计算机是在不同的抽象层上设计和构建的。 我们可以通过计算机递归地下降,看到组件将自身放大为完整的子系统,直到我们遇到单个晶体管。 尽管有些故障很普遍,例如断电,但许多故障仅限于模块中的单个组件。 因此,一个模块在一个级别上的完全故障可以被认为仅仅是更高级别模块中的组件错误。
一个困难的问题是确定系统何时正常运行。 随着互联网服务的普及,这一理论观点变得更加具体。 基础设施提供商开始提供服务水平协议 (SLA) 或服务水平目标 (SLO),以保证他们的网络或电力服务可靠。 例如,如果他们没有遵守每月几个小时的协议,他们将向客户支付罚款。
系统在关于 SLA 的两种服务状态之间交替:
1. 服务完成,其中服务按规定交付。
2. 服务中断,交付的服务与 SLA 不同。
这两个状态之间的转换是由故障(从状态 1 到状态 2)或恢复(从 2 到 1)引起的。 量化这些转变可以得出两个主要的可靠性衡量标准:
■ 模块可靠性是衡量从参考初始时刻开始的连续服务成就(或等效的故障时间)的衡量标准。 因此,平均无故障时间 (MTTF) 是一种可靠性衡量标准。 MTTF 的倒数是故障率,通常报告为每十亿小时运行故障数,或 FIT(及时故障)。
■ 服务中断以平均修复时间 (MTTR) 衡量。 平均无故障时间 (MTBF) 就是 MTTF + MTTR 的总和。
■ 模块可用性是关于完成和中断两种状态之间的交替的服务完成的量度。 对于有维修的非冗余系统,模块可用性是
模块可用性 = MTTF / (MTTF + MTTR)
可靠性和可用性现在是可量化的指标,而不是可靠性的同义词。 根据这些定义,如果我们注意到可靠性和可用性现在是可量化的指标,而不是可靠性的同义词,我们就可以定量地估计系统的可靠性。 根据这些定义,如果我们对组件的可靠性做出一些假设并且故障是独立的,我们可以定量地估计系统的可靠性
MTTF(平均故障时间)是指不可修复的模块或元件的平均寿命。它是通过收集大量的模块或元件的寿命然后取平均值来计算的。
MRBF(平均故障间隔时间)是指可修复的模块两次故障之间的平均时间。它是通过将总运行时间除以故障次数来计算的。它反映了模块的可靠性,即正常运行的时长。
MTTR(平均修复时间)是指从模块发生故障到恢复正常运行所需的平均时间。它包括发现、定位、修复和测试的时间。它反映了模块的维修效率,即恢复速度。
模块可用性是指模块正常运行的时间占比。它是通过将MRBF除以MRBF加上MTTR来计算的。它反映了模块对用户或系统提供服务的能力。

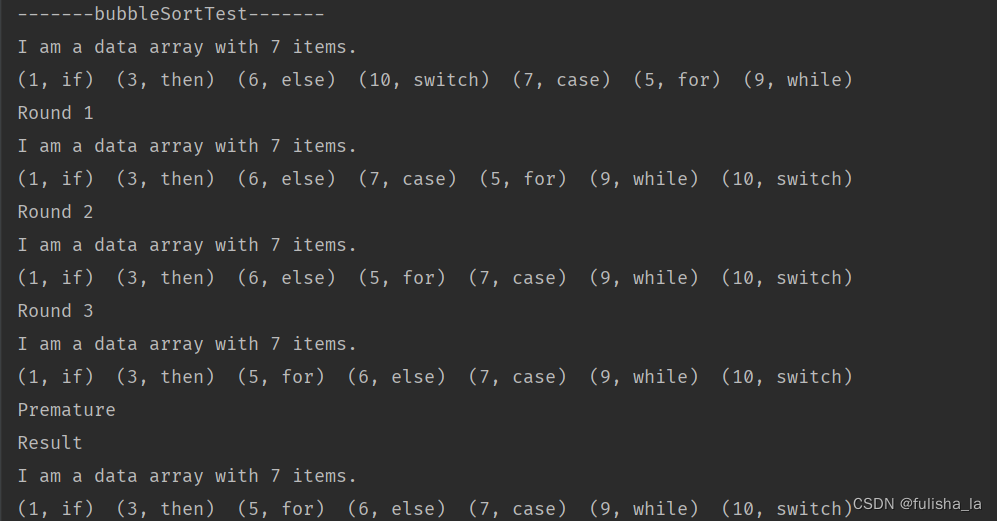
假设我们有一个模块,它在一年内发生了四次故障,每次故障的间隔和修复时间如下:
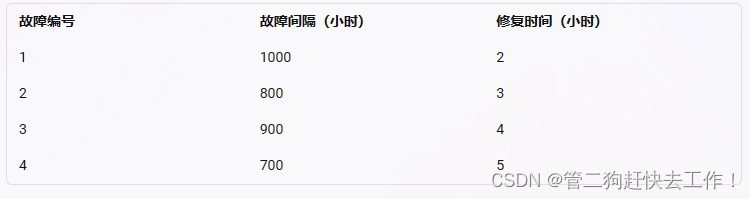
那么,我们可以计算出:
- MTTF(平均故障时间)= N/A,因为这是一个可修复的模块,不适用MTTF指标。
- MRBF(平均故障间隔时间)= (1000 + 800 + 900 + 700) / 4 = 850 小时
- MTTR(平均修复时间)= (2 + 3 + 4 + 5) / 4 = 3.5 小时
- 模块可用性 = 850 / (850 + 3.5) = 0.996
另一个例子:
假设一个磁盘子系统具有以下组件和 MTTF:
■ 10 个磁盘,每个磁盘的额定 MTTF 为 1,000,000 小时
■ 1 个 ATA 控制器,500,000 小时 MTTF
■ 1 个电源,200,000 小时 MTTF
■ 1 个风扇,200,000 小时 MTTF
■ 1 ATA 电缆,1,000,000 小时 MTTF
使用寿命呈指数分布且故障独立的简化假设,计算整个系统的 MTTF。
故障率的总和是:
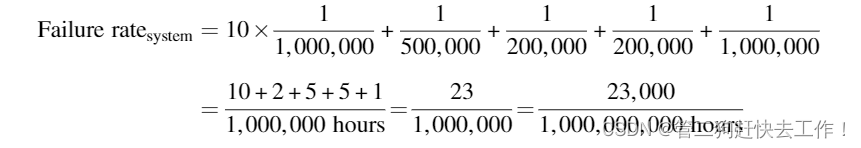
系统的 MTTF 只是故障率的倒数:

最后一个例子:
磁盘子系统通常具有冗余电源以提高可靠性。 使用前面的组件和 MTTF,计算冗余电源的可靠性。 假设一个电源足以运行磁盘子系统,并且我们要添加一个冗余电源。
我们需要一个公式来显示当我们可以容忍故障并仍然提供服务时会发生什么。 为了简化计算,我们假设组件的寿命呈指数分布,并且组件故障之间没有依赖关系。 我们的冗余电源的 MTTF 是一个电源发生故障之前的平均时间除以另一个电源在更换第一个电源之前发生故障的可能性。 因此,如果在维修前发生第二次故障的可能性很小,则该对的 MTTF 就很大。
由于我们有两个电源和独立的故障,一个电源出现故障的平均时间是 MTTFpower supply/2。 二次故障概率的一个很好的近似值是 MTTR 在另一个电源出现故障之前的平均时间。 因此,一对冗余电源的合理近似是

使用前面的 MTTF 数字,如果我们假设操作员平均需要 24 小时才能注意到电源出现故障并更换它,则容错电源对的可靠性为
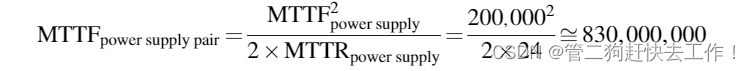
使这对电源的可靠性比单个电源高 4150 倍。