { //如果 becomeActive 失败,等待 1s 后再尝试选举 reJoinElectionAfterFailureToBecomeActive(); } return; } if (isNodeExists(code)) { //如果选举的临时节点已经存在 if (createRetryCount == 0) { becomeStandby(); //如果尝试次数为 0 则转换为 Standby } ... monitorActiveStatus(); //再次 watch Zonde return; } .... if (shouldRetry(code)) { if (createRetryCount < maxRetryNum) { LOG.debug("Retrying createNode createRetryCount: " + createRetryCount); ++createRetryCount; //次数+1 createLockNodeAsync(); //创建 Znode 进行选主 return; } .... }

4.2.2. Active ResourceManager “故障” 时触发的选主
故障覆盖范围
由于节点故障导致该节点上的 ResourceManager 进程挂掉的情况 由于 ResourceManager 内部异常导致进程挂掉的情况 由于节点网络异常导致 ResourceManager 与 Zk 断链的情况 由于 ResourceManager 内部异常导致 ResourceManager 与 Zk 断链的情况
-
由上可知在 ResourceManager 启动后 Active、Standby ResourceManager 都会再监听选主临时节点的变化
-
当 Active ResourceManager 发生 “故障” 时机会再次触发选主
-
当 RM 的 Watcher 感知到选主的 Znode 变化之后接收到回调,出来回调的结果来决定是否参与选主
-
如果选主的 Znode 还存在,则对比 Znode 当前的 onwer 是否与当前 RM 持有的 Zk session 是否一致
-
如果一致则调用 becomeActive 尝试将当前 RM 转换为 active
-
否则调用 becomeStandby 切换到 Standby
-
-
如果 Znode 不存在了,则让当前 RM 先进入 NEUTRAL 状态,再执行 becomeStandby 切换到 Standby ,最后再调用 joinElectionInternal 方法去创建 Znode 参与选主
-

4.2.3. Active ResourceManager 操作 ZK 元数据失败触发的选主
4.2.3.1. RMStateStore 介绍
-
主要作用为 Yarn 的元数据存储服务,主要为作业的提交信息、运行时信息
-
RMStateStore 的实现方式有:FileSystem、Memory、LevelDB、ZK
-
ResourceManager 使用的 RMStateStroe 由 "yarn.resourcemanager.store.class“ 指定
-
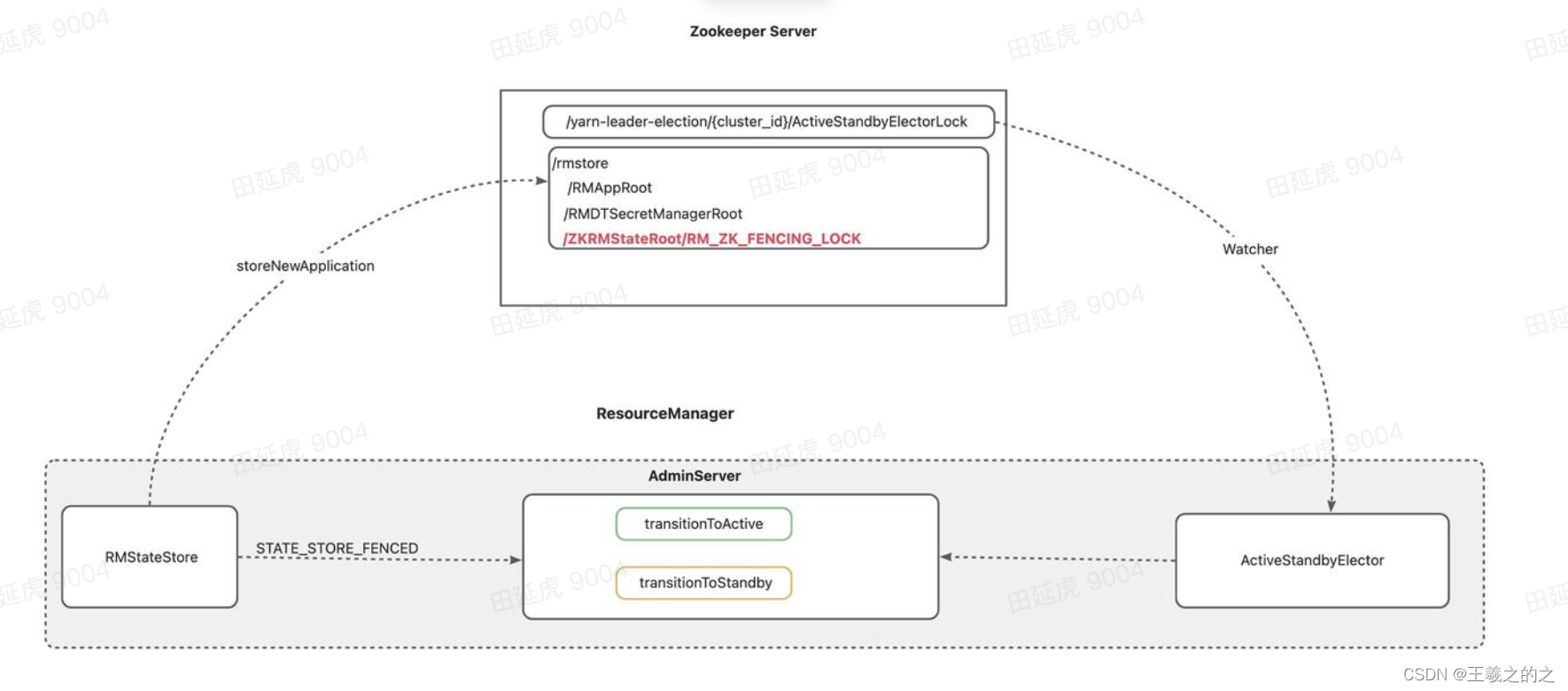
RMStateStore 在操作元数据失败时,会触发 STATE_STORE_FENCED 事件最后由 RMFatalEventDispatcher 调用 handleTransitionToStandByInNewThread 将当前 ResourceManager 状态转为 Standby
4.2.4. ZKRMStateStore 的 Fencing 机制
-
Fencing 机制主要是解决 ZKRMStateStore 在操作元数据发生脑裂问题,写入错误的数据
在实际生产情况,可能会出现 RM 在垃圾回收、机器负载过高等情况,会在长时间内整个系统无响应, 因此,也就无法向 zk 写入心跳信息,这样的话会导致选择的临时节点掉线备 RM 会切换到 Active 状态, 但是当前节点仍然会认为自己是 Active 节点,由此会导致整个集群会有同时有两个 Active RM
-
Yarn 为了解决该问题 RM 修改元数据时会,在 ZK 中元数据修改前创建一个持久化节点( RM_ZK_FENCING_LOCK) 并设置 ACL 独占对 Yarn 元数据的修改,在元数据修改之后删除该节点释放独占,并将这个三个操作绑定在一个事务中合并执行保证执行结果的一致性
RM_ZK_FENCING_LOCK 就是一个分布式锁,拿到锁的人才允许操作元数据
4.2.4.1. 操作元数据失败触发的选主
-
如下图 Active Rm 在调用 ZKRMStateStore 操作 Zk 上 Yarn 的元数据 (添加 App、删除 APP)过程中如果,操作失败或者发生异常则会触发 RMFatalEventType 事件
-
最后 RMFatalEventDispatcher 接收处理,并创建一个 StandByTransitionRunnable 线程调用 transitionToStandby 方法将当前 Active RM 转换为 Standby RM,并触发 ResourceManager HA 自动故障转移

ResourceManager HA 自动模式下故障紧急操作命令
-
如 HA 自动模式下异常脑裂时可使用 “forcemanual” 进行强制手动切换 Active 与 Standby
yarn rmadmin -transitionToActive --forcemanual rm2 /** Automatic failover is enabled for org.apache.hadoop.yarn.client.RMHAServiceTarget@12d3a4e9 Refusing to manually manage HA state, since it may cause a split-brain scenario or other incorrect state. If you are very sure you know what you are doing, please specify the --forcemanual flag. */
4.2.5. becomeActive/becomeStandby 主备切换方法详解
在 RM 选主时得到最终结果时调用 ActiveStandbyElector 的 becomeActive 方法将当前 Rm 切换为 active 节点 调用 becomeStandby 方法将当前节点切换为 Standby 节点
4.2.5.1. ResourceManager HA 服务纳管
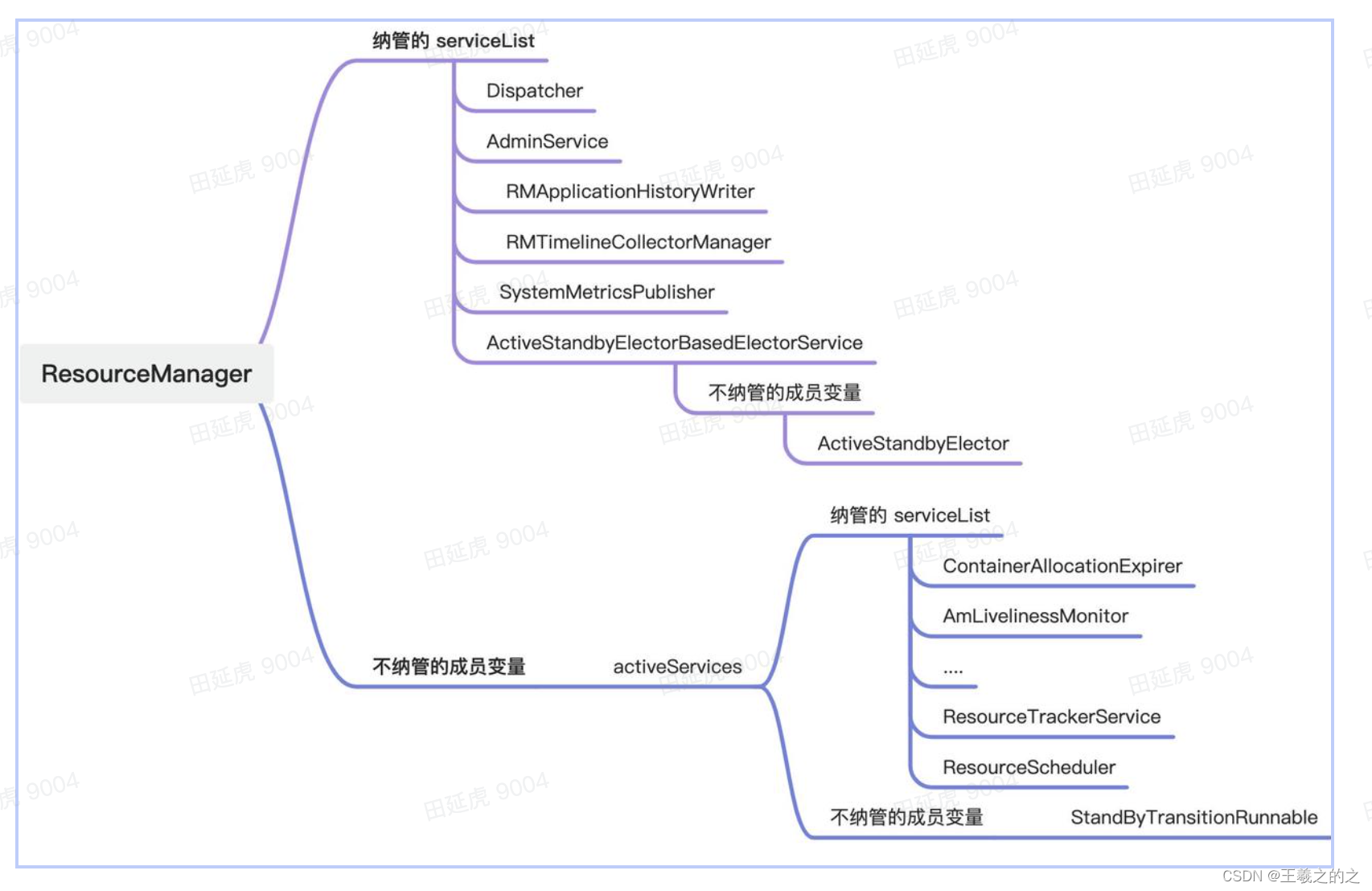
ResourceManger 在开启 HA 时 Standby RM 能正常选主和避免 Standby 状态时部分服务一直运行会导致异常运行,将服务拆分为两大类管理:
-
主备切换时不需要重启的服务,会在 ResourceManager 进程中一直运行提供服务
-
Dispatcher :核心事件转发器
-
ActiveStandbyElectorBasedElectorService : 选主器
-
AdminService :RM 管理服务
-
-
主切换时需要重启的服务,交给 RMActiveServices 管理,在 Standby 状态事将管理的服务全部停止,在 Active 状态时会创建 RMActiveServices 以及下面管理的各项子服务对外提供服务
-
RMStateStore
-
nodesListManager
-
ClientRMService
-
ApplicationMasterService
-
ResourceScheduler
-
4.2.5.2. becomeActive 过程详解
-
当 Rm 选主器 Watcher 到 Zk 上选主的临时节点被删除时就会触发选主,当该 Rm 的选主器在 Zk 上创建选主节点成功后,就会调用 becomeActive 方法将当前 RM 转换为 Active Rm
-
选主器(ActiveStandbyElector) 的 becomeActive 方法首先会 AdminService 内部服务的 transitionToActive 方法将所有内部服务拉起能够对外提供服务
-
其次会更新选主器状态为 ACTIVE 标记当前 Rm 为 Active Rm
private boolean becomeActive() { ... try { ... LOG.debug("Becoming active for {}", this); //初始化 Active Rm 内部服务 appClient.becomeActive(); //更新当前 RM 的状态 state = State.ACTIVE; return true; } catch (Exception e) { LOG.warn("Exception handling the winning of election", e); return false; } }
-
transitionToActive 过程中
-
首先会调用 refreshAll 重新加载最新的配置
-
//队列调度配置 refreshQueues(); //刷新 include、exclude 节点信息 refreshNodes(); //刷新超级用户信息 refreshSuperUserGroupsConfiguration(); //刷新用户组映射信息 refreshUserToGroupsMappings(); //刷新各服务 acl 信息 if (getConfig().getBoolean( CommonConfigurationKeysPublic.HADOOP_SECURITY_AUTHORIZATION, false)) { refreshServiceAcls(); }
-
其次将其 RMActiveServices 纳管的各项子服务全部启动
-
最后更新 RM 上下文(RMContext)的 HA 状态
-
该状态用于内部 RM HA 的状态判断和外部调用 AdminService Rpc 服务时核心方法是否能允许执行的判断
-
4.2.5.3. becomeStandby 过程详解
-
当 Active Rm 故障与 Zk 断连最终导致持有的 Zk 上的选主节点被删除掉时,当该 Rm 的选主器也会感知到该事件,同时再次会参与选主,再次选主失败后 ,就会调用 becomeStandby 方法将当前 RM 转换为 Standby Rm
-
选主器(ActiveStandbyElector) 的 becomeStandby 方法首先会将选主器的状态转为 STANDBY
private void becomeStandby() { if (state != State.STANDBY) { //先更新状态为 STANDBY,不对外提供服务 state = State.STANDBY; appClient.becomeStandby(); } }
-
其次调用 AdminService 的 transitionToStandby 方法
-
首先会将 RM 上下文(RMContext)的 HA 状态更新为 Standby
-
其次将 RMActiveServices 纳管的各项子服务关闭
-
最后清空内部统计指标、重置各基础服务信息
-