一、属性声明
1、存储段:section
1.1 GNU C编译器扩展关键字:__attribute__
GNU C增加了一个__attribute__关键字用来声明一个函数、变量或类型的特殊属性。主要用途就是指导编译器在编译程序时进行特定方面的优化或代码检查。例如,我们可以通过属性声明来指定某个变量的数据对齐方式。
__attribute__的使用非常简单,当我们定义一个函数、变量或类型时,直接在它们名字旁边添加下面的属性声明即可。

需要注意的是,__attribute__后面是两对小括号,不能图方便只写一对,否则编译就会报错。括号里面的ATTRIBUTE表示要声明的属性。目前__attribute__支持十几种属性声明。
- section.
- aligned.
- packed.
- format.
- weak.
- alias.
- noinline.
- always_inline.
aligned和packed用来显式指定一个变量的存储对齐方式。在正常情况下,当我们定义一个变量时,编译器会根据变量类型给这个变量分配合适大小的存储空间,按照默认的边界对齐方式分配一个地址。而使用__atttribute__这个属性声明,就相当于告诉编译器:按照我们指定的边界对齐方式去给这个变量分配存储空间。

有些属性可能还有自己的参数。如aligned(8)表示这个变量按8字节地址对齐,属性的参数也要使用小括号括起来,如果属性的参数是一个字符串,则小括号里的参数还要用双引号引起来。
1.2 属性声明:section
section属性的主要作用是:在程序编译时,将一个函数或变量放到指定的段,即放到指定的section中。一个可执行文件主要由代码段、数据段、BSS段构成。除了这三个段,可执行文件中还包含其他一些段。用编译器的专业术语讲,还包含其他一些section,如只读数据段、符号表等。
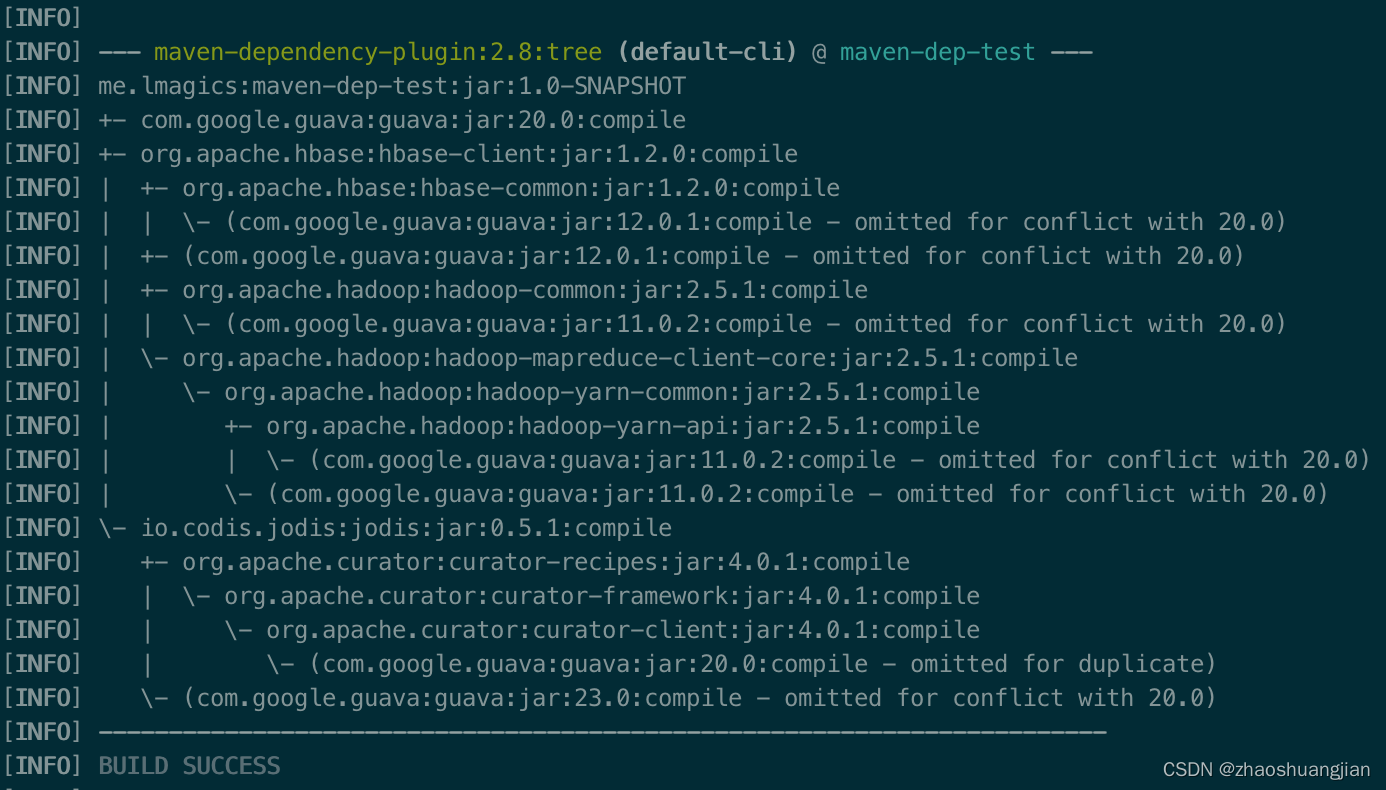
在Linux环境下,使用GCC编译生成一个可执行文件a.out,使用readelf命令,就可以查看这个可执行文件中各个section的基本信息,如大小、起始地址等。在这些section中,.text section就是我们常说的代码段,.data section是数据段,.bss section是BSS段。


编译器在编译程序时,以源文件为单位,将一个个源文件编译生成一个个目标文件。在编译过程中,编译器都会按照这个默认规则,将函数、变量分别放在不同的section中,最后将各个section组成一个目标文件。编译过程结束后,链接器会将各个目标文件组装合并、重定位,生成一个可执行文件。

在GNU C中,我们可以通过__attribute__的section属性,显式指定一个函数或变量,在编译时放到指定的section里面。通过上面的程序我们知道,未初始化的全局变量默认是放在.bss section中的,即默认放在BSS段中。现在我们就可以通过section属性声明,把这个未初始化的全局变量放到数据段.data中。
通过readelf命令查看符号表,我们可以看到,uninit_val这个未初始化的全局变量,通过__attribute__((section(".data")))属性声明,就和初始化的全局变量一样,被编译器放在了数据段.data中。
1.3 U-boot镜像自复制分析
有了section这个属性声明,我们就可以试着分析:U-boot在启动过程中,是如何将自身代码加载的RAM中的。
嵌入式Linux中,U-boot的用途主要是加载Linux内核镜像到内存,给内核传递启动参数,然后引导Linux操作系统启动。U-boot一般存储在NOR Flash或NAND Flash上。无论从NOR Flash还是从NAND Flash启动,U-boot其本身在启动过程中,都会从Flash存储介质上加载自身代码到内存,然后进行重定位,跳到内存RAM中去执行。
那么U-boot是怎么完成代码自复制的呢?或者说它是怎样将自身代码从Flash复制到内存的呢?
在复制自身代码的过程中,一个主要的疑问就是:U-boot是如何识别自身代码的?是如何知道从哪里开始复制代码的?是如何知道复制到哪里停止的?这时候我们需要了解U-boot源码中的一个零长度数组。
 这两行代码的作用是分别定义一个零长度数组,并指示编译器要分别放在.__image_copy_start和.__image_copy_end这两个section中。
这两行代码的作用是分别定义一个零长度数组,并指示编译器要分别放在.__image_copy_start和.__image_copy_end这两个section中。
链接器在链接各个目标文件时,会按照链接脚本里各个section的排列顺序,将各个section组装成一个可执行文件。


通过链接脚本我们可以看到,__image_copy_start和__image_copy_end这两个section,在链接的时候分别放在了代码段.text的前面、数据段.data的后面,作为U-boot复制自身代码的起始地址和结束地址。**而在这两个section中,我们除了放两个零长度数组,并没有放其他变量,众所周知,零长度数组是不占用存储空间的。**因此以上两个零长度数组分别代表了U-boot镜像要复制自身镜像的起始地址和结束地址。无论U-boot自身镜像存储在NOR Flash,还是存储在NAND Flash上,只要知道了这两个地址,我们就可以直接调用相关代码复制。
在嵌入式系统中,通过ARM的LDR伪指令,直接获取要复制镜像的首地址,并保存在R1寄存器中。数组名本身其实就代表一个地址,通过这种方式,U-boot在嵌入式启动的初始阶段,就完成了自身代码的复制工作:从Flash复制自身镜像到内存中,然后进行重定位,最后跳到内存中执行。
2、属性声明:aligned
2.1 地址对齐:aligned
GNU C通过__attribute__来声明aligned和packed属性,指定一个变量或类型的对齐方式。这两个属性用来告诉编译器:在给变量分配存储空间时,要按指定的地址对齐方式给变量分配地址。
定义一个int变量,在内存中以8字节地址对齐,就可以这样定义。
 在上面的程序中,我们分别定义2个int型变量、2个char型变量,然后分别打印它们的地址,运行结果如下。
在上面的程序中,我们分别定义2个int型变量、2个char型变量,然后分别打印它们的地址,运行结果如下。
 对于int型数据,其在内存中的地址都是以4字节或4字节整数倍对齐的。而char类型的数据,其在内存中是以1字节对齐的。变量c2就直接被分配到了c1变量的下一个存储单元,不用像int数据那样考虑4字节对齐。接下来,我们修改一下程序,指定变量c2按4字节对齐。
对于int型数据,其在内存中的地址都是以4字节或4字节整数倍对齐的。而char类型的数据,其在内存中是以1字节对齐的。变量c2就直接被分配到了c1变量的下一个存储单元,不用像int数据那样考虑4字节对齐。接下来,我们修改一下程序,指定变量c2按4字节对齐。
 程序运行结果如下。
程序运行结果如下。

运行结果可以看到,字符变量c2由于使用aligned属性声明按照4字节边界对齐,所以编译器不可能再给其分配0x00402009这个地址,因为这个地址不是按照4字节对齐的。编译器会空出3个存储单元,直接从0x0040200C这个地址上给变量c2分配存储空间。通过aligned属性声明,虽然可以显式地指定变量的地址对齐方式,但是也会因边界对齐造成一定的内存空洞,浪费内存资源。如在上面这个程序中,0x00402009~0x0040200b这三个地址上的存储单元就没有被使用。
问题:地址对齐会造成一定的内存空洞,为什么使用地址对齐?
原因:这种对齐设置可以简化CPU和内存RAM之间的接口和硬件设计。为了配合计算机的硬件设计,编译器在编译程序时,对于一些基本数据类型,如int、char、short、float等,会按照其数据类型的大小进行地址对齐,按照这种地址对齐方式分配的存储地址,CPU一次就可以读写完毕。虽然边界对齐会造成一些内存空洞,浪费一些内存单元,但是在硬件上的设计却大大简化了。
2.2 结构体对齐:aligned
结构体作为一种复合数据类型,编译器在给一个结构体变量分配存储空间时,不仅要考虑结构体内各个基本成员的地址对齐,还要考虑结构体整体的对齐。为了结构体内各个成员地址对齐,编译器可能会在结构体内填充一些空间;为了结构体整体对齐,编译器可能会在结构体的末尾填充一些空间。
举个例子定义一个结构体,结构体内定义int、char和short 3个成员,并打印结构体的大小和各个成员的地址。
 程序运行结果如下。
程序运行结果如下。

正常而言,结构体的成员b需要4字节对齐,所以编译器在给成员a分配完1字节的存储空间后,会空出3字节,在满足4字节对齐的0x0028FF34地址处才给成员b分配4字节的存储空间;接着是short类型的成员c占据2字节的存储空间;三个结构体成员一共占用1+3+4+2=10字节的存储空间。但是根据结构体的对齐规则,**结构体的整体对齐要按结构体所有成员中最大对齐字节数或其整数倍对齐,或者说结构体的整体长度要为其最大成员字节数的整数倍,如果不是整数倍则要补齐。**因为结构体最大成员int为4字节,所以结构体要按4字节对齐,或者说结构体的整体长度要是4的整数倍,要在结构体的末尾补充2字节,最后结构体的大小为12字节。
结构体成员按不同的顺序排放,可能会导致结构体的整体长度不一样。如下程序所示。
 程序运行结果如下。
程序运行结果如下。
 我们发现,char型变量a和short型变量b,被分配在了结构体前4字节的存储空间中,而且都满足各自的地址对齐方式,整个结构体大小是8字节,只造成1字节的内存空洞。我们继续修改程序,让short型的变量b按4字节对齐。
我们发现,char型变量a和short型变量b,被分配在了结构体前4字节的存储空间中,而且都满足各自的地址对齐方式,整个结构体大小是8字节,只造成1字节的内存空洞。我们继续修改程序,让short型的变量b按4字节对齐。
 程序运行结果如下。
程序运行结果如下。

结构体的大小又重新变为12字节。这是因为,我们显式指定short变量以4字节地址对齐,导致变量a的后面填充了3字节空间。int型变量c也要4字节对齐,所以变量b的后面也填充了2字节,导致整个结构体的大小为12字节。
我们不仅可以显式指定结构体内某个成员的地址对齐,也可以显式指定整个结构体的对齐方式。

 程序运行结果如下。
程序运行结果如下。
 在这个结构体中,各个成员共占8字节。通过前面的学习我们知道,整个结构体的对齐只要按最大成员的对齐字节数对齐即可。所以这个结构体整体就以4字节对齐,结构体的整体长度为8字节。但是在这里,显式指定结构体整体以16字节对齐,所以编译器就会在这个结构体的末尾填充8字节以满足16字节对齐的要求,最终导致结构体的总长度变为16字节。
在这个结构体中,各个成员共占8字节。通过前面的学习我们知道,整个结构体的对齐只要按最大成员的对齐字节数对齐即可。所以这个结构体整体就以4字节对齐,结构体的整体长度为8字节。但是在这里,显式指定结构体整体以16字节对齐,所以编译器就会在这个结构体的末尾填充8字节以满足16字节对齐的要求,最终导致结构体的总长度变为16字节。
问题:编译器一定会按照aligned指定的方式对齐吗?
回答:非也!我们通过这个属性声明,其实只是建议编译器按照这种大小地址对齐,但不能超过编译器允许的最大值。一个编译器,对每个基本数据类型都有默认的最大边界对齐字节数。如果超过了,则编译器只能按照它规定的最大对齐字节数来给变量分配地址。
 在这个程序中,我们指定char型的变量c2以16字节对齐,编译运行结果如下。
在这个程序中,我们指定char型的变量c2以16字节对齐,编译运行结果如下。
 我们可以看到,编译器给c2分配的地址是按16字节地址对齐的,如果我们继续修改c2变量按32字节对齐,你会发现程序的运行结果不再有变化,编译器仍然分配一个16字节对齐的地址,这是因为32字节的对齐方式已经超过编译器允许的最大值了。
我们可以看到,编译器给c2分配的地址是按16字节地址对齐的,如果我们继续修改c2变量按32字节对齐,你会发现程序的运行结果不再有变化,编译器仍然分配一个16字节对齐的地址,这是因为32字节的对齐方式已经超过编译器允许的最大值了。
2.3 属性声明:packed
aligned属性一般用来增大变量的地址对齐,元素之间因为地址对齐会造成一定的内存空洞。而packed属性则与之相反,一般用来减少地址对齐,指定变量或类型使用最可能小的地址对齐方式。
 在上面的程序中,我们将结构体的成员b和c使用packed属性声明,就是告诉编译器,尽量使用最可能小的地址对齐给它们分配地址,尽可能地减少内存空洞。程序的运行结果如下。
在上面的程序中,我们将结构体的成员b和c使用packed属性声明,就是告诉编译器,尽量使用最可能小的地址对齐给它们分配地址,尽可能地减少内存空洞。程序的运行结果如下。

这个特性在底层驱动开发中还是非常有用的。使用packed可以避免这个问题,结构体的每个成员都紧挨着,依次分配存储地址,这样就避免了各个成员因地址对齐而造成的内存空洞。我们也可以对整个结构体添加packed属性,这和分别对每个成员添加packed属性效果是一样的。

2.4 内核中的aligned、packed声明
在Linux内核源码中,我们经常看到aligned和packed一起使用,即对一个变量或类型同时使用aligned和packed属性声明。这样做的好处是:既避免了结构体内各成员因地址对齐产生内存空洞,又指定了整个结构体的对齐方式。
 程序运行结果如下。
程序运行结果如下。

结构体data虽然使用了packed属性声明,结构体内所有成员所占的存储空间为7字节,但是我们同时使用了aligned(8)指定结构体按8字节地址对齐,所以编译器要在结构体后面填充1字节,这样整个结构体的大小就变为8字节,按8字节地址对齐。
3、format
3.1 变参函数的格式检查
GNU通过__attribute__扩展的format属性,来指定变参函数的参数格式检查。使用方法如下。

在一些商业项目中,我们经常会实现一些自定义的打印调试函数,甚至实现一个独立的日志打印模块。这些自定义的打印函数往往是变参函数,用户在调用这些接口函数时参数往往不固定,那么编译器在编译程序时,怎么知道我们的参数格式对不对呢?
__attribute__的format属性这时候就派上用场了。上面的示例代码中,我们定义一个LOG()变参函数,用来实现日志打印功能。
编译器在编译程序时,如何检查LOG()函数的参数格式是否正确呢?通过给LOG()函数添加__attribute__((format(printf,1,2)))属性声明就可以了。这个属性声明告诉编译器:你知道printf()函数不?你怎么对printf()函数进行参数格式检查的,就按照同样的方法,对LOG()函数进行检查。
属性format(printf,1,2)有3个参数,第1个参数printf是告诉编译器,按照printf()函数的标准来检查;第2个参数表示在LOG()函数所有的参数列表中格式字符串的位置索引;第3个参数是告诉编译器要检查的参数的起始位置。

在这个LOG()函数中有2个参数,第1个参数是格式字符串,第2个参数是要打印的一个常量值0,用来匹配格式字符串中的占位符。
4、weak
在C语言标准中,当我们定义并初始化一个数组时,常用方法如下。