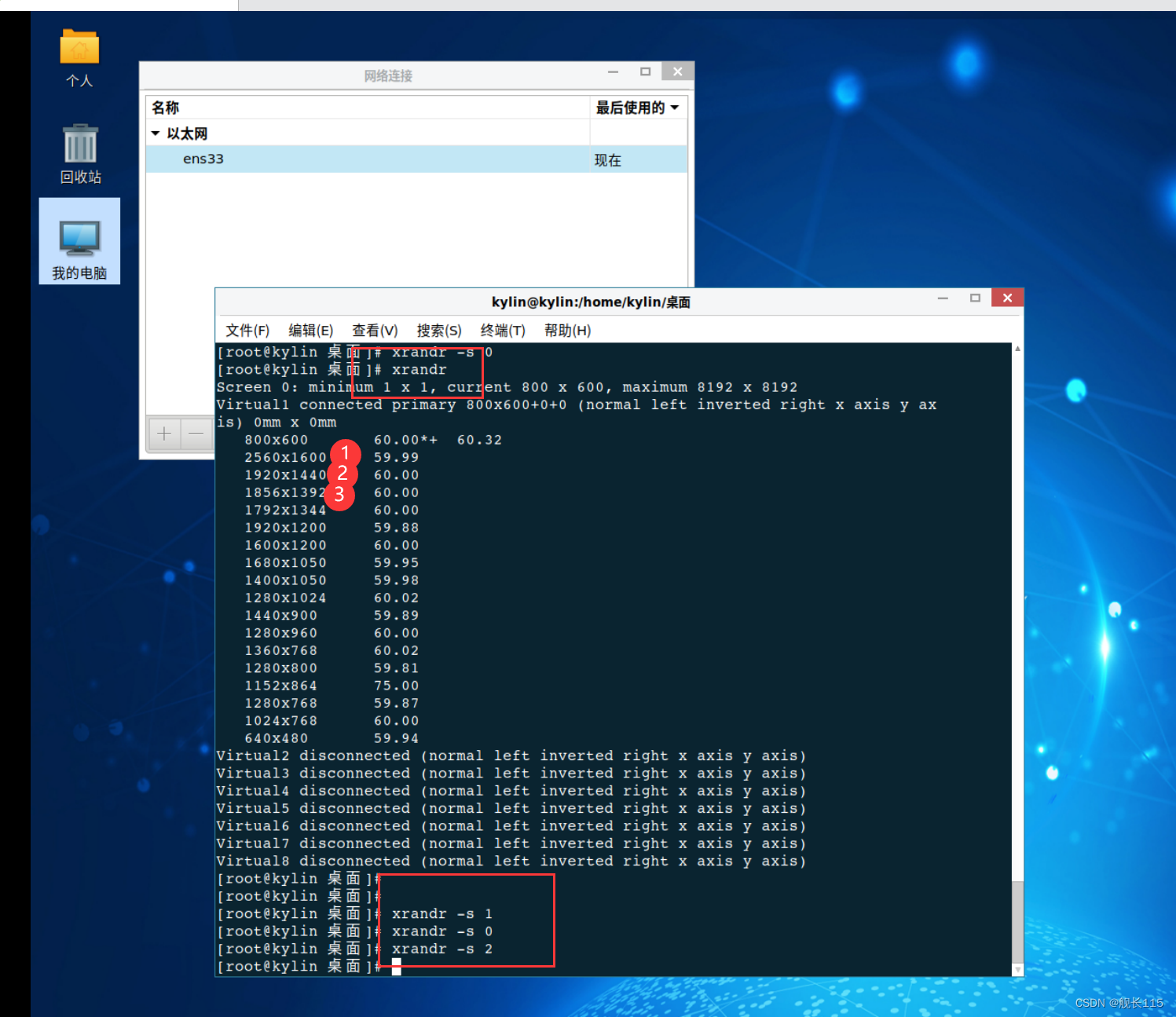
Java9
- (一)、stream流
- 1.1 Stream流的中间方法和终结方法
- (二)、方法引用
- 2.1 方法引用的分类
- (三)、异常
- 3.1 编译时异常和运行时异常
- 3.2 异常的作用
- 3.3 异常的处理方式
- 3.4 异常中的常见方法
- 3.5 自定义异常
- (四)、File
- 4.1 成员方法
- (五)、IO流
- 5.1 分类
- 5.2 字节流的基本使用
- 5.2.1FileOutputStream
- 5.2.2 FileInputStream
- 5.3 IO流中不同的jdk版本捕获异常的方式
- 5.4 字符集详解
- 5.5 Java中的编码和解码
- 5.6 字符流的基本使用
- 5.6.1 字符输入流
- 5.6.2 字符输出流
(一)、stream流
1.先得到一条stream流,并把数据放上去
2.利用stream流中的Api进行各种操作(中间方法,终结方法)
获取stream流

使用of时,如果将基本类型的数组放进去,会将整个数组当做一个元素,放进stream中
传递数组必须传引用数据类型
1.1 Stream流的中间方法和终结方法
中间方法:
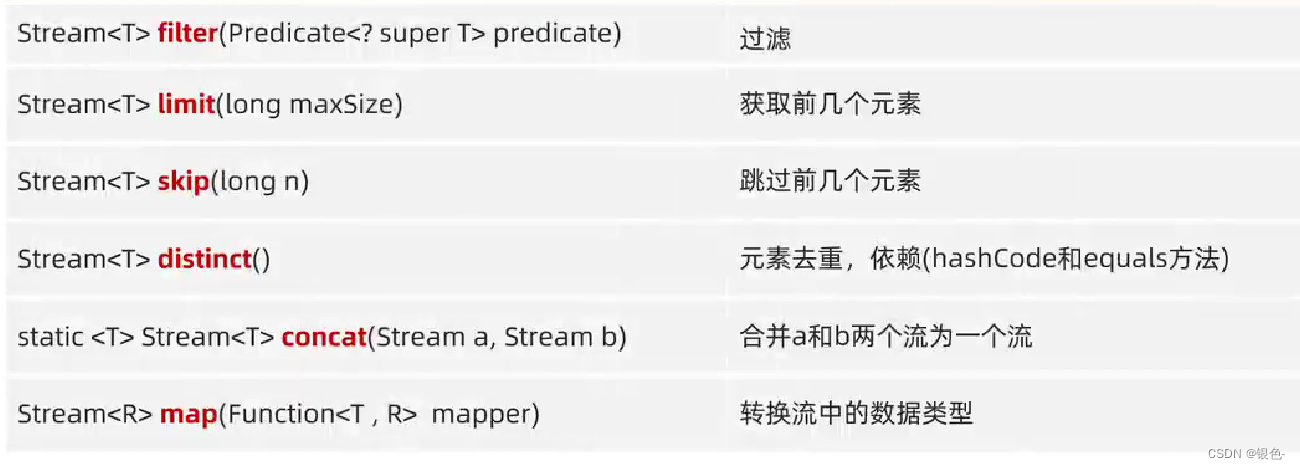
注:修改stream流中的数据,不会影响原数组或集合中的数据
中间方法会返回新的stream流,原来的stream流只会用一次,建议链式编程
合并时,如果两个流的类型不一样,会提升为两个类型的父类(类型的提升)
终结方法:
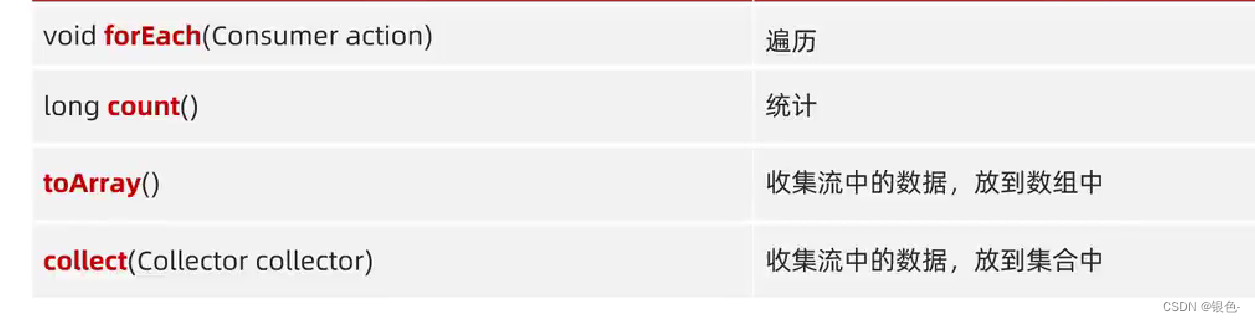
toArray的返回值是装着流中所有数据的数组,这个方法中的形参是创建一个指定类型数组
底层:依次得到每一个数据,放进数组当中
collect方法注意点:
收集到map集合中,键不能重复,否则会报错
练习1:

代码:
package day3next;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.stream.Collectors;
public class stream1 {
public static void main(String[] args) {
ArrayList<Integer> a1=new ArrayList<>();
/*a1.add(1);
a1.add(2);
a1.add(3);
a1.add(4);
a1.add(5);
a1.add(6);
a1.add(7);
a1.add(8);
a1.add(9);
a1.add(10);
add方法一个一个添加数据
*/
Collections.addAll(a1,1,2,3,4,5,6,7,8,9,10);
//批量添加数据
//System.out.println(a1);
//a1.stream().filter(n->n%2==0).forEach(n-> System.out.println(n));
//先把数组放到stream流中,再用filter过滤,留下偶数,最后用foreach打印
List<Integer> list1 = a1.stream()
.filter(n -> n % 2 == 0)
.collect(Collectors.toList());
//最后用collect收集数据,收集到list数组中
System.out.println(list1);
}
}
练2:

package day3next;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Map;
import java.util.function.Function;
import java.util.stream.Collectors;
public class stream2 {
public static void main(String[] args) {
ArrayList<String> list1=new ArrayList<>();
Collections.addAll(list1,"zhangsan,23","lisi,24","wangwu,25");
//System.out.println(list1);
// list1.stream().filter(s->Integer.parseInt(s.split(",")[1])>=24)
// .collect(Collectors.toMap(new Function<String, String>() {
// @Override
// public String apply(String s) {
// return s.split(",")[0];
// }
// }, new Function<String, Integer>() {
// @Override
// public Integer apply(String s) {
// return Integer.parseInt(s.split(",")[1]);
// }
// })); 匿名内部类的具体写法,一般使用lambda表达式。
// toMap中两个参数,第一个表示的是键的规则,第二个表示的是值的规则
Map<String, Integer> maplist1 = list1.stream().filter(s -> Integer.parseInt(s.split(",")[1]) >= 24)
.collect(Collectors.toMap(s -> s.split(",")[0], s -> Integer.parseInt(s.split(",")[1])));
System.out.println(maplist1);
}
}
练3:

package day3next;
import javafx.print.Collation;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class stream3 {
public static void main(String[] args) {
ArrayList<String> list1=new ArrayList<>();
ArrayList<String> list2=new ArrayList<>();
Collections.addAll(list1,"蔡坤坤,23","刘不甜,24","王三五,25","杨七六,26","陈七,27","沙八,28");
Collections.addAll(list2,"张一,20","陈二,21","王三,22","杨四,22","杨五,23","赵七,24");
Stream<String> man = list1.stream().filter(s -> s.split(",")[0].length() == 3)
.limit(2);
Stream<String> woman = list2.stream().filter(s -> s.split(",")[0].startsWith("杨"))
.skip(1);
//stratWith筛选开头为杨的人
List<Actor> listall = Stream.concat(man, woman)
.map(s -> new Actor(s.split("',")[0], Integer.parseInt(s.split(",")[1])))
.collect(Collectors.toList());
//使用concat合并两个流,然后再使用map将数据变成actor对象
System.out.println(listall);
}
}
(二)、方法引用
把已有方法拿过来使用,当做函数式接口中抽象方法的方法体
要求:
1.引用处必须是函数式接口
2.被引用方法必须已经存在
3.被引用方法的形参和返回值需要跟抽象方法保持一致
4.被引用的方法必须满足当前需求
调用格式:类名::方法名
::是方法引用符
2.1 方法引用的分类
1.引用静态方法
格式:类名::静态方法
package yingyong;
import java.util.ArrayList;
import java.util.Collections;
public class yy1 {
public static void main(String[] args) {
ArrayList<String> list=new ArrayList<>();
Collections.addAll(list,"1","2","3","6");
list.stream()
.map(Integer::parseInt)
.forEach(s-> System.out.println(s));
//直接引用Integer中的parseInt方法,将list中的字符串转为整数
}
}
2.引用成员方法
格式:对象::成员方法

静态方法是没有this的,如果要调用本类静态方法,则直接创建一个本类的对象进行调用
3.引用构造方法
格式:类名::new
4.类名引用成员方法
格式:类名::成员方法
特殊规则:被引用方法的形参,需要跟抽象方法的第二个形参到最后一个形参保持一致,返回值需要保持一致
其他规则一样

不能引用所有类中的成员方法
5.引用数组的构造方法
格式:数据类型[]::new
数组的类型,需要跟流中的数据类型保持一致
数组底层存在构造方法
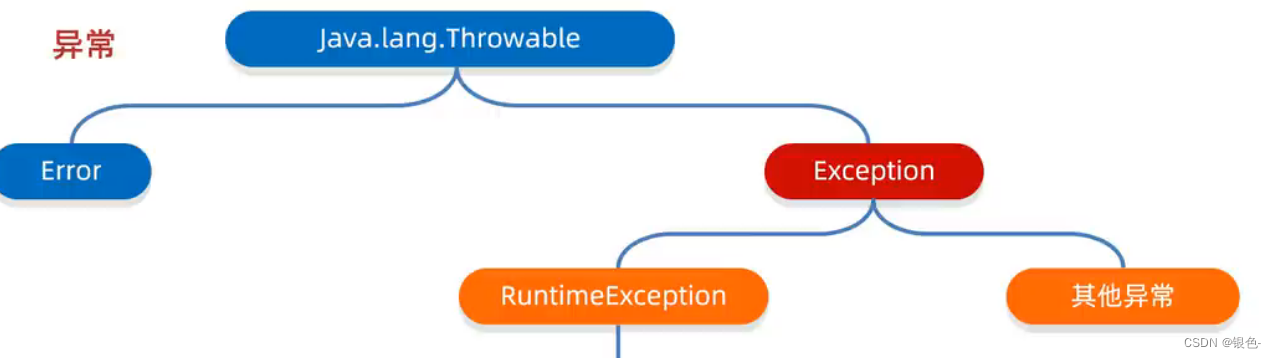
(三)、异常
异常就是代表程序出现问题
学会出了异常如何处理
Error:代表系统级别的错误
是sun公司自己使用的,开发人员不用管
Exception:异常,代表程序可能会出现的问题
通常用Exception以及它的子类来封装程序出现的问题
RuntimeException:运行时出现的异常,编译阶段不会出现异常提醒
编译时异常:编译阶段就出现异常提醒
3.1 编译时异常和运行时异常
编译时异常:在编译阶段,必须手动处理,不然报错。主要是提醒程序员检查本地信息。
运行时异常:编译阶段不用处理,代码运行时才会出现
3.2 异常的作用
1.异常是用来查询bug的关键信息
2.异常可以作为方法内部的一种特殊返回值,以便通知调用者底层的执行情况
3.3 异常的处理方式
-
JVM默认的处理方式:
把异常的名称,异常原因以及异常出现的位置等信息输出在控制台
程序停止运行,下面的代码不执行 -
自己处理(捕获异常)
格式:
try{
可能出现异常的代码
}catch(异常类名 变量名){
异常的处理代码
}
目的:当代码出现异常,程序可以继续往下执行
问1:如果try中没有遇到问题,会怎么执行?
会把try中的代码全部执行完毕,不会执行catch中的代码
只有出现了异常才会执行catch里的代码
问2:如果try中遇到多个问题,怎么执行?
会写多个 catch与之对应
若这些异常存在父子关系,则父类一定要写在下面
jdk7后,可以在catch中同时捕获多个异常,中间用 | 隔开
问3:如果try中遇到的问题没有被捕获,怎么执行?
相当于try catch白写,最终交给虚拟机处理
问4:如果try中遇到了问题,那么try下面的代码还会执行吗
下面的代码不会执行,会直接跳转到对应的catch当中,执行catch里的语句体
若没有与之对应的catch语句体,那么还是交给虚拟机处理
-
抛出处理
throws :写在方法定义处,表示声明一个异常
告诉调用者,本方法可能有的异常
编译时异常必须要写,运行时异常可以不写格式:

throw:写在方法内,结束方法
手动抛出异常对象,交给调用者
方法中下面的代码就不再执行了对调用者的异常需要进行处理,不然最终会交给虚拟机处理

3.4 异常中的常见方法

Throwable类中的方法
printStackTrace只是打印错误信息,不会停止程序运行。以红色字体将错误输出在控制台
练习:

测试代码:
package yingyong;
import java.util.Scanner;
public class g1 {
public static void main(String[] args) {
Scanner sc=new Scanner(System.in);
GirlFriend gf =new GirlFriend();
while (true) {
try {
System.out.println("请输入女朋友的名字");
String name = sc.nextLine();
gf.setName(name);
System.out.println("请输入女朋友年龄");
String ageStr=sc.nextLine();
int age = Integer.parseInt(ageStr);
gf.setAge(age);
break;
} catch (NumberFormatException e) {
System.out.println("年龄格式有误,请输入数字");
}catch (RuntimeException e){
System.out.println("姓名的长度或年龄范围错误");
}
}
System.out.println(gf);
}
}
GrilFriend类:
package yingyong;
public class GirlFriend {
private String name;
private int age;
public GirlFriend() {
}
public GirlFriend(String name, int age) {
this.name = name;
this.age = age;
}
/**
* 获取
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
* @param name
*/
public void setName(String name) {
int len=name.length();
if (len<3 || len>10){
throw new RuntimeException();
}
this.name = name;
}
/**
* 获取
* @return age
*/
public int getAge() {
return age;
}
/**
* 设置
* @param age
*/
public void setAge(int age) {
if (age<18 ||age>40){
throw new RuntimeException();
}
this.age = age;
}
public String toString() {
return "GirlFriend{name = " + name + ", age = " + age + "}";
}
}
3.5 自定义异常
1.定义异常类
2.写继承关系
3.空参构造
4.带参构造
运行时异常继承:RuntimeException
编译时异常继承:Exception
(四)、File
File对象表示一个路径,可以是文件的,也可以是文件夹的
可以存在,也可以不存在
构造方法 :

后两个方法都是路径的拼接
绝对路径:带盘符的路径
相对路径:不带盘符,默认在当前项目下找
4.1 成员方法
判断和获取:

length方法 只能返回文件的大小 ,单位是字节
getName 如果是文件,会返回文件名字和后缀名、拓展名
如果是文件夹,只会返回名字
创建和删除:

delete方法默认只能删文件和空文件夹,直接删除不走回收站
不能删除有内容的文件夹
createNewFile 如果当前路径表示的文件不存在,则创建成功,方法返回true。反之,不成功
如果父级路径不存在,会有异常IOExpection
此方法创建的一定是文件,如果路径中不包含后缀名,则创建的是一个没有后缀的文件
mkdir:在windows中,路径是唯一的。只能创建单级文件夹
获取并遍历:

注:

练1:删除一个多级文件夹:使用递归思想
package filedemo;
import java.io.File;
public class file2 {
public static void main(String[] args) {
File file =new File("D:\\aaa\\src");
delete(file);
}
public static void delete(File src){
//1.先进入文件夹删除里面的所有内容
//进入src
File[] files =src.listFiles();
//遍历里面的内容
for (File file : files) {
if (file.isFile()){
file.delete();//判断是文件还是文件夹,文件就删除
}else {
delete(file);
//是文件夹就递归
}
}
//2.再删除自己
src.delete();
}
}
练2:统计文件总大小
package filedemo;
import java.io.File;
public class file3 {
public static void main(String[] args) {
File f1=new File("D:\\aaa");
long len1 = getLen(f1);
System.out.println(len1);
}
public static long getLen(File src){
//1.定义变量len用来记录文件的大小
long len=0;
//2.进入文件夹aaa
File[] files=src.listFiles();
//3.遍历
for (File file : files) {
if(file.isFile()){
len+=file.length();
}else {
len+=getLen(file);
//递归传递的参数是子类文件夹
//递归后len是一个新的变量,所以返回值是返回给调用者也就是getLen(file)
}
}
return len;
}
}
练3:

package filedemo;
import java.io.File;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class file4 {
public static void main(String[] args) {
File file=new File("D:\\aaa");
HashMap<String, Integer> result = getCount(file);
System.out.println(result);
}
//统计一个文件夹中各种文件的个数
//返回值:用来统计的map集合
//键:后缀名,值:次数
public static HashMap<String,Integer> getCount(File src){
HashMap<String,Integer> hm=new HashMap<>();
File[] files = src.listFiles();
for (File file : files) {
if (file.isFile()){
String name=file.getName();//获取文件名和后缀名
String[] arr=name.split("\\.");//将得到的字符串切割,获得后缀名
if (arr.length>=2){
String endname=arr[arr.length-1];//endname为后缀名
if(hm.containsKey(endname)){
//键已经存在的情况
int count=hm.get(endname);//键已经存在,则让值+1
count++;
hm.put(endname,count);
}else {
//键不存在的情况
hm.put(endname,1);//添加新的键,并且值设为1
}
}
}else {
//子文件夹中的统计情况
HashMap<String, Integer> sonMap = getCount(file);
Set<Map.Entry<String, Integer>> entries = sonMap.entrySet();//表示每一个键值对
for (Map.Entry<String, Integer> entry : entries) {
String key = entry.getKey();//sonMap中每个键值对中的键
int value = entry.getValue();//sonMap中每个键值对中的值
if (hm.containsKey(key)){
//如果hm中存在和sonmap中的键,则直接将值累加进hm中
Integer count = hm.get(key);
count+=value;
hm.put(key,count);
}else {
//如果不存在,直接将键和值存进去
hm.put(key,value);
}
}
}
}
return hm;
}
}
(五)、IO流
存储和读取数据的解决方案
所有的输入和输出都是相对于程序来说
5.1 分类
流的方向:
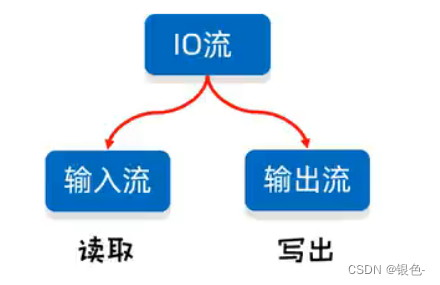
输出流:程序-> 文件
输入流:文件-> 程序
操作文件类型:
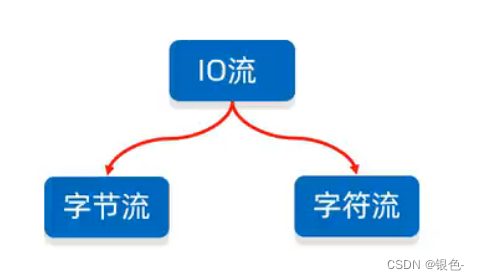
字节流可以操作所有类型文件
字符流只能操作纯文本文件(Windows自带的记事本能打开并且读懂的,如md,txt文件)
5.2 字节流的基本使用
两类都是抽象类,不能直接用
InputStream:字节输入流
OutputStream:字节输出流
5.2.1FileOutputStream
操作本地文件的字节输出流,可以把程序数据写到本地文件中
步骤:
1.创建字节输出流对象(创建时要指定文件的路径)
注意:
1.1:参数是字符串表示的路径或file对象都可以
1.2:如果文件不存在会创建一个新的文件,但是要保证父级路径存在
1.3:如果文件存在,则会清空文件
2.写数据
注:
2.1write方法中的参数是整数,但是实际上写到本地文件中是ASCII表上对应的字符
3.释放资源
注:3.1每次使用完后都要释放资源
如果不释放,文件会一直被java占用
简单使用:
package IOstudy;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class i1 {
public static void main(String[] args) throws IOException {
FileOutputStream fos=new FileOutputStream("day4\\a.txt");//相当于创建了一个传输通道
fos.write(97);//传入数据
fos.close();//关闭传输通道
}
}
写数据的多种方法:

package IOstudy;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class i1 {
public static void main(String[] args) throws IOException {
FileOutputStream fos=new FileOutputStream("day4\\a.txt");
// 第二种方法
// fos.write(97);
// fos.close();
/*第三种方法
* void write(byte[],int off, int len)
* 参数一:数组
* 参数二:起始索引
* 参数三:个数 (写入的个数)
*
* fos.write(bytes,1,2);
* fos.close();
* */
}
}
两个问题:
换行:写出一个换行符
Windows:\r\n
Linux:\n
Mac: \r
Windows系统中,Java对换行进行了优化,写\r或\n都可以,底层会补全
package IOstudy;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class i3 {
public static void main(String[] args) throws IOException {
FileOutputStream fos=new FileOutputStream("day4\\a.txt");
String str="asdwdsqweqeadad";
byte[] bytes = str.getBytes();
fos.write(bytes);
String str2="\r\n";
byte[] bytes2 = str2.getBytes();
fos.write(bytes2);
String str3="as213131eqeadad";
byte[] bytes3 = str3.getBytes();
fos.write(bytes3);
fos.close();
}
}
续写:创建FileOutputStream对象时,第二个参数是控制续写开关,默认是false
打开续写后,再次创建就不会清空文件里的数据
5.2.2 FileInputStream
操作本地文件的字节输入流,可以把本地文件的数据读取到程序中来
步骤:
-
创建字节输入流的对象
注:如果文件不存在,则直接报错 -
读数据
注:使用read()读取,有int返回值。一个一个读取,读取的结果是在ASCII上对应的数字,如果读取不到则返回-1
循环读取:
package IOstudy;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class i4 {
public static void main(String[] args) throws IOException {
FileInputStream fis=new FileInputStream("day4\\a.txt");
int b;//用来接受读取到的数据,返回-1时,循环结束
while ((b=fis.read()) != -1){
System.out.println((char)b);
}
fis.close();
}
}
- 释放资源
练习:文件拷贝
package IOstudy;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class i5 {
public static void main(String[] args) throws IOException {
FileInputStream fis=new FileInputStream("D:\\新建文件夹 (6)\\t1.mp4");//把数据写进程序
FileOutputStream fos=new FileOutputStream("day4\\copy.mp4");//把数据写到本地
int b;//读取t1.mp4中的数据
while ((b=fis.read()) !=-1){
fos.write(b);//将读取到的数据写进copy中
}
//先开的流后关
fos.close();
fis.close();
}
}
弊端:速度慢,一次只读一个字节
读取多个数据:每次读取会尽量填满数组
会返回一次读取了几个数据,并且会将读取到的数据填进数组中
每次读取都是在覆盖数组里的数据,所以有时候会造成数据的残留
解决方法:
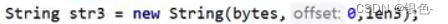

一般数组的大小为1024的整数倍
5.3 IO流中不同的jdk版本捕获异常的方式
try catch finally
finally中的代码一定被执行,除非虚拟机停止
AutoCloseable 自动释放接口
5.4 字符集详解
ASCII编码规则:前面补0,补齐8位
解码规则:直接转成10进制
GBK:英文也是一个字节存储,兼容ASCII。不足8位,补0
汉字规则:使用2个字节存储,编码不用变动。高位字节二进制一定以1开头,转成10进制后是一个负数
简中Windows默认使用GBK

Unicode:万国码
UTF-8 :1-4个字节保存
中文用三个字节,英文一个字节

UTF-8是一种编码方式
为什么会有乱码?
1.读取数据时未读完整个汉字
字节流一次读取一个字节
2.编码和解码方式不统一
解决方法:

5.5 Java中的编码和解码
编码方法:

解码方法:

5.6 字符流的基本使用
Reader:字符输入流
Writer:字符输出流
字符输入流的底层:创建对象时,会创建一个缓冲区(长度为8192的字节数组)
读取数据时,判断缓冲区有没有数据可以读取
缓冲区没有数据,就从文件中获取数据,装到缓冲区中,每次尽可能装满缓冲区
缓冲区有数据:直接从缓冲区读取
字符输出流的底层:写进去的数据会先存进缓冲区,当缓冲区满了或flush(手动刷新)或释放资源,才会将数据存入目的地。
flush:刷新之后,还能继续往文件中写数据

5.6.1 字符输入流
FileReader:操作本地文件的字符输入流
1.创建对象
文件不存在则直接报错
构造方法:

2.读取数据

空参read,读取数据后,在底层会进行解码并转成10进制,然后返回,这些10进制数字也表示在字符集上的数字
有参read,把强转后的字符放到数组当中
3.释放资源
close()
5.6.2 字符输出流
FileWriter:操作本地文件的字符输出流
构造方法:

成员方法:

步骤和注意事项:

练1:
拷贝文件夹
package IOstudy;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.lang.annotation.ElementType;
public class i6 {
public static void main(String[] args) {
//数据源
File src=new File("D:\\aaa");
//目的地
File dest=new File("D:\\bbb");
}
private static void copydir(File src,File dest) throws IOException{
dest.mkdirs();//如果文件夹不存在就直接创建,存在就直接创建失败
File[] files=src.listFiles();//获取数据
//遍历数组
for (File file : files) {
if (file.isFile()){
FileInputStream fis=new FileInputStream(file);//当前遍历到的数据作为数据源
//将父级路径和子级路径拼接,如果目的地没有相应的文件,则直接创建出来
//file.getName()获取当前数据源的名字和后缀
FileOutputStream fos=new FileOutputStream(new File(dest,file.getName()));
byte[] bytes=new byte[1024];
int len;
while ((len=fis.read(bytes)) !=-1){
fos.write(bytes,0,len);//写入数据
}
fos.close();
fis.close();
}else {
//递归的目的地应该是子类路径,如果不存在就直接创建出来
copydir(file,new File(dest,file.getName()));
}
}
}
}
练2:文件加密

使用异或:^
两次^得到原始数据
package IOstudy;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class i7 {
public static void main(String[] args) throws IOException {
//原始文件
FileInputStream fis=new FileInputStream("day4\\331.jpg");
//加密文件
FileOutputStream fos=new FileOutputStream("day4\\ency.jpg");
//拷贝时进行加密处理
int b;
while ((b= fis.read()) !=-1){
fos.write(b^2);
}
fos.close();
fis.close();
}
}
解密时:将加密文件变为数据源,解密后的文件为目的文件,其他不变