在我们编写程序时,经常需要传递参数给函数,其中一种常见的参数类型就是数组。数组作为一种数据结构,可以存储多个相同类型的数据元素,并按照一定的顺序排列。在函数中传递数组参数,可以方便地对数组进行操作处理。但是,数组传参也有其特殊和需要注意的地方。在文中,我将向大家讲解数组作为参数传递时的一些问题和解决方法。学习之前我们要先了解数组的一些基础知识,也是对前期数组知识的补充。
一维数组与二维数组
本文将重点针对对一维数组和二维数组进行讲解。
前几期中我对一维数组的创建及初始化已进行了讲解,先对二维数组进行简单介绍。
二维数组
二维数组我们可以理解为一个数组里放了多个一维数组
例如:arr[4][5]:可以理解为arr[4][5]中存放了四个数组,分别名为arr[0],arr[1],arr[2],arr[3]每个数组大小都是5;
arr[0]:arr[0][0],arr[0][1],arr[0][2],arr[0][3],arr[0][4]
arr[1]:arr[1][0],arr[1][1],arr[1][2],arr[1][3],arr[1][4]
arr[2]:arr[2][0],arr[2][1],arr[2][2],arr[2][3],arr[2][4]
arr[3]:arr[3][0],arr[3][1],arr[3][2],arr[3][3],arr[3][4]
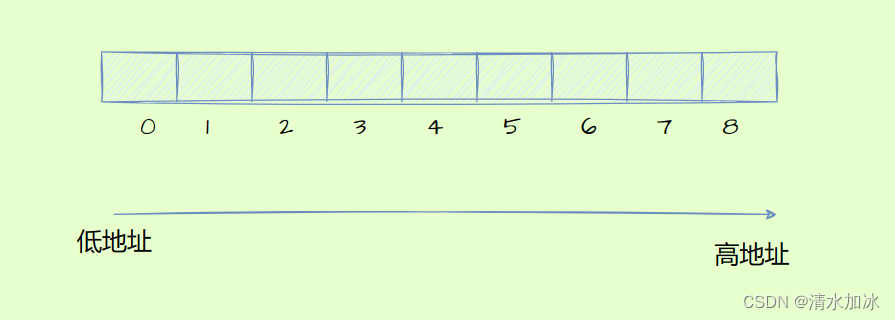
二维数组和一维数组在内存中存储都是连续存放的。
首先我们先写一个小程序对二维数组进行初始化
#include<stdio.h>
int main() {
int arr[2][3];
int i = 0;
for (i = 0; i < 2; i++) {
for (int j = 0; j < 3; j++) {
scanf("%d", &arr[i][j]);
}
}
for (i = 0; i < 2; i++) {
int j = 0;
for (j = 0; j < 3; j++) {
printf("%d ", arr[i][j]);
}
printf("\n");
}
return 0;
}
通过调试时我们可以发现相邻的两个元素之间地址相差4(这里表示地址使用的是16进制,每个元素相差4个字节),并且是连续的。随着数组下标的增长,元素的地址也在有规律的增长(由低地址到高地址)。
二维数组的创建
二维数组的创建与一维数组很相似,当然我们也可以创建多种类型的数组
char arr[2][3];
int arr1[3][4];
double arr2[2][4];二维数组的初始化
有以下几种初始化形式。
int arr[3][4]={1,2,3,4};
int arr1[3][4]={{1,2},{3,4}};
int arr2[][4]={{2,3},{4,5}};二维数组的两个[],分别代表的是行和列,前两个数组创建时是一个三行四列的数组,并且在数据元素不够时,会进行补0操作。
注意:二维数组的行可以省,但列不行,计算机会根据初始化时的数据自动计算行的值,而对于列,规定列的大小是为了确定后续计算机进行补0的个数。
数组越界
数组的下标是有范围的。
数组下标规定从0开始,如果数组有n个元素,那么最后一个数组下标就是n-1。
所以数组下标如果小于0,或者大于n-1,就是数组越界访问了,超出了数组合法空间的访问。
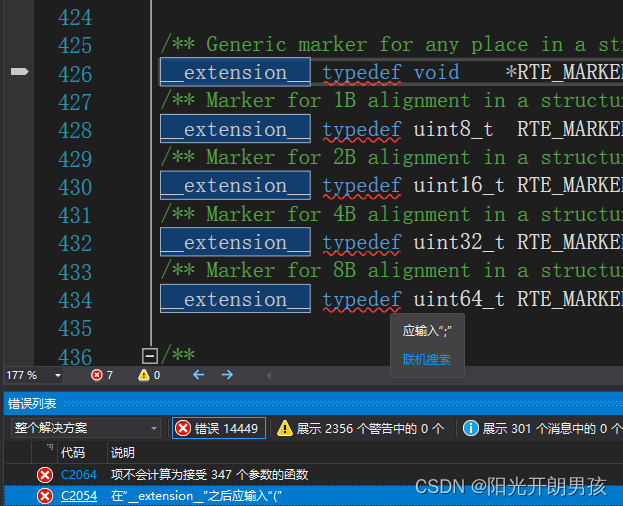
C语言本身是不做数组下标的越界检查,编译器也不一定会报错,但编译器不报错就并不意味着程序就是正确的。
所以在写代码时,程序员最好自己做越界检查。
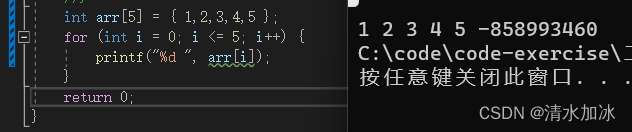
如上图,编译器没有报错,最后一个数字因为数组越界访问输出结果是随机值。
当然二维数组的行和列也可能存在越界访问
数组作为函数参数
在写代码时,会将数组作为参数传给函数,比如:实现一个冒泡排序的函数
先解释一下冒泡排序的原理以升序为例:相邻两个数字进行比较,较大数与后一个数位置交换
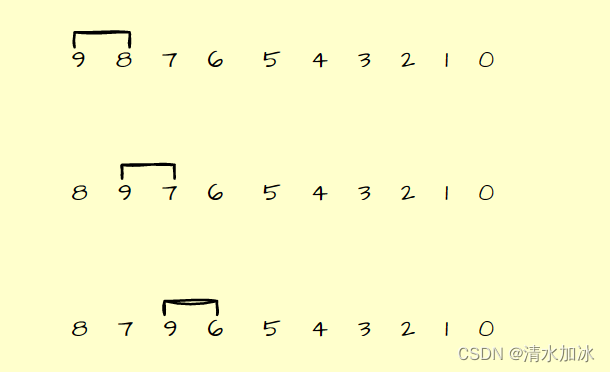
最终直到最大数到最后的位置(此过程需要比较9次)

这个过程为一趟,而第二趟就只需要交换8次,第三趟需要交换7次,需要交换的次数依次减少,一共需要9趟(交换次数也就是9!)由于我示例数据是降序,要排列为升序,需要交换的次数是最多的,在乱序数据中,交换次数只会比示例交换次数少。
代码实现:
for (int j = 0; j < sz-1; j++) //sz是数组元素个数
{
for (int i = 0; j < sz - 1 - i; i++)
{
if (arr[i] > arr[i + 1])
{
t = arr[i]; //t是作为交换的中间媒介
arr[i] = arr[i + 1];
arr[i + 1] = t;
}
}
}写一个冒泡排序函数该如何实现呢?
void bubble(int arr[10]) {
int t;
int sz = sizeof(arr) / sizeof(arr[0]);//计算数组元素个数
for (int j = 0; j < sz-1; j++)
{
for (int i = 0; j < sz - 1 - i; i++)
{
if (arr[i] > arr[i + 1])
{
t = arr[i];
arr[i] = arr[i + 1];
arr[i + 1] = t;
}
}
}
}
int main()
{
int arr[10];
for (int i = 0; i < 10; i++) {
scanf("%d", &arr[i]);
}
bubble(arr);
for (int i = 0; i < 10; i++) {
printf("%d ", arr[i]);
}
return 0;
}
这段代码可以实现冒泡排序吗?当结果运行起来我们会发现,结果并没有预期那样排序,这是为什么呢?
在调用函数时bubble(arr),arr作为数组进行传参,数组传参,传递的实质是首元素的地址,而void bubble(int arr[10])这里的arr[10]本质上也是指针,在函数中我们使用sizeof计算数组大小也仅仅只是形参接收的首元素地址。

通过调试我们会发现这里的sz的值是1(在64位操作系统结果是2,64位操作系统中,指针变量占8个字节除以arr[0]整形所以结果是2)。
或许有同学会疑惑arr是数组首元素地址那sizeof(arr)为什么就可以计算数组长度。
这里额外补充一下
数组名的理解
数组名该怎么理解?
在通常情况下数组名就是首元素的地址。但是有两个意外
1.sizeof(数组名),数组名单独放在sizeof()内部,这里的数组名表示整个数组,计算的是数组大小
2.&数组名,这里的数组名也是表示整个数组,取出的是整个数组的地址
除此之外所有遇到的数组名都表示数组首元素的地址。
这里通过代码给大家更清晰的呈现:
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9 };//%p用来打印地址
printf("%p\n", arr);
printf("%p\n", &arr[0]);
printf("%p\n", &arr);
printf("%p\n", &arr+1);
printf("%p\n", arr+1);
return 0;
}运行结果如下:

我们发现前3个结果相同,这是因为整个数组的地址也是从首元素地址开始的,将&arr+1,和arr+1我们就会发现结果不同。&arr+1结果与首元素地址相差28(这里28是16进制转化为10进制就是40。)正好相差一个数组的大小,arr+1与首元素地址相差4。
区别在于:arr+1跳过的是一个数组元素,而&arr+1跳过的是整个数组。
那如何完成冒泡排序函数呢?
也很简单,只需在主函数里求好数组元素个数,传到函数中(上述情况说明:数组元素是数组时没法在函数中计算大小,这里也仅限数组元素是数字,字符串数组可以),就可以解决这个问题。
代码修改后:
void bubble(int arr[10],int sz) {
int t;
for (int j = 0; j < sz-1; j++)
{
for (int i = 0; j < sz - 1 - i; i++)
{
if (arr[i] > arr[i + 1])
{
t = arr[i];
arr[i] = arr[i + 1];
arr[i + 1] = t;
}
}
}
}
int main() {
int arr[10];
for (int i = 0; i < 10; i++) {
scanf("%d", &arr[i]);
}
int sz = sizeof(arr) / sizeof(arr[0]);
bubble(arr, sz);
for (int i = 0; i < 10; i++) {
printf("%d ", arr[i]);
}
return 0;
}这里在给大家补充一点:计算数组元素个数有sizeof(数组名)/sizeof(arr[0]),和strlen(数组名)两种,
char str[]="hello world"
printf("%d %d",sizeof(str),strlen(str));//输出结果是:12 11sizeof(str):获取数组的总大小,12个元素,每个元素占1个字节,因此总共是12个字节
strlen(str): 获取字符串中有效字符的个数,不算'\0',因此总共11个有效字符。此外strlen是只能计算字符串长度。在函数中可以使用strlen计算字符串数组的大小(当然字符串数组传进去的也是数组首元素地址)。
好了本期内容到这里就结束了,希望对你有所帮助,感谢观看!