一.常用的 hadoop shell
文件路径需要自己有才行,示例中的文件路径是本人自己的文件路径,不是公共文件路径,如何建立自己的数仓,查看本人 大数据单机学习环境搭建 相关文章
1.1查看 创建 删除
# 列出当前hdfs所存贮的文件
hadoop fs -ls /
# user下的所有内容
hadoop fs -ls -R /user
# user下级目录的内容
hadoop fs -ls -h /user
# 创建文件
hadoop fs -mkdir /abc
# 创建多级目录
hadoop fs -mkdir -p /abc/mm/ff
# 把/abc目录下面的123.txt文件删除掉
hadoop fs -rm -r /abc/123.txt
1.2上传 查看 下载
# 上传/home/caw/demo_test_data.txt文件到/user/hive/warehouse/demo.db/test文件夹下
hadoop fs -put /home/caw/demo_test_data.txt /user/hive/warehouse/demo.db/test
# 小文件合并,本地2.txt 3.txt,合并上传到hdfs的1.txt
hadoop fs -appendToFile 2.txt 3.txt /1.txt
# 查看文件000000_0的内容
hadoop fs -cat /user/hive/warehouse/demo.db/test/000000_0
# 文件下载到/home/caw/桌面/test.txt
hadoop fs -get /user/hive/warehouse/demo.db/test/000000_0 /home/caw/桌面/test.txt
# test下面有两个文件分别为000000_0 和demo_test_data.txt ,我们想同时下载两个文件,并且下载到本地的时候自动将两个文件合并
hadoop fs -getmerge /user/hive/warehouse/demo.db/test/000000_0 /user/hive/warehouse/demo.db/test/demo_test_data_copy_1.txt /home/caw/桌面/test.txt
1.3修改 复制
# abc目录下面的abc1.txt移动到/abc/mm下面
hadoop fs -mv /abc/abc1.txt /abc/mm
# 把demo_test_data_copy_1.txt.txt改个名字叫000000_1
hadoop fs -mv /user/hive/warehouse/demo.db/test/demo_test_data_copy_1.txt /user/hive/warehouse/demo.db/test/000000_1
# 把刚才的/abc/mm/123.txt给复制到/abc下面
hadoop fs -cp /abc/mm/123.txt /abc
1.4权限修改
# 修改文件的权限
hadoop fs chmod 文件权限 文件
hadoop fs -chmod -R 777 /user/hive/warehouse/tms_app.db/cust_id_tb
1.5文件监听
# 监听文件
hadoop fs -tail -f
# 监听的必须是文件不能是文件夹
hadoop fs -tail -f /user/hive/warehouse/null_demo/null_demo.txt
1.6更多方法
hadoop fs -help查看更多用法
hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum [-v] <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-concat <target path> <src path> <src path> ...]
[-copyFromLocal [-f] [-p] [-l] [-d] [-t <thread count>] [-q <thread pool queue size>] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-crc] [-ignoreCrc] [-t <thread count>] [-q <thread pool queue size>] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] [-e] [-s] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] [-t <thread count>] [-q <thread pool queue size>] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] [-v] [-x] <path> ...]
[-expunge [-immediate] [-fs <path>]]
[-find <path> ... <expression> ...]
[-get [-f] [-p] [-crc] [-ignoreCrc] [-t <thread count>] [-q <thread pool queue size>] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-head <file>]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [-e] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] [-d] [-t <thread count>] [-q <thread pool queue size>] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] [-s <sleep interval>] <file>]
[-test -[defswrz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touch [-a] [-m] [-t TIMESTAMP (yyyyMMdd:HHmmss) ] [-c] <path> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
二.一个小案例
本节内容以SQL使用技巧(5)NULL值和空值的重要说明的数据构造为例,展示hadoop shell的 查看ls、上传put、删除rm 、内容展示cat 等 hadoop fs 操作
2.1Hive建表
location位置非常关键,直接决定Hive能否通过metastore的源信息找到HDFS文件并成功解析
create table null_demo(
id bigint,
name string,
age int,
city string,
address string,
notes string)
row format DELIMITED
fields terminated by ','
;
验证建表
hadoop fs -ls /user/hive/warehouse

2.2上传数据
将数据put到hadoop,存为HDFS
hadoop fs -put /home/null_demo.txt /user/hive/warehouse/null_demo

2.3sed流编辑器替换
替换文本中的单引号 sed -i "s?'??g" /home/null_demo.txt
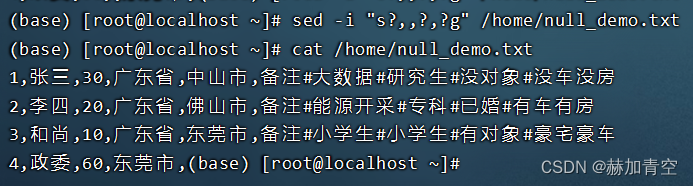
2.4删除错误数据的文件
删除错误数据,重新上传替换单引号后的文件
hadoop fs -rm -r /user/hive/warehouse/null_demo/null_demo.txt
hadoop fs -ls /user/hive/warehouse
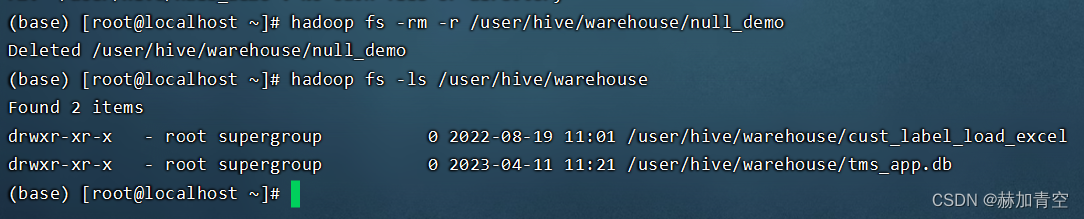
重新上传修改后的文本
hadoop fs -put /home/null_demo.txt /user/hive/warehouse/null_demo
2.5查看HDFS文件内容
hadoop fs -cat /user/hive/warehouse/null_demo/null_demo.txt

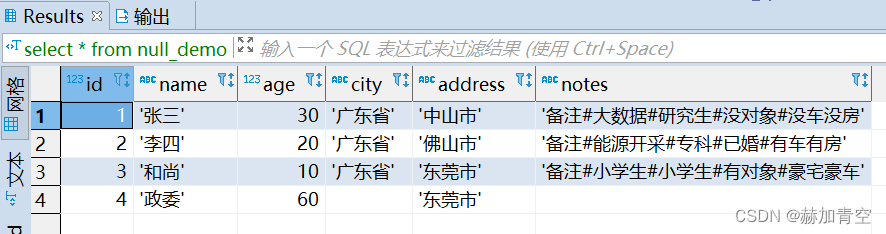
2.6Hive查询结果验证
select * from null_demo;
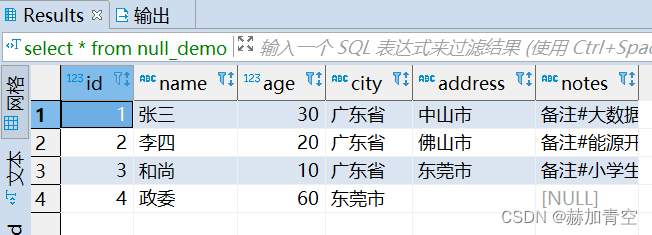
2.7小文件的get方法
未完待续
声明:本文所载信息不保证准确性和完整性。文中所述内容和意见仅供参考,不构成实际商业建议,可收藏可转发但请勿转载,如有雷同纯属巧合