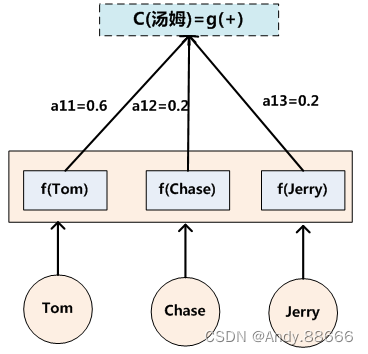
如果拿机器翻译来解释这个分心模型的Encoder-Decoder框架更好理解,比如输入的是英文句子:Tom chase Jerry,Encoder-Decoder框架逐步生成中文单词:“汤姆”,“追逐”,“杰瑞”。
在翻译“杰瑞”这个中文单词的时候,分心模型里面的每个英文单词对于翻译目标单词“杰瑞”贡献是相同的,很明显这里不太合理,显然“Jerry”对于翻译成“杰瑞”更重要,但是分心模型是无法体现这一点的,这就是为何说它没有引入注意力的原因。
上面的例子中,如果引入Attention模型的话,应该在翻译“杰瑞”的时候,体现出英文单词对于翻译当前中文单词不同的影响程度,比如给出类似下面一个概率分布值:
(Tom,0.3)(Chase,0.2) (Jerry,0.5)

Attention机制的本质思想
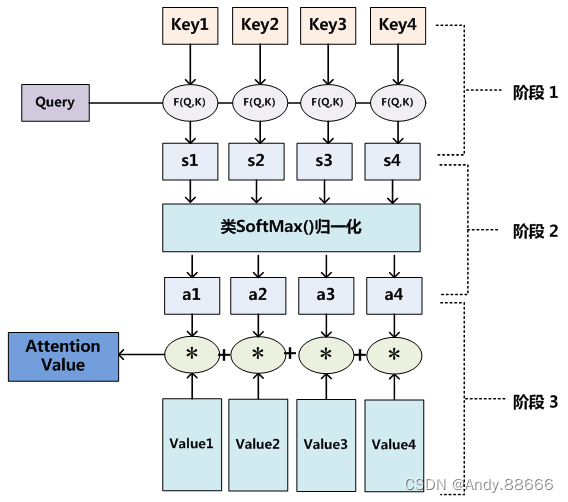
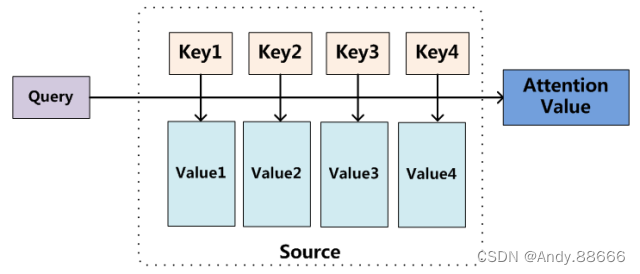 将Source中的构成元素想象成是由一系列的<Key,Value>数据对构成,此时给定Target中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到了最终的Attention数值。所以本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。
将Source中的构成元素想象成是由一系列的<Key,Value>数据对构成,此时给定Target中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到了最终的Attention数值。所以本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。
至于Attention机制的具体计算过程,如果对目前大多数方法进行抽象的话,可以将其归纳为两个过程:第一个过程是根据Query和Key计算权重系数,第二个过程根据权重系数对Value进行加权求和。而第一个过程又可以细分为两个阶段:第一个阶段根据Query和Key计算两者的相似性或者相关性;第二个阶段对第一阶段的原始分值进行归一化处理;这样,可以将Attention的计算过程抽象为如图10展示的三个阶段。
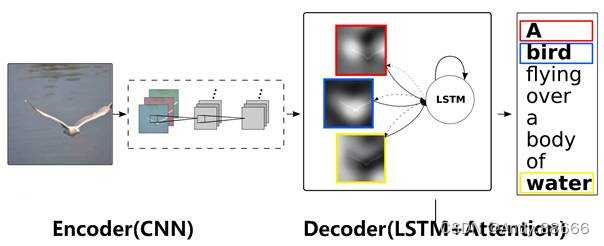
Attention机制的应用
硬查询
所谓硬查询,它的过程类似于python中的dict。本质上是用一个q,在一个k-v对里查询v,如果q等于某个k,就可以把这个k对应的v取出来。硬查询的“硬”体现在,q必须等于某个k才能查到k所对应的v,如果不相等,则什么都查不到。
软查询
软查询,“软”体现在,不需要q=k,而是,q会与所有的k计算一下相似度,按照相似的程度,从不同的k中按等份取出对应的v。
软查询不需要Q与K完全相等,就假设q=green吧。假设green是由50%的yellow和50%bule组成的。那么,首先计算q与K的相似度,结果发现是[0,0.5,0.5]。然后根据这个结果去V里取值,就是01+0.52+0.5*3=2.5,换句话说,软查询就是把所有与q相关的v,按照相似程度的比例,加权累加取出来。
attention就是本质是软查询的过程,只不过q与K的相似度,在不同的attention里有不同的计算方案,self-attention的相似度采用的是点积(向量点积也可以是一种相似性度量)外加一个归一化。
翻译模型的decoder-encoder中,encoder的编码扮演的是K和V,decoder保存的编码扮演的是q。软查询的过程是,q去和K一一比较一下,也就是看下decoder中的状态跟哪个单词的hidden state的关系最大,谁关系大谁贡献度就最大。然后根据这个贡献度去V里面查值(这一步实际上就是给hidden state加权累加)。