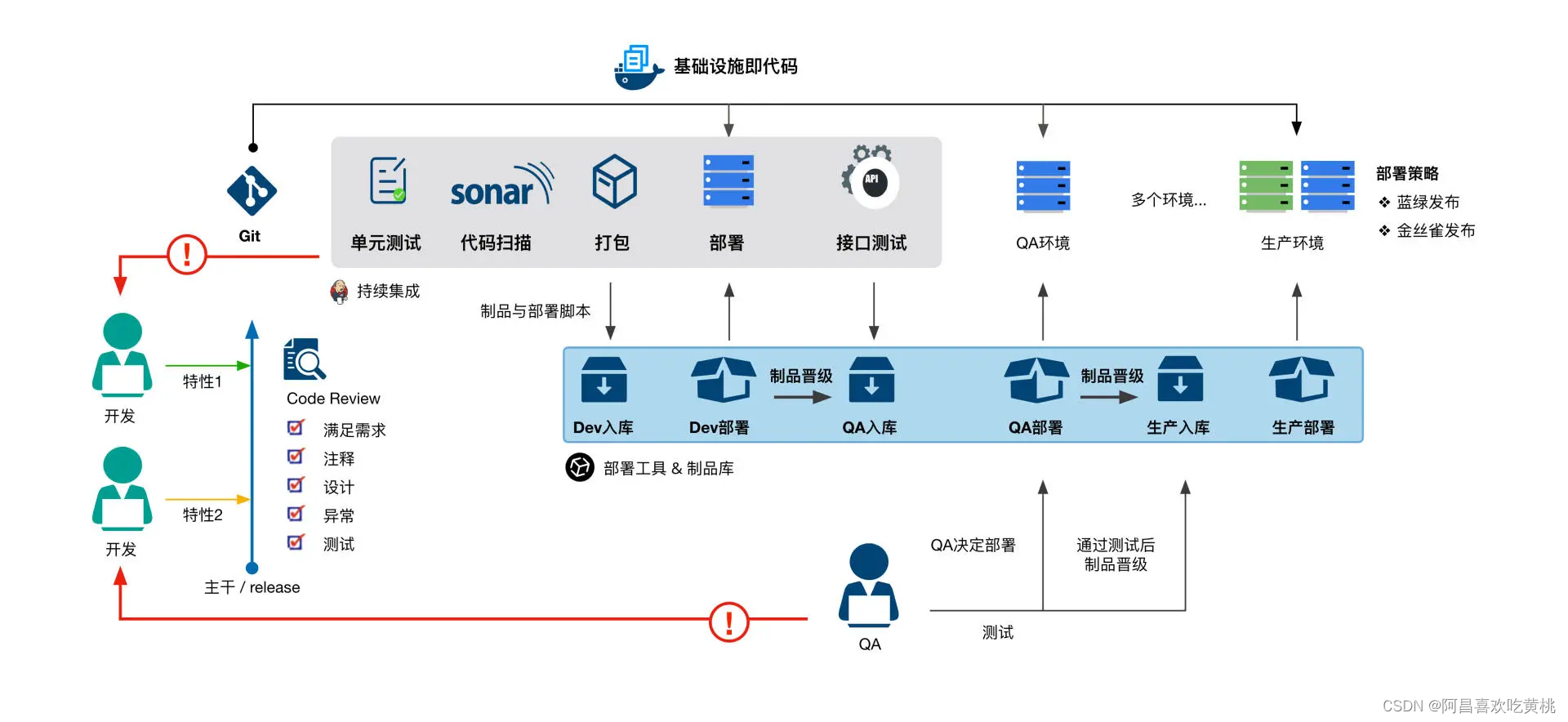
从持续集成到持续部署
Hi,我是阿昌,今天学习记录的是关于从持续集成到持续部署的内容。
只有做好任务分解和小步提交,才能放心大胆地 PUSH 代码,触发持续构建;
只有通过质量门禁,才能得到一个有信心的制品;
分级构建可以让我们更加快速地得到反馈;而制品晋级才真正地让持续集成流水线流动起来。
一、持续集成
要想做到真正的持续集成,需要一个与之匹配的代码分支策略。
这方面的话题历来就十分有争议,说一说观点。
二、分支策略:特性分支 or 基于主干开发?
要说现在国内最流行的分支策略,非特性分支(Feature Branch)莫属,它还有一个更响亮的名字—— GitFlow。
不过,虽然名字叫 GitFlow,但它并不是 Git 官方推荐的做法,而只是 Vincent Driessen 的发明创造而已。
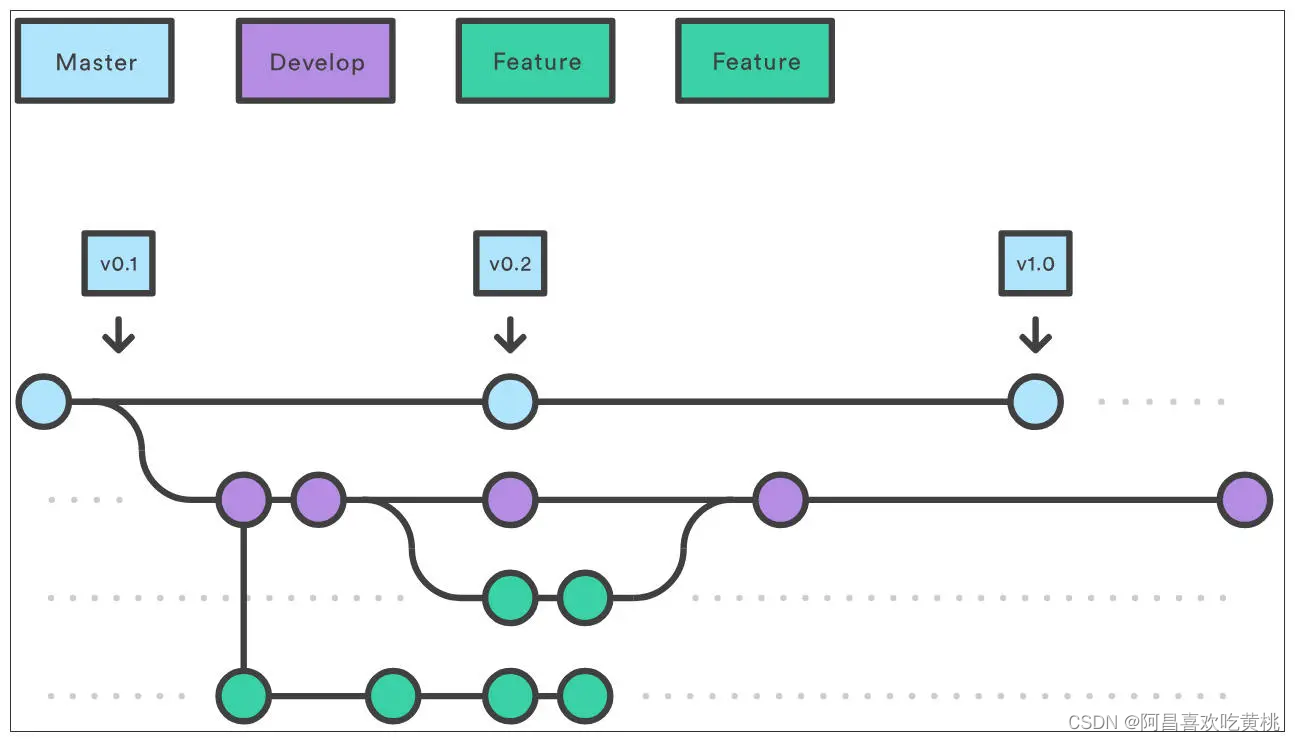
不过,国内很多团队刚刚开始使用持续集成工具,其分支策略是在 GitFlow 基础上的某种变形。
比如,每个开发人员在开发一个特性时,都会在主分支上拉出自己的特性分支;
等开发完成后再合并到 QA 分支,当持续集成流水线运行成功,制品会部署到 QA 环境;
当 QA 测试通过后,开发人员再把自己的特性分支合并到 UAT 分支,进行 UAT 测试……以此类推,当各个测试环境都测试通过后,再把特性分支合并到发布分支。
可以看出,这样的方式是不可能做到制品晋级的。
1、特性分支带来的问题
不管是 GitFlow,还是这种变形的特性分支都会造成很多问题。
首先最大的问题就是质量隐患,因为缺少制品晋级的机制,即使所有的特性分支在各测试环境都得到了充分验证,也无法 100% 保证,所有特性分支合并到发布分支后的制品是可靠的。毕竟只有经过多个环境层层检验的同一个制品,才能让放心部署。
另外,特性分支的好处之一是,可以在发布之前灵活选择哪些特性延迟上线,方法就是不把这个特性分支合并到发布分支。但这同样有很严重的质量隐患。
在其他测试环境所测试的制品都包含这个特性分支的代码,但发布分支中的制品却不包含,必须对所有特性重新测试才能确保它们的正确性。然而这一步却常常被忽略,人们普遍认为只要特性被单独测过了,集成后就仍然是正确的。
其次,特性分支只有在特性开发完毕后才会合并代码,这样就无法实现小步提交和持续构建,更不要说持续集成了。
在每个开发周期的前几天,团队成员都刚刚起步,没有代码提交,持续集成服务器可能都不会执行任何构建任务,资源闲置。而在中后期,大家密集地合并代码,又可能导致资源不够用。
第三,由于合并的时机比较晚,常常会造成大规模的合并冲突,不仅如此,在向每个环境的分支上合并时,都要解决一遍合并冲突,十分痛苦。说好的痛苦的事情频繁做呢?
有时候为了避免冲突,很多开发人员会选择不去修改原有代码,而是将代码复制出来,只加入自己的修改,造成了大量代码重复。
乍看上去有点像我们已经讲过的种种模式,但它只“扩张”,不“收缩”,实际上只能增加混乱。而且重构代码是最有可能造成大规模冲突的。
不得不面对旷日持久的代码合并,彼此合并代码时的怨声载道,这种状况下心情和效率自然都好不了。
久而久之,团队重构代码的意愿也会逐渐消退,代码质量也就越来越糟,新系统又会向着遗留系统的不归路大步流星。
最后,由于开发人员在开发完一个需求并合并到 QA 分支后,就开始着手开发下一个需求了。
但此时他还需要时刻想着,将原来的特性分支在不同的时间点合并到其他测试分支,就这样在不同的分支上下文之间来回切换,开发人员除了开发需求外,脑子里还要想着各种跟开发无关的东西,认知负载相当高。
这种分支策略,表面上看是把不同的特性分支当成沙箱,帮助多个开发人员在隔离的环境下并行开发,但实际上它把软件开发这个团队活动割裂为单个开发人员的单人行为,与 DevOps 的价值观背道而驰。
说白了,选择等一个需求完全开发完毕再合并,就已经和持续集成渐行渐远了。
近年来国内流行的 AoneFlow 分支策略其实也无法解决上述问题,它虽然允许频繁提交代码,但由于要保持本地分支的“干净”,只能将代码合并到 release 分支,却不能把 release 的代码合并(或 rebase)到本地。也就是说,代码只在远端集成,本地不能集成。
这就导致你每次的合并都将十分头疼。而且,当临时有需求延迟发布或者干脆砍掉的时候,虽然 AoneFlow 的重建发布分支很快,但想想,这个新发布分支中的所有特性是不是还需要重新测试?它们之前已经测过了。
但那是在有延迟发布的那个需求代码的基础上测试的,摘掉这些代码后,就不需要测试了吗?
对于开发人员,重建分支是分分钟的事情,但对于测试人员,就又得加班加点重测一遍。说好的团队为质量负责呢?
2、最理想的分支策略:基于主干开发
最理想的分支策略是基于主干开发(Trunk Based Development)。
这其实是 SVN 时代就流行的开发方式。在最新的 2021 DevOps 年度报告中,仍然把基于主干开发作为必备的 DevOps 能力。
同时,在刚刚上市的《加速:企业数字化转型的 24 项核心能力》这本书中,也推荐了基于主干开发。
为什么值得推荐,先看看这种策略的一般流程。
- 持续提交:开发人员每日持续提交当天开发的代码,持续构建和集成;
- 冲突处理:每次提交代码,都会先 rebase 远端的 master 代码,这让开发人员有机会在本地解决当前的冲突;
- 制品晋级:提交的代码经过持续集成流水线产生制品,该制品不断晋级,最终成为生产环境的部署候选。
- 延迟发布的特性处理:在一开始就预警这种风险,并使用特性开关(Feature Toggle)来进行控制,如果需要延迟,就将开关关闭,只部署但并不交付这个特性,由于开关关闭的场景早就在多个环境下验证过了,测试人员也不需要加班。
因为采用了基于业务场景的任务分解和小步提交,理论上每个 commit 都能提供业务价值,也是可以部署和交付的。
由于代码直接 PUSH,根本不用在本地建立分支,而直接在本地的主干分支上开发即可。
每一个 commit 都是可以提交甚至交付的,所以无需担心其他高优先级的工作影响本地分支。
可以立即 PUSH 当前已经 commit 的代码,着手新的工作。
即使有时当前代码无法提交,也可以建立一个临时分支,或者暂时 stash 代码。
一直头疼的冲突处理也被分解了,它内嵌到每次提交代码中,因为团队日常始终在频繁多次地解决这些冲突,所以冲突都不会太大。
在这种策略下,所有的代码变更(包括 revert 的代码)都会走一遍流水线,产生新的制品,这也是一种增量的思想。而不是像其他策略那样,靠是否合并到特定分支来决定代码的去留。
-
只有做好
任务分解和小步提交,才能做到持续 PUSH 代码; -
只有写好
单元测试,才有信心 PUSH 代码; -
只有引入
特性开关,才能无所畏惧地 PUSH 代码。
主干开发和上节课讲的诸多 DevOps 实践是一脉相承的。
然而很多团队认为主干开发的门槛太高,任务分解、小步提交、单元测试、特性开关这些实践对开发人员要求过高,普通的团队无法达到这样的要求。但我认为这并不是人员能力的问题,因为很多互联网大厂也无法做到这一点,是他们的能力不行吗?
显然不是。这其实是团队文化的问题。
三、DevOps 文化
DevOps 其实不是一个角色,而是一种文化,一种价值观。
任务分解、小步提交等实践与其说是开发技能,不如说是团队协作、快速反馈等价值观在技术实践上的投影。
拿持续集成流水线的纪律来举个例子。一般持续集成做得好的团队,都会贯彻这样的流水线纪律:
- 如果当前 CI 的状态是红色,则禁止提交新的代码
- 如果 15 分钟内不能快速修复,就 revert 刚才 PUSH 的代码,重新提交
- 尽量频繁地触发 CI,比如一天 N 次
- CI 失败不过夜
- 一旦提交代码,要监控 CI 状态,直到全部通过(或提交构建通过,次级构建开始),才能着手其他工作

这样的纪律背后,隐藏的是团队协作、责任共享、快速反馈的 DevOps 价值观。
CI 是团队的 CI,一个人把 CI“搞挂了”,其他人就不能再次提交,要等他修复;
如果短时间无法修复,则 revert 代码,不要影响其他人;
尽量频繁地提交代码,让其他人可以跟你的代码更早地集成;
CI 失败如果过夜,第二天早上早来的同事就无法提交代码;
负责任地监控 CI 状态,得到失败的反馈后第一时间着手修复;
只有修复了或 revert 了,才是有效的反馈,如果置之不理,则是无效的反馈。
基于特性分支开发,代码提交频率低且代码量大,导致 CI 挂掉的可能性非常高。
为了避免影响其他人提交,开发团队只能退而为每次提交提供单独的 CI 服务器。团队协作进一步割裂,产出的制品也无法部署。
如果 DevOps 文化没有融入整个团队,那么各种 DevOps 实践都会打折扣,充其量也就是能做到用工具来辅助构建和打包,无法做到持续构建和持续集成。
四、需求管理
当然主干分支 + 特性开关的策略并不是毫无缺点的,特别是当需求变化较大,多个特性开关并存且存在交叉的情况下,这些都有可能成为定时炸弹。这时,需求管理就需要变革了。
一方面,有可能不会上线的需求要提前预警,让开发人员准备特性开关。
另一方面,要把需求的粒度砍小。为什么要砍小呢?
可以从开发侧来倒推。我们所提倡的任务分解和小步提交,前提就是需求的粒度足够小,这样代码提交的粒度才能随之变小。
如果还是传统的大需求,这中间自然需要一个拆解过程,把需求从粗粒度拆分成细粒度,进而分解成足够小的开发任务。
不过拆分需求并非开发人员擅长的,而是需求分析人员的本职工作。
再者,如果一个大需求需要几个月开发完成,需求方就只能在最后阶段才能看到做成了什么样子。
一旦与想要的不符,就要推倒重来,造成了巨大的浪费。细粒度的需求可以在早期就向客户展示部分已完成的内容,确保方向的正确性。
这时,需求管理不但要需求分析人员转变工作方式,连需求方都要一并加入,用细粒度的用户故事替代落后的需求文档。
五、Code Review
还有一个影响持续集成的原因,是目前普遍存在的基于 Pull Request 的 Code Review 方式。
团队是不是这样做 Code Review 的?
开发人员开发完特性,commit 完代码,申请一个 Pull Request,并选择一个高级开发人员进行 Code Review。
这名高级开发人员在 Review 完成后,才会合并代码,触发持续集成流水线。
发现这样做的问题了吗?根本不知道你提交的代码在什么时候合并,什么时候触发 CI。提完 PR 后,你会跟自己的代码“失联”多久是未知的。于是你着手其他工作,等发现 CI 挂掉,又不得不切换回上个特性分支修复。
在基于主干的分支策略下,代码是直接 PUSH 的,而无需使用 PR。你可以立即得到 CI 的反馈。秉承极限编程的理念,既然 Code Review 是好的,那么就频繁地去做。
所以, 可以尝试每日 Code Review。每天一个固定的时间,团队成员围在一台显示器前或者会议室的大电视前,集体 Code Review,每个人都能知道其他人在做的事情,尽早知道是否会影响自己的开发,也能在其他人遇到困难的时候,第一时间伸手帮忙。
为了实现更高效的 Code Review,还可以在 commit 代码的时候使用一些小技巧。
比如在使用并行运行模式的时候,需要复制代码。
可以在复制完代码后立即 commit 一次,然后再在复制后的代码上修改,继续 commit。
这样做的好处是,第二次 commit 和第一次 commit 的代码是可以看出差别的,有利于 Code Review。
否则,如果复制出来直接修改,那么就只能看到修改后的代码,无法 diff 你的修改了。
六、持续部署
当团队内部形成了良好的 DevOps 文化之后,你就可以考虑加快部署频率了。
七、高频发布
2017 年的 DevOps 年度报告中指出,Amazon 和 Netflix 每天的部署次数高达数千次。
报告还给出了高效组织的部署频次约为每天 4 次,每年 1460 次;中等组织每年部署 32 次;而低效组织每年部署 7 次。
每天可以部署这么多次,有什么好处呢?
其实,这种高频发布跟任务分解、小步提交等实践,都遵循了增量演进的思想。
部署的频率越高,每次部署的风险和成本也越低,部署时间和 Bug 修复的时间也越少。
此外,由于你能更快速地得到真实用户的反馈,也能及时调整产品演进的方向。
八、自动化部署
要做到高频次地发布,首先要实现部署的自动化,也就是在持续集成流水线中加上部署的阶段。
这样,每一次代码 PUSH 所触发的集成,最终都能部署到服务器上。
在遗留系统中,部署总是最头疼的问题。通常需要一个专门的发布团队,停机数小时甚至更久,按照部署手册依次进行抽取软件包、准备并执行数据库脚本、复制文件等操作。
而要做到自动化部署,需要为每个阶段准备部署脚本,使用部署流水线来管理部署的过程,对不同的环境也尽量使用同一套部署脚本,并把脚本纳入到代码版本管理中。
在尝试之初,你可以只把持续部署到测试环境这条链路打通。毕竟对于大多数系统,还是需要经过手动测试,才能部署到生产环境的。
但即使你只能做到每一行代码提交都能持续部署到测试环境,也已经超越了绝大多数软件项目。
九、低风险发布
其次,要构建低风险发布策略,将发布风险降到最低。
低风险发布策略,是指在部署过程中不要影响正常的业务行为,要让用户无感知;
一旦部署失败,需要尽快回滚到正常状态,尽量减少对客户的影响。
低风险发布策略包括蓝绿部署、滚动部署、金丝雀发布等。
蓝绿部署(blue-green deployment)是指准备两套完全一样的运行环境,即生产环境(蓝环境)和预生产环境(绿环境)。
在部署时,先在绿环境中部署,并测试验收。在确认没有问题后,再将请求引流到绿环境,而蓝环境则仍然保持旧版本。当确定新版的部署没有问题后,绿环境升级为生产环境,而蓝环境则变为预生产环境,等待下次部署。由于蓝绿部署并不会造成停机,新的生产数据一直在产生,这样就会给环境切换造成一定的困难。
因此,很多蓝绿部署方案都会采用共享数据库的方式,同时对数据迁移脚本做兼容性处理,让共享的数据库可以应对新旧两个版本的系统。
比如在修改字段时使用扩张 - 收缩模式,先增加字段,并做数据迁移。
这样,数据库就可以运行在新旧两个版本上了。
当新版本确认没问题后,在下次部署的时候再删掉老字段。

蓝绿部署需要准备两个完全一样的环境,有没有比它更节省资源的策略呢?
这种策略就是滚动部署(rolling deployment),即在服务集群中选择一个或多个服务单元,先对这些服务单元进行部署,然后投入使用,并开始部署其他服务单元。
如此循环直到所有单元都部署完毕。
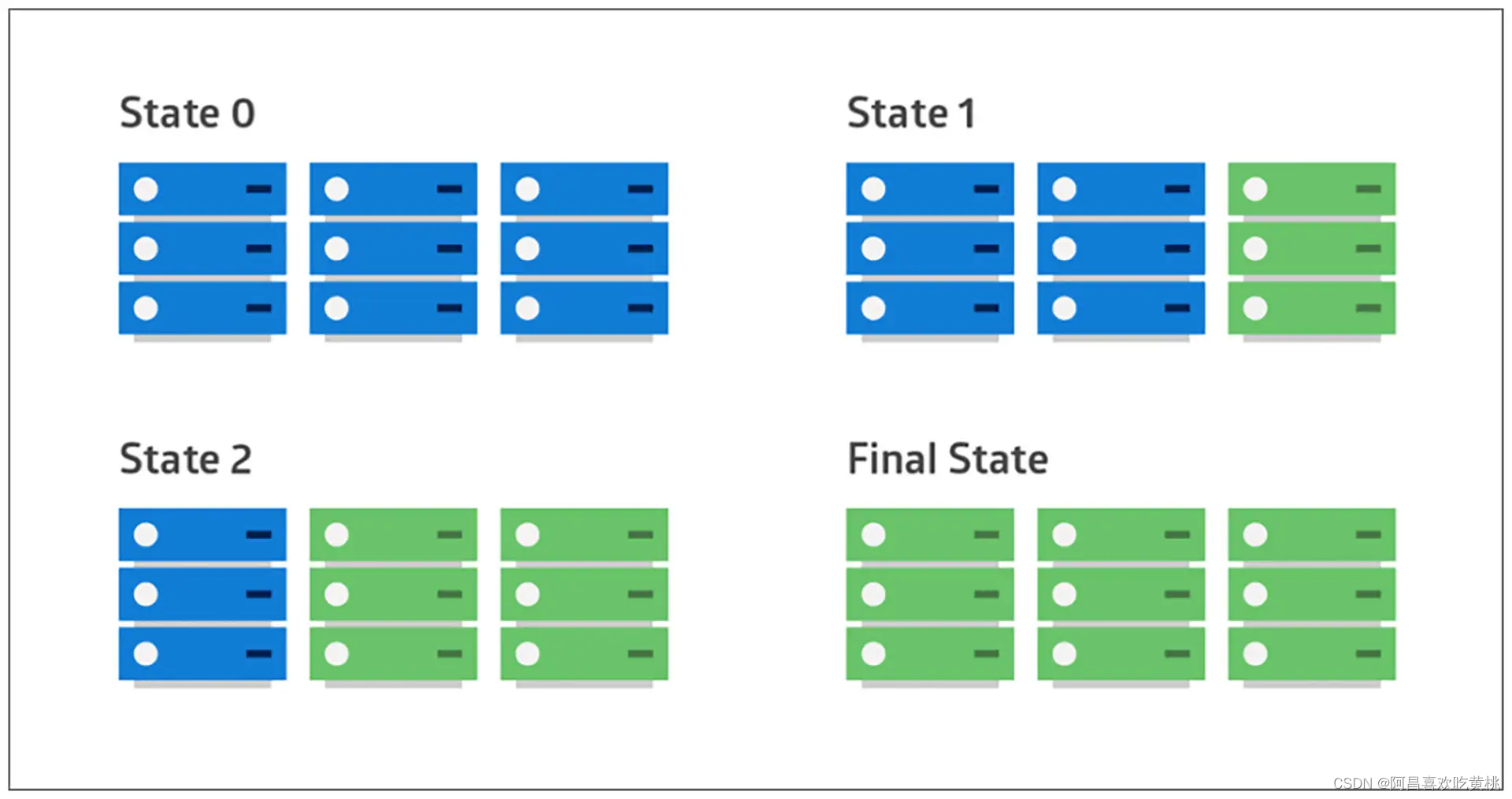
上面的两种部署方式是从物理的角度隔离新旧版本,而金丝雀发布(Canary Release)策略则引入了用户的维度。
比如在蓝绿部署或滚动部署中引入了新版本后,并不是将所有流量都引流到新版本,而是只对一小部分用户开放,以快速验证,从而降低发布风险。
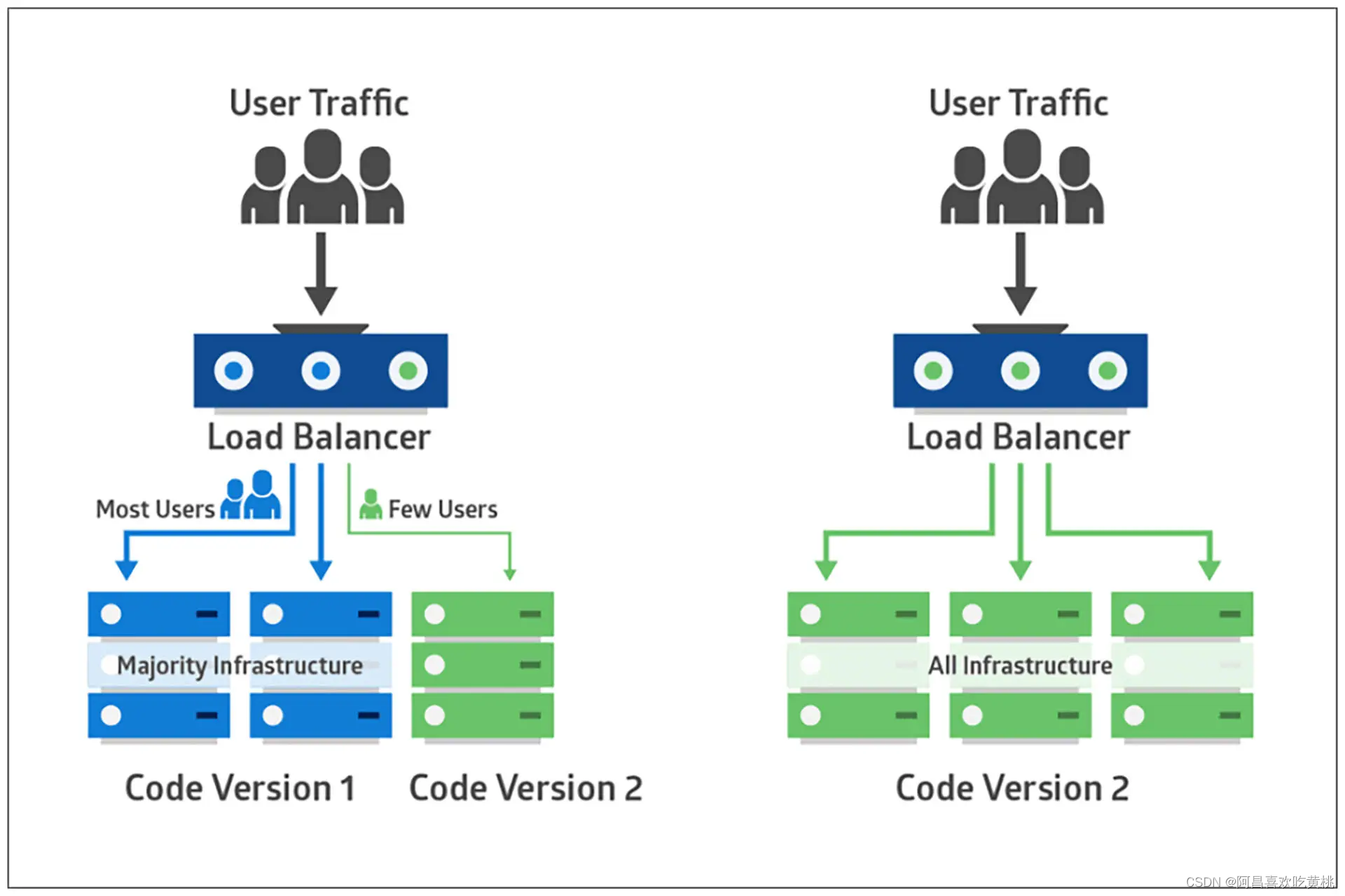
在实际操作中,可以让生产环境的测试用户作为金丝雀用户,测试人员在生产环境进行测试和验证,这样能在一定程度上做到 QA in Production。
可能都不需要那么多的测试环境了。金丝雀发布还可以延伸成为灰度发布,即当金丝雀用户验证通过后,不立即开发给全部用户,而是按照一定阶段逐步开放给所有用户。
有的时候你会发现,你和别人用着同样版本的手机 App,但却没有别人的功能,那可能就是还没有“灰度”到你。
十、应用回滚
哪怕已经将发布风险降到最低,也不代表零风险。
发布出现问题的时候,要及时将系统“回滚”到上一个稳定的版本。
这里说的“回滚”并不是指像数据库回滚事务那样,从逻辑上逆向执行一遍所有代码增量;
也不是指 revert 所有这次部署的代码提交,重新走一遍流水线,产生新的制品,进而部署,而是指部署上一个稳定的版本。
这个稳定版本是相对可靠的,没必要产生新的制品了。但这时可能会需要一定程度的人工介入,如果流水线执行速度相当快、质量相当高,也可以 revert 代码并重新产生制品。
如果发生问题的部分包含特性开关,也可以关闭开关来规避问题。
同时,数据库的结构要做到向下兼容。一般回滚部署时,只回滚应用程序,而不要回滚数据库,否则会造成数据丢失等问题。
就算只做到了持续部署到测试环境,低风险发布策略和应用回滚也是有必要的,毕竟在如此高频的发布下,测试人员的工作是不能被阻塞的。
十一、总结
分支策略。这是一个充满争议的话题,每次对于 GitFlow 的批判,都会引发热议。
只有应用了主干开发,遗留系统现代化的增量演进原则才能更好地贯彻。
每次增量演进都能及时 PUSH 到主干,从而过一遍持续集成流水线,并部署到各个环境。而如果是特性分支策略,会不自觉地等着全部完成后再合并代码。
灵活的分支功能是 Git 的一大亮点,但它并不是为了开发特性而设计的。利用特性分支在本地长期保存多份代码版本,这是对 Git 分支的滥用,增加了不必要的认知负载。
虽然应用主干开发也具备一定的认知负载,但这些都属于内在认知负载,一旦掌握就一劳永逸。而不像特性分支所带来的外在认知负载那样,需要时刻想着这个想着那个。
另外还要说的一点是,不要因为忌惮代码合并而回避代码重构。
此外,团队协作、责任共享、快速反馈的 DevOps 文化,以及要适应这种文化,需要在需求管理方面做出的转变。
这里总结了一个对于持续集成的建议,希望不畏艰难,勇于尝试:

尽管遗留系统看上去离做到持续部署还很遥远,但低风险发布和应用回滚等策略对遗留系统现代化是非常有价值的。
比如常说的增量演进原则,以及抽象分支、扩张收缩模式的应用,在测试和交付时都会用到蓝绿部署和灰度发布等低风险发布策略。
一旦发生问题,就会关闭开关,将应用回滚。
从单次构建,到持续构建,到持续集成,到持续部署和持续交付,这是一条漫长又美好的演进之旅。
现在国内很多传统企业都开始做 DevOps 转型,这是一个好现象,也是企业遗留系统现代化,以及数字化转型的必经之路。