点击上方“Python爬虫与数据挖掘”,进行关注
回复“书籍”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
忽闻海上有仙山,山在虚无缥缈间。
大家好,我是皮皮。
一、前言
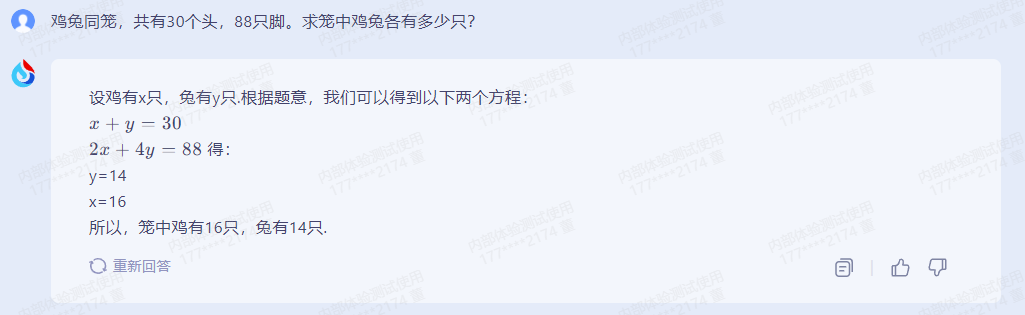
前几天在Python白银群【kim】问了一个Python机器学习的问题,这里拿出来给大家分享下。
二、实现过程
这里【eric】给出了一个思路,如下所示:在机器学习中,通常将数据分成两个部分:训练集和测试集。其中,训练集用于训练模型,在训练过程中寻找模型的最优参数;测试集用于评估模型在未见过的数据上的表现。
对于每一个数据点,通常含有多个特征(features),比如身高、体重等等。这些特征构成了数据样本(data sample)。而一个数据样本所对应的输出值(即因变量)通常称为标签(label)。在监督学习任务中,我们通常关注训练数据集中的标签,因为我们希望通过训练数据,让模型能够预测出相应的标签值。
一般来说,进行特征选择时可以考虑以下几个因素:
相关性:选取与目标变量高度相关的特征。
方差:选取方差较大的特征。
噪声:去除噪声比较大的特征。
特征重要性:通过模型训练后得到每个特征的重要性,选取重要性较高的特征。
对于预测未来十年人口,您需要根据具体的应用场景和数据情况,选择合适的特征进行预测。同时还需注意模型的选择和调参,以及对数据集进行有效的验证和评估。
从提供的 Excel 表格来看,数据集中的每一行为一个样本,包含了该样本对应的各个特征(Age, Gender, Education, Occupation等)以及目标变量/标签(Pop_Density)。其中,样本的特征是可以作为输入输入到机器学习模型中进行训练的,而目标变量/标签则是我们希望模型能够预测的值。
对于如何选择特征,通常可以从以下几个方面考虑:
领域知识:在掌握了相关领域知识的前提下,可以利用领域知识对特征进行筛选、改进或生成新的特征。
特征重要性分析:可以通过特征重要性分析的方法对现有的特征进行评估,去除不必要的特征或强化对目标变量的贡献。
特征工程:特征工程是将原始数据转换为更能代表问题的特征的过程。通常可以使用统计特征、聚类、降维等方法进行特征工程。
关于如何预测未来十年人口,这需要更多的信息和上下文以及具体的预测目标来进行更详细的分析和建模。
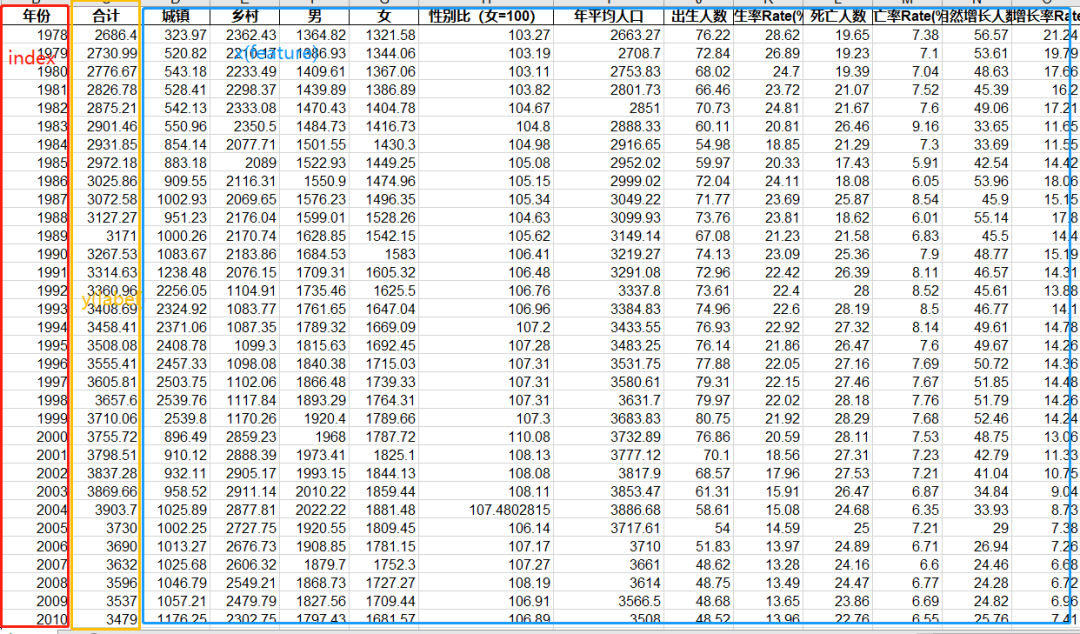
下图是【王者级混子】分享的一个图:
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Python机器学习基础的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【kim】提问,感谢【eric】、【王者级混子】给出的思路和代码解析,感谢【冫马讠成】等人参与学习交流。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。

大家在学习过程中如果有遇到问题,欢迎随时联系我解决(我的微信:pdcfighting1),应粉丝要求,我创建了一些高质量的Python付费学习交流群和付费接单群,欢迎大家加入我的Python学习交流群和接单群!

小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。

------------------- End -------------------
往期精彩文章推荐:
if a and b and c and d:这种代码有优雅的写法吗?
Pycharm和Python到底啥关系?
都说chatGPT编程怎么怎么厉害,今天试了一下,有个静态网页,chatGPT居然没搞定?
站不住就准备加仓,这个pandas语句该咋写?

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~