摘要:数据治理中经常要遇表或者字段级“血缘分析”和“影响分析”,但是真正在数据ETL调度操作过程中使用影响和血缘分析频繁,看白鲸开源的WhaleStudio如何解决这个难题。
提到“血缘分析”和“影响分析”,普通开发者第一印象就是数据治理当中的表分析或者字段级分析,用于分析表某一个字段或者某一个指标出现问题的时候数据质量的溯源。这是一个非常普遍的功能,但是发现数据质量有问题的表之后,如何处理呢?一定会回到数据处理系统当中进行重跑或者修改跑处理相关的数据,而哪些作业涉及到这个表的数据处理呢?这其实就需要用到调度系统中的“血缘分析”和“影响分析”了。
所以,我们往往说,数据治理的“血缘分析”和“影响分析”是给业务人员和数据分析师使用的,而数据调度中的“血缘分析”和“影响分析”是给数据工程师使用的。
在白鲸开源的WhaleScheduler 2.4.6 版本当中提供的“血缘分析”和“影响分析”就充分考虑到这一点。同时,大家知道WhaleScheduler是白鲸开源主要维护的Apache DolphinScheduler的商业版本,它继承了开源DolphinScheduler强大的工作流和任务调度体系。其中有两种复杂的任务类型,依赖(Dependent)和子工作流(SubWorkflow):
- 依赖任务(Dependent):在一个工作流(Workflow)当中,可以跨项目依赖另外的另外一个工作流的完成或者另外一个任务的完成。同时,这种依赖可以支持复杂依赖关系,例如,日依赖24个小时任务,月依赖31个日任务,几个任务之间存在与或非的各种关系等。
- 子工作流任务(SubWorkflow):顾名思义就是一个任务可以直接引用另外的项目中的一个工作流成为一个子任务,并且可以把当前工作流当中的变量和情况,直接传递给另外一个工作流当中。
这两个任务类型对于调度系统的灵活性非常重要,也得到了开源社区的广泛使用。不过对于工作流的“血缘分析”和“影响分析”则是复杂性非常高。因为这意味着,通过这两个任务,一个工作流可以无限的扩展到其它工作流和任务之间的关系,而其它任务涉及到的工作流又可能依赖更多的其它任务或者有其他子工作流,所以,调度系统中整体的“血缘分析”和“影响分析”是比数据治理中的复杂的多的。
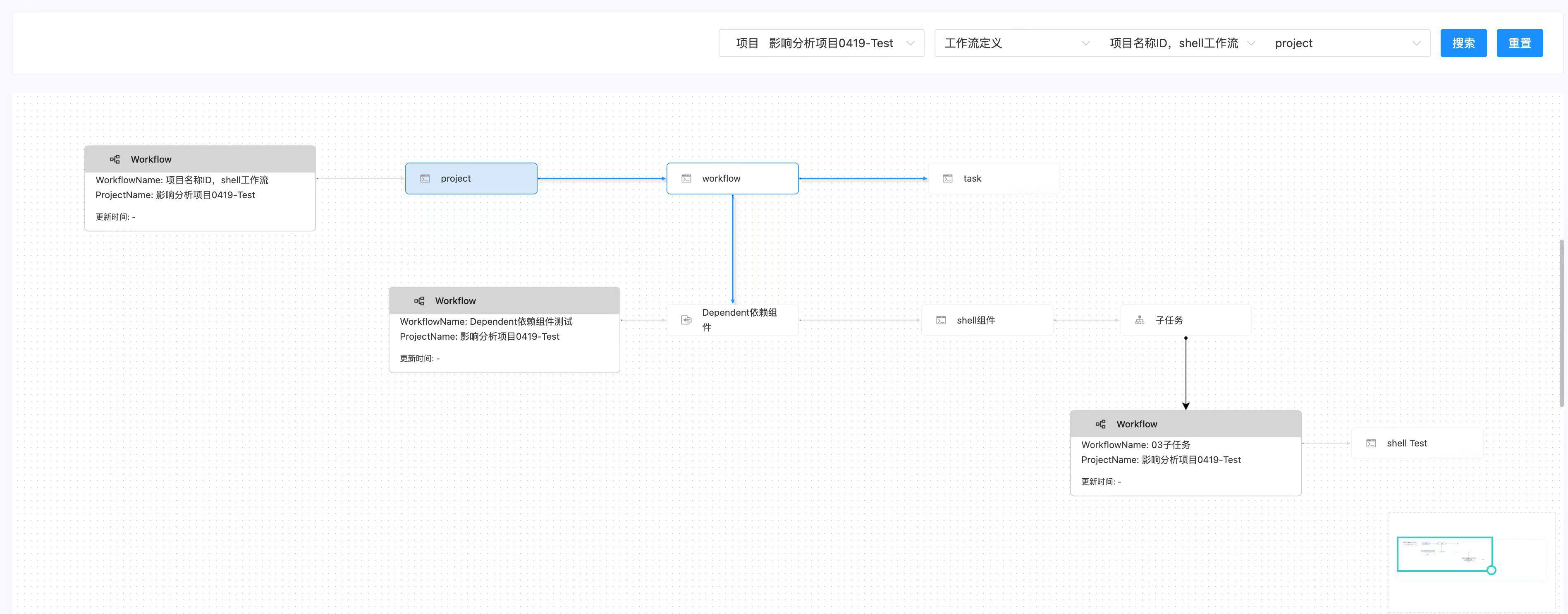
而调度的“血缘分析”和“影响分析”实用性和使用频繁度也是比数据治理中的频繁得多, 因为工作流和任务每天都要跑,如果出错,处理的时候都要看下这个任务的上下游,从而进行更好的运行态的处理。所以,白鲸开源在设计调度系统的“血缘分析”和“影响分析”时不仅仅提供一个静态的模板级别工作流设计里面的依赖和影响,更是可以针对工作流实例和任务实例来进行运行态中的“血缘分析”和“影响分析”,同时运行用户直接在分析的DAG图中,根据实例的状态直接邮件就行运行操作,从而真正帮助到数据工程师提高调试和运维效率。当然因为DolphinScheduler核心非常强大,支持无限子任务和依赖(目前在白鲸开源的商业客户中已有嵌套20层的客户),WhaleScheduler默认会展开上下5层Workflow的依赖和影响分析,用户可以自行上钻和下钻到自己需要的节点。
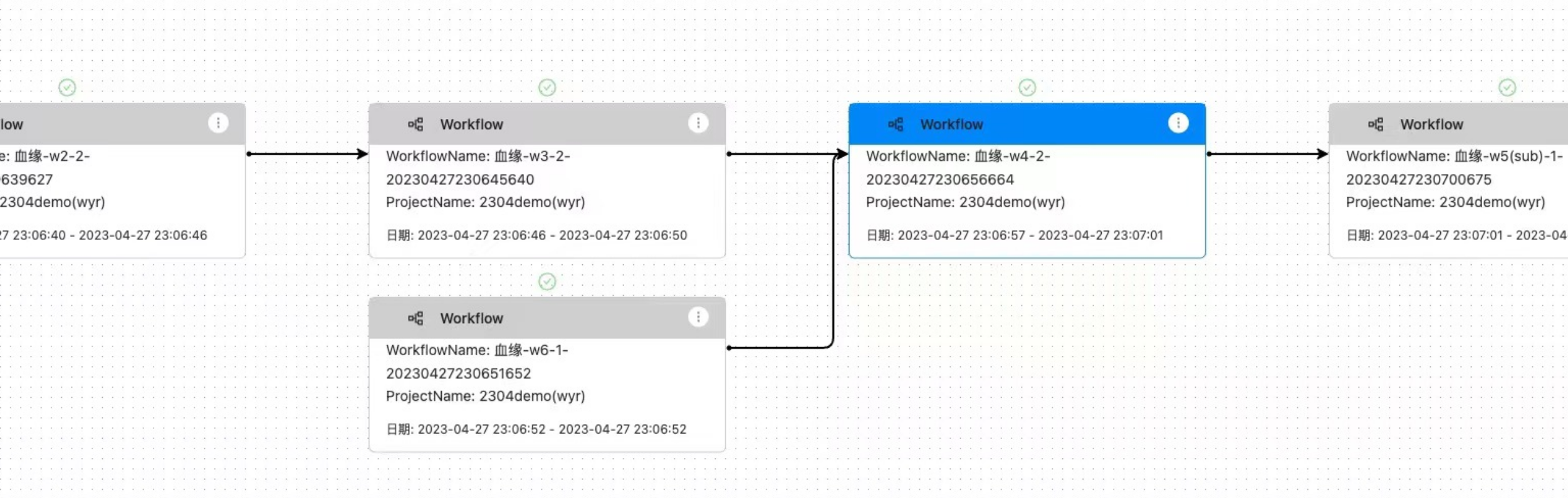
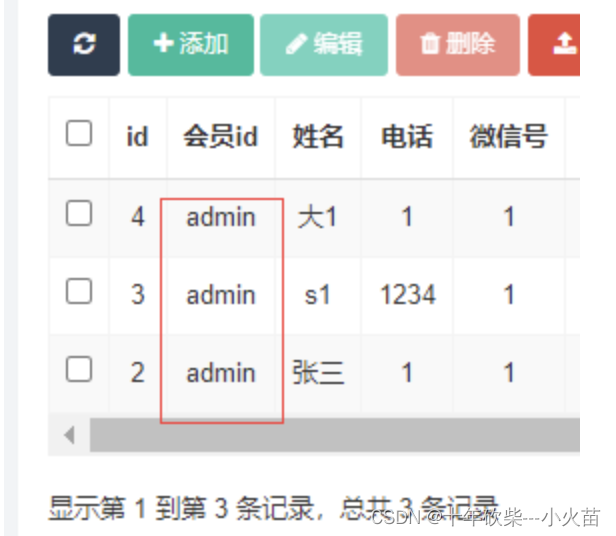
在企业真正使用过程当中,一般一个任务都处理一个表,而任务命名往往也和目标表命名类似,例如,表明DWD_Customer_Info,那么任务名称就是t_DWD_Customer_Info,所以,在表级别数据质量本身出现问题的时候,也可以利用任务的血缘分析来分析表技术质量,同时利用WhaleScheduler强大的运行态管理来任务重跑、工作流重跑、补数、依赖链重跑等多种方式快捷方便的完成数据问题的整理。
综上,调度也需要“血缘分析”和“影响分析”,而且使用频次和方便程度更直接关系到数据工程师的“幸福指数”,究竟无论是DolphinScheduler还是白鲸开源的WhaleScheduler,我们的目标都是让数据工程师们**“工具选的好,下班回家早;调度用的对,半夜安心睡”!**
本文由 白鲸开源科技 提供发布支持!