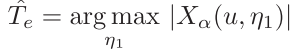本文简单介绍半监督算法中的Match系列方法:CoMatch(ICCV2021),CRMatch(GCPR2021),Dash(ICML2021),UPS(ICLR2021),SimMatch(CVPR2022),AdaMatch(ICLR2022)。
代码:GitHub - microsoft/Semi-supervised-learning: A Unified Semi-Supervised Learning Codebase (NeurIPS'22)
CoMatch: Semi-supervised Learning with Contrastive Graph Regularization, ICCV2021
解读:CoMatch 论文阅读 - 知乎 (zhihu.com)
【ICCV2021】CoMatch: Semi-supervised Learning with Contrastive Graph Regularization - 知乎 (zhihu.com)
Salesforce 研究院 | CoMatch:基于对比图正则化的半监督学习 - 智源社区 (baai.ac.cn)
论文:https://arxiv.org/abs/2011.11183
代码:GitHub - salesforce/CoMatch: Code for CoMatch: Semi-supervised Learning with Contrastive Graph Regularization
半监督学习是一种有效利用无标签数据减少对数据标注的依赖的范式。当前主要有两个主流的半监督学习研究趋势:(1)使用分类器为每个无监督样本赋予训练所需的伪标签(2)首先进行无监督、自监督预训练,然后基于得到的表征进行有监督的调优和自学习。然而,自学习方法高度依赖于分类结果的质量,会引起确认偏差,积累预测误差。另一方面,对比学习等自监督学习方法则学习到的是针对特定分类任务的次优解。
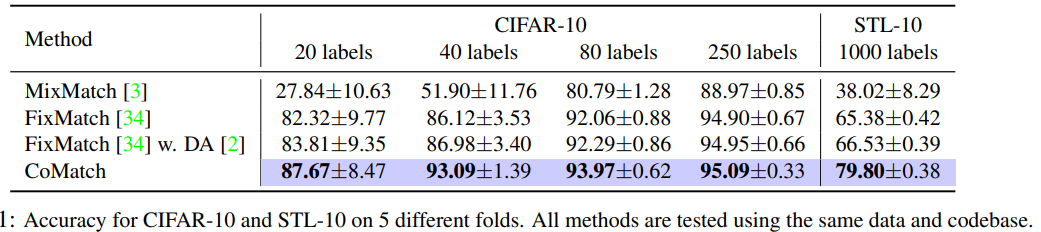
本文提出了一种新的半监督学习方法 CoMatch,它是目前主流半监督方法的集大成者,并解决了它们的局限性。CoMatch 会同时学习训练数据的两种表征(分类概率和低维嵌入)。这两种表示相互作用,共同演进。嵌入会对分类概率施加一个平滑性约束来改进伪标签,而伪标签则通过基于图的对比学习来对嵌入的结构进行正则化。


CoMatch联合学习训练数据的两种表示:类别概率和低维嵌入。这两种表征相互作用,共同演进。低维嵌入对类别概率进行平滑约束来改善伪标签,而伪标签则通过基于图的对比学习来规范嵌入的结构。
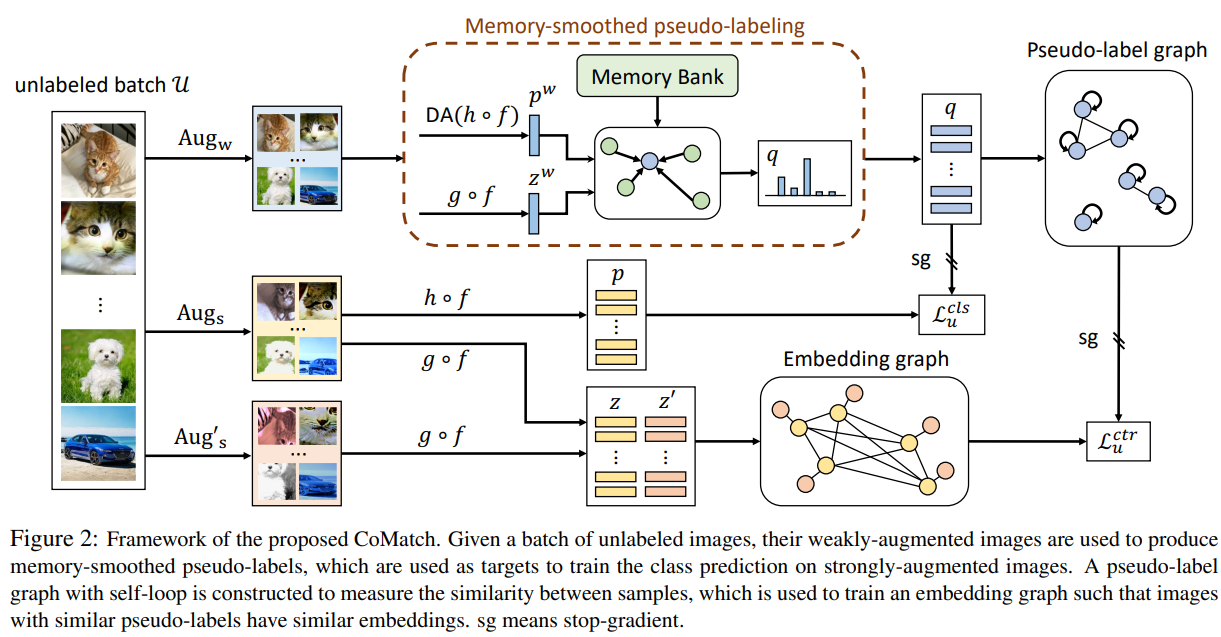
给定一批无标签图像,作者对它们进行较弱的数据增强,然后将增强后的图像用于生成记忆平滑后的伪标签。这些伪标签将被作为对应用了较强数据增强后的图像进行类别预测的目标标签。作者构建了一个带有自环的伪标签图,用来衡量样本之间的相似度,从而训练一个嵌入图,使得带有相似伪标签的图像拥有相似的嵌入。

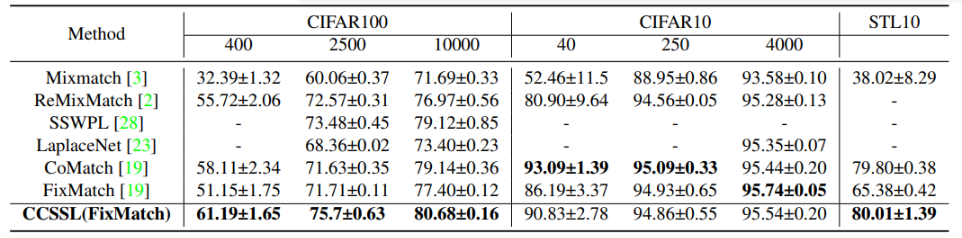
CRMatch: Revisiting Consistency Regularization for Semi-Supervised Learning, GCPR2021
论文:[2112.05825] Revisiting Consistency Regularization for Semi-Supervised Learning (arxiv.org)
代码:GitHub - subugoe/crmatch: Match unstructured references to DOIs using Crossref metadata search
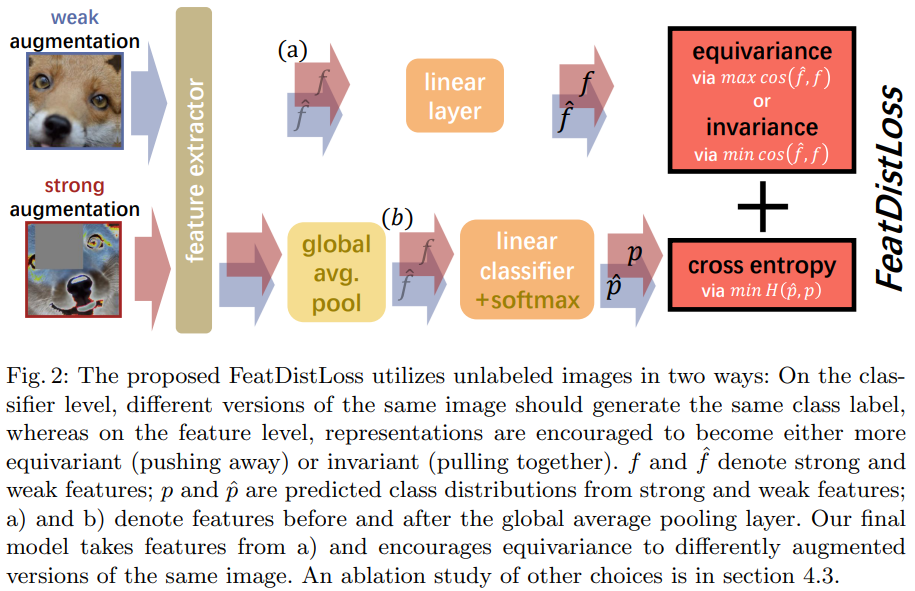
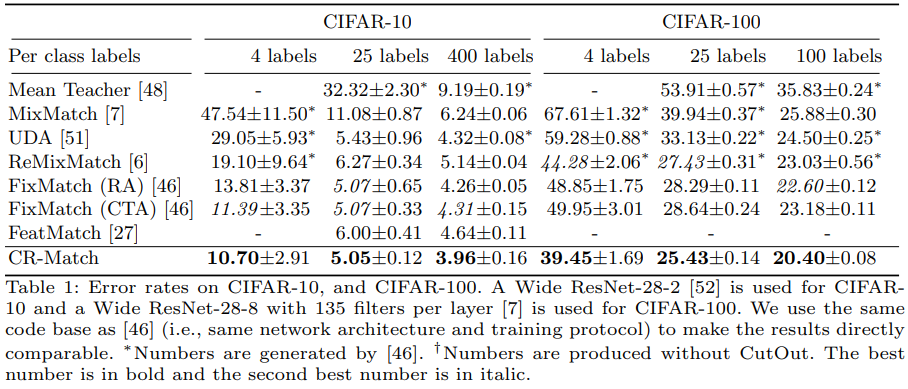
本文重新审视一致性正则化想法,通过减少不同增强图像的特征之间的距离来强制执行一致性,能提高性能。 然而,通过增加特征距离来激励一致性,能进一步提升性能。本文通过FeatDistLoss技术提出一个改进的一致性正则化框架CRMatch。该正则化框架分别在分类器和特征层面施加一致性和等值性。
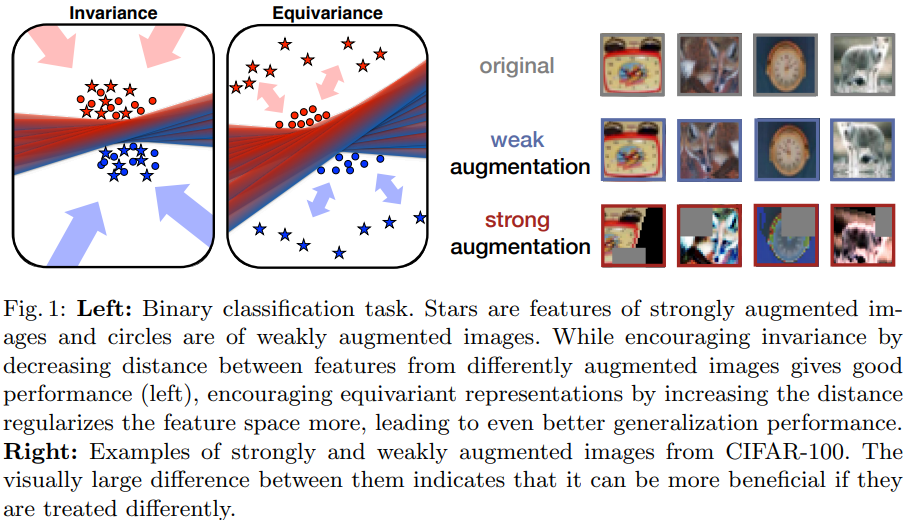
左图:二元分类任务。星星是强增强图像的特征,圆圈是弱增强图像的特征。虽然通过减少来自不同增强图像的特征之间的距离来鼓励不变性,可以提供良好的性能(左图),但通过增加距离来鼓励等值表征,使特征空间更加规范化,导致更好的泛化性能。
Dash: Semi-Supervised Learning with Dynamic Thresholding, ICML 2021
解读:论文笔记---“Dash” - 知乎 (zhihu.com)
达摩院开源半监督学习框架Dash,刷新多项SOTA - 知乎 (zhihu.com)
论文:https://arxiv.org/abs/2109.00650
代码:idstcv/Dash: Tensorflow implementation for Dash (github.com)
本文提出了一种具有动态阈值 (dynamic threshold,Dash) 的通用 SSL 算法,可以在训练过程中动态选择未标记的数据。具体来说,Dash 首先对有标签的数据进行遍历,得到一个用于无标签数据选择的阈值。然后它选择损失值小于阈值的未标记数据作为训练数据集。阈值在优化迭代过程中逐渐减小。


In Defense of Pseudo-Labeling: An Uncertainty-Aware Pseudo-label Selection Framework for Semi-Supervised Learning, ICLR 2021
解读:伪标签还能这样用?半监督力作UPS(ICLR 21)大揭秘! - 知乎 (zhihu.com)
论文解读: IN DEFENSE OF PSEUDO-LABELING - 知乎 (zhihu.com)
论文:[2101.06329] In Defense of Pseudo-Labeling: An Uncertainty-Aware Pseudo-label Selection Framework for Semi-Supervised Learning (arxiv.org)
代码:nayeemrizve/ups: "In Defense of Pseudo-Labeling: An Uncertainty-Aware Pseudo-label Selection Framework for Semi-Supervised Learning" by Mamshad Nayeem Rizve, Kevin Duarte, Yogesh S Rawat, Mubarak Shah (ICLR 2021) (github.com)
伪标签往往有着很高的置信度。如果用质量较差的伪标签作训练,将引进大量噪声样本,从而严重影响模型的性能(带噪学习(Learning with noisy labels)研究的范畴)。因此,有必要校正网络模型(calibration of Neural Networks)的输出。本文参考深度网络不确定性估计的技术(MC-dropout, ICML 2016),和softmax层输出的概率双管齐下,筛出可靠的贴伪标签的样本。Negative Learning带噪学习,虽然不知道样本属于哪类,但对它不属于哪类还是有把握的(Negative learning for noisy labels,ICCV 2019)。这样的伪标签相比传统的Positive Learning的伪标签更为准确,因而能很好地降低标签的带噪率,起到校正模型的作用。
本文提出的Uncertainty-Aware Pseudo-Label Selection Framework (UPS)策略,正是结合了不确定性估计(Uncertainty estimation)和Negative learning的技术。
- 兼顾Positive & Negative Pseudo Label的打伪标签法
- 基于不确定性的伪标签选择法

总体来说分为3步:
- 只用有标注的数据训练一个模型;
- 用训练得到的模型结合UPS方法筛选出样本打伪标签;
- 拿打上伪标签的数据和有标注数据一起训练模型(重新随机初始化),然后跳至(2)继续执行,直至循环到最大迭代次数。之所以要重新随机初始化,是为了避免打上错误伪标签的样本带来的误差在迭代训练中不断传播。
SimMatch: Semi-supervised Learning with Similarity Matching, CVPR2022
解读:SimMatch 论文分享___init__:的博客-CSDN博客
论文:https://arxiv.org/abs/2203.06915
代码:GitHub - mingkai-zheng/simmatch
半监督学习,
- 先在大规模数据集预训练,并用少量标签数据微调。缺点在于,难未利用到标签信息。
- 伪标签通常由弱视图或多个增强视图的平均预测产生。缺点在于,当标签数据十分有限时,所训练的语义分类器并不可靠,由此生成的伪标签将会出现“over confidence”问题,即模型会去拟合那些置信度很好但是错误的伪标签,由此导致性能下降。
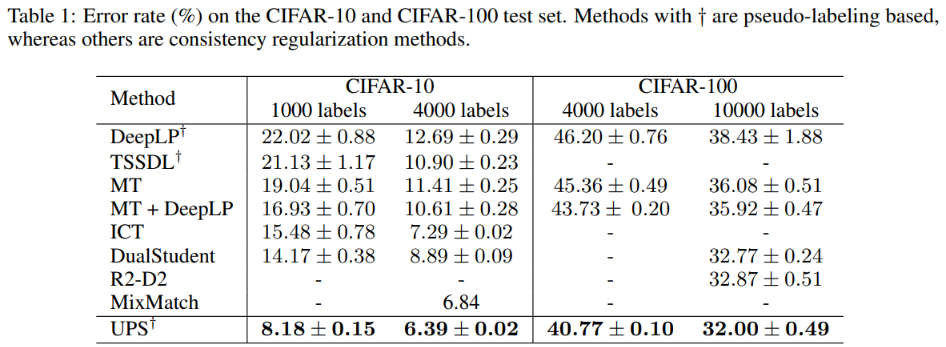
本文提出SimMatch框架,
- 首先,希望强增强视图和弱增强视图具有相同的语义相似性(预测的标签)。
- 强增强视图与弱增强视图具有相同的实例特征(即实例之间的相似性),以便于进行更多的内在特征匹配。希望强增强视图与弱增强视图具有类似的相似性分布。
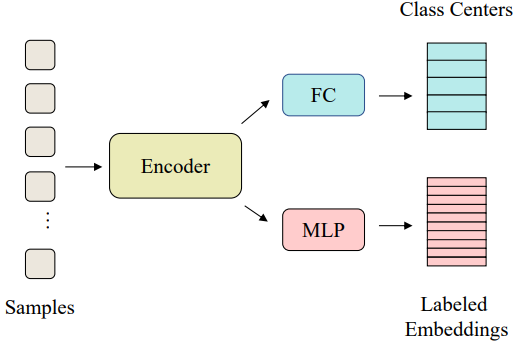

SimMatch 进行标签传播,并允许语义相似性和实例相似性相互交互。
- 使用语义相似度来校准实例相似度;
- 使用实例相似度调整语义相似度。
当语义相似度和实力相似度接近时,意味着两个分布与彼此的预测一致,由此生成的伪标签将具有更高的置信度,从而更加可靠。


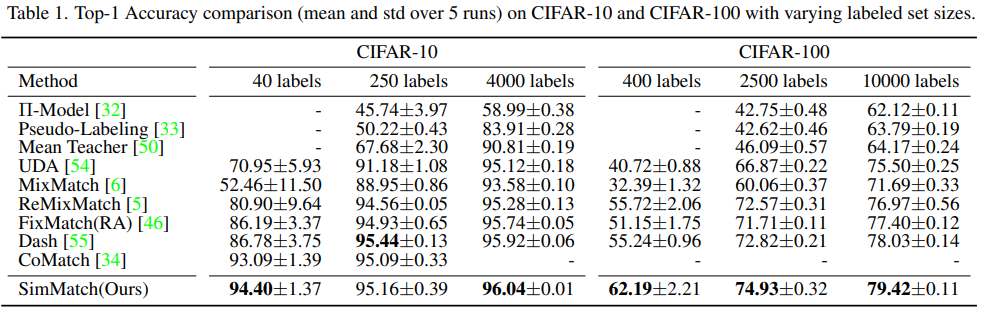
Class-Aware Contrastive Semi-Supervised Learning, CVPR2022
解读:类感知对比半监督学习(Class-Aware Contrastive Semi-Supervised Learning)论文阅读笔记_类感知是什么_Remoa的博客-CSDN博客
论文:[2203.02261] Class-Aware Contrastive Semi-Supervised Learning (arxiv.org)
代码:https://github.com/TencentYoutuResearch/Classification-SemiCLS
现有基于伪标签的半监督学习方法存在的问题:
- 伪标签 → 存在确认偏差(Confirmation Bias)
- 分布外噪声数据 → 影响模型的判别能力
是否存在一种通用增益方法,可适用于各基于伪标签的半监督方法?
- MixMatch[1](NIPS, 2019):数据Mixup → 预测锐化(Sharpen)
- FixMatch[2](NIPS, 2020):置信度阈值,弱增强 → 生成伪标签 → 监督强增强
本文提出一套缓解确认偏差(Confirmation Bias)的通用架构:
- 对于可靠的分布内数据(In-distribution Data):使用有监督对比学习。分布内数据:指无标记数据集不包含新类别,或具有平衡的数据分布的数据。
- 对于存在噪声的分布外数据(Out-of-distribution Data):对特征进行无监督对比学习。分布外数据:指无标记数据集包含未知类别,或具有不平衡的数据分布的数据。
针对伪标签存在的噪声问题:进行权重分配。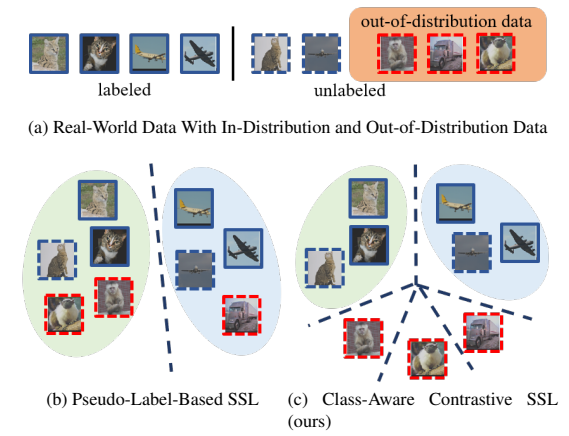




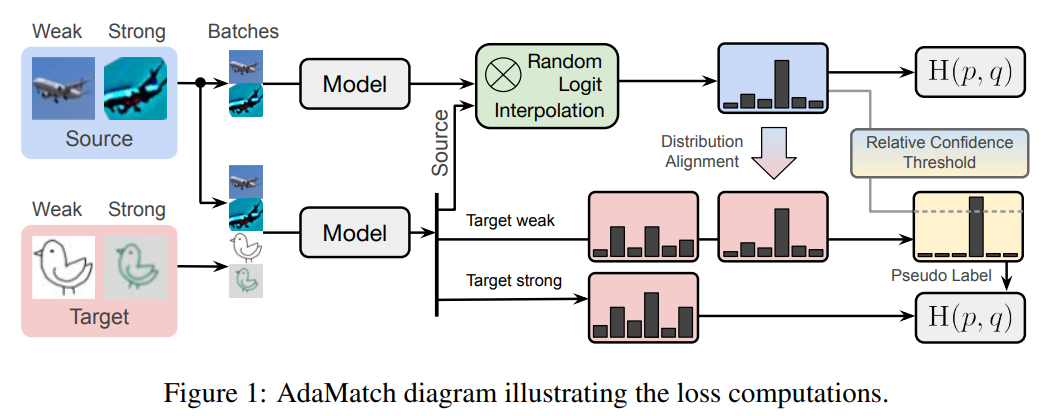
AdaMatch: A Unified Approach to Semi-Supervised Learning and Domain Adaptation, ICLR2022
解读:AdaMatch: A Unified Approach to Semi-Supervised Learning and Domain Adaptation - 知乎 (zhihu.com)
论文:https://arxiv.org/abs/2106.04732
代码:GitHub - google-research/adamatch
GitHub - yizhe-ang/AdaMatch-PyTorch: Unofficial PyTorch Implementation of AdaMatch: A Unified Approach to Semi-Supervised Learning and Domain Adaptation
https://github.com/zysymu/AdaMatch-pytorch
本文将半监督学习扩展到域适应问题,能够使得模型在一种数据分布上训练,并在另一种数据分布上测试。AdaMatch统一了无监督领域适应(UDA)、半监督学习(SSL)和半监督领域适应(SSDA)的任务。
 三种手段: 随机的输出插值(random logit interpolation),相对变化的置信度阈值调整(relative confidence threshold)和改进的分布对齐(源于ReMixMatch,但是算法backbone来自FixMatch)
三种手段: 随机的输出插值(random logit interpolation),相对变化的置信度阈值调整(relative confidence threshold)和改进的分布对齐(源于ReMixMatch,但是算法backbone来自FixMatch)