协议:CC BY-NC-SA 4.0
译者:飞龙
本文来自【OpenDocCN 饱和式翻译计划】,采用译后编辑(MTPE)流程来尽可能提升效率。
收割 SB 的人会被 SB 们封神,试图唤醒 SB 的人是 SB 眼中的 SB。——SB 第三定律
十、加密和解密文件
原文:https://inventwithpython.com/cracking/chapter10.html
“为什么治安警察抓人并刑讯逼供来获取他们的信息?硬盘对酷刑毫无抵抗力。你需要给硬盘一个抵抗的方法。这就是密码学。”
——Patrick Ball,人权数据分析小组

在前面的章节中,我们的程序只处理一些小消息,这些小消息是我们作为字符串值直接输入到源代码中的。我们在这一章中制作的密码程序将允许你加密和解密整个文件,这些文件的大小可能有数百万个字符。
本章涵盖的主题
-
open()函数 -
读取和写入文件
-
write()、close()和read()文件对象方法 -
os.path.exists()函数 -
upper()、lower()和title()字符串方法 -
startswith()和endswith()字符串方法 -
time模块和time.time()函数
纯文本文件
换位文件密码程序加密和解密纯(无格式)文本文件。这种文件只有文本数据,通常带有.txt文件扩展名。可以用 Windows 上的记事本、macOS 上的 TextEdit、Linux 上的 gedit 等程序编写自己的文本文件。(文字处理程序也可以生成纯文本文件,但请记住,它们不会保存任何字体、大小、颜色或其他格式。)你甚至可以使用 IDLE 的文件编辑器,用.txt扩展代替了通常的.py扩展保存文件。
对于某些示例,您可以从www.nostarch.com/crackingcodes下载文本文件。这些示例文本文件是现在公共领域的书籍,可以合法下载和使用。例如,玛丽·雪莱的经典小说《弗兰肯斯坦》在其文本文件中有超过 78000 个单词!把这本书输入加密程序要花很多时间,但通过使用下载的文件,程序可以在几秒钟内完成加密。
换位文件密码程序的源代码
与换位密码测试程序一样,换位文件密码程序导入transpositonecrypt.py和transpositonecrypt.py文件,以便调用encryptMessage()和decryptMessage()函数。因此,您不必在新程序中重新键入这些函数的代码。
选择文件 -> 新文件,打开新文件编辑器窗口。在文件编辑器中输入以下代码,保存为transpositionfilecipher.py。然后从www.nostarch.com/crackingcodes下载frankenstein.txt,并将该文件放在与transpositoinfilecipher.py文件相同的文件夹中。按F5运行程序。
换位
FileCipher.py
# Transposition Cipher Encrypt/Decrypt File
# https://www.nostarch.com/crackingcodes/ (BSD Licensed)
import time, os, sys, transpositionEncrypt, transpositionDecrypt
def main():
inputFilename = 'frankenstein.txt'
# BE CAREFUL! If a file with the outputFilename name already exists,
# this program will overwrite that file:
outputFilename = 'frankenstein.encrypted.txt'
myKey = 10
myMode = 'encrypt' # Set to 'encrypt' or 'decrypt'.
# If the input file does not exist, the program terminates early:
if not os.path.exists(inputFilename):
print('The file %s does not exist. Quitting...' % (inputFilename))
sys.exit()
# If the output file already exists, give the user a chance to quit:
if os.path.exists(outputFilename):
print('This will overwrite the file %s. (C)ontinue or (Q)uit?' %
(outputFilename))
response = input('> ')
if not response.lower().startswith('c'):
sys.exit()
# Read in the message from the input file:
fileObj = open(inputFilename)
content = fileObj.read()
fileObj.close()
print('%sing...' % (myMode.title()))
# Measure how long the encryption/decryption takes:
startTime = time.time()
if myMode == 'encrypt':
translated = transpositionEncrypt.encryptMessage(myKey, content)
elif myMode == 'decrypt':
translated = transpositionDecrypt.decryptMessage(myKey, content)
totalTime = round(time.time() - startTime, 2)
print('%sion time: %s seconds' % (myMode.title(), totalTime))
# Write out the translated message to the output file:
outputFileObj = open(outputFilename, 'w')
outputFileObj.write(translated)
outputFileObj.close()
print('Done %sing %s (%s characters).' % (myMode, inputFilename,
len(content)))
print('%sed file is %s.' % (myMode.title(), outputFilename))
# If transpositionCipherFile.py is run (instead of imported as a module),
# call the main() function:
if __name__ == '__main__':
main()
换位文件密码程序运行示例
当您运行transpositonfilecipher.py程序时,它应该产生以下输出:
Encrypting...
Encryption time: 1.21 seconds
Done encrypting frankenstein.txt (441034 characters).
Encrypted file is frankenstein.encrypted.txt.
一个新的Frankenstein.encrypted.txt文件被创建在与transpositoinfilecipher.py相同的文件夹中。当你用 IDLE 的文件编辑器打开这个文件时,你会看到frankenstein.py的加密内容。它应该是这样的:
PtFiyedleo a arnvmt eneeGLchongnes Mmuyedlsu0#uiSHTGA r sy,n t ys
s nuaoGeL
sc7s,
--snip--
一旦你有了一个加密的文本,你可以把它发送给别人解密。收件人还需要有换位文件密码程序。
要解密文本,请对源代码(粗体)进行以下更改,并再次运行换位文件密码程序:
inputFilename = 'frankenstein.encrypted.txt'
# BE CAREFUL! If a file with the outputFilename name already exists,
# this program will overwrite that file:
outputFilename = 'frankenstein.decrypted.txt'
myKey = 10
myMode = 'decrypt' # Set to 'encrypt' or 'decrypt'.
这一次当你运行程序时,一个名为Frankenstein.decrypted.txt的新文件会出现在文件夹中,该文件与原来的frankenstein.txt文件完全相同。
处理文件
在我们深入研究transpositionfilecipher.py的代码之前,让我们先来看看 Python 是如何处理文件的。读取文件内容的三个步骤是:打开文件,将文件内容读入变量,然后关闭文件。同样,要在文件中写入新内容,您必须打开(或创建)文件,写入新内容,然后关闭文件。
打开文件
Python 可以使用open()函数打开一个文件进行读写。open()函数的第一个参数是要打开的文件名。如果文件与 Python 程序在同一个文件夹中,可以只使用文件名,比如'thetimemachine.txt'。如果打开timemachine.txt的命令与你的 Python 程序存在于同一个文件夹中,该命令如下所示:
fileObj = open('thetimemachine.txt')
一个文件对象存储在fileObj变量中,该变量将用于读取或写入文件。
您还可以指定文件的绝对路径,包括文件所在的文件夹和父文件夹。比如'C:\\Users\\Al\\frankenstein.txt'(Windows 上)和'/Users/Al/frankenstein.txt'(MAC OS 和 Linux 上)就是绝对路径。请记住,在 Windows 上,必须通过在反斜杠(\)前键入另一个反斜杠来对其进行转义。
例如,如果您想打开frankenstein.txt文件,您可以将文件的路径作为字符串传递给open()函数的第一个参数(并根据您的操作系统格式化绝对路径):
fileObj = open('C:\\Users\\Al\\frankenstein.txt')
file 对象有几种写入、读取和关闭文件的方法。
写入并关闭文件
对于加密程序,在读入文本文件的内容后,您需要将加密(或解密)的内容写入一个新文件,这将通过使用write()方法来完成。
要在文件对象上使用write(),需要以写模式打开文件对象,这可以通过将字符串'w'作为第二个参数传递给open()来实现。(第二个参数是一个可选参数,因为open()函数仍然可以在不传递两个参数的情况下使用。)例如,在交互式 shell 中输入以下代码行:
>>> fileObj = open('spam.txt', 'w')
这一行以写模式创建了一个名为spam.txt的文件,这样您就可以编辑它了。如果在open()函数创建新文件的地方存在同名文件,旧文件将被覆盖,因此在写入模式下使用open()时要小心。
随着spam.txt现在以写模式打开,您可以通过调用文件上的write()方法写入文件。write()方法有一个参数:要写入文件的文本字符串。在交互 shell 中输入以下内容将'Hello, world!'写入spam.txt :
>>> fileObj.write('Hello, world!')
13
将字符串'Hello, world!'传递给write()方法,将该字符串写入spam.txt文件,然后打印13,即写入文件的字符串中的字符数。
当您处理完一个文件时,您需要通过调用file对象上的close()方法来告诉 Python 您已经处理完了这个文件:
>>> fileObj.close()
还有一种附加模式,它类似于写模式,只是附加模式不会覆盖文件。相反,字符串被写到文件中已有内容的末尾。虽然我们不会在这个程序中使用它,但是您可以通过将字符串'a'作为第二个参数传递给open()来以追加模式打开一个文件。
如果您在尝试调用file对象上的write()时得到一个io.UnsupportedOperation: not readable错误消息,您可能没有以写模式打开该文件。当您不包括open()函数的可选参数时,它会自动以读取模式('r')打开文件对象,这允许您只对文件对象使用read()方法。
从文件中读取
read()方法返回一个包含文件中所有文本的字符串。为了进行测试,我们将读取之前用write()方法创建的spam.txt文件。从交互式 shell 中运行以下代码:
>>> fileObj = open('spam.txt', 'r')
>>> content = fileObj.read()
>>> print(content)
Hello world!
>>> fileObj.close()
文件打开,创建的文件对象存储在fileObj变量中。一旦有了file对象,就可以使用read()方法读取文件,并将其存储在content变量中,然后打印出来。当你处理完文件对象后,你需要用close()关闭它。
如果您得到错误消息IOError: [Errno 2] No such file or directory,请确保文件确实在您认为的位置,并再次检查您键入的文件名和文件夹名是否正确。(目录是文件夹的别称。)
我们将在transpositionfilecipher.py中打开的文件上使用open()、read()、write()和close()进行加密或解密。
设置main()函数
transpositonfilecipher.py程序的第一部分应该看起来很熟悉。第 4 行是程序transpositionEncrypt.py和transpositionencrypt.py以及 Python 的time、os和sys模块的import语句。然后我们开始main(),设置一些在程序中使用的变量。
# Transposition Cipher Encrypt/Decrypt File
# https://www.nostarch.com/crackingcodes/ (BSD Licensed)
import time, os, sys, transpositionEncrypt, transpositionDecrypt
def main():
inputFilename = 'frankenstein.txt'
# BE CAREFUL! If a file with the outputFilename name already exists,
# this program will overwrite that file:
outputFilename = 'frankenstein.encrypted.txt'
myKey = 10
myMode = 'encrypt' # Set to 'encrypt' or 'decrypt'.
inputFilename变量保存要读取的文件的字符串,加密(或解密)的文本被写入在outputFilename中命名的文件。换位密码使用一个整数作为密钥,存储在myKey中。程序期望myMode存储'encrypt'或'decrypt'来告诉它加密或解密inputFilename文件。但是在我们能够读取inputFilename文件之前,我们需要使用os.path.exists()来检查它是否存在。
检查文件是否存在
读取文件总是无害的,但是写入文件时需要小心。在写入模式下对已经存在的文件名调用open()函数会覆盖原始内容。使用os.path.exists()函数,您的程序可以检查该文件是否已经存在。
os.path.exists()函数
os.path.exists()函数采用单个字符串参数作为文件名或文件路径,如果文件已经存在,则返回True,如果不存在,则返回False。os.path.exists()函数存在于path模块中,后者存在于os模块中,所以当我们导入os模块时,path模块也被导入。
在交互式 shell 中输入以下内容:
>>> import os
>>> os.path.exists('spam.txt') # ➊
False
>>> os.path.exists('C:\\Windows\\System32\\calc.exe') # Windows
True
>>> os.path.exists('/usr/local/bin/idle3') # macOS
False
>>> os.path.exists('/usr/bin/idle3') # Linux
False
在这个例子中,os.path.exists()函数确认calc.exe文件存在于 Windows 中。当然,只有在 Windows 上运行 Python 时,才能得到这些结果。记住在 Windows 文件路径中转义反斜杠,方法是在它前面键入另一个反斜杠。如果你使用的是 macOS,只有 macOS 的例子会返回真,对于 Linux 只有最后一个例子会返回真。如果没有给出完整的文件路径 ➊,Python 将检查当前的工作目录。对于 IDLE 的交互式 shell,这是安装 Python 的文件夹。
用os.path.exists()函数检查输入文件是否存在
我们使用os.path.exists()函数来检查inputFilename中的文件名是否存在。否则,我们没有要加密或解密的文件。我们在第 14 行到第 17 行这样做:
# If the input file does not exist, then the program terminates early:
if not os.path.exists(inputFilename):
print('The file %s does not exist. Quitting...' % (inputFilename))
sys.exit()
如果文件不存在,我们向用户显示一条消息,然后退出程序。
使用字符串方法使用户输入更加灵活
接下来,该程序检查是否存在与outputFilename同名的文件,如果存在,它会要求用户键入C以继续运行该程序,或者键入Q以退出该程序。因为用户可能会输入各种响应,比如'c'、'C',甚至是单词'Continue',我们希望确保程序会接受所有这些版本。为此,我们将使用更多的字符串方法。
upper()、lower()和title()字符串方法
upper()和lower()字符串方法将分别以全大写或全小写字母返回它们被调用的字符串。在交互式 shell 中输入以下内容,查看这些方法如何处理同一个字符串:
>>> 'Hello'.upper()
'HELLO'
>>> 'Hello'.lower()
'hello'
正如lower()和upper()字符串方法返回小写或大写的字符串一样,title()字符串方法返回大写的字符串。标题大小写是每个单词的第一个字符大写,其余字符小写。在交互式 shell 中输入以下内容:
>>> 'hello'.title()
'Hello'
>>> 'HELLO'.title()
'Hello'
>>> 'extra! extra! man bites shark!'.title()
'Extra! Extra! Man Bites Shark!'
稍后我们将在程序中使用title()来格式化我们为用户输出的消息。
startswith()和endswith()字符串方法
如果在字符串的开头找到了它的字符串参数,startswith()方法将返回True。在交互式 shell 中输入以下内容:
>>> 'hello'.startswith('h')
True
>>> 'hello'.startswith('H')
False
>>> spam = 'Albert'
>>> spam.startswith('Al') # ➊
True
startswith()方法区分大小写,也可以用于多字符字符串 ➊。
endswith()字符串方法用于检查一个字符串值是否以另一个指定的字符串值结尾。在交互式 shell 中输入以下内容:
>>> 'Hello world!'.endswith('world!')
True
>>> 'Hello world!'.endswith('world') # ➋
False
字符串值必须完全匹配。注意,'world' ➋ 中缺少感叹号导致endswith()返回False。
在程序中使用这些字符串方法
如前所述,我们希望程序接受任何以C开头的响应,而不考虑大小写。这意味着无论用户键入c、continue、C还是另一个以C开头的字符串,我们都希望文件被覆盖。我们将使用字符串方法lower()和startswith()使程序在接受用户输入时更加灵活:
# If the output file already exists, give the user a chance to quit:
if os.path.exists(outputFilename):
print('This will overwrite the file %s. (C)ontinue or (Q)uit?' %
(outputFilename))
response = input('> ')
if not response.lower().startswith('c'):
sys.exit()
在第 23 行,我们获取字符串的第一个字母,并使用startswith()方法检查它是否是一个C。我们使用的startswith()方法区分大小写,并检查小写的'c',所以我们使用lower()方法修改response字符串的大写,使其总是小写。如果用户没有输入以C开头的响应,那么startswith()返回False,使得if语句求值为True(因为if语句中的not),调用sys.exit()结束程序。技术上,用户不必输入Q退出;任何不以C开头的字符串都会导致调用sys.exit()函数来退出程序。
读取输入文件
在第 27 行,我们开始使用本章开始时讨论的文件对象方法。
# Read in the message from the input file:
fileObj = open(inputFilename)
content = fileObj.read()
fileObj.close()
print('%sing...' % (myMode.title()))
第 27 到 29 行打开存储在inputFilename中的文件,将其内容读入content变量,然后关闭文件。读入文件后,第 31 行向用户输出一条消息,告诉他们加密或解密已经开始。因为myMode应该包含字符串'encrypt'或'decrypt',所以调用title()字符串方法会将myMode中字符串的第一个字母大写,并将字符串拼接到'%sing'字符串中,所以它会显示'Encrypting...'或'Decrypting...'。
测量加密或解密所需的时间
加密或解密整个文件可能比一个短字符串需要更长的时间。用户可能想知道处理一个文件需要多长时间。我们可以通过使用time模块来测量加密或解密过程的长度。
time模块和time.time()函数
time.time()函数返回当前时间,作为自 1970 年 1 月 1 日以来的秒数的浮点值。这一时刻被称为 Unix 纪元。在交互式 shell 中输入以下内容,看看这个函数是如何工作的:
>>> import time
>>> time.time()
1540944000.7197928
>>> time.time()
1540944003.4817972
因为time.time()返回一个浮点值,所以可以精确到一个毫秒(即 1/1000 秒)。当然,time.time()显示的数字取决于调用这个函数的时间,可能很难解释。可能不清楚 1540944000.7197928 是 2018 年 10 月 30 日星期二,大约下午 5 点。然而,time.time()函数对于比较调用time.time()之间的秒数很有用。我们可以用这个函数来确定一个程序已经运行了多长时间。
例如,如果您减去我之前在交互式 shell 中调用time.time()时返回的浮点值,您将得到我键入时这些调用之间的时间:
>>> 1540944003.4817972 - 1540944000.7197928
2.7620043754577637
如果你需要编写处理日期和时间的代码,参见www.nostarch.com/crackingcodes获取关于datetime模块的信息。
使用程序中的time.time()函数
在第 34 行,time.time()返回当前时间,存储在名为startTime的变量中。第 35 到 38 行调用encryptMessage()或decryptMessage(),这取决于'encrypt'或'decrypt'是否存储在myMode变量中。
# Measure how long the encryption/decryption takes:
startTime = time.time()
if myMode == 'encrypt':
translated = transpositionEncrypt.encryptMessage(myKey, content)
elif myMode == 'decrypt':
translated = transpositionDecrypt.decryptMessage(myKey, content)
totalTime = round(time.time() - startTime, 2)
print('%sion time: %s seconds' % (myMode.title(), totalTime))
第 39 行在程序解密或加密并从当前时间中减去startTime后再次调用time.time()。结果是两次调用time.time()之间的秒数。time.time() - startTime表达式计算出一个传递给round()函数的值,该值四舍五入到最接近的两位小数点,因为程序不需要毫秒精度。该值存储在totalTime中。第 40 行使用字符串拼接来打印程序模式,并向用户显示程序加密或解密所花费的时间。
写入输出文件
加密(或解密)的文件内容现在存储在translated变量中。但是当程序终止时,这个字符串就被遗忘了,所以我们想把这个字符串存储在一个文件中,以便在程序结束运行后仍然存在。第 43 到 45 行的代码通过打开一个新文件(并将'w'传递给open()函数)然后调用write()文件对象方法来实现这一点:
# Write out the translated message to the output file:
outputFileObj = open(outputFilename, 'w')
outputFileObj.write(translated)
outputFileObj.close()
然后,第 47 行和第 48 行向用户显示更多消息,表明该过程已经完成,并显示所写文件的名称:
print('Done %sing %s (%s characters).' % (myMode, inputFilename,
len(content)))
print('%sed file is %s.' % (myMode.title(), outputFilename))
第 48 行是main()函数的最后一行。
调用main()函数
第 53 行和第 54 行(在第 6 行的def语句执行后执行)调用main()函数,如果该程序正在运行而不是正在导入:
# If transpositionCipherFile.py is run (instead of imported as a module),
# call the main() function:
if __name__ == '__main__':
main()
这在第 95 页的变量__name__T2 中有详细解释。
总结
恭喜你!除了open()、read()、write()和close()函数之外,transpositonfilecipher.py程序没什么特别的,这些函数让我们可以加密硬盘上的大型文本文件。您学习了如何使用os.path.exists()函数来检查文件是否已经存在。如您所见,我们可以通过导入新程序中使用的函数来扩展程序的函数。这大大提高了我们使用计算机加密信息的能力。
您还学习了一些有用的字符串方法,使程序在接受用户输入时更加灵活,以及如何使用time模块来测量程序运行的速度。
与凯撒密码程序不同,换位文件密码有太多可能的密钥,无法简单地使用暴力进行攻击。但是,如果我们能编写一个识别英语的程序(而不是一连串的胡言乱语),计算机就能检查成千上万次解密尝试的结果,并确定哪个密钥能成功地将一条信息解密成英语。你将在第 11 章中学习如何做到这一点。
练习题
练习题的答案可以在本书的网站www.nostarch.com/crackingcodes找到。
os.exists()和os.path.exists()哪个正确?
-
Unix 纪元是什么时候?
-
下面的表达式表示什么?
'Foobar'.startswith('Foo') 'Foo'.startswith('Foobar') 'Foobar'.startswith('foo') 'bar'.endswith('Foobar') 'Foobar'.endswith('bar') 'The quick brown fox jumped over the yellow lazy dog.'.title()
十一、以编程方式检测英语
原文:https://inventwithpython.com/cracking/chapter11.html
“老头子说了些更长更复杂的话。过了一会儿,Waterhouse(现在戴着他的密码分析师帽子,在明显的随机性中寻找意义,他的神经回路利用了信号中的冗余)意识到这个人说的是带有浓重口音的英语。”
——尼尔·斯蒂芬森,Cryptonomicon

以前,我们使用换位文件密码来加密和解密整个文件,但我们还没有尝试编写一个暴力破解程序来破解密码。用换位文件加密法加密的信息可以有成千上万个可能的密钥,你的计算机仍然可以很容易地对这些密钥进行暴力破解,但是你必须查看成千上万个解密文本才能找到一个正确的明文。你可以想象,这可能是一个大问题,但有一个解决办法。
当计算机使用错误的密钥解密消息时,得到的字符串是垃圾文本而不是英文文本。我们可以给计算机编程,让它识别解密后的信息是英语。这样,如果计算机使用错误的密钥解密,它知道继续尝试下一个可能的密钥。最终,当计算机尝试用一个密钥来解密英文文本时,它会停下来让你注意到这个密钥,让你不必查看成千上万个不正确的解密。
本章涵盖的主题
-
字典数据类型
-
split()方法 -
None值 -
除零错误
-
float()、int()、str()函数和整数除法 -
append()列表方法 -
默认参数
-
计算百分比
计算机如何理解英语?
计算机不能理解英语,至少不能像人类理解英语那样理解。计算机不理解数学、象棋或人类的反叛,就像时钟不理解午餐时间一样。计算机只是一个接一个地执行指令。但这些指令可以模仿复杂的行为来解决数学问题,赢得象棋比赛,或追捕人类抵抗运动的未来领导人。
理想情况下,我们需要创建的是一个 Python 函数(姑且称之为isEnglish()函数),我们可以向它传递一个字符串,如果该字符串是英文文本,则返回值为True,如果是随机的乱码,则返回值为False。让我们看看一些英文文本和一些垃圾文本,看看它们可能有什么模式:
Robots are your friends. Except for RX-686\. She will try to eat you.
ai-pey e. xrx ne augur iirl6 Rtiyt fhubE6d hrSei t8..ow eo.telyoosEs t
请注意,英文文本是由您可以在字典中找到的单词组成的,但垃圾文本不是。因为单词通常由空格分隔,所以检查消息字符串是否是英语的一种方法是在每个空格处将消息分割成更小的字符串,并检查每个子字符串是否是字典中的单词。要将消息字符串分割成子字符串,我们可以使用名为split()的 Python 字符串方法,该方法通过查找字符之间的空格来检查每个单词的开始和结束位置。(第 150 页上的split()方法对此有更详细的介绍。)然后,我们可以使用if语句将每个子串与字典中的每个单词进行比较,如下面的代码所示:
if word == 'aardvark' or word == 'abacus' or word == 'abandon' or word ==
'abandoned' or word == 'abbreviate' or word == 'abbreviation' or word ==
'abdomen' or ...
我们可以写出那样的代码,但我们可能不会,因为把它们都打出来会很乏味。幸运的是,我们可以使用英语字典文件,这是包含几乎每个英语单词的文本文件。我将为您提供一个字典文件来使用,所以我们只需要编写isEnglish()函数来检查消息中的子字符串是否在字典文件中。
不是每个单词都存在于我们的字典文件中。字典文件可能不完整;例如,它可能没有单词aardvark。也有非常好的解密,其中可能有非英语单词,如我们的英语句子示例中的RX-686。明文也可以是不同的语言,但是我们现在假设它是英语。
所以isEnglish()函数不会是万无一失的,但是如果字符串参数中的大多数单词是英语单词,那么很有可能该字符串是英语文本。用错误的密钥解密的密文解密成英文的概率非常低。
你可以从www.nostarch.com/crackingcodes下载我们将为这本书使用的字典文件(超过 45000 个单词)。字典文本文件以大写形式每行列出一个单词。打开它,你会看到这样的东西:
AARHUS
AARON
ABABA
ABACK
ABAFT
ABANDON
ABANDONED
ABANDONING
ABANDONMENT
ABANDONS
--snip--
我们的isEnglish()函数将一个解密的字符串分割成单独的子字符串,并检查每个子字符串是否作为一个单词存在于字典文件中。如果一定数量的子字符串是英语单词,我们会将该文本识别为英语。如果文本是英文的,我们很有可能用正确的密钥成功解密了密文。
detectEnglish模块的源代码
选择文件 -> 新文件,打开新文件编辑器窗口。在文件编辑器中输入以下代码,然后保存为detectEnglish.py。确保dictionary.txt和detectEnglish.py在同一个目录下,否则这段代码不会工作。按F5运行程序。
detectEnglish.py
# Detect English module
# https://www.nostarch.com/crackingcodes/ (BSD Licensed)
# To use, type this code:
# import detectEnglish
# detectEnglish.isEnglish(someString) # Returns True or False
# (There must be a "dictionary.txt" file in this directory with all
# English words in it, one word per line. You can download this from
# https://www.nostarch.com/crackingcodes/.)
UPPERLETTERS = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
LETTERS_AND_SPACE = UPPERLETTERS + UPPERLETTERS.lower() + ' \t\n'
def loadDictionary():
dictionaryFile = open('dictionary.txt')
englishWords = {}
for word in dictionaryFile.read().split('\n'):
englishWords[word] = None
dictionaryFile.close()
return englishWords
ENGLISH_WORDS = loadDictionary()
def getEnglishCount(message):
message = message.upper()
message = removeNonLetters(message)
possibleWords = message.split()
if possibleWords == []:
return 0.0 # No words at all, so return 0.0
matches = 0
for word in possibleWords:
if word in ENGLISH_WORDS:
matches += 1
return float(matches) / len(possibleWords)
def removeNonLetters(message):
lettersOnly = []
for symbol in message:
if symbol in LETTERS_AND_SPACE:
lettersOnly.append(symbol)
return ''.join(lettersOnly)
def isEnglish(message, wordPercentage=20, letterPercentage=85):
# By default, 20% of the words must exist in the dictionary file, and
# 85% of all the characters in the message must be letters or spaces
# (not punctuation or numbers).
wordsMatch = getEnglishCount(message) * 100 >= wordPercentage
numLetters = len(removeNonLetters(message))
messageLettersPercentage = float(numLetters) / len(message) * 100
lettersMatch = messageLettersPercentage >= letterPercentage
return wordsMatch and lettersMatch
detectEnglish模块的示例运行
我们将在本章中编写的detectEnglish.py程序不会自己运行。相反,其他加密程序将导入detectEnglish.py,以便它们可以调用detectEnglish.isEnglish()函数,当字符串被确定为英文时,该函数将返回True。这就是为什么我们没有给detectEnglish.py一个main()函数。detectEnglish.py中的其他函数是isEnglish()函数将调用的帮助函数。我们在这一章所做的所有工作将允许任何程序用一个import语句导入detectEnglish模块并使用其中的函数。
您还可以在交互式 shell 中使用该模块来检查单个字符串是否为英语,如下所示:
>>> import detectEnglish
>>> detectEnglish.isEnglish('Is this sentence English text?')
True
在本例中,该函数确定字符串'Is this sentence English text?'确实是英文,因此返回True。
设置指令和常量
让我们看一下detectEnglish.py程序的第一部分。前九行代码是注释,给出了如何使用这个模块的说明。
# Detect English module
# https://www.nostarch.com/crackingcodes/ (BSD Licensed)
# To use, type this code:
# import detectEnglish
# detectEnglish.isEnglish(someString) # Returns True or False
# (There must be a "dictionary.txt" file in this directory with all
# English words in it, one word per line. You can download this from
# https://www.nostarch.com/crackingcodes/.)
UPPERLETTERS = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
LETTERS_AND_SPACE = UPPERLETTERS + UPPERLETTERS.lower() + ' \t\n'
前九行代码是注释,给出了如何使用这个模块的说明。他们提醒用户,除非名为dictionary.txt的文件与detectEnglish.py在同一个目录下,否则这个模块不会工作。
第 10 行和第 11 行将一些变量设置为常量,它们都是大写的。正如你在第 5 章中所学的,常量是变量,它们的值一旦设定就永远不能改变。UPPERLETTERS是一个包含 26 个大写字母的常量,我们设置它是为了方便和节省键入时间。我们使用UPPERLETTERS常量来设置LETTERS_AND_SPACE,它包含字母表中所有的大小写字母以及空格字符、制表符和换行符。我们没有输入所有的大写和小写字母,而是将UPPERLETTERS.lower()返回的小写字母和额外的非字母字符与UPPERLETTERS连接起来。制表符和换行符用转义符\t和\n表示。
字典数据类型
在我们继续剩余的detectEnglish.py代码之前,您需要了解更多关于字典数据类型的知识,以理解如何将文件中的文本转换成字符串值。字典数据类型(不要与字典文件混淆)存储值,它可以像列表一样包含多个其他值。在列表中,我们使用整数索引来检索列表中的项目,例如spam[42]。但是对于字典值中的每一项,我们使用一个键来检索值。虽然我们只能使用整数从列表中检索条目,但是字典值中的键可以是整数或字符串,比如spam['hello']或spam[42]。字典让我们比列表更灵活地组织程序数据,并且不以任何特定的顺序存储项目。字典不像列表那样使用方括号,而是使用大括号。比如一个空字典长这样{}。
注
请记住,字典文件和字典值是完全不同的概念,只是名称相似而已。一个 Python 字典值可以包含多个其他值。字典文件是包含英语单词的文本文件。
字典的条目被输入为键值对,其中键和值由冒号分隔。多个键值对用逗号分隔。要从字典中检索值,请使用方括号,方括号之间有关键字,类似于使用列表进行索引时的情况。要尝试使用键从字典中检索值,请在交互式 shell 中输入以下内容:
>>> spam = {'key1': 'This is a value', 'key2': 42}
>>> spam['key1']
'This is a value'
首先,我们用两个键值对建立了一个名为spam的字典。然后我们访问与'key1'字符串键相关的值,这是另一个字符串。与列表一样,您可以在字典中存储所有类型的数据。
注意,和列表一样,变量不存储字典值;相反,它们存储对字典的引用。以下示例代码显示了引用同一字典的两个变量:
>>> spam = {'hello': 42}
>>> eggs = spam
>>> eggs['hello'] = 99
>>> eggs
{'hello': 99}
>>> spam
{'hello': 99}
第一行代码建立了另一个名为spam的字典,这次只有一个键值对。您可以看到它存储了一个与'hello'字符串键相关联的整数值42。第二行将字典键值对分配给另一个名为eggs的变量。然后,您可以使用eggs将与'hello'字符串键相关联的原始字典值更改为99。现在,eggs和spam这两个变量应该用更新后的值返回相同的字典键值对。
字典和列表的区别
字典在许多方面类似于列表,但也有一些重要的区别:
-
字典项目没有任何顺序。字典中没有列表中的第一项或最后一项。
-
不能用
+运算符连接字典。如果要添加新项目,请使用新键索引。比如foo['a new key'] = 'a string'。 -
列表只有范围从
0到列表长度减一的整数索引值,但是字典可以使用任何键。如果您在变量spam中存储了一个字典,那么您可以在spam[3]中存储一个值,而不需要spam[0]、spam[1]或spam[2]的值。
增加或改变字典中的条目
还可以通过使用字典键作为索引来添加或更改字典中的值。在交互式 shell 中输入以下内容,查看其工作原理:
>>> spam = {42: 'hello'}
>>> print(spam[42])
hello
>>> spam[42] = 'goodbye'
>>> print(spam[42])
goodbye
该字典有一个与关键字42相关联的现有字典字符串值'hello'。我们可以使用spam[42] = 'goodbye'给那个键重新赋值一个新的字符串值'goodbye'。为现有字典键分配新值会覆盖与该键关联的原始值。例如,当我们试图用关键字42访问字典时,我们会得到与之相关的新值。
正如列表可以包含其他列表一样,字典也可以包含其他字典(或列表)。要查看示例,请在交互式 shell 中输入以下内容:
>>> foo = {'fizz': {'name': 'Al', 'age': 144}, 'moo':['a', 'brown', 'cow']}
>>> foo['fizz']
{'age': 144, 'name': 'Al'}
>>> foo['fizz']['name']
'Al'
>>> foo['moo']
['a', 'brown', 'cow']
>>> foo['moo'][1]
'brown'
这个示例代码展示了一个字典(名为foo),它包含两个键'fizz'和'moo',每个键对应一个不同的值和数据类型。'fizz'键保存另一个字典,'键保存一个列表。(请记住,字典值不会按顺序排列它们的项目。这就是为什么foo['fizz']以不同于您输入的顺序显示键值对。)要从嵌套在另一个字典中的字典中检索一个值,首先要使用方括号指定想要访问的更大数据集的键,在本例中是'fizz'。然后再次使用方括号,输入与想要检索的嵌套字符串值'Al'相对应的键'name'。
对字典使用len()函数
函数显示了列表中的项目数或字符串中的字符数。它还可以显示字典中条目的数量。在交互式 shell 中输入以下代码,看看如何使用len()函数来计算字典中的条目:
>>> spam = {}
>>> len(spam)
0
>>> spam['name'] = 'Al'
>>> spam['pet'] = 'Zophie the cat'
>>> spam['age'] = 89
>>> len(spam)
3
这个例子的第一行显示了一个名为spam的空字典。len()函数正确显示这个空字典的长度是0。然而,在您将以下三个值'Al'、'Zophie the cat'和89引入字典后,len()函数现在为您刚刚分配给变量的三个键值对返回3。
对字典使用in运算符
您可以使用in操作符来查看字典中是否存在某个键。重要的是要记住in操作符检查的是键,而不是值。要查看该操作符的运行情况,请在交互式 shell 中输入以下内容:
>>> eggs = {'foo': 'milk', 'bar': 'bread'}
>>> 'foo' in eggs
True
>>> 'milk' in eggs
False
>>> 'blah blah blah' in eggs
False
>>> 'blah blah blah' not in eggs
True
我们用一些键值对建立了一个名为eggs的字典,然后使用in操作符检查字典中存在哪些键。密钥'foo'是eggs中的一个密钥,所以True被返回。鉴于'milk'返回False是因为它是一个值,而不是一个键,'blah blah blah'的计算结果是False,因为这个字典中不存在这样的条目。not in操作符也处理字典值,这可以在最后一个命令中看到。
使用字典查找条目比使用列表更快
想象一下交互式 shell 中的以下列表和字典值:
>>> listVal = ['spam', 'eggs', 'bacon']
>>> dictionaryVal = {'spam':0, 'eggs':0, 'bacon':0}
Python 对dictionaryVal中的表达式'bacon'求值的速度比listVal中的'bacon'快一点。这是因为对于列表,Python 必须从列表的开头开始,然后按顺序遍历每个项目,直到找到搜索项目。如果列表非常大,Python 必须搜索大量条目,这个过程会花费很多时间。
但是字典,也称为哈希表,直接翻译计算机内存中存储键值对的位置,这就是为什么字典的条目没有顺序。不管字典有多大,查找任何条目总是要花同样多的时间。
当搜索短列表和字典时,这种速度上的差异几乎不明显。但是我们的detectEnglish模块将会有成千上万的条目,当isEnglish()函数被调用时,我们将在代码中使用的表达式word in ENGLISH_WORDS将会被多次求值。在处理大量项目时,使用字典值可以加快这个过程。
对字典使用for循环
您还可以使用for循环遍历字典中的键,就像您可以遍历列表中的条目一样。在交互式 shell 中输入以下内容:
>>> spam = {'name': 'Al', 'age': 99}
>>> for k in spam:
... print(k, spam[k])
...
Age 99
name Al
要使用for语句迭代字典中的键,从for关键字开始。设置变量k,使用in关键字指定要循环遍历spam,并以冒号结束语句。如您所见,输入print(k, spam[k])将返回字典中的每个键及其对应的值。
实现字典文件
现在让我们返回到detectEnglish.py并设置字典文件。字典文件位于用户的硬盘上,但是除非我们将该文件中的文本作为字符串值加载,否则我们的 Python 代码无法使用它。我们将创建一个loadDictionary()助手函数来完成这项工作:
def loadDictionary():
dictionaryFile = open('dictionary.txt')
englishWords = {}
首先,我们通过调用open()并传递文件名的字符串'dictionary.txt'来获取字典的file对象。然后我们将字典变量命名为englishWords,并将其设置为一个空字典。
我们将把字典文件(存储英语单词的文件)中的所有单词存储在字典值(Python 数据类型)中。相似的名字很不幸,但两者完全不同。即使我们可以使用一个列表来存储字典文件中每个单词的字符串值,我们还是使用字典来代替,因为in操作符在字典上比在列表上工作得更快。
接下来,您将了解到split()字符串方法,我们将使用它将字典文件分割成子字符串。
split()字符串方法
split()字符串方法接受一个字符串,并通过在每个空格处分割传递的字符串来返回几个字符串的列表。要查看如何工作的示例,请在交互式 shell 中输入以下内容:
>>> 'My very energetic mother just served us Nutella.'.split()
['My', 'very', 'energetic', 'mother', 'just', 'served', 'us', 'Nutella.']
结果是一个包含八个字符串的列表,原始字符串中的每个单词对应一个字符串。即使列表中有多个空格,也会从列表项中删除空格。您可以向split()方法传递一个可选参数,告诉它在不同的字符串而不是空格上进行分割。在交互式 shell 中输入以下内容:
>>> 'helloXXXworldXXXhowXXXareXXyou?'.split('XXX')
['hello', 'world', 'how', 'areXXyou?']
注意,该字符串没有任何空格。使用split('XXX')在'XXX'出现的地方分割原始字符串,产生一个四个字符串的列表。字符串的最后一部分'areXXyou?'没有被拆分,因为'XX'与'XXX'不同。
将字典文件拆分成单个单词
让我们回到我们在detectEnglish.py中的源代码,看看我们如何在字典文件中分割字符串并将每个单词存储在一个键中。
for word in dictionaryFile.read().split('\n'):
englishWords[word] = None
让我们分解第 16 行。dictionaryFile变量存储打开文件的文件对象。dictionaryFile.read()方法调用读取整个文件,并将其作为一个大字符串值返回。然后,我们在这个长字符串上调用split()方法,并在换行符上拆分。因为字典文件每行有一个单词,所以按换行符拆分会返回一个由字典文件中的每个单词组成的列表值。
行首的for循环遍历每个单词,将每个单词存储在一个键中。但是我们不需要与键相关联的值,因为我们使用的是字典数据类型,所以我们将只存储每个键的None值。
None是一种值,可以分配给变量来表示缺少值。布尔数据类型只有两个值,而NoneType只有一个值None。它总是不带引号,大写字母N。
例如,假设您有一个名为quizAnswer的变量,它保存了用户对一个是非题的回答。如果用户跳过一个问题而没有回答,那么将quizAnswer赋给None作为默认值,而不是赋给True或False是最有意义的。否则,它可能看起来像用户回答了问题,而他们没有。同样,函数调用通过到达函数的末尾而不是从一个求值为None的return语句退出,因为它们不返回任何东西。
第 17 行使用被迭代的单词作为englishWords中的键,并将None存储为该键的值。
返回字典数据
在for循环结束后,englishWords字典中应该有数万个键。此时,我们关闭文件对象,因为我们已经完成了对它的读取,然后返回englishWords:
dictionaryFile.close()
return englishWords
然后我们调用loadDictionary()并将它返回的字典值存储在一个名为ENGLISH_WORDS的变量中:
ENGLISH_WORDS = loadDictionary()
我们想在detectEnglish模块中的其余代码之前调用loadDictionary(),但是 Python 必须在我们调用函数之前执行loadDictionary()的def语句。这就是为什么ENGLISH_WORDS的赋值在loadDictionary()函数代码之后的原因。
统计消息中的英文单词数
程序代码的第 24 行到第 27 行定义了getEnglishCount()函数,该函数接受一个字符串参数并返回一个浮点值,该值指示识别的英语单词与总单词的比率。我们将把比率表示为0.0和1.0之间的一个值。值0.0意味着message中没有单词是英语单词,而1.0意味着message中的所有单词都是英语单词。最有可能的是,getEnglishCount()将返回一个介于0.0和1.0之间的浮点值。isEnglish()函数使用该返回值来确定是求值为True还是False。
def getEnglishCount(message):
message = message.upper()
message = removeNonLetters(message)
possibleWords = message.split()
为了编写这个函数,首先我们从message中的字符串创建一个单个单词字符串的列表。第 25 行将字符串转换成大写字母。然后第 26 行通过调用removeNonLetters()删除字符串中的非字母字符,比如数字和标点符号。(稍后您将看到这个函数是如何工作的。)最后,第 27 行的split()方法将字符串拆分成单个单词,并将它们存储在一个名为possibleWords的变量中。
例如,如果字符串' Hello there. How are you?'在调用getEnglishCount()之后被传递,那么在第 25 到 27 行执行之后存储在possibleWords中的值将是['HELLO', 'THERE', 'HOW', 'ARE', 'YOU']。
如果message中的字符串是由整数组成的,比如'12345',那么对removeNonLetters()的调用将返回一个空字符串,而对split()的调用将返回一个空列表。在程序中,空列表相当于英语中的零单词,这可能会导致被零除的错误。
除零错误
为了返回一个在0.0和1.0之间的浮点值,我们将possibleWords中被识别为英语的单词数除以possibleWords中的总单词数。尽管这很简单,但我们需要确保possibleWords不是一个空列表。如果possibleWords为空,则表示possibleWords中的总字数为0。
因为在数学中被零除没有意义,所以在 Python 中被零除会导致被零除的错误。要查看此错误的示例,请在交互式 shell 中输入以下内容:
>>> 42 / 0
Traceback (most recent call last):
File "<pyshell#0>", line 1, in <module>
42 / 0
ZeroDivisionError: division by zero
您可以看到,42除以0得到一个ZeroDivisionError和一条解释错误的消息。为了避免被零除的错误,我们需要确保possibleWords列表不为空。
第 29 行检查possibleWords是否为空列表,如果列表中没有单词,第 30 行返回0.0。
if possibleWords == []:
return 0.0 # No words at all, so return 0.0
这种检查是必要的,以避免被零除的错误。
统计英语单词匹配数
为了得出英语单词与总单词的比率,我们将把possibleWords中被识别为英语的单词数除以possibleWords中的总单词数。为此,我们需要统计possibleWords中识别的英语单词的数量。第 32 行将变量matches设置为0。第 33 行使用for循环迭代possibleWords中的每个单词,并检查该单词是否存在于ENGLISH_WORDS字典中。如果该单词存在于字典中,则第 35 行的matches中的值递增。
matches = 0
for word in possibleWords:
if word in ENGLISH_WORDS:
matches += 1
在for循环完成后,字符串中的英文单词数存储在matches变量中。请记住,我们依赖字典文件的准确性和完整性来使detectEnglish模块正确工作。如果一个单词不在字典文本文件中,即使它是一个真实的单词,也不会被算作英语。相反,如果一个单词在字典中拼写错误,非英语单词可能会意外地被算作真实单词。
现在,possibleWords中被识别为英语的单词数和possibleWords中的总单词数由整数表示。要通过将这两个整数相除来返回一个位于0.0和1.0之间的浮点值,我们需要将其中一个转换成浮点值。
float()、int()和str()函数和整数除法
让我们看看如何将一个整数转换成一个浮点数,因为我们需要除以的两个值都是整数。Python 3 总是执行常规除法,不管值类型如何,而 Python 2 在除法运算中两个值都是整数时执行整数除法。因为用户可能会使用 Python 2 来导入detectEnglish.py,所以我们需要向float()传递至少一个整数变量,以确保在进行除法运算时返回一个浮点数。这样做可以确保无论使用哪个版本的 Python,都将执行常规除法。这是一个让代码向后兼容以前版本的例子。
虽然我们不会在这个程序中使用它们,但是让我们回顾一下将值转换成其他数据类型的其他函数。int()函数返回其参数的整数版本,而str()函数返回一个字符串。要查看这些函数是如何工作的,请在交互式 shell 中输入以下内容:
>>> float(42)
42.0
>>> int(42.0)
42
>>> int(42.7)
42
>>> int('42')
42
>>> str(42)
'42'
>>> str(42.7)
'42.7'
可以看到float()函数将整数42变成了浮点值。int()函数可以通过截断浮点数的十进制值将浮点数42.0和42.7转换成整数,也可以将字符串值'42'转换成整数。str()函数将数值转换成字符串值。如果您需要一个值的等价物是不同的数据类型,这些函数会很有帮助。
查找消息中英文单词的比例
为了求出英语单词占总单词的比率,我们用找到的matches的数量除以possibleWords的总数。第 36 行使用/操作符将这两个数相除:
return float(matches) / len(possibleWords)
在我们将整数matches传递给float()函数之后,它返回该数字的浮点版本,我们将该数字除以possibleWords列表的长度。
return float(matches) / len(possibleWords)导致被零除错误的唯一方式是如果len(possibleWords)求值为0。只有当possibleWords是一个空列表时,才有可能。然而,第 29 行和第 30 行专门检查这种情况,如果列表为空,则返回0.0。如果possibleWords被设置为空列表,程序执行将永远不会超过第 30 行,所以我们可以确信第 36 行不会导致ZeroDivisionError。
删除非字母字符
某些字符,如数字或标点符号,会导致我们的单词检测失败,因为单词看起来不会与它们在字典文件中的拼写完全相同。例如,如果message中的最后一个单词是'you.',并且我们没有删除字符串末尾的句点,那么它就不会被算作一个英语单词,因为'you'在字典文件中不会用句点拼写。为了避免这种误解,需要删除数字和标点符号。
前面解释的getEnglishCount()函数调用字符串上的函数removeNonLetters()来删除其中的任何数字和标点符号。
def removeNonLetters(message):
lettersOnly = []
for symbol in message:
if symbol in LETTERS_AND_SPACE:
lettersOnly.append(symbol)
第 40 行创建一个名为lettersOnly的空白列表,第 41 行使用一个for循环遍历message参数中的每个字符。接下来,for循环检查字符串LETTERS_AND_SPACE中是否存在该字符。如果字符是数字或标点符号,它不会存在于LETTERS_AND_SPACE字符串中,也不会添加到列表中。如果字符串中确实存在这个字符,那么使用append()方法将它添加到列表的末尾,我们接下来会看到这个方法。
append()列表法
当我们把一个值加到一个列表的末尾时,我们说我们是在把这个值追加到列表中。Python 中经常对列表这样做,以至于有一个append()列表方法将一个参数附加到列表的末尾。在交互式 shell 中输入以下内容:
>>> eggs = []
>>> eggs.append('hovercraft')
>>> eggs
['hovercraft']
>>> eggs.append('eels')
>>> eggs
['hovercraft', 'eels']
创建一个名为eggs的空列表后,我们可以输入eggs.append ('hovercraft')将字符串值'hovercraft'添加到这个列表中。然后当我们输入eggs时,它返回这个列表中存储的唯一值,就是' hovercraft '。如果您再次使用append()将'eels'添加到列表的末尾,eggs现在返回'hovercraft'后跟'eels'。类似地,我们可以使用append()列表方法将项目添加到我们之前在代码中创建的lettersOnly列表中。这就是第 43 行的lettersOnly.append(symbol)在for循环中的作用。
创建字母字符串
在完成for循环后,lettersOnly应该是来自原始message字符串的每个字母和空格字符的列表。因为单个字符串的列表对于查找英语单词没有用,所以第 44 行将lettersOnly列表中的字符串连接成一个字符串并返回它:
return ''.join(lettersOnly)
为了将lettersOnly中的列表元素连接成一个大字符串,我们在空白字符串''上调用join()字符串方法。这将连接lettersOnly中的字符串,它们之间有一个空白字符串。然后这个字符串值作为removeNonLetters()函数的返回值返回。
检测英文单词
当用错误的密钥解密消息时,它通常会产生比典型的英语消息中多得多的非字母和非空格字符。此外,它产生的单词通常是随机的,在英语字典中是找不到的。isEnglish()函数可以在给定的字符串中检查这两个问题。
def isEnglish(message, wordPercentage=20, letterPercentage=85):
# By default, 20% of the words must exist in the dictionary file, and
# 85% of all the characters in the message must be letters or spaces
# (not punctuation or numbers).
第 47 行设置了isEnglish()函数来接受一个字符串参数,当字符串是英文文本时返回一个布尔值True,否则返回False。该函数有三个参数:message、wordPercentage=20和letterPercentage=85。第一个参数包含要检查的字符串,第二个和第三个参数设置单词和字母的默认百分比,字符串必须包含这些百分比才能被确认为英语。(百分比是一个介于 0 和 100 之间的数字,表示某样东西与这些东西的总数成比例。)我们将在下面几节中探讨如何使用默认参数和计算百分比。
使用默认参数
有时一个函数在被调用时几乎总是有相同的值传递给它。您可以在函数的def语句中指定一个默认参数,而不是在每个函数调用中都包含这些参数。
第 47 行的def语句有三个参数,分别为wordPercentage和letterPercentage提供了默认参数 20 和 85。可以用一到三个参数调用isEnglish()函数。如果没有为wordPercentage或letterPercentage传递参数,那么分配给这些参数的值将是它们的默认参数。
默认参数定义了message字符串中需要由真实英文单词组成的百分比,以便isEnglish()确定message是英文字符串,以及message中需要由字母或空格而不是数字或标点符号组成的百分比。例如,如果调用isEnglish()时只有一个参数,默认参数用于wordPercentage(整数20)和letterPercentage(整数85)参数,这意味着字符串的 20% 需要由英语单词组成,85% 需要由字母组成。这些百分比在大多数情况下适用于检测英语,但是在特定情况下,当isEnglish()需要更宽松或更严格的阈值时,您可能想要尝试其他参数组合。在这些情况下,程序可以只传递参数wordPercentage和letterPercentage,而不使用默认参数。表 11-1 显示了对isEnglish()的函数调用以及它们的等价关系。
表 11-1: 有无默认参数的函数调用
| 函数调用 | 相当于 |
|---|---|
isEnglish('Hello') | isEnglish('Hello', 20, 85) |
isEnglish('Hello', 50) | isEnglish('Hello', 50, 85) |
isEnglish('Hello', 50, 60) | isEnglish('Hello', 50, 60) |
isEnglish('Hello', letterPercentage=60) | isEnglish('Hello', 20, 60) |
例如,表 11-1 中的第三个例子表明,当调用函数时指定了第二个和第三个参数,程序将使用这些参数,而不是默认参数。
计算百分比
一旦我们知道我们的程序将使用的百分比,我们将需要计算message字符串的百分比。例如,字符串值'Hello cat MOOSE fsdkl ewpin'有五个“单词”,但只有三个是英语。要计算英语单词在该字符串中所占的百分比,请将英语单词数除以总单词数,然后将结果乘以 100。'Hello cat MOOSE fsdkl ewpin'中英文单词的百分比是3 / 5 * 100,百分之六十。表 11-2 显示了一些计算百分比的例子。
表 11-2: 计算英语单词的百分比
| 英文单词数量 | 总字数 | 英语单词比例 | × 100 | = | 百分比 |
|---|---|---|---|---|---|
| 3 | 5 | 0.6 | × 100 | = | 60 |
| 6 | 10 | 0.6 | × 100 | = | 60 |
| 300 | 500 | 0.6 | × 100 | = | 60 |
| 32 | 87 | 0.3678 | × 100 | = | 36.78 |
| 87 | 87 | 1 | × 100 | = | 100 |
| 0 | 10 | 0 | × 100 | = | 0 |
该百分比将始终介于 0%(表示没有单词是英语)和 100%(表示所有单词都是英语)之间。如果字典文件中至少有 20% 的单词,并且字符串中有 85% 的字符是字母或空格,那么我们的isEnglish()函数会将字符串视为英语。这意味着,即使字典文件不完善,或者邮件中的某些单词不是我们定义的英语单词,邮件仍会被检测为英语。
第 51 行通过将message传递给getEnglishCount()来计算message中已识别英语单词的百分比,后者执行除法并返回一个介于0.0和1.0之间的浮点数:
wordsMatch = getEnglishCount(message) * 100 >= wordPercentage
要从这个浮点数中得到一个百分比,用它乘以100。如果结果数大于或等于wordPercentage参数,True被存储在wordsMatch中。(回想一下,>=比较运算符将表达式计算为布尔值。)否则,False存储在wordsMatch中。
第 52 到 54 行通过将字母字符数除以message中的字符总数来计算字母字符在message字符串中的百分比。
numLetters = len(removeNonLetters(message))
messageLettersPercentage = float(numLetters) / len(message) * 100
lettersMatch = messageLettersPercentage >= letterPercentage
在代码的前面,我们编写了removeNonLetters()函数来查找字符串中的所有字母和空格字符,所以我们可以重用它。第 52 行调用removeNonLetters(message)来获取一个字符串,该字符串只包含message中的字母和空格字符。将这个字符串传递给len()应该会返回message中字母和空格字符的总数,我们将它作为一个整数存储在numLetters变量中。
第 53 行通过获取numLetters中整数的浮点版本并除以len(message)来确定字母的百分比。len(message)的返回值将是message中的字符总数。正如前面讨论的,调用float()是为了确保第 53 行执行常规除法而不是整数除法,以防导入detectEnglish模块的程序员运行 Python 2。
第 54 行检查messageLettersPercentage中的百分比是否大于或等于letterPercentage参数。该表达式计算出一个存储在lettersMatch中的布尔值。
只有当wordsMatch和lettersMatch变量都包含True时,我们才希望isEnglish()返回True。第 55 行使用and操作符将这些值组合成一个表达式:
return wordsMatch and lettersMatch
如果wordsMatch和lettersMatch变量都是True,isEnglish()会声明message是英语并返回True。否则,isEnglish()将返回False。
总结
换位文件密码是对凯撒密码的改进,因为它可以有数百或数千个可能的消息密钥,而不是只有 26 个不同的密钥。尽管计算机可以用成千上万的潜在密钥解密一条消息,但我们需要编写代码来确定解密后的字符串是否是有效的英语,从而确定原始消息。
在这一章中,我们创建了一个英语检测程序,它使用一个字典文本文件来创建字典数据类型。字典数据类型非常有用,因为它可以像列表一样包含多个值。然而,与列表不同的是,您可以使用字符串值而不仅仅是整数作为键来索引字典中的值。你可以用列表完成的大多数任务也可以用字典来完成,比如把它传递给len()或者对它使用in和not in操作符。然而,in操作符在一个非常大的字典值上的执行速度要比在一个非常大的列表上快得多。这被证明对我们特别有用,因为我们的字典数据包含成千上万的值,我们需要快速筛选。
本章还介绍了split()方法,它可以将字符串拆分成一系列字符串,还介绍了NoneType数据类型,它只有一个值:None。该值对于表示缺少值很有用。
您学习了如何在使用/运算符时避免被零除的错误;使用int()、float()和str()函数将值转换成其他数据类型;并使用append()列表方法在列表末尾添加一个值。
定义函数时,可以给一些参数指定默认参数。如果在调用函数时没有为这些参数传递参数,程序将使用默认的参数值,这在您的程序中可能是一个有用的快捷方式。在第 12 章中,你将学会使用英文检测码破解换位密码!
练习题
练习题的答案可以在本书的网站www.nostarch.com/crackingcodes找到。
-
下面的代码打印了什么?
spam = {'name': 'Al'} print(spam['name']) -
这段代码打印了什么?
spam = {'eggs': 'bacon'} print('bacon' in spam) -
什么
for循环代码会打印下面的spam字典中的值?spam = {'name': 'Zophie', 'species':'cat', 'age':8} -
下面一行打印了什么?
print('Hello, world!'.split()) -
下面的代码会输出什么?
def spam(eggs=42): print(eggs) spam() spam('Hello') -
这句话中有效英语单词的百分比是多少?
"Whether it's flobulllar in the mind to quarfalog the slings and arrows of outrageous guuuuuuuuur."
十二、破解换位密码
原文:https://inventwithpython.com/cracking/chapter12.html
“RSA 的发明者之一 Ron Rivest 认为限制加密技术是鲁莽的:‘仅仅因为一些罪犯可能会利用它来为自己谋利,就不加选择地压制一项技术是糟糕的政策。’”
——西蒙·辛格,《密码之书》

在这一章中,我们将使用暴力破解换位密码。在可能与换位密码相关联的数千个密钥中,正确的密钥应该是唯一能够产生清晰的英语的密钥。使用我们在第 11 章中编写的detectEnglish.py模块,我们的换位密码破解程序将帮助我们找到正确的密钥。
本章涵盖的主题
-
带三重引号的多行字符串
-
strip()字符串方法
换位密码破解程序的源代码
选择文件 -> 新文件,打开新文件编辑器窗口。在文件编辑器中输入以下代码,保存为transpositionHacker.py。与之前的程序一样,确保pyperclip.py模块、transpositionHacker.py模块(第 8 章)、以及detectEnglish.py模块和dictionary.txt文件(第 11 章)与transpositionHacker.py文件在同一个目录下。然后按F5运行程序。
换位
黑客. py
# Transposition Cipher Hacker
# https://www.nostarch.com/crackingcodes/ (BSD Licensed)
import pyperclip, detectEnglish, transpositionDecrypt
def main():
# You might want to copy & paste this text from the source code at
# https://www.nostarch.com/crackingcodes/:
myMessage = """AaKoosoeDe5 b5sn ma reno ora'lhlrrceey e enlh
na indeit n uhoretrm au ieu v er Ne2 gmanw,forwnlbsya apor tE.no
euarisfatt e mealefedhsppmgAnlnoe(c -or)alat r lw o eb nglom,Ain
one dtes ilhetcdba. t tg eturmudg,tfl1e1 v nitiaicynhrCsaemie-sp
ncgHt nie cetrgmnoa yc r,ieaa toesa- e a0m82e1w shcnth ekh
gaecnpeutaaieetgn iodhso d ro hAe snrsfcegrt NCsLc b17m8aEheideikfr
aBercaeu thllnrshicwsg etriebruaisss d iorr."""
hackedMessage = hackTransposition(myMessage)
if hackedMessage == None:
print('Failed to hack encryption.')
else:
print('Copying hacked message to clipboard:')
print(hackedMessage)
pyperclip.copy(hackedMessage)
def hackTransposition(message):
print('Hacking...')
# Python programs can be stopped at any time by pressing
# Ctrl-C (on Windows) or Ctrl-D (on macOS and Linux):
print('(Press Ctrl-C (on Windows) or Ctrl-D (on macOS and Linux) to
quit at any time.)')
# Brute-force by looping through every possible key:
for key in range(1, len(message)):
print('Trying key #%s...' % (key))
decryptedText = transpositionDecrypt.decryptMessage(key, message)
if detectEnglish.isEnglish(decryptedText):
# Ask user if this is the correct decryption:
print()
print('Possible encryption hack:')
print('Key %s: %s' % (key, decryptedText[:100]))
print()
print('Enter D if done, anything else to continue hacking:')
response = input('> ')
if response.strip().upper().startswith('D'):
return decryptedText
return None
if __name__ == '__main__':
main()
换位密码破解程序的示例运行
当您运行transpositionHacker.py程序时,输出应该是这样的:
Hacking...
(Press Ctrl-C (on Windows) or Ctrl-D (on macOS and Linux) to quit at any time.)
Trying key #1...
Trying key #2...
Trying key #3...
Trying key #4...
Trying key #5...
Trying key #6...
Possible encryption hack:
Key 6: Augusta Ada King-Noel, Countess of Lovelace (10 December 1815 - 27
November 1852) was an English mat
Enter D if done, anything else to continue hacking:
> D
Copying hacked message to clipboard:
Augusta Ada King-Noel, Countess of Lovelace (10 December 1815 - 27 November
1852) was an English mathematician and writer, chiefly known for her work on
Charles Babbage's early mechanical general-purpose computer, the Analytical
Engine. Her notes on the engine include what is recognised as the first
algorithm intended to be carried out by a machine. As a result, she is often
regarded as the first computer programmer.
在尝试了密钥#6 之后,程序返回解密消息的一个片段,让用户确认它找到了正确的密钥。在这个例子中,消息看起来很有希望。当用户通过输入D确认解密正确时,程序返回完整的破解消息。你可以看到这是一篇关于阿达·洛芙莱斯的传记。(她在 1842 年和 1843 年设计的计算伯努利数的算法使她成为第一个计算机程序员。)如果解密是误报,用户可以按其他任何密钥,程序会继续尝试其他密钥。
再次运行程序,按D以外的任何键跳过正确的解密。该程序认为它没有找到正确的解密,并通过其他可能的密钥继续其暴力破解方法。
--snip--
Trying key #417...
Trying key #418...
Trying key #419...
Failed to hack encryption.
最终,程序运行所有可能的密钥,然后放弃,通知用户它无法破解密文。
让我们仔细看看源代码,看看程序是如何工作的。
导入模块
代码的前几行告诉用户这个程序将做什么。第 4 行导入了几个我们在前面章节中写过或见过的模块: pyperclip.py、detectEnglish.py和transpositondecrypt.py。
# Transposition Cipher Hacker
# https://www.nostarch.com/crackingcodes/ (BSD Licensed)
import pyperclip, detectEnglish, transpositionDecrypt
换位密码破解程序包含大约 50 行代码,相当短,因为它的大部分存在于我们用作模块的其他程序中。
带三重引号的多行字符串
变量存储我们试图破解的密文。第 9 行存储一个以三重引号开始和结束的字符串值。注意这是一个很长的字符串。
def main():
# You might want to copy & paste this text from the source code at
# https://www.nostarch.com/crackingcodes/:
myMessage = """AaKoosoeDe5 b5sn ma reno ora'lhlrrceey e enlh
na indeit n uhoretrm au ieu v er Ne2 gmanw,forwnlbsya apor tE.no
euarisfatt e mealefedhsppmgAnlnoe(c -or)alat r lw o eb nglom,Ain
one dtes ilhetcdba. t tg eturmudg,tfl1e1 v nitiaicynhrCsaemie-sp
ncgHt nie cetrgmnoa yc r,ieaa toesa- e a0m82e1w shcnth ekh
gaecnpeutaaieetgn iodhso d ro hAe snrsfcegrt NCsLc b17m8aEheideikfr
aBercaeu thllnrshicwsg etriebruaisss d iorr."""
三重引号字符串也称为多行字符串,因为它们跨越多行,并且其中可以包含换行符。多行字符串对于将大字符串放入程序的源代码是有用的,因为单引号和双引号不需要在其中转义。要查看多行字符串的示例,请在交互式 shell 中输入以下内容:
>>> spam = """Dear Alice,
Why did you dress up my hamster in doll clothing?
I look at Mr. Fuzz and think, "I know this was Alice's doing."
Sincerely,
Brienne"""
>>> print(spam)
Dear Alice,
Why did you dress up my hamster in doll clothing?
I look at Mr. Fuzz and think, "I know this was Alice's doing."
Sincerely,
Brienne
注意,这个字符串值和我们的密文字符串一样,跨越了多行。在开始的三重引号之后的所有内容都将被解释为字符串的一部分,直到程序到达结束它的三重引号。您可以使用三个双引号字符或三个单引号字符来创建多行字符串。
显示破解消息的结果
密文破解代码存在于hackTransposition()函数中,它在第 11 行被调用,我们将在第 21 行定义它。这个函数接受一个字符串参数:我们试图破解的加密的密文消息。如果该函数能够破解密文,它将返回一串解密后的文本。否则,它返回None值。
hackedMessage = hackTransposition(myMessage)
if hackedMessage == None:
print('Failed to hack encryption.')
else:
print('Copying hacked message to clipboard:')
print(hackedMessage)
pyperclip.copy(hackedMessage)
第 11 行调用hackTransposition()函数,如果尝试成功则返回被攻击的消息,如果尝试不成功则返回None值,并将返回值存储在hackedMessage中。
第 13 行和第 14 行告诉程序,如果函数无法破解密文,该做什么。如果None存储在hackedMessage中,程序通过打印让用户知道它无法破解消息的加密。
接下来的四行显示了如果函数能够破解密文,程序会做什么。第 17 行打印解密的消息,第 18 行将其复制到剪贴板。然而,为了让这段代码工作,我们还需要定义hackTransposition()函数,这是我们接下来要做的。
获取破解消息
hackTransposition()函数以几个print()语句开始。
def hackTransposition(message):
print('Hacking...')
# Python programs can be stopped at any time by pressing
# Ctrl-C (on Windows) or Ctrl-D (on macOS and Linux):
print('(Press Ctrl-C (on Windows) or Ctrl-D (on macOS and Linux) to
quit at any time.)')
因为该程序可以尝试许多密钥,所以该程序会显示一条消息,告诉用户破解已经开始,可能需要一段时间才能完成这个过程。第 26 行的print()调用告诉用户在任何时候按下ctrl+C(在 Windows 上)或ctrl+D(在 macOS 和 Linux 上)退出程序。实际上,您可以按下这些键来退出任何正在运行的 Python 程序。
接下来的几行通过指定换位密码的可能密钥范围,告诉程序要遍历哪些密钥:
# Brute-force by looping through every possible key:
for key in range(1, len(message)):
print('Trying key #%s...' % (key))
换位密码的可能密钥范围在 1 和消息长度之间。第 29 行的for循环用这些密钥中的每一个运行函数的黑客部分。第 30 行使用字符串插值来打印当前正在使用字符串插值进行测试的密钥,以向用户提供反馈。
使用我们已经编写的transpositionencrypt.py程序中的decryptMessage()函数,第 32 行从正在测试的当前密钥中获取解密后的输出,并将其存储在decryptedText变量中:
decryptedText = transpositionDecrypt.decryptMessage(key, message)
只有使用了正确的密钥,decryptedText中的解密输出才会是英语。否则,它将显示为垃圾文本。
然后程序将decryptedText中的字符串传递给我们在第 11 章中编写的detectEnglish .isEnglish()函数,并打印部分decryptedText、使用的key以及用户说明:
if detectEnglish.isEnglish(decryptedText):
# Ask user if this is the correct decryption:
print()
print('Possible encryption hack:')
print('Key %s: %s' % (key, decryptedText[:100]))
print()
print('Enter D if done, anything else to continue hacking:')
response = input('> ')
但是仅仅因为detectEnglish.isEnglish()返回True并将执行移到第 35 行并不意味着程序找到了正确的密钥。这可能是一个误报,意味着程序检测到一些实际上是垃圾文本的英语文本。为了确保这一点,第 38 行给出了文本的预览,因此用户可以确认该文本确实是英语。它用片decryptedText[:100]打印出decryptedText的前 100 个字符。
当第 41 行执行时,程序暂停,等待用户输入D或其他任何内容,然后将该输入作为字符串存储在response中。
strip()字符串方法
当一个程序给了用户特定的指令,但是用户没有完全按照指令去做,就会产生错误。当transpositionHacker.py程序提示用户输入D确认破解消息时,意味着程序不接受除D以外的任何输入。如果用户在D旁边输入一个额外的空格或字符,程序不会接受。让我们看看如何使用strip()字符串方法让程序接受其他输入,只要它们与D足够相似。
string 方法返回字符串的一个版本,去掉了字符串开头和结尾的所有空白字符。空白字符是空格字符、制表符和换行符。在交互式 shell 中输入以下内容,查看其工作原理:
>>> ' Hello'.strip()
'Hello'
>>> 'Hello '.strip()
'Hello'
>>> ' Hello World '.strip()
'Hello World'
在本例中,strip()删除前两个字符串开头或结尾的空格字符。如果像' Hello World '这样的字符串在字符串的开头和结尾都包含空格,那么该方法会从两边删除它们,但不会删除其他字符之间的任何空格。
strip()方法也可以有一个传递给它的字符串参数,告诉该方法从字符串的开头和结尾删除除空白以外的字符。要查看示例,请在交互式 shell 中输入以下内容:
>>> 'aaaaaHELLOaa'.strip('a')
'HELLO'
>>> 'ababaHELLObaba'.strip('ab')
'HELLO'
>>> 'abccabcbacbXYZabcXYZacccab'.strip('abc')
'XYZabcXYZ'
注意,传递字符串参数'a'和'ab'会删除出现在字符串开头或结尾的字符。然而,strip()并不删除嵌入在字符串中间的字符。正如你在第三个例子中看到的,字符串'abc'保留在'T5。
运用strip()字符串方法
让我们回到transpositionHacker.py中的源代码,看看如何在程序中应用strip()。第 43 行使用if语句设置了一个条件,为用户提供了一些输入灵活性:
if response.strip().upper().startswith('D'):
return decryptedText
如果语句的条件仅仅是response == 'D',用户必须准确地输入D才能结束程序。例如,如果用户输入'd'、' D'或'Done',条件将是False,程序将继续检查其他密钥,而不是返回被攻击的消息。
为了避免这个问题,response中的字符串通过调用strip()删除了字符串开头或结尾的空白。然后,response.strip()计算的字符串调用了upper()方法。无论用户输入'd'还是'D',从upper()返回的字符串都会大写为'D'。增加程序可以接受的输入类型的灵活性使它更容易使用。
为了让程序接受以'D'开始但却是一个完整单词的用户输入,我们使用startswith()只检查第一个字母。例如,如果用户输入' done'作为response,空白将被去除,然后字符串'done'将被传递给upper()。在upper()将整个字符串大写为'DONE'之后,该字符串被传递给startswith(),后者返回True,因为该字符串确实以子字符串'D'开头。
如果用户指出解密的字符串是正确的,第 44 行的函数hackTransposition ()返回解密的文本。
未能破解消息
第 46 行是从第 29 行开始的for循环之后的第一行:
return None
如果程序执行到这一点,这意味着程序从未到达第 44 行的return语句,如果从未为任何尝试过的密钥找到正确解密的文本,就会发生这种情况。在这种情况下,第 46 行返回None值,表示破解失败。
调用main()函数
如果这个程序是自己运行的,而不是由另一个使用hackTransposition ()函数的程序导入的,那么第 48 和 49 行调用main()函数:
if __name__ == '__main__':
main()
记住__name__变量是由 Python 设置的。如果transpositionHacker.py作为模块导入,则main()函数不会被调用。
总结
像第 6 章一样,这一章很短,因为大部分代码已经在其他程序中写好了。我们的破解程序可以通过将其他程序的函数作为模块导入来使用它们。
您了解了如何在源代码中使用三重引号来包含跨多行的字符串值。您还了解了strip()字符串方法对于删除字符串开头或结尾的空白或其他字符非常有用。
使用detectEnglish.py程序为我们节省了大量时间,我们将不得不花费大量时间来手动检查每一个解密的输出,看它是否是英语。它允许我们使用暴力破解技术破解一个有数千个可能密钥的密码。
练习题
练习题的答案可以在本书的网站www.nostarch.com/crackingcodes找到。
-
这个表达式表示什么?
' Hello world'.strip() -
哪些字符是空白字符?
-
为什么
'Hello world'.strip('o')的计算结果是一个字符串,其中仍然有O? -
为什么
'xxxHelloxxx'.strip('X')计算出的字符串中仍然有X?
十三、仿射密码的模运算模块
原文:https://inventwithpython.com/cracking/chapter13.html
“几个世纪以来,人们一直在用耳语、黑暗、信封、紧闭的门、秘密握手和信使来捍卫自己的隐私。过去的技术不允许强大的隐私,但电子技术可以。”
——埃里克·休斯,《一个赛博朋克的宣言》(1993)

在这一章,你将学习乘法密码和仿射密码。乘法密码类似于凯撒密码,但是使用乘法而不是加法来加密。仿射密码结合了乘法密码和凯撒密码,产生了更强和更可靠的加密。
但是首先,您将了解模运算和最大公约数,这是理解和实现仿射密码所需的两个数学概念。使用这些概念,我们将创建一个模块来处理绕回并为仿射密码找到有效的密钥。我们将在第 14 章中为仿射密码创建程序时使用这个模块。
本章涵盖的主题
模运算
模运算符(%)
最大公约数
多重任务
求 GCD 的欧几里德算法
乘法和仿射密码
欧几里德寻找模逆的扩展算法
模运算
模运算,或时钟运算,指的是当数字达到特定值时,它们会自动换行的数学运算。我们将使用模运算来处理仿射密码中的绕回。让我们看看它是如何工作的。
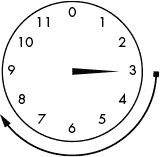
图 13-1:3 点 + 5 点 = 8 点
想象一个只有时针的钟,12 被 0 代替。(如果程序员设计时钟,第一个小时将从 0 开始。)如果现在的时间是 3 点,5 小时后会是几点?这个很容易算出来:3 + 5 = 8。再过 5 个小时就是 8 点了。想象时针从 3 开始,然后顺时针移动 5 小时,如图 13-1 所示。
如果现在是 10 点,5 小时后会是几点?加5 + 10 = 15,但是 15 点对于只显示 12 小时的时钟没有意义。要知道现在是什么时间,你要减去15 – 12 = 3,所以现在是 3 点。(通常,你会区分上午 3 点和下午 3 点,但这在模运算中无关紧要。)

图 13-2:10 点 + 5 点 = 3 点
从 10 点开始,顺时针移动时针 5 小时,仔细检查这个数学公式。它确实落在 3 上,如图 13-2 所示。
如果现在是 10 点,200 小时后会是几点?200 + 10 = 210,210 当然大于 12。因为一次完整的旋转将时针带回到它的原始位置,我们可以通过减去 12(这是一次完整的旋转)直到结果是一个小于 12 的数字来解决这个问题。210 – 12 = 198。但是 198 还是大于 12,所以我们继续减去 12,直到差小于 12;在这种情况下,最终答案将是 6。如果当前时间是 10 点,200 小时后的时间就是 6 点,如图 13-3 所示。
如果你想仔细检查10 点 + 200 点的数学,你可以在钟面上反复移动时针。当你移动时针到第 200 小时时,它应该停在 6 点。
然而,用模运算符让计算机为我们做这种模运算更容易。

图 13-3:10 点 + 200 点 = 6 点
模运算符
你可以使用模运算符,缩写为mod,来编写模表达式。在 Python 中,模运算符是百分号(%)。您可以将模运算符视为一种除法余数运算符;例如,21 ÷ 5 = 4,余数为 1,21 % 5 = 1。同样,15 % 12等于 3,就像 15 点就是 3 点一样。在交互式 shell 中输入以下内容,查看模运算符的运行情况:
>>> 21 % 5
1
>>> (10 + 200) % 12
6
>>> 10 % 10
0
>>> 20 % 10
0
就像 10 小时加上 200 个小时会在一个有 12 个小时的时钟上绕到 6 小时一样,(10 + 200) % 12会计算为6。注意,除尽的数字会模为0,比如10 % 10或者20 % 10。
稍后,我们将使用模操作符来处理仿射密码中的绕回。它也用于算法中,我们将使用它来寻找两个数字的最大公约数,这将使我们能够找到仿射密码的有效密钥。
寻找计算最大公约数的因数
因数是相乘得到一个特定数的数。考虑4 × 6 = 24。在这个等式中,4 和 6 是 24 的因数。因为一个数的因数也可以用来除以那个数而不留余数,所以因数也被称为约数。
24 这个数字还有其他一些因数:
所以 24 的因数是 1,2,3,4,6,8,12 和 24。
我们来看看 30 的因数:
30 的因数是 1、2、3、5、6、10、15 和 30。请注意,任何数字都将 1 及其自身作为其因数,因为 1 乘以一个数字等于该数字。还要注意,24 和 30 的因数列表中有 1、2、3 和 6。这些公因数中最大的是 6,所以 6 就是 24 和 30 的最大公因数,更俗称最大公约数(GCD) 。
通过可视化它们的因数,最容易找到两个数的 GCD。我们将使用古辛纳棒子来可视化因数和 GCD。古辛纳棒子由与棒子代表的数量相等的正方形组成,棒子帮助我们可视化数学运算。图 13-4 用古辛纳棒子形象化3 + 2 = 5和5 × 3 = 15。

图 13-4:用古辛纳棒子演示加法和乘法
一根 3 的棒子加到一根 2 的棒子上,等于一根 5 的棒子的长度。你甚至可以用棒子来寻找乘法问题的答案,方法是用你要相乘的数字的棒子来做一个长方形。矩形中正方形的个数就是乘法问题的答案。
如果一根 20 个单位长的棒子代表数字 20,如果这个数字的棒子可以均匀地放入 20 平方的棒子中,那么这个数字就是 20 的因数。图 13-5 显示 4 和 10 是 20 的因数,因为它们正好适合 20。

图 13-5:演示 4 和 10 是 20 的因数的古辛纳棒子
但是 6 和 7 不是 20 的因数,因为 6 平方和 7 平方的棒子不会均匀地放入 20 平方的棒子中,如图 13-6 所示。
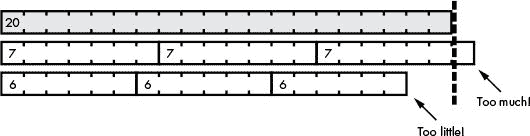
图 13-6:证明 6 和 7 不是 20 的因数的古辛纳棒子
两根棒子的 GCD,或这些棒子所代表的两个数字,是能均匀地装入两根棒子的最长的棒子,如图 13-7 所示。
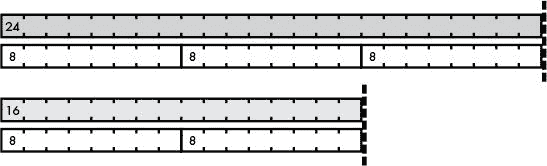
图 13-7:展示 16 和 24 的 GCD 的古辛纳棒子
在这个例子中,8 平方棒子是最长的棒子,可以均匀地放入 24 和 32。因此,8 是他们的 GCD。
现在你知道了因数和 GCD 是如何工作的,让我们用 Python 写的函数来求两个数的 GCD。
多重赋值
我们将编写的gcd()函数寻找两个数的 GCD。但是在你学习如何编码之前,让我们看看 Python 中的一个技巧,叫做多重赋值。多重赋值技巧允许你在一个赋值语句中一次给多个变量赋值。在交互式 shell 中输入以下内容,查看其工作原理:
>>> spam, eggs = 42, 'Hello'
>>> spam
42
>>> eggs
'Hello'
>>> a, b, c, d = ['Alice', 'Brienne', 'Carol', 'Danielle']
>>> a
'Alice'
>>> d
'Danielle'
您可以使用逗号分隔=操作符左侧的变量名和=操作符右侧的值。你也可以将列表中的每一个值赋给它自己的变量,只要列表中的项目数与=操作符左侧的变量数相同。如果变量的数量与值的数量不同,Python 会抛出一个错误,指出调用需要更多的变量或者值太多。
多重赋值的主要用途之一是交换两个变量的值。在交互式 shell 中输入以下内容以查看示例:
>>> spam = 'hello'
>>> eggs = 'goodbye'
>>> spam, eggs = eggs, spam
>>> spam
'goodbye'
>>> eggs
'hello'
在将' hello'赋值给spam并将'goodbye'赋值给eggs之后,我们使用多重赋值来交换这些值。让我们看看如何使用这种交换技巧来实现欧几里得算法,以找到 GCD。
求 GCD 的欧几里德算法
寻找 GCD 似乎很简单:找出你将使用的两个数字的所有因数,然后找到它们的最大公因数。但是找到更大数字的 GCD 并不容易。
欧几里德,一位生活在 2000 年前的数学家,想出了一个用模运算求两个数的 GCD 的简短算法。这里有一个用 Python 代码实现他的算法的gcd()函数,返回整数a和b的 GCD:
def gcd(a, b):
while a != 0:
a, b = b % a, a
return b
gcd()函数接受两个数字a和b,然后使用一个循环和多重赋值来寻找 GCD。图 13-8 显示了gcd()函数如何找到 24 和 32 的 GCD。
欧几里德算法的具体工作原理超出了本书的范围,但是你可以依靠这个函数返回你传递给它的两个整数的 GCD。如果从交互 shell 中调用该函数,并为参数a和b传递24和32,该函数将返回8:
>>> gcd(24, 32)
8

图 13-8:gcd()函数如何工作
不过,这个gcd()函数的最大好处是它可以轻松处理大量数据:
>>> gcd(409119243, 87780243)
6837
这个gcd()函数在为乘法和仿射密码选择有效密钥时会派上用场,您将在下一节中了解到。
了解乘法和仿射密码的工作原理
在凯撒密码中,加密和解密符号包括将它们转换成数字,加上或减去密钥,然后将新数字转换回符号。
当用乘法密码加密时,你将用密钥乘以索引。例如,如果您用密钥 3 加密了字母E,您将找到E的索引(4)并将其乘以密钥(3)以获得加密字母的索引(4 × 3 = 12),这将是m。
当乘积超过总字母数时,乘法密码有一个类似于凯撒密码的绕回问题,但现在我们可以使用模运算符来解决这个问题。例如,凯撒密码的SYMBOLS变量包含字符串'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz1234567890 !?.'。以下是SYMBOLS的首末几个字及其索引的表格:

让我们计算一下当密钥为 17 时,这些符号加密到什么。为了用密钥 17 加密符号 F,将它的索引 5 乘以 17,并将结果乘以 66 来处理 66 符号集的绕回。(5 × 17) mod 66的结果是 19,19 对应符号T,所以F用密钥 17 加密到T。以下两个字符串显示了明文中的所有字符及其对应的密文符号。第一个字符串中给定索引处的符号加密为第二个字符串中相同索引处的符号:
'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz1234567890 !?.'
'ARizCTk2EVm4GXo6IZq8Kbs0Mdu!Ofw.QhyBSj1DUl3FWn5HYp7Jar9Lct Nev?Pgx'
将此加密输出与使用凯撒密码加密时得到的输出进行比较,凯撒密码只是将明文符号转换为密文符号:
'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz1234567890 !?.'
'RSTUVWXYZabcdefghijklmnopqrstuvwxyz1234567890 !?.ABCDEFGHIJKLMNOPQ'
如您所见,密钥为 17 的乘法密码产生的密文更加随机化,也更难破解。然而,在为乘法密码选择密钥时,您需要小心。接下来我会讨论为什么。
选择有效的乘法密钥
乘法密码的密钥不能用任何数字。例如,如果您选择了密钥 11,下面是您最终得到的映射:
'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz1234567890 !?.'
'ALWhs4ALWhs4ALWhs4ALWhs4ALWhs4ALWhs4ALWhs4ALWhs4ALWhs4ALWhs4ALWhs4'
请注意,这个密钥不起作用,因为符号A、G和M都加密到同一个字母A。当您在密文中遇到A时,您不知道它解密到哪个符号。使用这个密钥,在加密字母A、N、F、S和其他字母时,您会遇到同样的问题。
在乘法密码中,密钥和符号集的大小必须互为质数。如果两个数的 GCD 为 1,则这两个数是互质。换句话说,除了 1,它们没有共同的因数。比如数字num1和num2是互质的如果gcd(num1, num2) == 1,其中num1是密钥,num2是符号集的大小。在前面的示例中,因为 11(密钥)和 66(符号集大小)的 GCD 不是 1,所以它们不是互质的,这意味着密钥 11 不能用于乘法密码。请注意,数字并不一定是质数,也可以互为质数。
使用乘法密码时,知道如何使用模运算和gcd()函数很重要。您可以使用gcd()函数来判断一对数字是否互质,您需要知道这一点来为乘法密码选择有效的密钥。
乘法密码对于一组 66 个符号只有 20 个不同的密钥,甚至比凯撒密码还少!但是,您可以将乘法密码和凯撒密码结合起来,以获得更强大的仿射密码,我接下来将对此进行解释。
用仿射密码加密
使用乘法密码的一个缺点是字母A总是映射到字母A。原因是A的数字是 0,0 乘以任何东西都永远是 0。您可以通过在乘法密码的乘法和修改完成后添加第二个密钥来执行凯撒密码加密来解决此问题。这个额外的步骤将乘法密码变为仿射密码。
仿射密码有两个密钥:密钥 A 和密钥 B。密钥 A 是用于乘以字母数字的整数。将明文乘以密钥 A 后,将密钥 B 加到乘积中。然后,您将总数减去 66,就像您在最初的凯撒密码中所做的那样。这意味着仿射密码的可能密钥是乘法密码的 66 倍。这也确保了字母 A 不会总是加密到它自己。
仿射密码的解密过程反映了加密过程;两者如图 13-9 所示。

图 13-9:仿射密码的加密和解密过程
我们使用与加密相反的操作来解密仿射密码。让我们更详细地看看解密过程和如何计算模逆。
用仿射密码解密
在凯撒密码中,你用加法加密,用减法解密。在仿射密码中,您使用乘法来加密。很自然,你可能认为你可以用仿射密码来解密。但是如果你尝试一下,你会发现它不起作用。要用仿射密码解密,您需要乘以密钥的模逆。这与加密过程中的 mod 操作相反。
两个数的模逆用表达式(a * i) % m == 1表示,其中i是模逆,a和m是两个数。例如,5 mod 7的逆将是某个数字i,其中(5 * i) % 7等于 1。您可以像这样强行计算:
1 不是5 mod 7的模逆,因为(5 * 1) % 7 = 5。
2 不是5 mod 7的模逆,因为(5 * 2) % 7 = 3。
3 是5 mod 7的模逆,因为(5 * 3) % 7 = 1。
虽然仿射密码的凯撒密码部分的加密和解密密钥是相同的,但是乘法密码的加密密钥和解密密钥是两个不同的数字。加密密钥可以是您选择的任何东西,只要它相对于符号集的大小是质数,在本例中是 66。如果选择密钥 53 用仿射密码加密,解密密钥是53 mod 66的模逆:
1 不是53 mod 66的模逆,因为(53 * 1) % 66 = 53。
2 不是53 mod 66的模逆,因为(53 * 2) % 66 = 40。
3 不是53 mod 66的模逆,因为(53 * 3) % 66 = 27。
4 不是53 mod 66的模逆,因为(53 * 4) % 66 = 14。
5 是53 mod 66的模逆,因为(53 * 5) % 66 = 1。
因为 5 是 53 和 66 的模逆,所以你知道仿射密码解密密钥也是 5。要解密一封密文信,将该信的数字乘以 5,然后取模 66。结果是原始明文的字母数。
使用 66 字符符号集,让我们使用密钥53加密单词Cat。C在索引2处,2 * 53是106,大于符号集大小,所以我们用66对106进行取模,结果是40。符号集中索引40处的字符是'o',所以符号C加密为o。
我们将对下一个字母使用相同的步骤,a。字符串'a'在符号集中的索引26处,26 * 53 % 66是58,是'7'的索引。所以符号a加密到7。字符串't'在索引45处,45 * 53 % 66是9,是'J'的索引。所以字Cat加密到o7J。
要解密,我们乘以53 % 66的模逆,就是5。的符号在索引40处,40 * 5 % 66是2,是'C'的索引。符号7在索引58处,58 * 5 % 66为26,为'a'的索引。符号J在索引9处,9 * 5 % 66是45,是't'的索引。密文o7J解密到Cat就是原来的明文,和预想的一样。
寻找模逆
为了计算模逆运算来确定解密密钥,您可以采用强力方法,开始测试整数 1,然后 2,然后 3,等等。但是这对于 8,953,851 这样的大密钥来说是很耗时的。
幸运的是,您可以使用欧几里德的扩展算法来寻找一个数的模逆,在 Python 中是这样的:
def findModInverse(a, m):
if gcd(a, m) != 1:
return None # No mod inverse if a & m aren't relatively prime.
u1, u2, u3 = 1, 0, a
v1, v2, v3 = 0, 1, m
while v3 != 0:
q = u3 // v3 # Note that // is the integer division operator.
v1, v2, v3, u1, u2, u3 = (u1 - q * v1), (u2 - q * v2), (u3 - q * v3),
v1, v2, v3
return u1 % m
使用findModInverse()函数不必了解欧几里德的扩展算法是如何工作的。只要传递给findModInverse()函数的两个参数互质,findModInverse()就会返回a参数的模逆。
你可以在www.nostarch.com/crackingcodes了解更多关于欧几里德的扩展算法是如何工作的。
整数除法运算符
您可能已经注意到了前一节中的findModInverse()函数中使用的//操作符。这就是整数除法运算符。它将两个数相除,并向下舍入到最接近的整数。在交互式 shell 中输入以下内容,看看//操作符是如何工作的:
>>> 41 / 7
5.857142857142857
>>> 41 // 7
5
>>> 10 // 5
2
鉴于41 / 7求值为5.857142857142857,使用41 // 7求值为5。对于不能均匀划分的除法表达式,//运算符对于获得答案的整数部分(有时称为商)很有用,而%运算符则获得余数。使用//整数除法运算符的表达式的计算结果总是int,而不是float。求值10 // 5时可以看到,结果是2而不是2.0。
cryptomath模块的源代码
我们将在本书后面的更多密码程序中使用gcd()和findModInverse(),所以让我们把这两个函数放在一个模块中。打开一个新的文件编辑器窗口,输入以下代码,将文件保存为cryptomath.py :
cryptomath.py
# Cryptomath Module
# https://www.nostarch.com/crackingcodes/ (BSD Licensed)
def gcd(a, b):
# Return the GCD of a and b using Euclid's algorithm:
while a != 0:
a, b = b % a, a
return b
def findModInverse(a, m):
# Return the modular inverse of a % m, which is
# the number x such that a*x % m = 1.
if gcd(a, m) != 1:
return None # No mod inverse if a & m aren't relatively prime.
# Calculate using the extended Euclidean algorithm:
u1, u2, u3 = 1, 0, a
v1, v2, v3 = 0, 1, m
while v3 != 0:
q = u3 // v3 # Note that // is the integer division operator.
v1, v2, v3, u1, u2, u3 = (u1 - q * v1), (u2 - q * v2),
(u3 - q * v3), v1, v2, v3
return u1 % m
这个程序包含本章前面描述的gcd()函数和实现欧几里德扩展算法的findModInverse()函数。
导入cryptomath.py模块后,您可以从交互式 shell 中试用这些函数。在交互式 shell 中输入以下内容:
>>> import cryptomath
>>> cryptomath.gcd(24, 32)
8
>>> cryptomath.gcd(37, 41)
1
>>> cryptomath.findModInverse(7, 26)
15
>>> cryptomath.findModInverse(8953851, 26)
17
如您所见,您可以调用gcd()函数和findModInverse()函数来寻找两个数的 GCD 或模逆。
总结
这一章讲述了一些有用的数学概念。%运算符计算一个数除以另一个数后的余数。gcd()函数返回能平分两个数的最大数。如果两个数的 GCD 是 1,你就知道这两个数互为质数。求两个数的 GCD 最有用的算法是欧几里德算法。
与凯撒密码不同,仿射密码使用乘法和加法而不仅仅是加法来加密字母。然而,并不是所有的数字都可以作为仿射密码的密钥。密钥数和符号集的大小必须互为质数。
要用仿射密码解密,需要将密文的索引乘以密钥的模逆。a % m的模逆是一个数i,使得(a * i) % m == 1。你可以使用欧几里德的扩展算法来计算模逆。第二十三章的公钥密码也使用模逆。
利用你在本章学到的数学概念,你将为第 14 章中的仿射密码编写一个程序。因为乘法密码和使用0的密钥 B 的仿射密码是一回事,所以你不会有单独的乘法密码程序。因为乘法密码只是仿射密码的一个安全性较低的版本,所以无论如何都不应该使用它。
练习题
练习题的答案可以在本书的网站www.nostarch.com/crackingcodes找到。
-
下面的表达式表示什么?
17 % 1000 5 % 5 -
10 和 15 的 GCD 是多少?
-
执行
spam, eggs = 'hello', 'world'后spam包含什么? -
17 和 31 的 GCD 是 1。17 和 31 是互质吗?
-
为什么 6 和 8 不是相对质数?
-
A mod C的模逆的公式是什么?
十四、仿射密码编程
原文:https://inventwithpython.com/cracking/chapter14.html
“即使你的耳朵在 1000 英里之外,而政府不同意,我也应该能在你耳边说些什么。”
——Philip Zimmermann,世界上最广泛使用的电子邮件加密软件 Pretty Good Privacy(PGP)的创造者

在第十三章中,你了解到仿射密码实际上是与凯撒密码结合的乘法密码(第五章),乘法密码与凯撒密码类似,只是它使用乘法而不是加法来加密消息。在本章中,您将构建并运行程序来实现仿射密码。因为仿射密码使用两种不同的密码作为其加密过程的一部分,所以它需要两个密钥:一个用于乘法密码,另一个用于凯撒密码。对于仿射密码程序,我们将把一个整数分成两个密钥。
本章涵盖的主题
-
元组数据类型
-
仿射密码可以有多少种不同的密钥?
-
生成随机密钥
仿射密码程序的源代码
选择文件 -> 新文件,打开新文件编辑器窗口。在文件编辑器中输入以下代码,然后保存为affinicipher.py。确保您在第 13 章中制作的pyperclip.py模块和cryptomath.py模块与affinicipher.py文件在同一个文件夹中。
affinicipher.py
# Affine Cipher
# https://www.nostarch.com/crackingcodes/ (BSD Licensed)
import sys, pyperclip, cryptomath, random
SYMBOLS = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz12345
67890 !?.'
def main():
myMessage = """"A computer would deserve to be called intelligent
if it could deceive a human into believing that it was human."
-Alan Turing"""
myKey = 2894
myMode = 'encrypt' # Set to either 'encrypt' or 'decrypt'.
if myMode == 'encrypt':
translated = encryptMessage(myKey, myMessage)
elif myMode == 'decrypt':
translated = decryptMessage(myKey, myMessage)
print('Key: %s' % (myKey))
print('%sed text:' % (myMode.title()))
print(translated)
pyperclip.copy(translated)
print('Full %sed text copied to clipboard.' % (myMode))
def getKeyParts(key):
keyA = key // len(SYMBOLS)
keyB = key % len(SYMBOLS)
return (keyA, keyB)
def checkKeys(keyA, keyB, mode):
if keyA == 1 and mode == 'encrypt':
sys.exit('Cipher is weak if key A is 1\. Choose a different key.')
if keyB == 0 and mode == 'encrypt':
sys.exit('Cipher is weak if key B is 0\. Choose a different key.')
if keyA < 0 or keyB < 0 or keyB > len(SYMBOLS) - 1:
sys.exit('Key A must be greater than 0 and Key B must be
een 0 and %s.' % (len(SYMBOLS) - 1))
if cryptomath.gcd(keyA, len(SYMBOLS)) != 1:
sys.exit('Key A (%s) and the symbol set size (%s) are not
relatively prime. Choose a different key.' % (keyA,
MBOLS)))
def encryptMessage(key, message):
keyA, keyB = getKeyParts(key)
checkKeys(keyA, keyB, 'encrypt')
ciphertext = ''
for symbol in message:
if symbol in SYMBOLS:
# Encrypt the symbol:
symbolIndex = SYMBOLS.find(symbol)
ciphertext += SYMBOLS[(symbolIndex * keyA + keyB) %
en(SYMBOLS)]
else:
ciphertext += symbol # Append the symbol without encrypting.
return ciphertext
def decryptMessage(key, message):
keyA, keyB = getKeyParts(key)
checkKeys(keyA, keyB, 'decrypt')
plaintext = ''
modInverseOfKeyA = cryptomath.findModInverse(keyA, len(SYMBOLS))
for symbol in message:
if symbol in SYMBOLS:
# Decrypt the symbol:
symbolIndex = SYMBOLS.find(symbol)
plaintext += SYMBOLS[(symbolIndex - keyB) * modInverseOfKeyA %
len(SYMBOLS)]
else:
plaintext += symbol # Append the symbol without decrypting.
return plaintext
def getRandomKey():
while True:
keyA = random.randint(2, len(SYMBOLS))
keyB = random.randint(2, len(SYMBOLS))
if cryptomath.gcd(keyA, len(SYMBOLS)) == 1:
return keyA * len(SYMBOLS) + keyB
# If affineCipher.py is run (instead of imported as a module), call
# the main() function:
if __name__ == '__main__':
main()
仿射密码程序的示例运行
在文件编辑器中,按F5运行affinicipher.py程序;输出应该如下所示:
Key: 2894
Encrypted text:
"5QG9ol3La6QI93!xQxaia6faQL9QdaQG1!!axQARLa!!AuaRLQADQALQG93!xQxaGaAfaQ1QX3o1R
QARL9Qda!AafARuQLX1LQALQI1iQX3o1RN"Q-5!1RQP36ARuFull encrypted text copied to
clipboard.
在仿射密码程序中,消息"A computer would deserve to be called intelligent if it could deceive a human into believing that it was human." -Alan Turing用密钥 2894 加密成密文。要解密这个密文,您可以复制并粘贴它作为新值存储在第 9 行的myMessage中,并将第 13 行的myMode改为字符串' decrypt'。
设置模块、常量和main()函数
程序的第 1 行和第 2 行是描述程序是什么的注释。这个程序中使用的模块还有一个import声明:
# Affine Cipher
# https://www.nostarch.com/crackingcodes/ (BSD Licensed)
import sys, pyperclip, cryptomath, random
该程序中导入的四个模块具有以下函数:
-
sys模块是为exit()函数导入的。 -
pyperclip模块是为copy()剪贴板函数导入的。 -
您在第十三章的中创建的
cryptomath模块是为gcd()和findModInverse()函数导入的。 -
random模块是为random.randint()函数导入的,用于生成随机密钥。
存储在SYMBOLS变量中的字符串是符号集,它是可以加密的所有字符的列表:
SYMBOLS = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz12345
67890 !?.'
消息中没有出现在SYMBOLS中的任何字符在密文中都保持未加密状态。例如,在运行affinicipher.py的示例中,引号和连字符(-)没有在密文中加密,因为它们不属于符号集。
第 8 行调用了main()函数,这个函数和换位密码程序中的函数几乎一模一样。第 9、10 和 11 行分别在变量中存储消息、密钥和模式:
main():
myMessage = """"A computer would deserve to be called intelligent
if it could deceive a human into believing that it was human."
-Alan Turing"""
myKey = 2894
myMode = 'encrypt' # Set to either 'encrypt' or 'decrypt'.
存储在myMode中的值决定了程序是加密还是解密消息:
if myMode == 'encrypt':
translated = encryptMessage(myKey, myMessage)
elif myMode == 'decrypt':
translated = decryptMessage(myKey, myMessage)
如果myMode被设置为'encrypt',则第 14 行执行,encryptMessage()的返回值被存储在translated中。但是如果myMode被设置为'decrypt',则decryptMessage()在第 16 行被调用,返回值被存储在translated中。当我们在本章后面定义encryptMessage()和decryptMessage()函数时,我将介绍它们是如何工作的。
在执行通过第 16 行之后,translated变量在myMessage中有消息的加密或解密版本。
第 17 行显示使用%s占位符的密码的密钥,第 18 行告诉用户输出是加密的还是解密的文本:
print('Key: %s' % (myKey))
print('%sed text:' % (myMode.title()))
print(translated)
pyperclip.copy(translated)
print('Full %sed text copied to clipboard.' % (myMode))
第 19 行打印translated中的字符串,它是myMessage中字符串的加密或解密版本,第 20 行将其复制到剪贴板。第 21 行通知用户它在剪贴板上。
计算并验证密钥
与只有一个密钥的凯撒密码不同,仿射密码使用两个整数密钥的乘法和加法,我们称之为密钥 A 和密钥 B。因为只记住一个数字更容易,所以我们将使用数学技巧将两个密钥转换为一个密钥。让我们看看这在affinicipher.py中是如何工作的。
第 24 行的getKeyParts()函数将一个整数密钥拆分成两个整数密钥 A 和密钥 B:
def getKeyParts(key):
keyA = key // len(SYMBOLS)
keyB = key % len(SYMBOLS)
return (keyA, keyB)
要分割的密钥被传递给key参数。在第 25 行,通过使用整数除法将key除以符号集的大小len(SYMBOLS)来计算密钥 A。整数除法(//)得出没有余数的商。第 26 行的模运算符(%)计算余数,我们将把它用于密钥 B。
例如,用2894作为key参数,一个 66 字符的SYMBOLS字符串,密钥 A 将是2894 // 66 = 43,密钥 B 将是2894 % 66 = 56。
要将密钥 A 和密钥 B 重新组合成一个密钥,将密钥 A 乘以符号集的大小,并将密钥 B 加到乘积中:(43 * 66) + 56计算为2894,这是我们开始使用的整数密钥。
注
请记住,根据香农的格言(“敌人知道系统!”)我们必须假设黑客知道加密算法的一切,包括符号集和符号集的大小。我们假设黑客唯一不知道的是所使用的密钥。我们的密码程序的安全性应该只取决于密钥的保密性,而不是符号集或程序源代码的保密性。
元组数据类型
第 27 行看起来像是返回一个列表值,除了用括号代替方括号。这是一个元组值。
return (keyA, keyB)
元组值类似于列表值,因为它可以存储其他值,这些值可以通过索引或切片来访问。但是,与列表值不同,元组值不能修改。元组值没有append()方法。
因为affinicipher.py不需要修改getKeyParts()返回的值,所以使用元组比列表更合适。
检查弱密钥
使用仿射密码加密涉及到将SYMBOLS中的一个字符的索引乘以密钥 A 并添加到密钥 B。但是如果keyA是1,则加密的文本非常脆弱,因为将索引乘以1会得到相同的索引。事实上,根据乘法恒等性质的定义,任何数与 1 的乘积就是那个数。类似地,如果keyB是0,加密的文本是脆弱的,因为将0添加到索引中不会改变它。如果同时keyA为1且keyB为0,则“加密”输出将与原始消息相同。换句话说,它根本不会被加密!
我们使用第 30 行的checkKeys()函数检查弱密钥。第 31 行和第 33 行的if语句检查keyA是1还是keyB是0。
def checkKeys(keyA, keyB, mode):
if keyA == 1 and mode == 'encrypt':
sys.exit('Cipher is weak if key A is 1\. Choose a different key.')
if keyB == 0 and mode == 'encrypt':
it('Cipher is weak if key B is 0\. Choose a different key.')
如果满足这些条件,程序将退出,并显示一条消息,指出哪里出错了。第 32 行和第 34 行各传递一个字符串给sys.exit()调用。sys.exit()函数有一个可选参数,允许您在终止程序之前在屏幕上打印一个字符串。您可以使用此函数在程序退出前在屏幕上显示一条错误消息。
这些检查防止你用弱密钥加密,但是如果你的mode被设置为'decrypt',第 31 和 33 行的检查不适用。
第 35 行的条件检查keyA是否为负数(即,是否小于0 )或keyB是否大于0或小于符号集的大小减一:
if keyA < 0 or keyB < 0 or keyB > len(SYMBOLS) - 1:
sys.exit('Key A must be greater than 0 and Key B must be
between 0 and %s.' % (len(SYMBOLS) - 1))
密钥在这些范围内的原因将在下一节中描述。如果这些条件中的任何一个为True,则密钥无效,程序退出。
此外,密钥 A 必须相对于符号集大小是质数。这意味着keyA和len(SYMBOLS)的最大公约数(GCD)必须等于1。第 37 行使用一个if语句对此进行检查,如果两个值不是互质的,第 38 行退出程序:
if cryptomath.gcd(keyA, len(SYMBOLS)) != 1:
sys.exit('Key A (%s) and the symbol set size (%s) are not
relatively prime. Choose a different key.' % (keyA,
len(SYMBOLS)))
如果checkKeys()函数中的所有条件都返回False,则密钥没有问题,程序不退出。程序执行返回到最初调用checkKeys()的那一行。
仿射密码可以有多少个密钥?
让我们试着计算仿射密码有多少个可能的密钥。仿射密码的密钥 B 受限于符号集的大小,其中len(SYMBOLS)是66。乍一看,只要与符号集的大小相对应,密钥 A 似乎可以像您希望的那样大。因此,您可能认为仿射密码有无限多的密钥,不能被暴力破解。
但事实并非如此。回想一下,由于环绕效应,凯撒密码中的大密钥最终与小密钥相同。在符号集大小为 66 的情况下,凯撒密码中的密钥67将产生与密钥1相同的加密文本。仿射密码也以这种方式环绕。
因为仿射密码的密钥 B 部分与凯撒密码相同,所以它的范围被限制为从 1 到符号集的大小。为了确定仿射密码的密钥 A 是否也是有限的,我们将编写一个简短的程序,使用密钥 A 的几个不同的整数来加密一条消息,并看看密文是什么样的。
打开一个新的文件编辑器窗口,并输入以下源代码。将该文件另存为affineKeyTest.py,与affineCipher.py和cryptomath.py放在同一文件夹下。然后按F5运行它。
affineKeyTest.py
# This program proves that the keyspace of the affine cipher is limited
# to less than len(SYMBOLS) ^ 2.
import affineCipher, cryptomath
message = 'Make things as simple as possible, but not simpler.'
for keyA in range(2, 80):
key = keyA * len(affineCipher.SYMBOLS) + 1
if cryptomath.gcd(keyA, len(affineCipher.SYMBOLS)) == 1:
print(keyA, affineCipher.encryptMessage(key, message))
该程序为其encryptMessage ()函数导入affineCipher模块,为其gcd()函数导入cryptomath模块。我们将总是加密存储在message变量中的字符串。for循环保持在2和80之间的范围内,因为0和1不允许作为有效的 Key A 整数,如前所述。
在循环的每次迭代中,第 8 行从当前的keyA值计算密钥,并且总是使用1作为密钥 B,这就是为什么在第 8 行的末尾添加了1。请记住,密钥 A 必须与符号集大小互质才有效。如果关键字和符号集大小的 GCD 等于1,则密钥 A 与符号集大小互质。所以如果密钥和符号集大小的 GCD 不等于1,第 10 行的if语句将跳过对第 11 行encryptMessage()的调用。
简而言之,这个程序打印用几个不同的整数为密钥 A 加密的相同消息。这个程序的输出如下所示:
5 0.xTvcin?dXv.XvXn8I3Tv.XvIDXXnE3T,vEhcv?DcvXn8I3TS
7 Tz4Nn1ipKbtnztntpDY NnztnYRttp7 N,n781nKR1ntpDY Nm9
13 ZJH0P7ivuVtPJtPtvhGU0PJtPG8ttvWU0,PWF7Pu87PtvhGU0g3
17 HvTx.oizERX.vX.Xz2mkx.vX.mVXXz?kx,.?6o.EVo.Xz2mkxGy
--snip--
67 Nblf!uijoht!bt!tjnqmf!bt!qpttjcmf,!cvu!opu!tjnqmfsA
71 0.xTvcin?dXv.XvXn8I3Tv.XvIDXXnE3T,vEhcv?DcvXn8I3TS
73 Tz4Nn1ipKbtnztntpDY NnztnYRttp7 N,n781nKR1ntpDY Nm9
79 ZJH0P7ivuVtPJtPtvhGU0PJtPG8ttvWU0,PWF7Pu87PtvhGU0g3
仔细观察输出,您会注意到5的密钥 A 的密文与71的密钥 A 的密文相同!事实上,密钥7和73的密文是一样的,密钥13和79的密文也是一样的!
还要注意,从 71 中减去 5 得到 66,这是我们符号集的大小。这就是为什么71的密钥 A 和5的密钥 A 做同样的事情:加密的输出每 66 个密钥重复一次,或者绕回一次。如您所见,仿射密码对密钥 A 和密钥 B 具有相同的环绕效果,总之,密钥 A 也受限于符号集大小。
当你用 66 个可能的 A 密钥乘以 66 个可能的 B 密钥,结果是 4356 个可能的组合。然后,当您减去不能用于密钥 A 的整数(因为它们与 66 不是相对质数)时,仿射密码的可能密钥组合总数下降到 1320。
编写加密函数
为了加密affinicipher.py中的消息,我们首先需要key和message来加密,encryptMessage()函数将它们作为参数:
def encryptMessage(key, message):
keyA, keyB = getKeyParts(key)
checkKeys(keyA, keyB, 'encrypt')
然后我们需要从第 42 行的getKeyParts ()函数中获得密钥 A 和密钥 B 的整数值,方法是将它传递给key。接下来,我们通过将这些值传递给checkKeys()函数来检查它们是否是有效的密钥。如果checkKeys()函数没有导致程序退出,那么密钥是有效的,第 43 行之后的encryptMessage()函数中的剩余代码可以继续执行。
在第 44 行,ciphertext变量以一个空字符串开始,但最终将保存加密的字符串。从第 45 行开始的for循环遍历message中的每个字符,然后将加密的字符添加到ciphertext:
ciphertext = ''
for symbol in message:
当for循环结束时,ciphertext变量将包含加密消息的完整字符串。
在循环的每次迭代中,symbol变量被赋予一个来自message的字符。如果这个字符存在于我们的符号集中的SYMBOLS中,那么在SYMBOLS中的索引被找到并分配给第 48 行的symbolIndex:
if symbol in SYMBOLS:
# Encrypt the symbol:
symbolIndex = SYMBOLS.find(symbol)
ciphertext += SYMBOLS[(symbolIndex * keyA + keyB) %
len(SYMBOLS)]
else:
ciphertext += symbol # Append the symbol without encrypting.
要加密文本,我们需要计算加密密码的索引。第 49 行将这个symbolIndex乘以keyA,并将keyB加到乘积上。然后,它根据符号集的大小修改结果,用表达式len(SYMBOLS)表示。由len(SYMBOLS)进行的调制通过确保计算出的指数总是在0和不包括len(SYMBOLS)之间来处理绕回。得到的数字将是加密字符在SYMBOLS中的索引,它被连接到ciphertext中字符串的末尾。
上一段的所有内容都是在第 49 行完成的,只用了一行代码!
如果symbol不在我们的符号集中,symbol被连接到第 51 行的ciphertext字符串的末尾。例如,原始消息中的引号和连字符不在符号集中,因此会连接到字符串。
代码遍历完消息字符串中的每个字符后,ciphertext变量应该包含完整的加密字符串。第 52 行返回来自encryptMessage()的加密字符串:
return ciphertext
编写解密函数
解密文本的decryptMessage()函数和encryptMessage()几乎一样。第 56 到 58 行相当于第 42 到 44 行。
def decryptMessage(key, message):
keyA, keyB = getKeyParts(key)
checkKeys(keyA, keyB, 'decrypt')
plaintext = ''
modInverseOfKeyA = cryptomath.findModInverse(keyA, len(SYMBOLS))
然而,解密过程不是乘以密钥 A,而是乘以密钥 A 的模逆。模逆通过调用cryptomath.findModInverse()来计算,如第 13 章中所述。
第 61 到 68 行几乎与encryptMessage()函数的第 45 到 52 行相同。唯一的区别在第 65 行。
for symbol in message:
if symbol in SYMBOLS:
# Decrypt the symbol:
symbolIndex = SYMBOLS.find(symbol)
plaintext += SYMBOLS[(symbolIndex - keyB) * modInverseOfKeyA %
len(SYMBOLS)]
else:
plaintext += symbol # Append the symbol without decrypting.
return plaintext
在encryptMessage()函数中,符号索引乘以密钥 A,然后添加密钥 B。在decryptMessage()函数的行 65 中,符号索引首先从符号索引中减去密钥 B,然后将其乘以模逆。然后它根据符号集的大小修改这个数字,len(SYMBOLS)。
这就是affinicipher.py中的解密过程如何撤销加密。现在让我们看看如何改变affineCipher.py,以便它为仿射密码随机选择有效的密钥。
生成随机密钥
很难找到仿射密码的有效密钥,所以您可以使用getRandomKey()函数生成一个随机但有效的密钥。为此,只需更改第 10 行,将getRandomKey ()的返回值存储在myKey变量中:
y = getRandomKey()
--snip--
print('Key: %s' % (myKey))
现在,当第 17 行执行时,程序随机选择密钥并将其打印到屏幕上。让我们看看getRandomKey()函数是如何工作的。
第 72 行的代码进入一个while循环,其中条件为True。这个无限循环将永远循环下去,直到被告知返回或者用户终止程序。如果你的程序陷入了一个无限循环,你可以通过按下ctrl+C(Linux 或 macOS 上的ctrl+D)来终止程序。getRandomKey()函数将最终通过return语句退出无限循环。
def getRandomKey():
while True:
keyA = random.randint(2, len(SYMBOLS))
keyB = random.randint(2, len(SYMBOLS))
第 73 和 74 行确定了在2和为keyA和keyB设置的符号大小之间的随机数。这个代码确保密钥 A 或密钥 B 不会等于无效值0或1。
第 75 行的if语句通过调用cryptomath模块中的gcd()函数来检查以确保keyA与符号集的大小互质。
if cryptomath.gcd(keyA, len(SYMBOLS)) == 1:
return keyA * len(SYMBOLS) + keyB
如果keyA与符号集的大小互质,则通过将keyA乘以符号集的大小并将keyB加到乘积上,将这两个随机选择的密钥组合成一个密钥。(注意,这与getKeyParts()函数相反,它将单个整数密钥拆分成两个整数。)第 76 行从getRandomKey()函数返回这个值。
如果第 75 行的条件返回False,代码循环回到第 73 行的while循环的起点,并再次为keyA和keyB选择随机数。无限循环确保程序继续循环,直到找到有效密钥的随机数。
调用main()函数
如果这个程序是自己运行的,而不是由另一个程序导入的,那么第 81 和 82 行调用main()函数:
# If affineCipher.py is run (instead of imported as a module), call
# the main() function:
if __name__ == '__main__':
main()
这确保了main()函数在程序运行时运行,而不是在程序作为模块导入时运行。
总结
正如我们在第 9 章中所做的一样,在这一章中我们编写了一个程序( affineKeyTest.py )来测试我们的密码程序。使用这个测试程序,您了解到仿射密码大约有 1320 个可能的密钥,您可以使用暴力破解这个数字。这意味着我们将不得不把仿射密码扔到容易破解的弱密码堆上。
所以仿射密码并不比我们之前看到的密码更安全。换位密码可以有更多可能的密钥,但是可能的密钥数量受限于消息的大小。对于只有 20 个字符的消息,换位密码最多可以有 18 个密钥,密钥范围从 2 到 19。您可以使用仿射密码加密短消息,比凯撒密码提供的安全性更高,因为它的可能密钥数是基于符号集的。
在第 15 章中,我们将编写一个暴力破解程序,可以破解仿射密码加密的信息!
练习题
练习题的答案可以在本书的网站www.nostarch.com/crackingcodes找到。
-
仿射密码是哪两种密码的组合?
-
什么是元组?元组和列表有什么不同?
-
如果密钥 A 是 1,为什么它会使仿射密码变弱?
-
如果密钥 B 为 0,为什么会使仿射密码变弱?