1、项目需求:实现黑客攻击系统菜单打印
实现:
#include <iostream>#include <Windows.h>int main( void ) {std::cout << "1. 网站 404 攻击 " << std::endl;std::cout << "2. 网站篡改攻击 " << std::endl;std::cout << "3. 网站攻击记录 " << std::endl;std::cout << "4.DNS 攻击 " << std::endl;std::cout << "5. 服务器重启攻击 " << std::endl;system( "pause" );return 0;}
需求增加:没有输入账号登录, 就直接显示功能菜单. 应该先让用户输入账号并登录
实现:
#include <iostream>#include <Windows.h>int main( void ) {char name;int pwd;std::cout << " 请输入账号: " ;std::cin >> name;std::cout << " 请输入密码: " ;std::cin >> pwd;/*std::cout << "1. 网站 404 攻击 " << std::endl;std::cout << "2. 网站篡改攻击 " << std::endl;std::cout << "3. 网站攻击记录 " << std::endl;std::cout << "4.DNS 攻击 " << std::endl;std::cout << "5. 服务器重启攻击 " << std::endl;*/system( "pause" );return 0;}
不用懂代码,只是让你跟着敲,熟悉头文件的名字,熟悉主函数。
2、C++数据类型
已经是用过的数据类型有:字符串类型、整数类型
2.1什么是数据类型?
不同类型的人, 思考问题,处理问题的方式都不一样。计算机中的数据,也分成很多种类型:
| int | usigned int | char |
| usigned char | long | long long |
| unsigned long | short | unsigned short |
| float | double | 各种指针类型 |
| 枚举类型 | struct结构体类型 | union联合类型 |
| bool | string | 类 |
其中C++完全支持C语言的各种数据类型,不同数据类型的区别:
1. 表示意义不同2. 占用内存不同3. 表示的范围不同4. 使用方法不同
数据类型使用不当,将导致严重的后果。
1.
对于程序员:隐藏
BUG,建议载刷题的时候,浮点数用double,整数用long long或者int
2. 对于系统:隐藏灾难,因数据类型使用不当,产生数据溢出,导致阿丽亚娜
5
型运载火箭自爆
3、变量
变量,不是数学中的变量,程序在运行时,需要保存很多内容常常变化的数据。
比如,射击类游戏中不断变化的“分数”。 世界中的芸芸众生:数据在大量变量之间“计算”、“交换”。
变量是处理数据的基本实体。变量是什么?
变量,是内存中的一块存储空间,即一小块内存
变量和数据类型有什么关系?
变量,是一个盒子,盒子里保存了“数据” ,数据又分成很多“类型”(数据类型)
=>
变量的类型,就是变量中数据的类型。
=>
变量在定义(创建)时,必须先指定它的类型。
【相当于:制作一个盒子时,必须先确认这个盒子是用来装什么的】
=> 1
个变量只有
1
个类型,而且不能改成其他类型
变量的定义形式:
定义形式
1
:
int x;
int y;
定义形式
2
:
(
不推荐)
int x, y;
定义形式
3
:(定义的时候,设置一个初始值)
int x = 100;
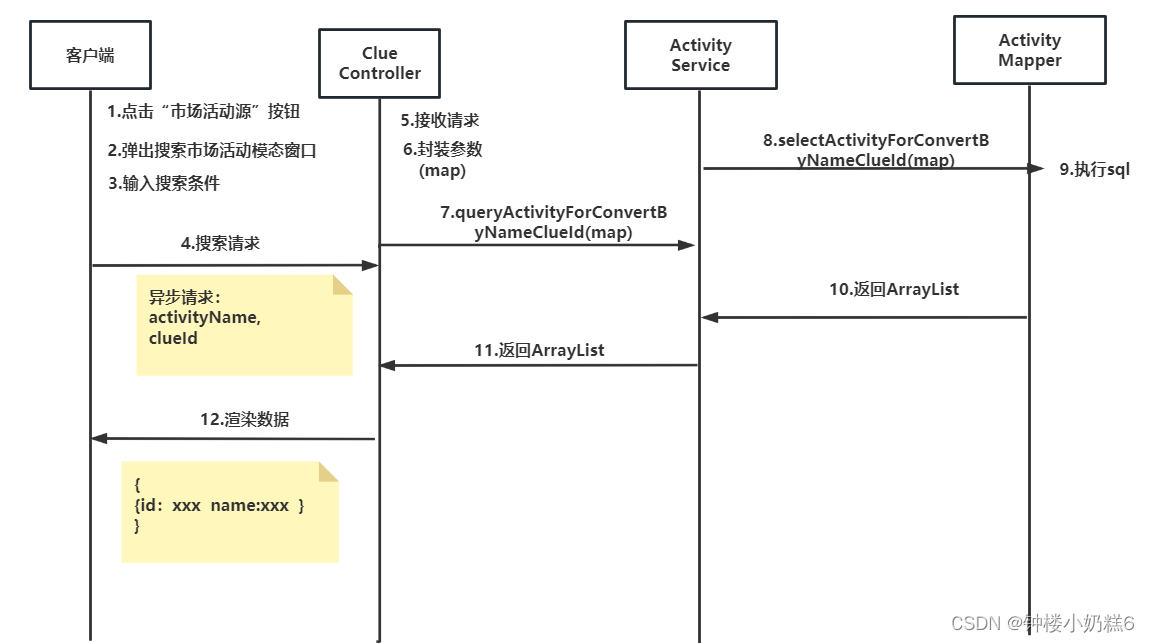
深度剖析:
int a; //
定义了一个变量
a = 100;
内存原理:
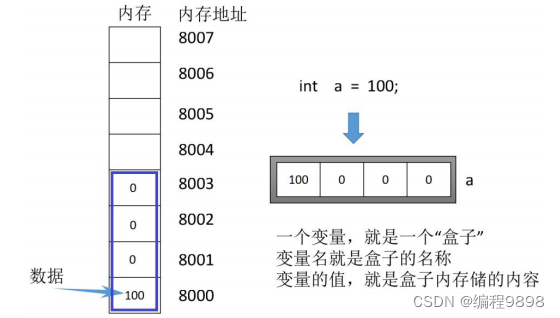
内存的存储单位
-
“字节”
内存的存储单位,是字节。 一个字节,包含 8
位二进制位。
数据在内存中存储的模式:
大端模式:低字节存放到高地址中
小端模式:低字节存放到低地址中。
一般
PC
机都是小端方式,大端方式对人来
看友好,小端方式对机器来看友好。参考
《计算机组成原理》
变量名的命名规范
1) 只能包含 3 种字符(数字、大 / 小写字母,下划线)2) 不能以数字开头(即,只能以字母或下划线开头)int 2name; // 非法3) 不能和“关键字”同名(c 语言内部已经使用的“名称”),比如类型名 int变量名的最大长度, C 语言没有规定。最大长度限制,取决于编译器,一般都在 32 以上。
变量名,最好“
顾名思义
”,即见名知意,不用使用汉语拼英的简写
!
比如:用
name
表示姓名,用
power
表示功率。
命名风格
:
小驼峰命名:如果只有一个单词则全
部小写,如果有多个单词,则从第二
个单词开始,所有单词首字母大写。
eg:studentAge
大驼峰命名:如果只有一个单词,首
字母大写即可,如果有多个单词,则
每个单词首字母大写即可。
1
)下划线风格
int student_age; (一般用于变量名、函数名
)
2
)小驼峰风格
int studentAge; (一般用于变量名、函数名
)
1
)大驼峰风格
class StudentAge; (
一般用于“类名”
)
2
)全部大写
(
一般用于宏
)
#define MAX_AGE 30
注意:
宏在预处理的时候就被替换成
相应的数据了。
请忘记“匈牙利命名法”(属性
+
类型
+
对象描述),这种命名已被丢弃。
注意:在编程语言中,一般都可以以
$
符号开头 ,这个企业面试容易问到,只是一般不 用$
开头,所以把这个忽略了。
4、整形
原始人,使用结绳计数,这个“数”就是整数
int
类型
使用最多的整数类型
在内存中占
4
个字节
表示范围:
- (2
的
31
次方
) ~ 2
的
31
次方
-1
【正负 21 亿左右】
长整形
long
long
也就是
long int
可用来存储更大的整数。
在
32
位系统上,占
4
个字节,和
int
相同
在 64 位系统上,占 8 个字节【正负 9 百亿亿左右】,在VS编译器上不管在32还是64位平台均和int范围一样,为了统一,以后长整型都用long long类型
长长整形
long long
用来存储整数。
在内存中占
8
字节。
很少使用,仅用于特殊的计算。
long long
类型最大值为:
9223372036854775807
即九百亿亿多。
短整形
short
用来存储整数。
在内存中占
2
字节。
用于存储小范围的整数
表示范围:
- (2
的
15
次方
) ~ 2
的
15
次方
-1
【正负 3 万多】
无符号类型, 铁公鸡
-
概不赊欠
-
没有负数
unsigned int
unsigned long
unsigned long long
unsigned short
最小值都是
0
, 最大值是对应的有符号数的
2 倍
经典用法:
unsigned short port; //
用来表示网络通信的端口号(0-65535)
unsigned int num; //
表示编号(0 到四十多亿)
字符类型,
用于单个字符的数据类型
char
某学员的字母故事
.
单个字符:
‘0’ ‘1’ ‘2’ ‘3’ ...... ‘9’‘a ’ ‘b’ ‘c’ ‘d’ ...... ‘z’‘A’ ‘B’ ‘C’ ‘D’ ...... ‘Z’‘,’‘-’‘!’ ‘#’.......
单个字符常量, 要求用‘’括起来
字符类型
char
一个字节。
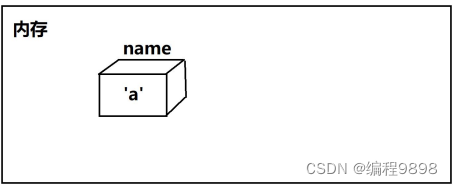
char name = ‘a’;
内存示意图:
字符的实际表示:
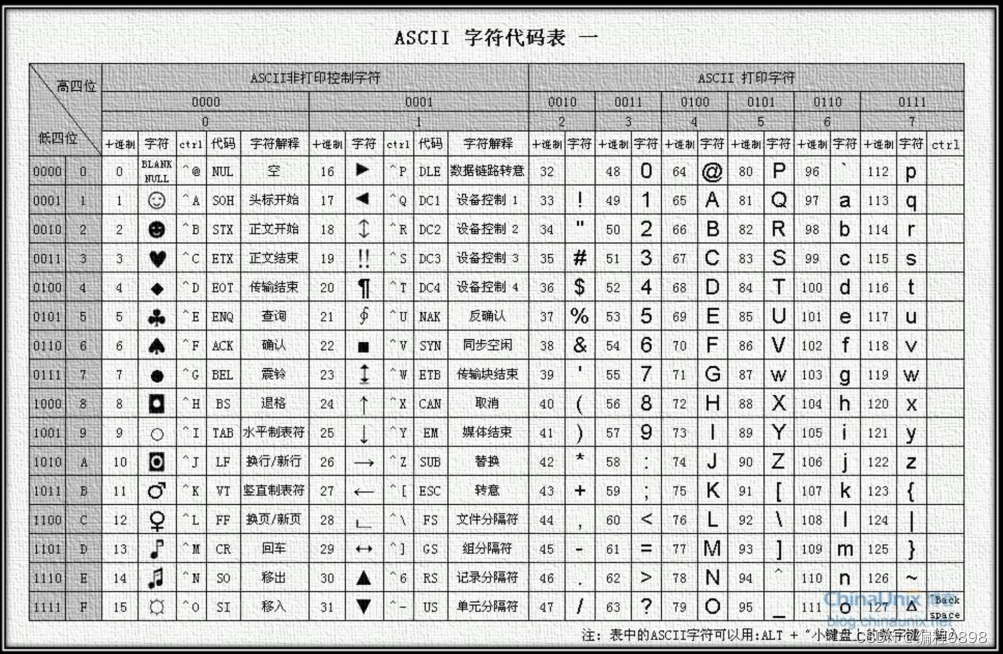
所有的字符,使用对应的
ASCII
值来存储。 为什么?(因为计算机中只能存储 0
和
1
的组合)
ASCII
码,使用
1
个字节(包含
8
个二进制位,即
8
个
0
和
1
的组合)
比如:’A’ ,
用
0100 0001
来表示, 就是
65,
‘B’, 用
0100 0010
来表示, 就是
66
ASCII码表:
char name ='a'
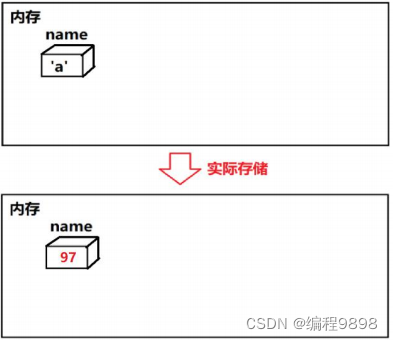
char name = ‘a’;
等效于:
char name = 97;
char
类型的另一种用法
用来表示小范围的整数(
-128 ~ 127
)
不过现在开发时,小范围的整数,也常常直接用
int
类型。
实例:
int x = 0;
x = ‘a’ + 1; // 97 + 1
注意
:
1
和
‘1’
的区别
.
int x = 1;
char y = ‘1’; //49
5、浮点型:用于精确计算的数据类型(浮点型)
需要精确计算的数学、工程应用,用整数类型不合适。
生活中的
”
敏感数据
”

float
类型(单精度浮点类型)
用来存储带小数部分的数据。 在内存中占用 4
个字节
表示范围:
-3.4*10^38
~
+3.4*10^38
(
不需记忆
)
精度:
最长
7
位有效数字
(是指
7
位
10
进制位)
float y = 1.123456789;
//
精度只能取值到
1.1234568,
在第
7
位(整数部分不算)是四舍五入后的值。
float 类型的存储方式:

学过计算机组成原理的都知道,这是 经典的IEEE754
标准存储浮点数。科 班出生的同学一定要掌握,不然学到 深处跟不上。
符号位: 0 代表正数, 1 代表负数阶码: 指数 +127符号位 尾数 * 2 ^ ( 阶码 -127)
转化过程:(了解)
float x = 13.625;
13.625
的转化:
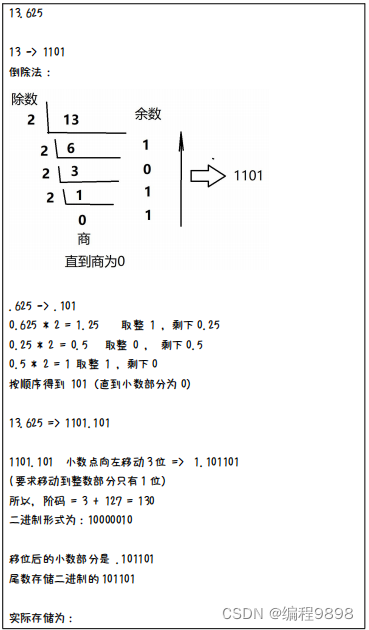
阶码用移码表示,位数用原码表示,隐藏一位1,有效位数为24位,因此把int型转为float类型可能会有精度丢失。实际存储如下:

double
类型(双精度浮点类型)
用来存储带小数部分的数据。
8
个字节
具体的存储方式和
float
相似
.

有效位数为53位。
表示范围:
-1.7*10^308~1.7*10^308
(
不需记忆
)
精度:
最长
16
位有效数字
(是指
16
位
10
进制位)
double y = 1.12345678901;
浮点类型的常量
带小数的常量默认都是
double
类型
3.14
是
double
类型
3.14f
强制指定是
float
类型
注意,编程的时候,给 float类型变量赋值时,后 面要加上F
,这样写更加规 范,不加F
默认是
double
类型,会发生便宜警告。
可以用
”
科学计数法
”
表示浮点类型的常量
1.75E5
或
1.75 e5
1.75E5
就是
1.75
乘以
10
的
5
次方
(100000), 175000.0
注意:
1
是
int
类型的常量
1.0
是
double
类型的常量
小案例,浮点数据的输出控制
#include<iostream>
#include<Windows.h>
using namespace std;
int main(void){
double value = 12.3456789;
// 默认精度是 6,所以输出为 12.3457
//(默认情况下,精度是指总的有效数字)
cout << value << endl;
// 把精度修改为 4, 输出 12.35, 对最后一位四舍五入
// 精度修改后,持续有效,直到精度再次被修改
cout.precision(4);
cout << value << endl;
// 使用定点法, 精度变成小数点后面的位数
// 输出 12.3457
cout.flags(cout.fixed);
cout << value << endl;
// 定点法持续有效
// 输出 3.1416
cout << 3.1415926535 << endl;
// 把精度恢复成有效数字位数
cout.unsetf(cout.fixed);
cout << value << endl; //输出 12.35
cout << 3.1415926535 << endl; //输出 3.142
system("pause");
return 0;
}这个案例是浮点数打印的经典案例,必须自己手动敲牢牢掌握。