1.简介
SnowFlake 中文意思为雪花,故称为雪花算法。最早是 Twitter 公司在其内部用于分布式环境下生成唯一 ID。在2014年开源 scala 语言版本。
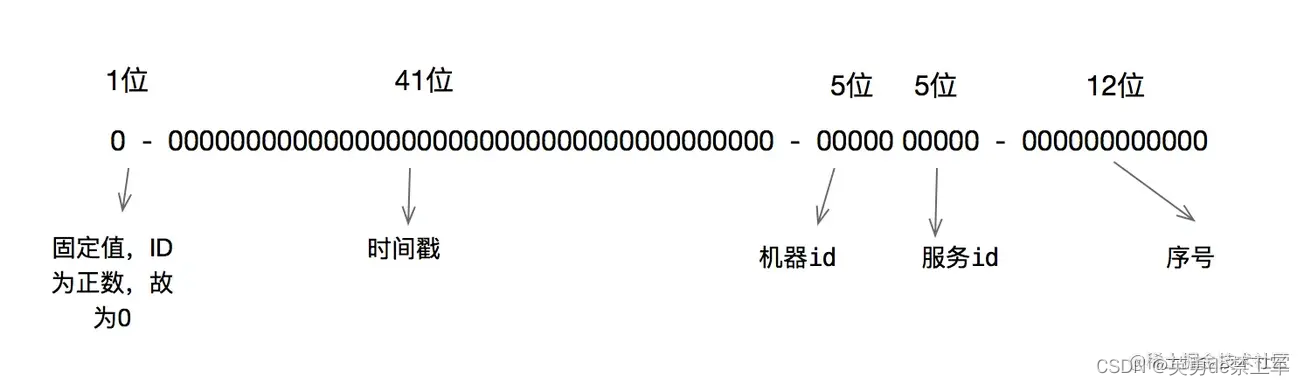
雪花算法的原理就是生成一个的 64 位比特位的 long 类型的唯一 id。
- 最高 1 位固定值 0,因为生成的 id 是正整数,如果是 1 就是负数了。
- 接下来 41 位存储毫秒级时间戳,2^41/(1000606024365)=69,大概可以使用 69 年。
- 再接下 10 位存储机器码,包括 5 位 datacenterId 和 5 位 workerId。最多可以部署 2^10=1024 台机器。
-最后 12 位存储序列号。同一毫秒时间戳时,通过这个递增的序列号来区分。即对于同一台机器而言,同一毫秒时间戳下,可以生成 2^12=4096 个不重复 id。
可以将雪花算法作为一个单独的服务进行部署,然后需要全局唯一 id 的系统,请求雪花算法服务获取 id 即可。
对于每一个雪花算法服务,需要先指定 10 位的机器码,这个根据自身业务进行设定即可。例如机房号+机器号,机器号+服务号,或者是其他可区别标识的 10 位比特位的整数值都行。
2.源码
package util;
import java.util.Date;
/**
* @ClassName: SnowFlakeUtil
* @Author: jiaoxian
* @Date: 2022/4/24 16:34
* @Description:
*/
public class SnowFlakeUtil {
private static SnowFlakeUtil snowFlakeUtil;
static {
snowFlakeUtil = new SnowFlakeUtil();
}
// 初始时间戳(纪年),可用雪花算法服务上线时间戳的值
// 1650789964886:2022-04-24 16:45:59
private static final long INIT_EPOCH = 1650789964886L;
// 时间位取&
private static final long TIME_BIT = 0b1111111111111111111111111111111111111111110000000000000000000000L;
// 记录最后使用的毫秒时间戳,主要用于判断是否同一毫秒,以及用于服务器时钟回拨判断
private long lastTimeMillis = -1L;
// dataCenterId占用的位数
private static final long DATA_CENTER_ID_BITS = 5L;
// dataCenterId占用5个比特位,最大值31
// 0000000000000000000000000000000000000000000000000000000000011111
private static final long MAX_DATA_CENTER_ID = ~(-1L << DATA_CENTER_ID_BITS);
// dataCenterId
private long dataCenterId;
// workId占用的位数
private static final long WORKER_ID_BITS = 5L;
// workId占用5个比特位,最大值31
// 0000000000000000000000000000000000000000000000000000000000011111
private static final long MAX_WORKER_ID = ~(-1L << WORKER_ID_BITS);
// workId
private long workerId;
// 最后12位,代表每毫秒内可产生最大序列号,即 2^12 - 1 = 4095
private static final long SEQUENCE_BITS = 12L;
// 掩码(最低12位为1,高位都为0),主要用于与自增后的序列号进行位与,如果值为0,则代表自增后的序列号超过了4095
// 0000000000000000000000000000000000000000000000000000111111111111
private static final long SEQUENCE_MASK = ~(-1L << SEQUENCE_BITS);
// 同一毫秒内的最新序号,最大值可为 2^12 - 1 = 4095
private long sequence;
// workId位需要左移的位数 12
private static final long WORK_ID_SHIFT = SEQUENCE_BITS;
// dataCenterId位需要左移的位数 12+5
private static final long DATA_CENTER_ID_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS;
// 时间戳需要左移的位数 12+5+5
private static final long TIMESTAMP_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS + DATA_CENTER_ID_BITS;
/**
* 无参构造
*/
public SnowFlakeUtil() {
this(1, 1);
}
/**
* 有参构造
* @param dataCenterId
* @param workerId
*/
public SnowFlakeUtil(long dataCenterId, long workerId) {
// 检查dataCenterId的合法值
if (dataCenterId < 0 || dataCenterId > MAX_DATA_CENTER_ID) {
throw new IllegalArgumentException(
String.format("dataCenterId 值必须大于 0 并且小于 %d", MAX_DATA_CENTER_ID));
}
// 检查workId的合法值
if (workerId < 0 || workerId > MAX_WORKER_ID) {
throw new IllegalArgumentException(String.format("workId 值必须大于 0 并且小于 %d", MAX_WORKER_ID));
}
this.workerId = workerId;
this.dataCenterId = dataCenterId;
}
/**
* 获取唯一ID
* @return
*/
public static Long getSnowFlakeId() {
return snowFlakeUtil.nextId();
}
/**
* 通过雪花算法生成下一个id,注意这里使用synchronized同步
* @return 唯一id
*/
public synchronized long nextId() {
long currentTimeMillis = System.currentTimeMillis();
System.out.println(currentTimeMillis);
// 当前时间小于上一次生成id使用的时间,可能出现服务器时钟回拨问题
if (currentTimeMillis < lastTimeMillis) {
throw new RuntimeException(
String.format("可能出现服务器时钟回拨问题,请检查服务器时间。当前服务器时间戳:%d,上一次使用时间戳:%d", currentTimeMillis,
lastTimeMillis));
}
if (currentTimeMillis == lastTimeMillis) {
// 还是在同一毫秒内,则将序列号递增1,序列号最大值为4095
// 序列号的最大值是4095,使用掩码(最低12位为1,高位都为0)进行位与运行后如果值为0,则自增后的序列号超过了4095
// 那么就使用新的时间戳
sequence = (sequence + 1) & SEQUENCE_MASK;
if (sequence == 0) {
currentTimeMillis = getNextMillis(lastTimeMillis);
}
} else { // 不在同一毫秒内,则序列号重新从0开始,序列号最大值为4095
sequence = 0;
}
// 记录最后一次使用的毫秒时间戳
lastTimeMillis = currentTimeMillis;
// 核心算法,将不同部分的数值移动到指定的位置,然后进行或运行
// <<:左移运算符, 1 << 2 即将二进制的 1 扩大 2^2 倍
// |:位或运算符, 是把某两个数中, 只要其中一个的某一位为1, 则结果的该位就为1
// 优先级:<< > |
return
// 时间戳部分
((currentTimeMillis - INIT_EPOCH) << TIMESTAMP_SHIFT)
// 数据中心部分
| (dataCenterId << DATA_CENTER_ID_SHIFT)
// 机器表示部分
| (workerId << WORK_ID_SHIFT)
// 序列号部分
| sequence;
}
/**
* 获取指定时间戳的接下来的时间戳,也可以说是下一毫秒
* @param lastTimeMillis 指定毫秒时间戳
* @return 时间戳
*/
private long getNextMillis(long lastTimeMillis) {
long currentTimeMillis = System.currentTimeMillis();
while (currentTimeMillis <= lastTimeMillis) {
currentTimeMillis = System.currentTimeMillis();
}
return currentTimeMillis;
}
/**
* 获取随机字符串,length=13
* @return
*/
public static String getRandomStr() {
return Long.toString(getSnowFlakeId(), Character.MAX_RADIX);
}
/**
* 从ID中获取时间
* @param id 由此类生成的ID
* @return
*/
public static Date getTimeBySnowFlakeId(long id) {
return new Date(((TIME_BIT & id) >> 22) + INIT_EPOCH);
}
public static void main(String[] args) {
SnowFlakeUtil snowFlakeUtil = new SnowFlakeUtil();
long id = snowFlakeUtil.nextId();
System.out.println(id);
Date date = SnowFlakeUtil.getTimeBySnowFlakeId(id);
System.out.println(date);
long time = date.getTime();
System.out.println(time);
System.out.println(getRandomStr());
}
}
3.算法优缺点
雪花算法有以下几个优点:
- 高并发分布式环境下生成不重复 id,每秒可生成百万个不重复 id。
- 基于时间戳,以及同一时间戳下序列号自增,基本保证 id 有序递增。
- 不依赖第三方库或者中间件。
- 算法简单,在内存中进行,效率高。
雪花算法有如下缺点:
- 依赖服务器时间,服务器时钟回拨时可能会生成重复 id。算法中可通过记录最后一个生成 id 时的时间戳来解决,每次生成 id 之前比较当前服务器时钟是否被回拨,避免生成重复 id。
4.注意事项
其实雪花算法每一部分占用的比特位数量并不是固定死的。例如你的业务可能达不到 69 年之久,那么可用减少时间戳占用的位数,雪花算法服务需要部署的节点超过1024 台,那么可将减少的位数补充给机器码用。
注意,雪花算法中 41 位比特位不是直接用来存储当前服务器毫秒时间戳的,而是需要当前服务器时间戳减去某一个初始时间戳值,一般可以使用服务上线时间作为初始时间戳值。
对于机器码,可根据自身情况做调整,例如机房号,服务器号,业务号,机器 IP 等都是可使用的。对于部署的不同雪花算法服务中,最后计算出来的机器码能区分开来即可。
参考网址
链接1🔗
链接2🔗