Linux 常见命令
- Linux 基础命令
- 目录相关
- 查看文件(日志)
- 查看普通的文件
- 查看压缩的文件
- 解压压缩
- Linux 系统调优
- top
- vmstat
- pidstat
- ps
- vi/vim 编辑文件
- 查找文件
- 属性相关
- 定时任务
- scp 复制文件和目录
- awk 分隔
- cut
- sort 与 uniq
- 常见问题处理思路
- CPU 高
- 系统平均负载高(load average)
Linux 基础命令
sudo + 其他命令:以系统管理者的身份执行指令,也就是说,经由 sudo 所执行的指令就好像是 root 亲自执行
grep 在指定数据源中查找指定的数据,这个数据源可以是用户指定的文本文件,也可以是流,因此该命令一般配合管道使用
目录相关
一般使用 cd 来切换目录
cd user: 切换到该目录下 user 目录
cd …(或cd…/): 切换到上一层目录
cd /: 切换到系统根目录
cd ~: 切换到用户主目录
cd -: 切换到上一个操作所在目录,并且显示该目录的绝对路径
用户的主目录是在根目录下的 /home/用户名 这个目录,即 ~ = /home/userName
用 ls 或者 ll 来查看当前目录下的信息
ls(英文全拼:list files): 列出目录及文件名,可以使用 ls -al 来查看更多信息
pwd(英文全拼:print work directory):显示目前的目录
增删改目录
mkdir(英文全拼:make directory):创建一个新的目录
rmdir(英文全拼:remove directory):删除一个空的目录
cp(英文全拼:copy file): 复制文件或目录
rm(英文全拼:remove): 删除文件或目录
mv(英文全拼:move file): 移动文件与目录,或修改文件与目录的名称
查看文件(日志)
一般 Linux 都需要去查看日志文件,这些日志有的是离线的有的是动态的,还有些是压缩的,如何去查看这些文件呢
查看普通的文件
cat:由第一行开始显示内容,并将所有内容输出,如果文件过大,可能会造成性能损耗
tac:从最后一行倒序显示内容,并将所有内容输出
more:根据窗口大小,一页一页的显示文件内容,可以使用 pgdn、空格来翻页,也可以使用回车来一行一行向下翻,使用 q 退出查看
less:和 more 类似,可以查阅大型文本文件,但其优点可以使用 pgup 往前翻页,而且进行可以搜索字符,man 命令解释使用 less 来查看文档的。该命令又以下常用键
- Space 或者 PgDn : 向下移动一页
- b 或者 PgUp : 向上移动一页
- g : 移到文件的开头
- G : 移动到文件的末尾
- q : 退出查看
head:只显示头几行,使用 head -n 20 xxx 来显示 xxx 的前二十行,-n 后面的数字可以是负数,表示除了前二十行其他都显示
tail:只显示最后几行,使用 tail -f 动态查看日志文件
nl:类似于cat -n,显示时输出行号
tailf:类似于tail -f
od:读取二进制文件,以零一格式显示,一般读出来的数据人类都看不懂
查看压缩的文件
使用 zcat 命令查看归档/压缩文件:zcat test.tar.gz
zcat 与 gunzip -c 命令功能相同。因此,你还可以用下面的命令:gunzip -c test.tar.gz
使用 zless 命令查看归档/压缩文件:zless test.tar.gz
同时 less 命令也可以查看压缩文件:less test.tar.gz
zgrep 命令用于不解压过滤压缩包中文本
zgrep test.tar.gz
注意查看日志的时候不要一次性全部打印出来,可能压缩文件或者普通文件中的日志信息太多了,一次性打出来不知道要打到什么时候,而且就算打完了也没办法去看,因为太多了找不到自己需要的信息。因此需要加入限制信息,比如加入自己想找的内容或者打印最后多少多少行
查找想要的内容
Linux 的查看命令不能很好的支持查找想要的内容这一需求,虽然有些命令支持查找数据,比如在 more 中使用 / 加关键字可以跳转到那一行,开始这种查找不能找文件中包含关键字的全部行。因此推荐使用 grep 在文件中搜索关键字
# 查看关键字的上下10行
grep -C 10 'NullPointerException' logback.log
# 查看关键字的上10行
grep -B 10 'NullPointerException' logback.log
# 查看关键字的下10行
grep -A 10 'NullPointerException' logback.log
除了可以查看上下几行以外,它还支持正则表达式,支持与与或(包含 a 的行或者包含 b 的行)
除了搜索功能全面之外,grep 在查找功能上也做了拓展,比如可以一次搜索很多个文件,最常使用的一个场景就是:从大量的文件中找出含有特定字符的文件
我们的搜索需求是,找出内容中含有first单词的文件都有哪些。我们希望得到的是一个文件列表
[roc@roclinux ~]$ grep -l "first" *.txt
1.txt
这里的模糊匹配使用了 * 号,正则表达式中的 * 表示匹配前面的表达式任意次,而数据库查询中模糊查询一般使用百分号“%”和下划线“_”作为通配符
解压压缩
Linux 中的打包文件一般是以.tar 结尾的,压缩的命令一般是以.gz 结尾的。而一般情况下打包和压缩是一起进行的,打包并压缩后的文件的后缀名一般.tar.gz。
命令:tar -zcvf 打包压缩后的文件名 要打包压缩的文件 ,其中:
z:调用 gzip 压缩命令进行压缩
c:打包文件
v:显示运行过程
f:指定文件名
x:代表解压
使用 tar [-xvf] 解压压缩包
可以将文件压缩为其他不同的方式,只需要使用其他的命令即可,比如 bzip2 命令打 zb2 包、gzip 打 gz2 包等
同时解压不同的压缩包使用的命令也不一样,比如解压 bzip2 包需要使用 bunzip2、解压 gz2 需要使用 gunzip 等
Linux 系统调优
top
top 命令用于查看进程各种信息,能实时查看系统中各个进程资源占用情况,比如 CPU、内存使用情况,IO 情况等,使用 top -Hp xxxx 可查看对应进程的线程情况
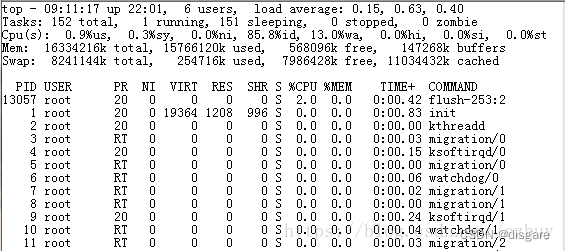
第一行:
当前时间、系统启动时间、当前系统登录用户数目、平均负载(1分钟,10分钟,15分钟)
平均负载(load average),一般对于单个cpu来说,负载在0~1.00之间是正常的,超过1.00须引起注意。在多核cpu中,系统平均负载不应该高于cpu核心的总数
第二行:
进程总数、运行进程数、休眠进程数、终止进程数、僵死进程数。
第三行:
%us用户空间占用cpu百分比;
%sy内核空间占用cpu百分比;
%ni用户进程空间内改变过优先级的进程占用cpu百分比;
%id空闲cpu百分比,反映一个系统cpu的闲忙程度。越大越空闲;
%wa等待输入输出(I/O)的cpu百分比;
%hi指的是cpu处理硬件中断的时间;
%si值的是cpu处理软件中断的时间;
%st用于有虚拟cpu的情况,用来指示被虚拟机偷掉的cpu时间。
第四行:
total总的物理内存;
used使用物理内存大小;
free空闲物理内存;
buffers用于内核缓存的内存大小
第五行:
total总的交换空间大小;
used已经使用交换空间大小;
free空间交换空间大小;
cached缓冲的交换空间大小
buffers 与 cached 区别:buffers指的是块设备的读写缓冲区,cached指的是文件系统本身的页面缓存。他们都是Linux系统底层的机制,为了加速对磁盘的访问。
第六行:
PID 进程号
USER 运行用户
PR
优先级,PR(Priority)所代表的值有什么含义?它其实就是进程调度器分配给进程的时间片长度,单位是时钟个数,那么一个时钟需要多长时间呢?这
跟CPU的主频以及操作系统平台有关,比如linux上一般为10ms,那么PR值为15则表示这个进程的时间片为150ms。
NI 任务nice值
VIRT 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES 物理内存用量
SHR 共享内存用量
S 该进程的状态。其中S代表休眠状态;D代表不可中断的休眠状态;R代表运行状态;Z代表僵死状态;T代表停止或跟踪状态
%CPU 该进程自最近一次刷新以来所占用的CPU时间和总时间的百分比
%MEM 该进程占用的物理内存占总内存的百分比
TIME+ 累计cpu占用时间
vmstat
从名字就可以看出 vmstat 是一个虚拟内存检测工具,用于查看进程的 CPU、内存使用情况,IO 情况等,还有个比较重要的功能,它可以查看上下文切换情况
pidstat
top 和 vmstat 两个命令都是监测进程的内存、CPU 以及 I/O 使用情况,而 pidstat 命令可以检测到线程级别的
ps
ps 比较常用,通过此命令可以查看系统中所有运行进程的详细信息,相当与 win 中的任务管理器。ps 命令有些与众不同,它的部分选项不能加入"-“,比如命令"ps aux”,其中"aux"是选项,但是前面不能带“-”
我们一般使用 ps aux (可以查看系统中所有的进程)或者 ps -le(可以查看系统中所有的进程,而且还能看到进程的父进程的 PID 和进程优先级)
如果想要查看特定的进程可以使用这样的格式:ps aux | grep redis (查看包括 redis 字符串的进程),也可使用 pgrep redis -a。| 表示管道,grep 表示在文件中搜索需要的数据,这两者经常被用到
数据查出来了,那各个数据的意义代表什么呢:
| 名称 | 意义 |
|---|---|
| USER | 该进程是由哪个用户产生的。 |
| PID | 进程的 ID。 |
| %CPU | 该进程占用 CPU 资源的百分比,占用的百分比越高,进程越耗费资源。 |
| %MEM | 该进程占用物理内存的百分比,占用的百分比越高,进程越耗费资源。 |
| VSZ | 该进程占用虚拟内存的大小,单位为 KB。 |
| RSS | 该进程占用实际物理内存的大小,单位为 KB。 |
| TTY | 该进程是在哪个终端运行的。其中,tty1 ~ tty7 代表本地控制台终端(可以通过 Alt+F1 ~ F7 快捷键切换不同的终端),tty1~tty6 是本地的字符界面终端,tty7 是图形终端。pts/0 ~ 255 代表虚拟终端,一般是远程连接的终端,第一个远程连接占用 pts/0,第二个远程连接占用 pts/1,依次増长。 |
| STAT | 进程状态 |
| START | 该进程的启动时间。 |
| TIME | 该进程占用 CPU 的运算时间,注意不是系统时间。 |
| COMMAND | 产生此进程的命令名。如果该进程是通过脚本产生的,command 中的数据可能会包含很多信息。 |
vi/vim 编辑文件
所有的 Unix Like 系统都会内建 vi 文书编辑器,其他的文书编辑器则不一定会存在。我们可以使用 vi 或者 vim 命令来修改某个文件的内容
vim 是从 vi 发展出来的一个文本编辑器。代码补全、编译及错误跳转等方便编程的功能特别丰富,在程序员中被广泛使用。简单的来说,vi 是老式的字处理器,不过功能已经很齐全了,但是还是有可以进步的地方。 vim 则可以说是程序开发者的一项很好用的工具,但是 vim 的学习比较困难,下面是按键图
我相信大家看到这张图就不是很开心了,所以学习基本的使用即可,其他功能在遇到的时候查看就行了
vim 进入文件是命令模式,按 i 或者 a 或者 o 进入编辑模式,可以对文件进行修改,修改完毕按 Esc 退出编辑模式,然后按 :wq 保存并退出(输入 wq 代表写入内容并退出,即保存;输入 q!代表强制退出不保存)
一些常用的功能:
- gg:光标跳转到该文件的行首;
- dG:删除光标行及其以下行的全部内容。(注:d为删除,G为光标跳转到末尾行)
- set paste:取消代码缩进,但是在敲代码的时候会自动缩进,要再设置 set nopaste
查找文件
Linux 下有各种查找文件的命令
- which 查看可执行文件的位置 ,只有设置了环境变量的程序才可以用
- whereis 寻找特定文件,只能用于查找二进制文件、源代码文件和man手册页
以上两种都只能查看特定的文件,一般来说,使用 locate 的效率最高,因为使用到了索引,不过我比较喜欢用 find
基本格式:find path expression
可以按照文件名查找
- find / -name httpd.conf #在根目录下查找文件 httpd.conf,/ 表示在整个硬盘查找
- find /etc -name * srm #使用通配符*(0或者任意多个)。表示在/etc目录下查找文件名中含有字符串‘srm’的文件
- find . -name srm* #表示当前目录下查找文件名开头是字符串 srm 的文件
还可以按照文件属性查找,比如在系统中最后 x 分钟访问的文件,或者查找在系统中为空的文件或者文件夹,或者查找出小于1000KB的文件等等
该命令可以会出现权限不够的问题,导致文件拒绝访问,使用 sudo 配合 find 解决这个问题
属性相关
文件不止有在 ls -al 下显示的777,每个文件还有自己的属性,就是我们之前说的 inode,我们可以使用 lsattr 命令来看属性
------------------ x.txt
chattr 这项指令可改变存放在ext2文件系统上的文件或目录属性,这些属性共有以下8种模式,用 + 表示让某个文件获得某种属性,用 - 表示让某个文件失去某种属性:
a:让文件或目录仅供附加用途。
b:不更新文件或目录的最后存取时间。
c:将文件或目录压缩后存放。
d:将文件或目录排除在倾倒操作之外。
i:不得任意更动文件或目录。
s:保密性删除文件或目录。
S:即时更新文件或目录。
u:预防意外删除。
可以用 chattr 命令防止系统中某个关键文件被修改:
chattr +i /etc/resolv.conf
lsattr /etc/resolv.conf
chattr -i /etc/resolv.conf
有些主要的文件可能只有管理员才能修改,它们往往会被上锁,即使用 lsattr 命令看,会显示这个样子
----i--------e- a.txt
这时候我们要将这个 i 去掉,应该这么做。反之,使用 +i 就是对这个文件加锁
sudo chattr -i a.txt
定时任务
crontab -e 增加定时任务,在打开的文件中填入信息并保存,设置的定时任务就生效了
crontab -l 表示列出所有的定时任务
crontab -r 表示删除用户的定时任务,当执行此命令后,所有用户下面的定时任务会被删除,执行crontab -l后会提示用户:“no crontab for admin”
/sbin/service crond start //启动服务
/sbin/service crond stop //关闭服务
/sbin/service crond restart //重启服务
/sbin/service crond reload //重新载入配置
service crond status 查看crontab服务状态
service crond start 手动启动crontab服务
该文件中每行都包括六个域,其中前五个域是指定命令被执行的时间,最后一个域是要被执行的命令。其中设置时间的被称为 Cron 表达式,只有满足所有的条件才会执行任务。格式如下:
minute hour day month week command
其中:
- minute: 表示分钟,可以是从0到59之间的任何整数
- hour:表示小时,可以是从0到23之间的任何整数
- day:表示日期,可以是从1到31之间的任何整数
- month:表示月份,可以是从1到12之间的任何整数
- week:表示星期几,可以是从0到7之间的任何整数,这里的0或7代表星期日
- command:要执行的命令,可以是系统命令,也可以是自己编写的脚本文件
在以上各个字段中,还可以使用以下特殊字符:
- 星号(*):代表所有可能的值,例如 month 字段如果是星号,则表示在满足其它字段的制约条件后每月都执行该命令操作
- 逗号(,):可以用逗号隔开的值指定一个列表范围,例如,“1,2,5,7,8,9”
- 中杠(-):可以用整数之间的中杠表示一个整数范围,例如“2-6”表示“2,3,4,5,6”
- 正斜线(/):可以用正斜线指定时间的间隔频率,例如 “0-23/2” 表示每两小时执行一次。同时正斜线可以和星号一起使用,例如 */10,如果用在 minute 字段,表示每十分钟执行一次
比如可以设置执行 sh 文件,设置 python 文件,甚至 java 文件
*/1 * * * * sh /work/demo_startup.sh
00 * * * * python /home/task/task_main.py
生成 cron 表达式的网站:
https://cron.qqe2.com/
scp 复制文件和目录
Linux scp 命令用于 Linux 之间复制文件和目录
scp 是 secure copy 的缩写, scp 是 linux 系统下基于 ssh 登陆进行安全的远程文件拷贝命令
scp 是加密的,rcp 是不加密的,scp 是 rcp 的加强版
从本地复制到远程使用如下命令:
scp /home/space/music/1.mp3 www.runoob.com:/home/root/others/music
从远程复制到本地使用如下命令
scp www.runoob.com:/home/q/www/c2b_backend/logs/ ./
awk 分隔
逐行读取文本,默认以空格或 tab 键为分隔符进行分隔,将分隔所得的各个字段保存到内建变量中,并按模式或者条件执行编辑命令
awk 比较倾向于将一行分成多个字段然后再进行处理。awk 信息的读入也是逐行读取的,执行结果可以通过 print 的功能将字段数据打印显示
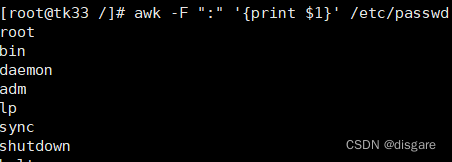
awk -F ":" '{print $1}' /etc/passwd #输出每行中(以空格或制表位分隔)的第1个字段
awk '{print}' name.txt #输出所有内容
awk '{print $0}' name.txt #输出所有内容
更多操作:
https://blog.csdn.net/Dark_Tk/article/details/114844529
cut
文件内容查看,可以显示行中的指定部分,删除文件中指定字段
选项:
-b:仅显示行中指定直接范围的内容;
-c:仅显示行中指定范围的字符;
-d:指定字段的分隔符,默认的字段分隔符为“TAB”;
-f:显示指定字段的内容;
-n:与“-b”选项连用,不分割多字节字符;
--complement:补足被选择的字节、字符或字段;
--out-delimiter=<字段分隔符>:指定输出内容是的字段分割符;
--help:显示指令的帮助信息;
--version:显示指令的版本信息。
比如 cut -d “:” -f 2,代表意思是以冒号为分隔符,提取第二个字段
sort 与 uniq
Linux uniq 命令用于检查及删除文本文件中重复出现的行列,但是当重复的行并不相邻时,uniq 命令是不起作用的,因此一般与 sort 命令结合使用
uniq 可检查文本文件中重复出现的行列
$ sort testfile1 | uniq -d
Hello 95
Linux 85
test 30
统计各行在文件中出现的次数
$ sort testfile1 | uniq -c
3 Hello 95
3 Linux 85
3 test 30
uniq 命令直接使用可以删除重复的行
$ uniq testfile
test 30
Hello 95
Linux 85
常见问题处理思路
CPU 高
1,步骤:查找进程-》查找线程-》分析threadDump日志-》找出问题代码
a、查看 cpu 高的 java 进程
top
b、生成进程下所有线程的栈日志
jstack 1721 > 1712.txt
c、查看进程下哪些线程占用了高的 cpu
top -p 1712 -H
d、将十进制 pid 转换为十六进制的 pid
printf “%x” 8247
2037
e、在 1712.txt 文件中定位问题
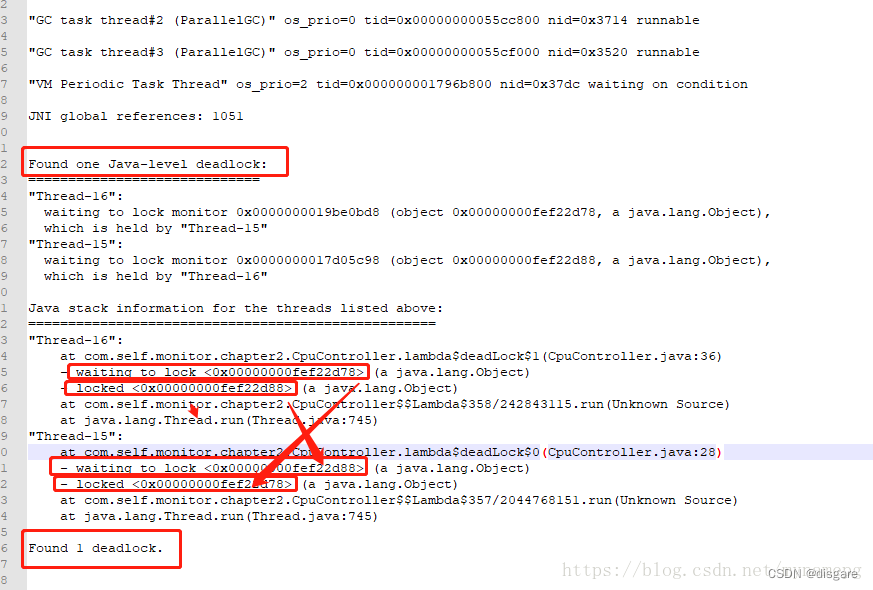
执行 jmap,jstack 等命令时可能会出现 Unable to open socket file: target process not responding or HotSpot VM not loaded 问题
其实大部分情况是用户错误,切换到进程所在用户执行命令即可
su yarn
系统平均负载高(load average)
平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数,它和 CPU 使用率并没有直接关系。一般来说单核 CPU 的 load 不应该大于1,同理,多核的 load 不应该大于核数
我们常见的负载高一般有这几种情况引起,一个是 cpu 密集型,使用大量 cpu 会导致平均负载升高。另外一个就是 io 密集型等待 I/O 会导致平均负载升高,但是 CPU 使用率不一定很高
还有就是大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高