Diesel 2.0.4
官网
github
API Documentation
一个安全的,可扩展的ORM和Rust查询构建器
Diesel去掉了数据库交互的样板,在不牺牲性能的情况下消除了运行时错误。它充分利用了Rust的类型系统来创建一个“感觉像Rust”的低开销查询构建器。
支持数据库:
- PostgreSQL
- MySQL
- SQLite
你可以在Cargo.toml中配置数据库后端:
[dependencies]
diesel = { version = "<version>", features = ["<postgres|mysql|sqlite>"] }
我们为什么要制造Diesel?
- 防止运行时错误
我们不想浪费时间追踪运行时错误。我们通过让Diesel在编译时消除不正确的数据库交互的可能性来实现这一点。 - 为性能而生
Diesel提供了一个高级查询构建器,让你用Rust而不是SQL来思考问题。我们对零成本抽象(zero-cost abstractions)的关注使Diesel能够比C更快地运行查询和加载数据。 - 高效和可扩展
与活动记录和其他ORMs不同,Diesel被设计为抽象的。Diesel使您能够编写可重用的代码,并根据您的问题领域而不是SQL进行思考。
1、入门指南
在本指南中,我们将为CRUD的每个部分介绍一些简单的示例,CRUD代表“创建、读取、更新、删除”。本指南中的每一步都将建立在前一步的基础上,并将遵循这些步骤。
本指南假设您正在使用PostgreSQL。在我们开始之前,确保您已经安装并运行了PostgreSQL。如果您正在使用一些不同的数据库,例如SQLite,那么一些示例将无法运行,因为实现的API可能不同。在项目存储库中,您可以为每个受支持的数据库找到各种示例。
关于Rust版本的说明:
Diesel需要Rust 1.56或更高版本。如果您遵循本指南,请通过运行rustup update stable来确保您使用的至少是那个版本的Rust。
1.1 初始化一个新项目
我们需要做的第一件事是生成项目。
cargo new --lib diesel_demo
cd diesel_demo
首先,让我们将Diesel添加到依赖项中。我们还将使用一个名为.env的工具来管理我们的环境变量。我们也会把它添加到我们的依赖项中。
# Cargo.toml
[dependencies]
diesel = { version = "2.0.0", features = ["postgres"] }
dotenvy = "0.15"
1.2 安装Diesel CLI
Diesel提供了一个单独的CLI工具来帮助管理您的项目。因为它是一个独立的二进制文件,并且不会直接影响项目的代码,所以我们没有将它添加到Cargo.toml中。相反,我们只需将其安装在我们的系统上。
cargo install diesel_cli
关于安装diesel_cli的注意事项
如果您遇到如下错误:
note: ld: library not found for -lmysqlclient
clang: error: linker command failed with exit code 1 (use -v to see invocation)
这意味着您缺少数据库后端所需的客户端库——在本例中是mysqlclient。您可以通过安装库(根据您的操作系统使用通常的方法来完成此操作)或通过使用 --no-default-features标志排除不需要的默认库来解决此问题。
默认情况下,diesel依赖于以下客户端库:
- libpq for the PostgreSQL backend
- libmysqlclient for the Mysql backend
- libsqlite3 for the SQlite backend
如果您不确定如何安装这些依赖项,请查阅相应依赖项的文档或您的发行包管理器。
例如,如果你只安装了PostgreSQL,你可以使用下面的命令来安装diesel_cli:
cargo install diesel_cli --no-default-features --features "postgres mysql"
# diesel -h
diesel 2.0.1
USAGE:
diesel [OPTIONS] <SUBCOMMAND>
OPTIONS:
--config-file <CONFIG_FILE>
The location of the configuration file to use. Falls back to the `DIESEL_CONFIG_FILE`
environment variable if unspecified. Defaults to `diesel.toml` in your project root. See
diesel.rs/guides/configuring-diesel-cli for documentation on this file.
--database-url <DATABASE_URL>
Specifies the database URL to connect to. Falls back to the DATABASE_URL environment
variable if unspecified.
-h, --help
Print help information
--locked-schema
Require that the schema file is up to date.
-V, --version
Print version information
SUBCOMMANDS:
completions Generate shell completion scripts for the diesel command.
database A group of commands for setting up and resetting your database.
help Print this message or the help of the given subcommand(s)
migration A group of commands for generating, running, and reverting migrations.
# 一组用于生成、运行和恢复迁移的命令。
print-schema Print table definitions for database schema.
setup Creates the migrations directory, creates the database specified in your
DATABASE_URL, and runs existing migrations.
You can also run `diesel SUBCOMMAND -h` to get more information about that subcommand.
1.3 为您的项目设置Diesel
我们得告诉Diesel去哪里找数据库。我们通过设置DATABASE_URL环境变量来实现这一点。在我们的开发机器上,我们可能会同时进行多个项目,我们不想污染我们的环境。我们可以将url放在.env文件中。
现在Diesel CLI可以为我们设置一切。
diesel setup
提示如下错误:
#diesel setup
Creating database: postgres
connection to server at "182.254.211.60", port 5432 failed: FATAL: password authentication failed for user "postgres"
connection to server at "182.254.211.60", port 5432 failed: FATAL: password authentication failed for user "postgres"
修改:pg_hba.conf
将scram-sha-256改为 trust
这将创建我们的数据库(如果它还不存在的话),并创建一个空的迁移目录,我们可以用它来管理我们的模式(schema, 稍后将详细介绍)。
现在我们要编写一个小的CLI,让我们可以管理博客(忽略我们只能从这个CLI访问数据库的事实…)。首先,我们需要一个表来存储我们的帖子。让我们为此创建一个迁移:
diesel migration generate create_posts
Diesel CLI将在所需的结构中为我们创建两个空文件。你会看到类似这样的输出:

迁移允许我们随时间发展数据库模式。每个迁移都可以应用(up.sql)或还原(down.sql)。应用并立即恢复迁移应该使数据库模式保持不变。
接下来,我们将编写用于迁移的SQL:
# up.sql
CREATE TABLE posts (
id SERIAL PRIMARY KEY,
title VARCHAR NOT NULL,
body TEXT NOT NULL,
published BOOLEAN NOT NULL DEFAULT FALSE
)
# down.sql
DROP TABLE posts
我们可以应用我们的新迁移:
diesel migration run

确定一下down.sql 是正确的是个好主意。通过重新执行迁移,您可以快速确认您的down.sql来正确回滚迁移:
diesel migration redo

关于迁移中原始SQL的注意事项:
由于迁移是用原始SQL编写的,因此它们可以包含您使用的数据库系统的特定特性。例如,上面的CREATE TABLE语句使用了PostgreSQL的SERIAL类型。如果你想使用SQLite,你需要使用INTEGER。
关于在生产环境中使用迁移的注意事项:
在准备应用程序用于生产环境时,您可能希望在应用程序初始化阶段运行迁移。您可能还希望将迁移脚本作为代码的一部分,以避免将它们复制到部署位置/映像等。
diesel_migrations crate提供了embed_migrations!宏,允许您在最终的二进制文件中嵌入迁移脚本。一旦代码使用了它,您就可以在main函数的开头简单地包含connection.run_pending_migrations(MIGRATIONS),以便在每次应用程序启动时运行迁移。
1.4 Write Rust
好了,SQL说够了,让我们来写一些Rust。我们将首先编写一些代码来显示最近发布的五篇文章。我们需要做的第一件事是建立一个数据库连接。
// src/lib.rs
use diesel::pg::PgConnection;
use diesel::prelude::*;
use dotenvy::dotenv;
use std::env;
pub fn establish_connection() -> PgConnection {
dotenv().ok();
let database_url = env::var("DATABASE_URL").expect("DATABASE_URL must be set");
PgConnection::establish(&database_url)
.unwrap_or_else(|_| panic!("Error connecting to {}", database_url))
}
我们还需要创建一个Post结构体,我们可以在其中读取数据,并让diesel生成在查询中用于引用表和列的名称。
我们将把以下几行添加到src/lib.rs的顶部:
// src/lib.rs
pub mod models;
pub mod schema;
接下来,我们需要创建刚才声明的两个模块。
// src/models.rs
use diesel::prelude::*;
#[derive(Queryable)]
pub struct Post {
pub id: i32,
pub title: String,
pub body: String,
pub published: bool,
}
#[derived (Queryable)]将生成从SQL查询中加载Post结构所需的所有代码。
schema 模块通常不是手工创建的,而是由Diesel生成的。当我们运行diesel setup时,一个名为 diesel.toml的文件被创建,它告诉Diesel在src/schema.rs下维护一个文件。文件应该是这样的:
// src/schema.rs
// @generated automatically by Diesel CLI.
diesel::table! {
posts (id) {
id -> Int4,
title -> Varchar,
body -> Text,
published -> Bool,
}
}
根据数据库的不同,确切的输出可能略有不同,但应该是相等的。
table! 宏根据数据库模式创建一堆代码来表示所有的表和列。在下一个示例中,我们将看到如何准确地使用它。
每当我们运行或恢复迁移(migration)时,该文件都会自动更新。
A Note on Field Order
使用#[derive(Queryable)]假设Post结构体上字段的顺序与posts表中的列匹配,因此请确保按照schema.rs中看到的顺序定义它们。
让我们编写代码来实际显示我们的帖子。
// src/bin/show_posts.rs
use crate::models::*;
use diesel::prelude::*;
use diesel_demo::*;
use diesel_demo::schema::posts::dsl::*;
fn main(){
let connection = &mut establish_connection();
let results = posts
.filter(published.eq(true))
.limit(5)
.load::<Post>(connection)
.expect("Error loading posts");
println!("Displaying {} posts", results.len());
for post in results {
println!("{}", post.title);
println!("-----------\n");
println!("{}", post.body);
}
}
self::schema::posts::dsl::*行导入了一堆别名,这样我们就可以用posts来代替posts::table,用published来代替posts::published。当我们只处理单个表时,它很有用,但这并不总是我们想要的。
我们可以使用cargo run --bin show_posts来运行脚本。不幸的是,结果不会非常有趣,因为我们实际上在数据库中没有任何帖子。尽管如此,我们已经编写了相当数量的代码,所以让我们提交。

在这里可以找到演示的完整代码。
接下来,让我们编写一些代码来创建一个新帖子。我们需要一个用于插入新记录的结构体。
// src/models.rs
use crate::schema::posts;
#[derive(Insertable)]
#[diesel(table_name = posts)]
pub struct NewPost<'a> {
pub title: &'a str,
pub body: &'a str,
}
现在让我们添加一个保存新文章的函数。
// src/lib.rs
use crate::models::{NewPost, Post};
pub fn create_post(conn: &mut PgConnection, title: &str, body: &str) -> Post {
use crate::schema::posts;
let new_post = NewPost { title, body };
diesel::insert_into(posts::table)
.values(&new_post)
.get_result(conn)
.expect("Error saving new post")
}
当我们在插入或更新语句上调用.get_result 时,它会自动将RETURNING *添加到查询的末尾,并允许我们将其加载到任何为正确类型实现Queryable结构体中。整洁!
Diesel可以在单个查询中插入多条记录。只需传递Vec或slice来插入,然后调用get_results而不是get_result。如果您实际上不想对刚刚插入的行做任何事情,则调用.execute。这样编译器就不会向你抱怨了。😃
现在我们已经设置好了一切,我们可以创建一个小脚本来写一篇新文章。
// src/bin/write_post.rs
use diesel_demo::*;
use std::io::{stdin, Read};
fn main() {
let connection = &mut establish_connection();
let mut title = String::new();
let mut body = String::new();
println!("What would you like your title to be?");
stdin().read_line(&mut title).unwrap();
let title = title.trim_end(); // Remove the trailing newline
println!(
"\nOk! Let's write {} (Press {} when finished)\n",
title, EOF
);
stdin().read_to_string(&mut body).unwrap();
let post = create_post(connection, title, &body);
println!("\nSaved draft {} with id {}", title, post.id);
}
#[cfg(not(windows))]
const EOF: &str = "CTRL+D";
#[cfg(windows)]
const EOF: &str = "CTRL+Z";
我们可以使用cargo run --bin write_post来运行我们的新脚本。继续写一篇博文吧。很有创意!下面是我的:
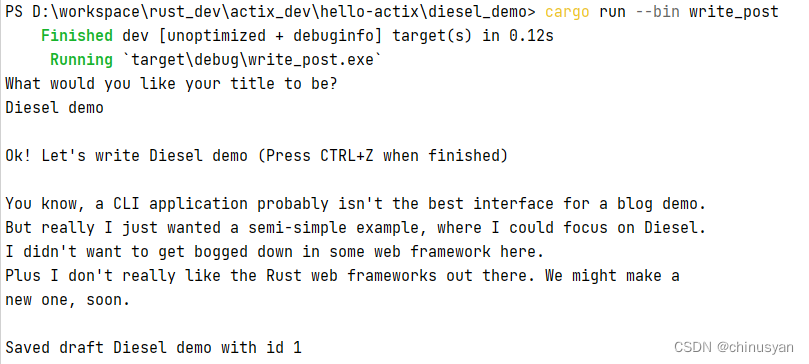
不幸的是,运行show_posts仍然不会显示我们的新帖子,因为我们将其保存为草稿。如果我们回头看看show_posts中的代码,我们添加了.filter(published.eq(true)),并且我们在迁移中将默认published 为false。我们需要发布它!但为了做到这一点,我们需要看看如何更新一个现有的记录。首先,让我们提交。这个演示的代码可以在这里找到。
现在我们已经完成了创建和读取,更新实际上相对简单。让我们直接进入脚本:
// src/bin/publish_post.rs
use self::models::Post;
use diesel::prelude::*;
use diesel_demo::*;
use std::env::args;
fn main() {
use self::schema::posts::dsl::{posts, published};
let id = args()
.nth(1)
.expect("publish_post requires a post id")
.parse::<i32>()
.expect("Invalid ID");
let connection = &mut establish_connection();
let post = diesel::update(posts.find(id))
.set(published.eq(true))
.get_result::<Post>(connection)
.unwrap();
println!("Published post {}", post.title);
}
就是这样!让我们用cargo run --bin publish_post 1进行试验。

现在,最后,运行cargo run --bin show_posts我们可以看到我们的post
尽管如此,我们仍然只讨论了CRUD的四个字母中的三个。让我们展示一下如何删除东西。有时我们写了一些我们非常讨厌的东西,我们没有时间去查ID。让我们基于标题删除,甚至是标题中的一些单词。
// src/bin/delete_post.rs
use diesel::prelude::*;
use diesel_demo::*;
use std::env::args;
fn main() {
use self::schema::posts::dsl::*;
let target = args().nth(1).expect("Expected a target to match against");
let pattern = format!("%{}%", target);
let connection = &mut establish_connection();
let num_deleted = diesel::delete(posts.filter(title.like(pattern)))
.execute(connection)
.expect("Error deleting posts");
println!("Deleted {} posts", num_deleted);
}
我们可以使用cargo run --bin delete_post demo运行脚本(至少使用我选择的标题)。你的输出应该看起来像这样:

当我们再次尝试运行cargo run --bin show_posts时,可以看到该帖子实际上已被删除。这仅仅触及了您可以使用Diesel做的事情的表面,但希望本教程已经为您提供了一个良好的基础。我们建议您查看API文档以了解更多信息。本教程的最终代码可以在这里找到。