Why RCU
1. 中断与抢占
当一个进程被时钟中断打断后,kernel运行tick中断处理程序(一般是top half),中断处理程序运行结束后,有两种情况:
-
之前的进程获得CPU继续运行。
-
另一个进程获得了CPU开始运行,而之前的进程则被抢占(preempted)了。
所以,抢占只会发生在tick时钟中断之后,但时钟中断并不是每次都会产生进程抢占。
这里一定是时钟中断sheduler_tick()么?还是指所有的interrupt中断都可能产生抢占?
1.1 进程调度与抢占关系
进程调度是由kernel中scheduler来完成,但是也分为抢占性调度和非抢占性调度。如果内核没有开启抢占,那么OS一旦将CPU分配给某个进程开始运行后,除非该进程执行完毕或因事件主动放弃CPU,否则该进程会一直执行下去,这种情况下因该进程主动放弃CPU或执行结束而放弃CPU导致的进程调度,我理解为非抢占调度,是scheduler被动调度,然后发生进程切换。
而如果内核开启了抢占,那么当某个进程在执行时,来了更高优先级的进程或事件,则可以抢占当前正在运行的进程,scheduler_tick()时钟中断处理中scheduler会去判断,然后安排进程调度,将CPU让给更需要优先运行的任务,进而发生进程切换,这是scheduler主动调度,我理解为抢占调度。
2. 内核同步
2.1 内核抢占
2.1.1 理解内核
内核如同辛勤劳动的你,对,没错,你就是内核。你每天的工作运行至少能满足两类人的需求,老板和客户,所以你每天采取的策略是:
-
老板(中断)发起要求时,如果你(内核)手头空闲,则为老板(中断)服务。
-
如果老板(中断)发起要求时,你(内核)正在为客户(异常包括系统调用)服务,则你(内核)停止为客户(异常)服务,开始为老板(中断)服务。
-
如果老板1(中断1)发起要求时,你(内核)正在为老板2(中断2)服务,那么你(内核)停止为老板2(中断2)服务,开始为老板1(中断1)服务。
-
老板1(中断1)发起要求,你(内核)原本在为客户1(异常1)服务,然后停止,去为老板1(中断1)服务完成,服务完成后,你(内核)没有选择原来的客户1(异常1)继续服务,而是挑选了一个新的客户2(异常2)开始服务。
你的服务就对应于CPU处于内核态时所执行的代码。老板们的请求就是中断,客户们的请求就是异常(这里的异常是用户态进程系统调用和普通的异常的统称)。
2.1.2 抢占
内核分为抢占式和非抢占式,Linux kernel 2.6之后就可以配置选择抢占还是非抢占。
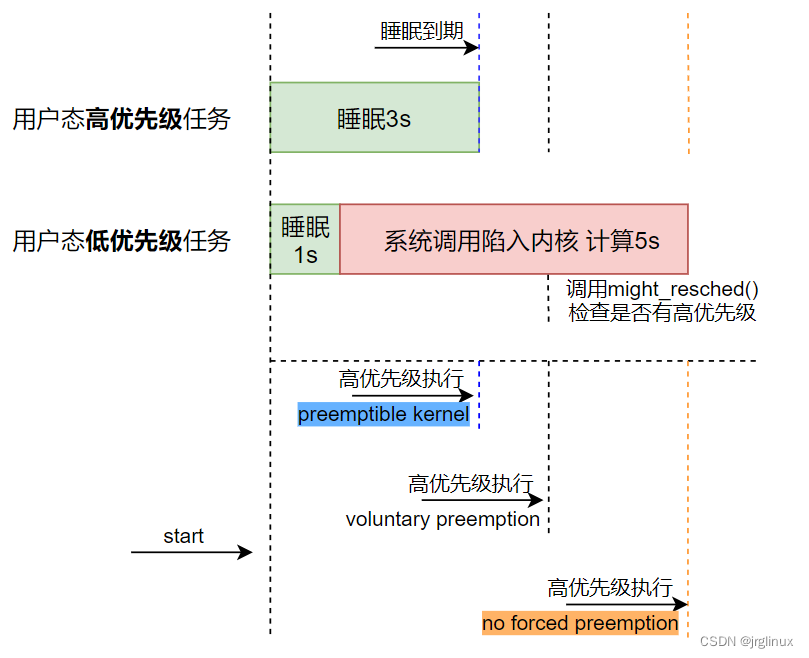
| 抢占模式 | 理解 |
|---|---|
| No Forced Preemption | 上下文切换发生在系统调用返回用户空间的点,不会在内核空间主动抢占 |
| Voluntary Kernel Preemption | 与“no forced”模式类似,但内核开发者可以在进行复杂操作时时不时检查下是否可以reschedule,比如cond_resched()来检查系统是否有更高优先级的任务被唤醒 |
| Preemptible Kernel | 内核里面也可以抢占,系统会有更多的上下文切换,实时性更好,对软实时系统,该选项最佳 对服务器系统,CPU会有一定时间做上下文切换“无用功”,此时就不如no forced |
| Fully Preemptible Kernel | 硬实时系统,除了少数选定的关键部分之外,所有内核代码都是可抢占的 |
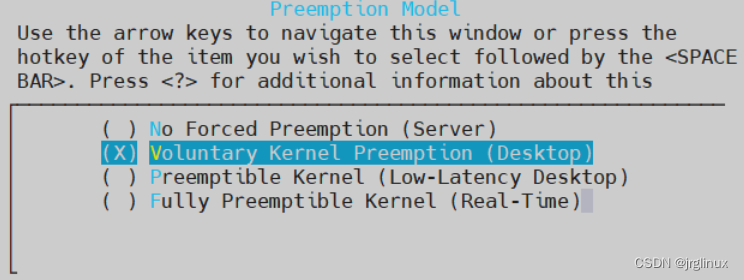
Linux内核中抢占注意点
无论是抢占模式还是非抢占模式,运行中的内核态进程都可以主动放弃CPU,比如进程需要等待资源而不得不转入睡眠状态,因为主动放弃CPU而产生的进程切换叫做计划性进程切换。而抢占模式下,内核在响应引起进程切换的异常事件(比如唤醒高优先级进程的中断处理程序)的方式上与非抢占模式下的进程切换有区别,叫做强制性进程切换。
所有的进程切换都有宏switch_to()来完成。非抢占模式下,当前正在运行的内核态进程除非它自己放弃CPU,否则不会发生进程切换(就没有所谓的时间片概念了)。
2.1.3 何时同步必需
进入临界区内,必须采取保护措施。
2.1.4 何时同步非必需
-
中断处理程序和tasklet不必编写成可重入的函数。
-
仅被软中断和tasklet访问的per cpu变量不需要同步。
-
仅被一种tasklet访问的数据结构不需要同步。
3. RCU介绍
3.1 是什么
Linux kernel document中解释:
RCU背后的基本思想可以分为removal(删除)和reclamation(回收)来理解。
removal:删除对旧数据的指针引用,同时还允许readers读访问旧数据。
reclamation:释放旧数据,必须是在没有读者还指向该旧数据之后才能释放回收。
RCU中updater可以立即实施removal操作,然后等到在removal操作期间的active readers都完成了读操作再来实施reclamation操作,等待的方法一般由两种:1. 阻塞直至所有readers完成;2. 设置callback函数来等待readers完成然后通知。这里只需要考虑removal过程中依然还是active状态的readers,因为在removal操作之后再来进行读操作的readers已经不能访问到旧数据,也就不能进行reclamation释放操作。
所以经典的RCU更新时序是:
-
删除指向数据的指针,这样后续readers就不能再指引到它。
-
等待所有之前还指引到数据的reader完成RCU的read-side操作。
-
在没有reader还指向数据后,释放到该数据。
通俗的理解:RCU机制中记录了指向共享数据的指针的所有使用者,在该数据需要改变时,先创建一个副本,在副本中修改。等待所有读者使用者结束对旧数据的读取之后,指针替换为指向新的、修改后的副本的指针,释放旧数据。 RCU机制允许读写并发。
3.1.1 RCU约束
RCU性能好,但也有一些约束:
-
对共享资源的访问主要是只读,写访问相对较少。
-
RCU保护的代码范围内,内核不能进入睡眠状态。
-
RCU保护的资源必须通过指针访问。
3.2 解决什么
是一种同步问题解决方案。
在内核代码编程中,要时刻有一个意识:任意一条执行流,都有可能在任意一条指令之后被中断,然后再执行时是不确定的时间之后。
这就会引出一个问题:被中断之后,再回到断点开始执行时,前后的依赖环境是否发生了变化?
进一步简化该问题:指令执行所依赖的环境是独享还是共享?,独享则安全,共享则可能被意外修改而引发同步问题。
那么,遇到同步问题,怎么办?
你可能直接说出来了,那就是加锁,对共享资源上锁。
3.2.1 同步问题的本质
同步问题的产生本质是共享与同时,共享顾名思义就是数据会被共同访问,不管是读还是写。同时并不是指同一个时间点,而是说A在某项工作还未做完的情况下(这可能是一段时间,因为代码执行中间可能会被中断然后切走),B也需要去参与进来访问共享资源,这就视为同时。
只要破坏共享或者同时,就可解决同步问题。
内核中的同步技术有
| 技术 | 说明 | example code |
|---|---|---|
| per CPU变量 | 在CPU之间复制数据结构 | per_cpu(name, cpu) |
| 原子操作 | 对一个计数器原子地“读-修改-写”的指令 | atomic_add(i, v) |
| 内存屏障 | 避免指令重新排序 | wmb() |
| 自旋锁 | 加锁时忙等 | spin_lock() |
| 信号量 | 加锁时阻塞等待(睡眠) | struct semaphore内核信号量对象 |
| 顺序锁 | 基于访问计数器的锁 | write_seqlock() |
| 禁止本地中断 | 禁止本地CPU上的中断处理 | local_irq_disable() |
| 禁止本地软中断 | 禁止本地CPU上的可延迟函数处理 | local_bh_disable()给本地CPU的软中断计数器加1,这样do_softirq()就不会执行软中断 |
| RCU | 通过指针而不是锁来访问共享数据 | rcu_read_lock() |
3.2.2 经典的spinlock
spinlock在无法获取锁的时候会自旋等待,其有特征:
- spinlock持锁是关闭抢占的,但不一定关闭中断,也就是说在spinlock临界区中,不会出现进程调度,但是可能出现进程环境的切换比如中断、软中断
如何深入思考spinlock的实现原理,发现一个矛盾点:spinlock的作用是对共享数据进行互斥保护,当一个访问者进入临界区后其他访问者只能等待。但是要做到当一个访问真进入临界区后其他访问者等待需要依赖线程之间的通信,这就是矛盾点:
spinlock中,等待着要知道锁已经被占用,也必须访问某个共享的资源才能获取这个信息,实现spinlock就要依赖对另一个共享资源的同步问题,谁来实现?
软件无法实现,就得靠硬件实现,对于每个不同的硬件架构至少需要实现对单字长变量的原子操作执行,比如64位平台,硬件必须支持一类或一组指令能保证对一个变量执行如++操作时是原子操作。
int main(int argc, char *argv[])
{
400536: 55 push %rbp
400537: 48 89 e5 mov %rsp,%rbp
40053a: 89 7d ec mov %edi,-0x14(%rbp)
40053d: 48 89 75 e0 mov %rsi,-0x20(%rbp)
int i = 0;
400541: c7 45 fc 00 00 00 00 movl $0x0,-0x4(%rbp)
i++;
400548: 83 45 fc 01 addl $0x1,-0x4(%rbp)
return 0;
40054c: b8 00 00 00 00 mov $0x0,%eax
}
如果是变量i是volatile(每次从内存重新读取,而不是使用寄存器中的值)类型呢?
int main(int argc, char *argv[])
{
400536: 55 push %rbp
400537: 48 89 e5 mov %rsp,%rbp
40053a: 89 7d ec mov %edi,-0x14(%rbp)
40053d: 48 89 75 e0 mov %rsi,-0x20(%rbp)
volatile int i = 0;
400541: c7 45 fc 00 00 00 00 movl $0x0,-0x4(%rbp)
i++;
400548: 8b 45 fc mov -0x4(%rbp),%eax
40054b: 83 c0 01 add $0x1,%eax
40054e: 89 45 fc mov %eax,-0x4(%rbp)
return 0;
400551: b8 00 00 00 00 mov $0x0,%eax
}
由此可见,对于共享数据的竞争变成了对锁的竞争,对锁的竞争实际上是对锁变量的竞争,本质上市将复合数据的保护收敛成单字长变量的保护,通过硬件的原子指令来解决该问题。
但是,是药三分毒,锁是一剂解决同步问题的猛药,它就有它的"副作用":
-
死锁、饿死问题可能导致系统直接挂掉;
-
锁只是缓解竞争,不是根治,在锁激烈竞争条件下系统性能开销依旧不小;
-
锁的实现越来越复杂,其本身也会消耗指令周期和cache空间,且这种复杂度让问题越来越难量化分析;
-
不同锁机制的实现,可能有其自身的问题;比如spinlock会带来cpu空转,假设4个cpu同时竞争一个spinlock,因为关闭抢占,这4个cpu只能处理中断和空转,其他不能处理,浪费cpu资源;
3.2.3 场景方案
通用的锁方案无法更进一步时,一个创新方向就是分拆场景,寻找特定场景下的针对性解决方案。
3.2.3.1 锁的延续
继续沿用锁的形式,但区分读写,因为读写的性质完全不一样,从用户角度看,读和写都是访问者,从硬件角度看,读和写的操作有本质区别,通常写操作才是带来同步问题的罪魁祸首,比如两个访问者都是仅读操作共享数据,没问题,但两个访问者都是写操作共享数据,那就会有同步问题。OS既然可以在多读少写的场景中,基于spinlock、mutex等衍生出rwlock、rwsem等机制。
3.2.3.2 无锁设计
放弃同步机制
某些场景下,干脆放弃同步机制或者最小化使用同步机制,对于共享资源不加锁也是能接受的。
-
比如/proc/目录下的节点变量,即使存在同时读写,也不一定会有bug,该设置对应内核中的一个全局变量,而内核代码只会读取该变量,这种情况不加同步措施(或者之加编译器屏障),通常也只会造成短时间内的读者读到旧值的问题,通常不会产生严重的bug。
-
再比如,对于下图中的同时写,特定场景中不加锁也没问题。线程A和线程B同时操作变量cnt,尽管A和B都执行了cnt++,但是B的操作被覆盖了,两次++最终结果只有一次++的结果,理论上这一定是有问题的。但是在诸如统计网络包的时候,这种情况的发生概率较小,和加锁带来的巨大性能损失相比,统计值上的微差也不是不能接受,可以只加一个WRITE_ONCE来限制编译器优化。
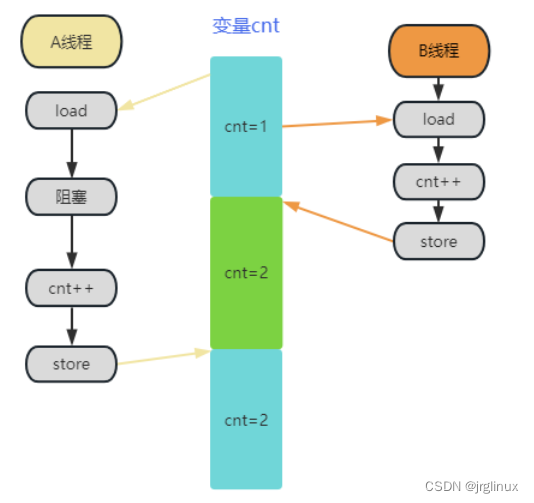
所以,能否放弃同步机制,在了解了特定场景下同步措施带来的性能损失与同步措施解决的问题等等情况后,可以做出权衡。
二次确认
如果共享数据的并发访问概率足够低,直接加锁可能没有必要,可以直接无锁操作,然后对操作结果检查,如果不符合预期,再重新执行一遍操作,以期正确的结果。
percpu机制
perCPU变量也是一种解决了同步问题的方案,它破坏的是"共享"这个条件,将原本CPU之间共享的数据分散到每个CPU一份,这样虽然会存在进程环境和中断环境的同步问题,但却极大降低了多CPU之间的同步问题,从多核问题收敛到单核问题
RCU机制
RCU机制也是特定场景下的一种无锁方案。内核中RCU有多种实现,比如tiny rcu和tree rcu两种,tiny rcu一般用于小型系统、嵌入式系统,tree rcu用于多核CPU、桌面系统、服务器以及安卓等。
3.2.4 RCU机制
3.2.4.1 grace period
RCU机制的宽限期(grace period)是什么?
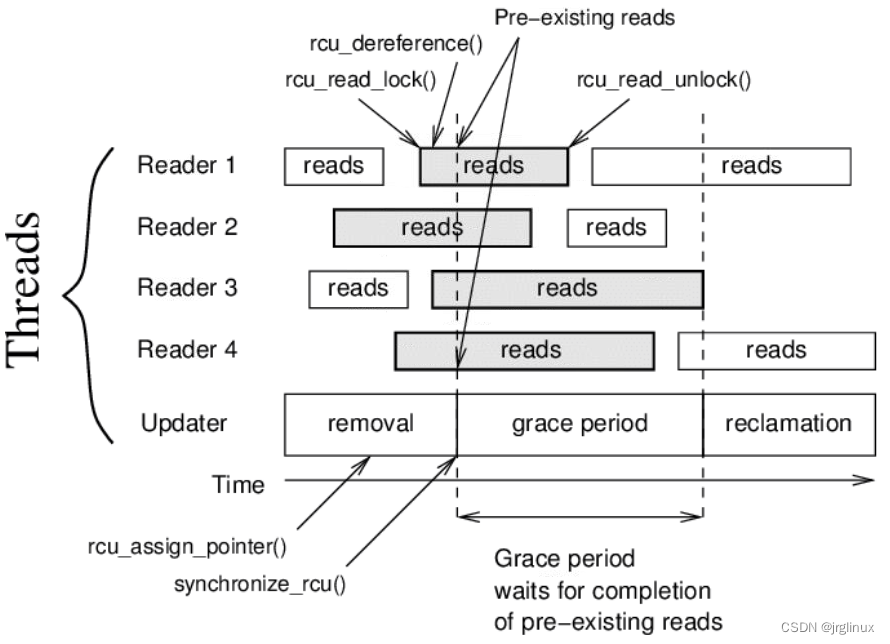
RCU机制中被保护的指针动态数据的removal和reclamation之间是有一定的时间期限的,这个时间就叫grace period(宽限期)。看上图,updater必须等待所有在宽限期开始之前就已经进入RCU临界区的线程都退出后,才能进行reclamation操作,因为如果不等待这批线程退出直接就kfree()掉那这些线程就可能会访问已经被释放的指针而出错。
4. RCU使用
4.1 core API
RCU机制中有许多API,不过核心的API可以列举下面5个,其他的API可以由它们扩展而来。
void rcu_read_lock(void)
void rcu_read_unlock(void)
void synchronise_rcu(void)
rcu_assign_pointer(p, v)
rcu_dereference(p)
4.1.1 rcu_read_lock()
static __always_inline void rcu_read_lock(void)
{
__rcu_read_lock();
__acquire(RCU);
rcu_lock_acquire(&rcu_lock_map);
RCU_LOCKDEP_WARN(!rcu_is_watching(),
"rcu_read_lock() used illegally while idle");
}
static inline void __rcu_read_lock(void)
{
preempt_disable();
}
用于reader进入RCU读临界区,经典RCU中,在读临界区内,线程是不能睡眠的(原因和rcu_read_lock()的实现有关,其实现是通过关闭抢占,关闭抢占就不能发声抢占调度,所以如果进入睡眠就可能睡死了),尽管有RCU也有preemptible的实现,kernel编译时打开CONFIG_PREEMPT_RCU这样RCU读临界区内能被抢占,也是不允许在RCU读临界区内阻塞进入睡眠的。
没有rcu_write_lock(),这是RCU机制的特点,也是RCU性能提升的原因,如果读、写都有lock,那就使用spinlock就可以了。
4.1.2 rcu_read_unlock()
reader通知updater它退出了RCU读临界区
static inline void rcu_read_unlock(void)
{
RCU_LOCKDEP_WARN(!rcu_is_watching(),
"rcu_read_unlock() used illegally while idle");
__release(RCU);
__rcu_read_unlock();
rcu_lock_release(&rcu_lock_map); /* Keep acq info for rls diags. */
}
static inline void __rcu_read_unlock(void)
{
preempt_enable();
if (IS_ENABLED(CONFIG_RCU_STRICT_GRACE_PERIOD))
rcu_read_unlock_strict();
}
4.1.3 synchronize_rcu() / call_rcu()
用来判断宽限期是否已经到了,换句话说就是判断再进入grace period之前已经在RCU读临界区内的reader是否都退出了。可以参考grace period那张图。
看下面这个时序图,CPU1是updater,CPU0和CPU2是reader,CPU1进入grace period之前,只有CPU0已经进入RCU读临界区内了,所以CPU1只需要等待CPU0退出RCU读临界区,便可以从synchronize_rcu()返回,结束grace period,去进行reclamation旧数据操作,而不必管CPU2还没有退出RCU读临界区,因为CPU2是在CPU1已经进入grace period之后才进入RCU读临界区,已经读取的是新数据。
CPU 0 CPU 1 CPU 2
----------------- ------------------------- ---------------
1. rcu_read_lock()
2. enters synchronize_rcu()
3. rcu_read_lock()
4. rcu_read_unlock()
5. exits synchronize_rcu()
6. rcu_read_unlock()
synchronize_rcu()是可以blocking的,call_rcu()是synchronize_rcu()的一种异步实现,其不阻塞,而是通过注册一个回调函数,在所有的需要被等待的reader退出读临界区后,被调用。
4.1.4 rcu_assign_pointer()
updater用来assign一个新的指针,替换原来的被RCU保护的旧指针。通过宏定义实现,为的是在updater和reader之间安全地交互。
#define rcu_assign_pointer(p, v) \
do { \
uintptr_t _r_a_p__v = (uintptr_t)(v); \
rcu_check_sparse(p, __rcu); \
\
if (__builtin_constant_p(v) && (_r_a_p__v) == (uintptr_t)NULL) \
WRITE_ONCE((p), (typeof(p))(_r_a_p__v)); \
else \
smp_store_release(&p, RCU_INITIALIZER((typeof(p))_r_a_p__v)); \
} while (0)
4.1.5 rcu_dereference()
与rcu_assign_pointer()一样必须通过宏定义实现。reader通过该API来获取一个被RCU保护的指针。
rcu_dereference()并不是真的去解引用一个指针,而是从复制RCU-protected pointer至本地变量,通过调用rcu_dereference()是为了方便后面真正的去dereference它。
比如
p = rcu_dereference(head.next);
return p->data;
rcu_dereference()获取的RCU变量作用域必须是在一次RCU读临界区内使用,不能在临界区外使用,如
rcu_read_lock();
p = rcu_dereference(head.next);
rcu_read_unlock();
x = p->address; /* BUG!!! */
rcu_read_lock();
y = p->data; /* BUG!!! */
rcu_read_unlock();
4.2 代码示例
4.2.1 updater阻塞
struct foo {
int a;
char b;
long c;
};
DEFINE_SPINLOCK(foo_mutex);
struct foo __rcu *gbl_foo;
void foo_init()
{
struct foo *p = NULL;
p = kmalloc(sizeof(struct foo), GFP_KERNEL);
p->a = 1;
p->b = 2;
p->c = 3;
rcu_assign_pointer(gbl_foo, p);
}
void foo_update_a(int new_a)
{
struct foo *new_fp;
struct foo *old_fp;
new_fp = kmalloc(sizeof(*new_fp), GFP_KERNEL);
spin_lock(&foo_mutex);
old_fp = rcu_dereference_protected(gbl_foo, lockdep_is_held(&foo_mutex));
*new_fp = *old_fp; //拷贝旧数据到新内存
new_fp->a = new_a; //写操作,更新数据
rcu_assign_pointer(gbl_foo, new_fp); //更新gbl_foo指向新内存
spin_unlock(&foo_mutex);
synchronize_rcu(); //阻塞等待宽限期
kfree(old_fp); //释放旧内存
}
int foo_read_a(void)
{
int retval;
rcu_read_lock();
retval = rcu_dereference(gbl_foo)->a;
rcu_read_unlock();
return retval;
}
代码中展现了用RCU保护一个指向动态分配空间的全局指针。updater动态创建new_fp,与原来的全局变量指针gbl_foo所指的对象类型一样,然后设置new_fp->a=new_a,做了个写操作(通过rcu_dereference_protected()来获取的RCU保护变量gbl_foo),然后通过rcu_assign_pointer()来更新gbl_foo指向new_fp指向的对象,保证reader还能通过gbl_foo访问到数据,最后通过synchronize_rcu()来等待宽限期,等到宽限期之前所有的reader都退出读临界区后,synchronize_rcu()返回,然后来reclamation旧数据,kfree()释放。
可以看出,updater之间也有同步竞争问题,这里是通过spinlock来解决的,这里的RCU是解决reader与updater之间的同步竞争问题,使得reader不用管是否有人在写,直接读即可。
问题:kfree()释放的是kmalloc()分配的内存,old_fp何时指向动态分配的内存的?
这里应该是示例代码不全,gbl_foo原本指向的内存空间应该是kmalloc()分配的,这里没写出来,因为是动态分配的,才可以用kfree(old_fp)来释放旧内存空间。
使用方法总结:
-
reader通过rcu_read_lock()和rcu_read_unlock()来保护读临界区。
-
reader在读临界区内,通过rcu_dereference()来获取RCU指针变量;updater在写临界区内,通过rcu_dereference_protected()来获取RCU指针变量。
-
updaters之间通过锁、信号量等来解决同步问题。
-
updater通过rcu_assign_pointer()来更新RCU指针变量,注意rcu_assign_pointer()只能保证reader月updater之前没有同步问题,但不能保证多个updaters之间的同步问题,所以该操作需要在临界区内操作,比如用锁来保护。
-
updater通过synchronize_rcu()来等待宽限期结束,然后释放旧数据。
从上面代码例子可以看出RCU机制的两点约束,RCU机制使用场景是读多写少;RCU保护的对象只能是指向动态分配内存,且通过指针访问。
4.2.2 updater非阻塞
上面的例子中,synchronize_rcu()会block,直至grace period结束。但是,如果updater不想阻塞等待怎么办,还有其他事要办。可以使用call_rcu()来替换synchronize_rcu() 的使用。
void call_rcu(struct rcu_head *head, rcu_callback_t func);
call_rcu()函数会在grace period宽限期结束后回调func(head),需要注意的是func(head)要么是软中断要么是进程上下文中来调用,所以func(head)函数中不能阻塞blocking。
如果使用call_rcu(),则需要做一些修改:
- 需要再struct foo中添加struct rcu_head rcu变量。
struct foo {
int a;
char b;
long c;
struct rcu_head rcu;
};
- foo_update_a()函数也需要稍加修改
void foo_update_a(int new_a)
{
struct foo *new_fp;
struct foo *old_fp;
new_fp = kmalloc(sizeof(*new_fp), GFP_KERNEL);
spin_lock(&foo_mutex);
old_fp = rcu_dereference_protected(gbl_foo, lockdep_is_held(&foo_mutex));
*new_fp = *old_fp;
new_fp->a = new_a;
rcu_assign_pointer(gbl_foo, new_fp);
spin_unlock(&foo_mutex);
call_rcu(&old_fp->rcu, foo_reclaim);
}
void foo_reclaim(struct rcu_head *rp)
{
struct foo *fp = container_of(rp, struct foo, rcu);
kfree(fp);
}
这里设置call_rcu()的回调函数为foo_reclaim()来做回收处理。
如果call_rcu()中只是调用kfree()来释放旧数据,也可以直接使用kfree_rcu()来代替call_rcu()
kfree_rcu(old_fp, rcu);
5. RCU核心特征
5.1 读临界区
5.1.1 grace period理解
RCU中通过rcu_read_lock()和rcu_read_unlock()之间来保护读临界区,其是如何实现的?
通过看代码,你会发现,经典RCU中rcu_read_lock()仅仅是关了一下抢占,preempt_disable(),会不会好奇,像以往的自旋锁之类,要保护临界区,怎么也得上个锁吧,怎么RCU只要关一下抢占就进入读临界区了?
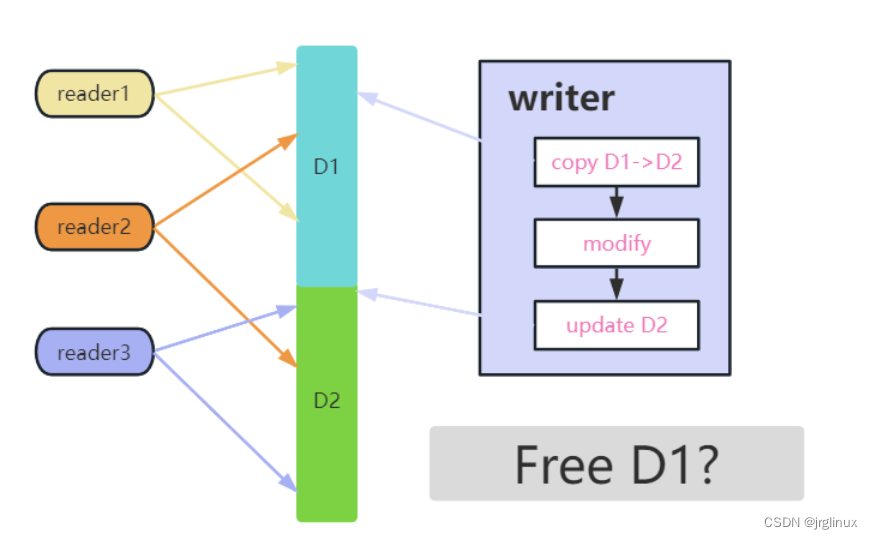
上图中存在三个reader,updater(writer)先是从D1拷贝一份到D2,然后写操作,最后update更新D2,在这个过程中,reader3是一开始就读到了新数据,所以这里不用管,而reader1一直读的旧数据,它下次再读时就是读新的数据了,所以也不用管,reader2就麻烦,reader2是开始读的旧数据D1,然后updater更新到D2时(grace period开始),reader2还没读完,那么此时updater虽然更新完了D2新数据,但还不能立即删除旧数据D1,因为reader2还在读旧数据,所以updater必须等reader2读完之后,才能删除旧数据,这个等待时间就是grace period宽限期。
5.1.2 开关抢占
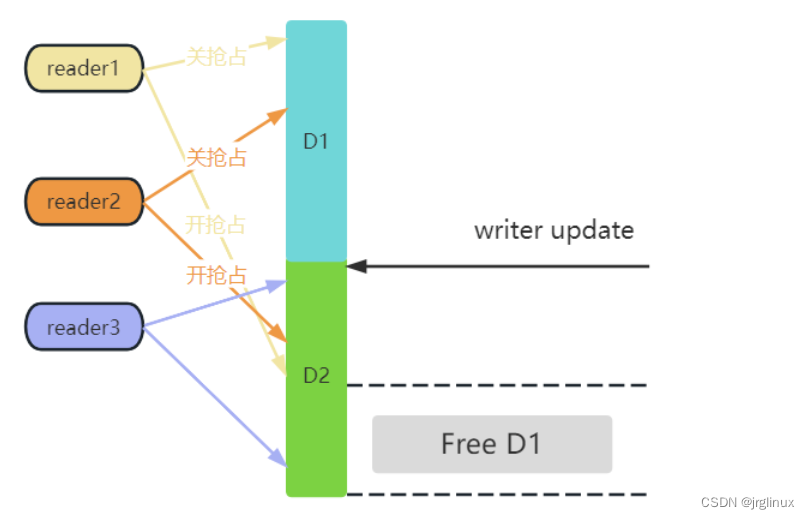
参考上图,这个图中reader3一直读的新数据D2,不用管。reader1和reader2在updater更新新数据之前就开始读旧数据,所以updater必须等reader1和reader2退出才能释放旧数据。而reader的读临界区是通过关抢占进入的,退出读临界区是开抢占的,关闭抢占意味着在读临界区这段时间内,该CPU上不会发生抢占性进程调度,所以updater要判断reader1有没有读完数据退出读临界区,只要判断reader1所在CPU上有没有发生一次进程调度即可(即使是reader1主动退出发生非抢占性调度,那也说明reader1读完退出了),这样通过开关抢占就能实现保护读临界区的问题,而不用再额外通过锁机制来实现,最大化了读端的性能,并且读端不用管是否有写端在进行写操作,只管读就是。
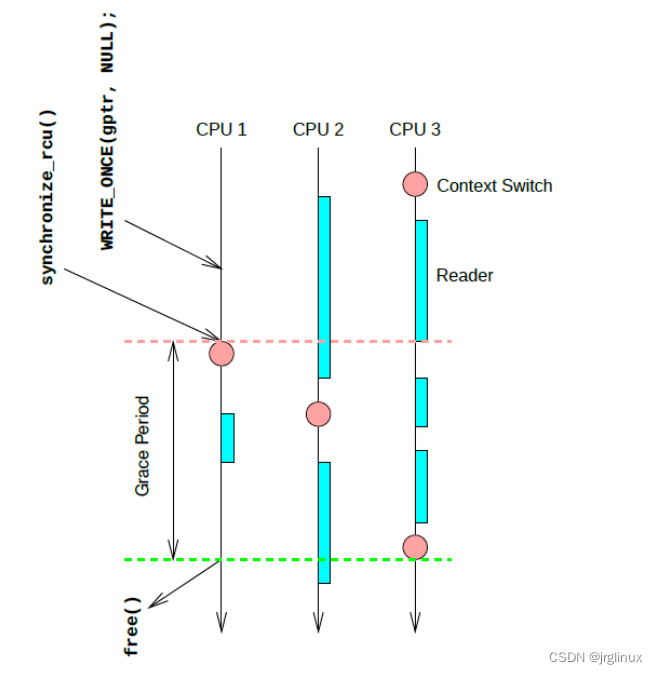
上图是一个简单的示例,updater在CPU1上更新数据,调用synchronize_rcu()进入grace period,开始等待所有reader退出后才能释放旧数据,而调用synchronize_rcu()会阻塞然后立即触发一次非抢占性进程调度,而此时CPU2上的reader还没有读完,等reader2读完后,CPU2上发生了一次进程调度,说明发生了进程切换,reader2在进入grace period之前的读操作完成了。再看CPU3上,reader3进退读临界区3次之后才发生了一次进程调度,updater便可以判断reader3在进入grace period之前的读操作绝对完成了。此时grace period结束,updater可以释放旧数据了。
从上面的例子可以看出,RCU也有几点特征:
-
RCU针对读多写少的场景。
-
RCU中写端有一定延迟,宽限期内,有的读端拿的新数据,有的还拿的旧数据,也是一种延迟。
-
RCU中updater删除旧数据有延迟,并不是更新完新数据后立即删除旧数据,而是要等到grace period结束才能删除旧数据。
-
RCU保护的对象不能是复合结构,只能是指针,如果是复合结构,新数据会直接覆盖旧数据,读端可能就发生错误。
-
RCU机制追求的是读端极致性能,这是内核中的场景创新。
-
经典RCU中读临界区是通过开-关抢占来实现的,性能及多核扩展性非常好,但这也导致读临界区内不支持抢占和睡眠。
5.2 写临界区
5.2.1 updater如何感知进程调度
对于经典RCU中可以设计通过perCPU变量来时updater感知所有CPU是否完成了一次进程调度。
在较新的linux kernel代码中,为了减少grace period,减少延迟,加快释放旧数据内存,synchronize_rcu()可以通过IPI中断来触发CPU发生一次中断,其原理可以写成如下:
for_each_online_cpu(cpu)
run_on(cpu);
这里的run_on(cpu)将当前线程绑定到指定CPU去执行,这样就能在该CPU上强制发生一次进程调度切换,这样就可以保证所有的grace period之前进入RCU read-side critical sections的reader都退出。该方法适用于RCU读临界区类禁止抢占的内核(非抢占内核和抢占内核都可以,因为是中断触发),但不适用于实时抢占内核,realtime rcu有另外的实现。
6. 参考文献
-
Linux kernel document – what is RCU
-
内核工匠 – RCU前传
-
LWN – the design of preemptible RCU
-
Linux kernel 6.0.9 source code