- 👏作者简介:大家好,我是爱敲代码的小黄,独角兽企业的Java开发工程师,CSDN博客专家,阿里云专家博主
- 📕系列专栏:Java设计模式、Spring源码系列、Netty源码系列、Kafka源码系列、JUC源码系列
- 🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦
- 🍂博主正在努力完成2023计划中:以梦为马,扬帆起航,2023追梦人
- 📝联系方式:hls1793929520,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬👀

文章目录
- 线程池源码剖析
- 一、引言
- 二、使用
- 三、源码
- 1、初始化
- 1.1 拒绝策略
- 1.1.1 AbortPolicy
- 1.1.2 CallerRunsPolicy
- 1.1.3 DiscardOldestPolicy
- 1.1.4 DiscardPolicy
- 1.1.5 自定义拒绝策略
- 1.2 其余变量
- 2、线程池的execute方法
- 3、线程池的addWorker方法
- 3.1 校验
- 3.2 添加线程
- 4、线程池的 worker 源码
- 5、线程池的 runWorker 方法
- 6、线程池的 getTask 方法
- 7、线程池的 processWorkerExit 方法
- 8、线程池的关闭方法
- 8.1 shutdownNow 方法
- 8.2 shutdown 方法
- 四、流程图
- 五、总结
线程池源码剖析
一、引言
线程池技术在互联网技术使用如此广泛,几乎所有的后端技术面试官都要在线程池技术的使用和原理方面对小伙伴们进行 360° 的刁难。
作为一个在互联网公司面一次拿一次 Offer 的面霸,打败了无数竞争对手,每次都只能看到无数落寞的身影失望的离开,略感愧疚(请允许我使用一下夸张的修辞手法)。
于是在一个寂寞难耐的夜晚,暖男我痛定思痛,决定开始写 《吊打面试官》 系列,希望能帮助各位读者以后面试势如破竹,对面试官进行 360° 的反击,吊打问你的面试官,让一同面试的同僚瞠目结舌,疯狂收割大厂 Offer!
虽然现在是互联网寒冬,但乾坤未定,你我皆是黑马
二、使用
我想大部分人应该都使用过线程池,我们的 JDK 中也提供了一些包装好的线程池使用,比如:
-
newFixedThreadPool:返回一个核心线程数为
nThreads的线程池public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); } -
newSingleThreadExecutor:返回一个核心线程数为
1的线程池public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>())); } -
newCachedThreadPool:大同小异
public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); }
通过上面 JDK 提供的我们可以发现一个共识,他们其实都是调用了 ThreadPoolExecutor 的构造方法来进行线程池的创建
这时候,我们不免有疑问,我们难道不可以直接使用 ThreadPoolExecutor 的构造方法去进行创建嘛
是的,阿里巴巴Java开发手册中明确指出,『不允许』使用Executors创建线程池
所以,我们在生产中,一般使用 ThreadPoolExecutor 的构造方法自定义去创建线程池,比如:
public class ThreadPoolTest {
public static void main(String[] args) {
ThreadPoolExecutor executor = new ThreadPoolExecutor(
2, // 核心线程数
5, // 最大线程数
200, // 非核心工作线程在阻塞队列位置等待的时间
TimeUnit.SECONDS, // 非核心工作线程在阻塞队列位置等待的单位
new LinkedBlockingQueue<>(), // 阻塞队列,存放任务的地方
new ThreadPoolExecutor.AbortPolicy() // 拒绝策略:这里有四种
);
for (int i = 0; i < 10; i++) {
MyTask task = new MyTask();
executor.execute(task);
}
// 关闭线程
executor.shutdown();
}
}
class MyTask implements Runnable {
@Override
public void run() {
System.out.println("我被执行了....");
}
}
三、源码
整体的流程如下:
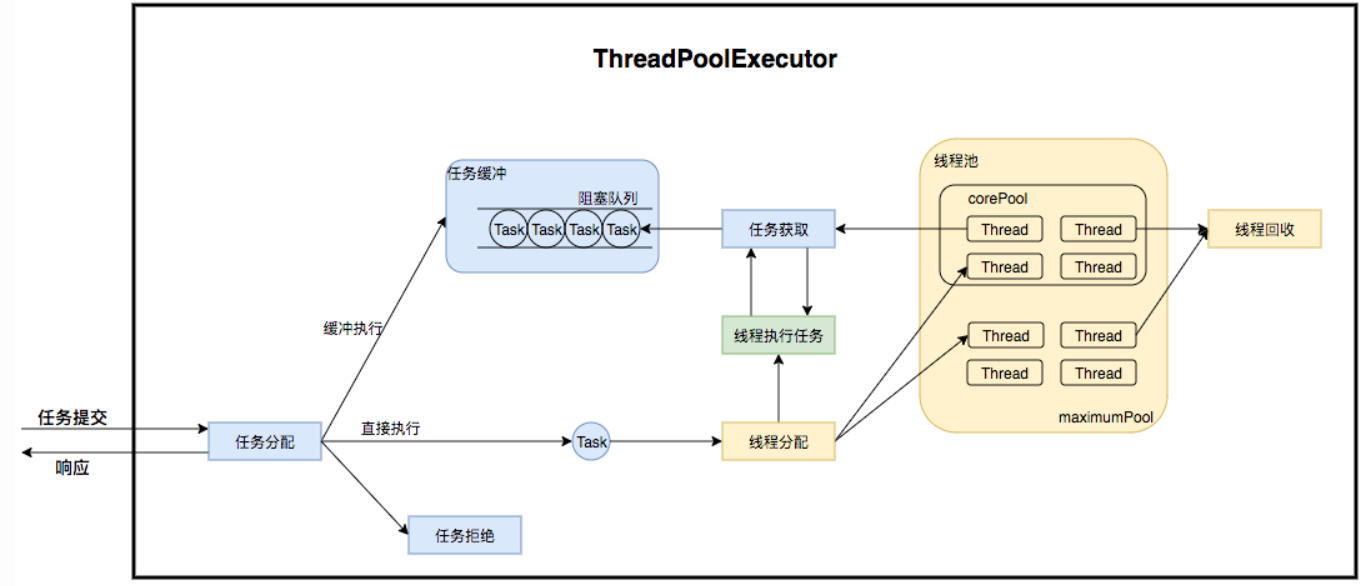
1、初始化
聊源码不从初始化聊的,都是不讲道理的
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, RejectedExecutionHandler handler) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), handler);
}
// 执行ThreadPoolExecutor的构造方法进行初始化
// corePoolSize: 核心线程数
// maximumPoolSize: 最大线程数
// keepAliveTime: 非核心工作线程在阻塞队列位置等待的时间
// unit: 非核心工作线程在阻塞队列位置等待的时间单位
// workQueue: 存放任务的阻塞队列
// threadFactory: 线程工厂(生产线程的地方)
// RejectedExecutionHandler: 拒绝策略
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
// 核心线程数可以为0
// 最大线程数不为0
// 最大线程数 大于 核心线程数
// 等待时间大于等于0
if (corePoolSize < 0 || maximumPoolSize <= 0 || maximumPoolSize < corePoolSize || keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
// 将当前的入参赋值给成员变量
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
我们上面初始化的过程主要对入参做了一些校验,然后将方法的入参赋予给成员变量
1.1 拒绝策略
1.1.1 AbortPolicy
简单粗暴,直接抛出异常
public static class AbortPolicy implements RejectedExecutionHandler {
public AbortPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() + " rejected from " + e.toString());
}
}
1.1.2 CallerRunsPolicy
当前拒绝策略会在线程池无法处理任务时,将任务交给调用者处理
public static class CallerRunsPolicy implements RejectedExecutionHandler {
public CallerRunsPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
// 如果当前的
if (!e.isShutdown()) {
r.run();
}
}
}
1.1.3 DiscardOldestPolicy
如果当前的阻塞队列满了,弹出时间最久的
public static class DiscardOldestPolicy implements RejectedExecutionHandler {
public DiscardOldestPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
// 获取阻塞队列,弹出一个时间最久的
e.getQueue().poll();
// 执行当前的
e.execute(r);
}
}
}
1.1.4 DiscardPolicy
简单粗暴,不做任何操作
public static class DiscardPolicy implements RejectedExecutionHandler {
public DiscardPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
}
1.1.5 自定义拒绝策略
自己写的业务逻辑,可以将拒绝的任务放至数据库等存储,等后续在执行
public static class MyRejectedExecution implements RejectedExecutionHandler{
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
System.out.println("这是我自己的拒绝策略");
}
}
1.2 其余变量
// 该数值代表两个意思:
// 高3位表示当前线程池的状态
// 低29位表示当前线程池工作线程的个数
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
// COUNT_BITS = 29
private static final int COUNT_BITS = Integer.SIZE - 3;
// CAPACITY就是当前工作线程能记录的工作线程的最大个数
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// 111:代表RUNNING状态,RUNNING可以处理任务,并且处理阻塞队列中的任务。
private static final int RUNNING = -1 << COUNT_BITS;
// 000:代表SHUTDOWN状态,不会接收新任务,正在处理的任务正常进行,阻塞队列的任务也会做完。
private static final int SHUTDOWN = 0 << COUNT_BITS;
// 001:代表STOP状态,不会接收新任务,正在处理任务的线程会被中断,阻塞队列的任务一个不管。
private static final int STOP = 1 << COUNT_BITS;
// 010:代表TIDYING状态,这个状态是否SHUTDOWN或者STOP转换过来的,代表当前线程池马上关闭,就是过渡状态。
private static final int TIDYING = 2 << COUNT_BITS;
// 011:代表TERMINATED状态,这个状态是TIDYING状态转换过来的,转换过来只需要执行一个terminated方法。
private static final int TERMINATED = 3 << COUNT_BITS;
// 基于&运算的特点,保证只会拿到ctl高三位的值
private static int runStateOf(int c) { return c & ~CAPACITY; }
// 基于&运算的特点,保证只会拿到ctl低29位的值
private static int workerCountOf(int c) { return c & CAPACITY; }
线程池的状态变化流程图:

2、线程池的execute方法
- Step1:当前的线程池个数低于核心线程数,直接添加核心线程即可
- Step2:当前的线程池个数大于核心线程数,将任务添加至阻塞队列中
- Step3:如果添加阻塞队列失败,则需要添加非核心线程数处理任务
- Step4:如果添加非核心线程数失败(满了),执行拒绝策略
public void execute(Runnable command) {
// 如果当前传过来的任务是null,直接抛出异常即可
if (command == null)
throw new NullPointerException();
// 获取当前的数据值
int c = ctl.get();
//==========================线程池第一阶段:启动核心线程数开始==================================================
// Step1:获取ctl低29位的数值,与我们的核心线程数相比
if (workerCountOf(c) < corePoolSize) {
// Step2:添加一个核心线程
if (addWorker(command, true)){
return;
}
// 更新一下当前值
c = ctl.get();
}
//==========================线程池第一阶段:启动核心线程数结束==================================================
// 如果走到下面会有两种情况:
// 1、核心线程数满了,需要往阻塞队列里面扔任务
// 2、核心线程数满了,阻塞队列也满了,执行拒绝策略
//==========================线程池第二阶段:任务放至阻塞队列开始==================================================
// 判断当前的状态是不是Running的状态(RUNNING可以处理任务,并且处理阻塞队列中的任务)
// 如果是Running的状态,则可以将任务放至阻塞队列中
// 这里如果放阻塞队列失败了,证明阻塞队列满了
if (isRunning(c) && workQueue.offer(command)) {
// 再次更新数值
int recheck = ctl.get();
// 再次校验当前的线程池状态是不是Running
// 如果线程池状态不是Running的话,需要删除掉刚刚放的任务
if (!isRunning(recheck) && remove(command)){
// 执行拒绝策略
reject(command);
}
// 如果到这里,说明上面阻塞队列中已经有数据了
// 如果线程池的个数为0的话,需要创建一个非核心工作线程去执行该任务
// 不能让人家堵塞着
else if (workerCountOf(recheck) == 0){
addWorker(null, false);
}
}
//==========================线程池第二阶段:任务放至阻塞队列结束==================================================
// 如果走到这里的逻辑,证明上面的逻辑没走通,有以下两种情况:
// 1、线程池的状态不是Running
// 1.1 如果是这种情况,下面的添加非核心工作线程失败执行拒绝策略,但这个并不是这个逻辑的重点
// 2、阻塞队列添加任务失败(阻塞队列满了)
// 2.1 这种情况才是我们需要关心的
// 2.2 阻塞队列满了,添加非核心工作线程
// 2.3 若添加非核心工作线程失败,证明已经到达maximumPoolSize的限制,执行拒绝策略
//==========================线程池第三阶段:启动非核心线程数开始==================================================
// 添加一个非核心工作线程
else if (!addWorker(command, false))
// 工作队列中添加任务失败,执行拒绝策略
reject(command);
//==========================线程池第三阶段:启动非核心线程数结束==================================================
}
流程图如下:

3、线程池的addWorker方法
3.1 校验
- 校验当前线程池的状态
- 校验当前线程池工作线程的个数(核心线程数、最大工作线程数)
private boolean addWorker(Runnable firstTask, boolean core) {
// 这里主要是为了结束整个循环
retry:
for (;;) {
// 获取当前线程池的数值(ctl)
int c = ctl.get();
// runStateOf:基于&运算的特点,保证只会拿到ctl高三位的值
int rs = runStateOf(c);
//==========================线程池状态判断=============================================================
// rs >= SHUTDOWN:代表当前线程池状态为:SHUTDOWN、STOP、TIDYING、TERMINATED,线程池状态异常
// 但这里SHUTDOWN状态稍许不同(不会接收新任务,正在处理的任务正常进行,阻塞队列的任务也会做完)
// 如果当前的状态是SHUTDOWN状态并且阻塞队列任务不为空且新任务为空
// 需要新起一个非核心工作线程去执行任务
// 如果不是前面的,直接返回false即可
if (rs >= SHUTDOWN && ! (rs == SHUTDOWN && firstTask == null && !workQueue.isEmpty())){
return false;
}
//==========================工作线程个数判断==========================================================
for (;;) {
// 获取当前线程池中线程的个数
int wc = workerCountOf(c);
// 1、如果线程池线程的个数是否超过了工作线程的最大个数
// 2、core=true(核心线程)=false(工作线程)
// 2.1 根据当前core判断创建的是核心线程数(corePoolSize)还是非核心线程数(maximumPoolSize)
if (wc >= CAPACITY || wc >= (core ? corePoolSize : maximumPoolSize)){
return false;
}
// 尝试将线程池线程加一
if (compareAndIncrementWorkerCount(c)){
// CAS成功后,直接退出外层循环,代表可以执行添加工作线程操作了。
break retry;
}
// 获取当前线程池的数值(ctl)
c = ctl.get();
// 获取当前线程池的状态
// 判断当前线程池的状态等不等于我们上面的rs
// 我们线程池的状态被人更改了,需要重新跑整个for循环判断逻辑
if (runStateOf(c) != rs){
continue retry;
}
}
}
// 省略下面的代码
}
3.2 添加线程
{
// 省略校验的步骤
// 两个标记
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
// 将当前的任务封装成Worker
w = new Worker(firstTask);
// 拿到当前Worker的线程
final Thread t = w.thread;
// 线程不为空
if (t != null) {
// 上锁,保证线程安全(workers、largestPoolSize)
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 获取线程池的状态
int rs = runStateOf(ctl.get());
// 1、rs < SHUTDOWN:保证当前线程池的状态一定是RUNNING状态
// 2、rs == SHUTDOWN && firstTask == null:如果当前线程池是SHUTDOWN状态且新任务为空
if (rs < SHUTDOWN || (rs == SHUTDOWN && firstTask == null)) {
// 判断线程是否还活着
if (t.isAlive())
throw new IllegalThreadStateException();
// private final HashSet<Worker> workers = new HashSet<Worker>();
// 添加到我们的work队列中
workers.add(w);
// 获取works的大小
int s = workers.size();
// largestPoolSize在记录最大线程个数的记录
// 如果当前的大小比最大的还要打,替换即可
if (s > largestPoolSize)
largestPoolSize = s;
// worker添加成功
workerAdded = true;
}
} finally {
// 解锁
mainLock.unlock();
}
// 如果添加成功
if (workerAdded) {
// 启动线程
t.start();
// 线程启动标志位
workerStarted = true;
}
}
} finally {
// 如果线程没有启动成功,从workers集合中删除掉该worker
if (!workerStarted)
addWorkerFailed(w);
}
// 返回线程是否启动成功
return workerStarted;
}
// Worker的初始化
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
// 从线程工厂里面拿一个线程出来
this.thread = getThreadFactory().newThread(this);
}
// 从workers集合中删除掉该worker
private void addWorkerFailed(Worker w) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
if (w != null)
workers.remove(w);
decrementWorkerCount();
tryTerminate();
} finally {
mainLock.unlock();
}
}
4、线程池的 worker 源码
// Worker继承了AQS,目的就是为了控制工作线程的中断。
// Worker实现了Runnable,内部的Thread对象,在执行start时,必然要执行Worker中断额一些操作
private final class Worker extends AbstractQueuedSynchronizer implements Runnable{
private static final long serialVersionUID = 6138294804551838833L;
// 当前线程工厂创建的线程(也是执行任务使用的线程)
final Thread thread;
// 当前的第一个任务
Runnable firstTask;
// 记录执行了多少个任务
volatile long completedTasks;
// 构造方法
Worker(Runnable firstTask) {
// 将State设置为-1,代表当前不允许中断线程
setState(-1);
// 设置任务
this.firstTask = firstTask;
// 设置线程
this.thread = getThreadFactory().newThread(this);
}
// 线程启动执行的方法
public void run() {
runWorker(this);
}
// =======================Worker管理中断================================
// 当前方法是中断工作线程时,执行的方法
void interruptIfStarted() {
Thread t;
// 只有Worker中的state >= 0的时候,可以中断工作线程
if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) {
try {
// 如果状态正常,并且线程未中断,这边就中断线程
t.interrupt();
} catch (SecurityException ignore) {
}
}
}
}
5、线程池的 runWorker 方法
public void run() {
runWorker(this);
}
final void runWorker(Worker w) {
// 拿到当前的线程
Thread wt = Thread.currentThread();
// 拿到当前Worker的第一个任务(如果携带的话)
Runnable task = w.firstTask;
// 置空
w.firstTask = null;
// 解锁
w.unlock();
boolean completedAbruptly = true;
try {
// 如果任务不等于空 或者 从阻塞队列中拿到的任务不等于空
while (task != null || (task = getTask()) != null) {
// 加锁
w.lock();
// 如果线程池状态 >= STOP,确保线程中断了
if ((runStateAtLeast(ctl.get(), STOP) || (Thread.interrupted() && runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
// 在任务执行前做一些操作,自己实现的钩子
beforeExecute(wt, task);
Throwable thrown = null;
try {
// 任务执行
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
// 任务执行后一些操作:自己实现的钩子
afterExecute(task, thrown);
}
} finally {
// 任务置空
task = null;
// 执行任务+1
w.completedTasks++;
// 解锁
w.unlock();
}
}
completedAbruptly = false;
} finally {
// 删除线程的方法
processWorkerExit(w, completedAbruptly);
}
}
6、线程池的 getTask 方法
private Runnable getTask() {
// 超时的标记
boolean timedOut = false;
// 死循环拿数据
for (;;) {
// 拿到当前的ctl
int c = ctl.get();
// 获取其线程池状态
int rs = runStateOf(c);
// 如果线程池状态是STOP,没有必要处理阻塞队列任务,直接返回null
// 如果线程池状态是SHUTDOWN,并且阻塞队列是空的,直接返回null
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
// 线程池中的线程个数减一
decrementWorkerCount();
return null;
}
// 当前线程池中线程个数
int wc = workerCountOf(c);
// 这里是个重点
// allowCoreThreadTimeOut:是否允许核心线程数超时(开启这个之后),核心线程数也会执行下面超时的逻辑
// wc > corePoolSize:当前线程池中的线程个数大于核心线程数
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
// wc > maximumPoolSize:基本不存在
// timed && timedOut:第一次肯定是失败的(超时标记为false)
if ((wc > maximumPoolSize || (timed && timedOut))
// 1、线程个数为1
// 2、阻塞队列是空的
&& (wc > 1 || workQueue.isEmpty())) {
// 线程池的线程个数减一
if (compareAndDecrementWorkerCount(c)){
return null;
}
continue;
}
try {
// 根据我们前面的timed的值(当前线程池中的线程个数是否大于核心线程数)
// 如果大于,执行workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS)带有时间的等待,超过时间无任务,会返回null
// 如果小于,执行workQueue.take(),死等任务,不会返回null
Runnable r = timed ? workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) : workQueue.take();
if (r != null){
return r;
}
// 到这里,说明上面的等待超时了
// 这里要注意一下,如果这里超时后,我们上面 if ((wc > maximumPoolSize || (timed && timedOut)) 这个判断要起作用了
// (timed && timedOut) true
// wc > 1 || workQueue.isEmpty():当线程大于1或者阻塞队列无数据,直接返回null,让外部循环删除
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
7、线程池的 processWorkerExit 方法
private void processWorkerExit(Worker w, boolean completedAbruptly) {
// 正常退出的:completedAbruptly=false
// 不是正常退出的:completedAbruptly=true
if (completedAbruptly)
decrementWorkerCount();
// 加锁——上锁
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 将当前worker的执行任务数累加到线程池中
completedTaskCount += w.completedTasks;
// 线程池删除该工作线程
workers.remove(w);
} finally {
// 解锁
mainLock.unlock();
}
tryTerminate();
// 获取ctl的数据
int c = ctl.get();
// 这里只有SHUTDOWN、RUNNING会进入判断
if (runStateLessThan(c, STOP)) {
// 正常退出的
if (!completedAbruptly) {
// 是否允许超时
// 允许:0
// 不允许:核心线程数
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
// 如果min=0并且阻塞队列不为空
// 将min设置成1
if (min == 0 && ! workQueue.isEmpty())
min = 1;
// 当前线程池的大小大于最小值,直接返回即可
if (workerCountOf(c) >= min){
return;
}
}
// 如果没有的话,说明线程池中没有线程了,并且还有阻塞任务
// 只能添加一个非核心线程去处理这些任务
addWorker(null, false);
}
}
8、线程池的关闭方法
8.1 shutdownNow 方法
- 将线程池状态修改为Stop(不会接收新任务,正在处理任务的线程会被中断,阻塞队列的任务一个不管)
- 将线程池中的线程全部中断
- 删除当前线程池所有的工作线程
- 将线程池的状态从:Stop --> TIDYING --> TERMINATED,正式标记线程池的结束(唤醒一下等待的主线程)
public List<Runnable> shutdownNow() {
// 声明返回结果
List<Runnable> tasks;
// 加锁
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
// 将线程池状态修改为STOP
advanceRunState(STOP);
// 将线程池中的线程全部中断
interruptWorkers();
// 删除当前所有的工作线程
tasks = drainQueue();
} finally {
// 解锁
mainLock.unlock();
}
// 查看当前线程池是否可以变为TERMINATED状态
// 从 Stop 状态修改为 TIDYING,在修改为 TERMINATED
tryTerminate();
return tasks;
}
// targetState = STOP
// 作用:将当前线程池的状态修改为Stop
private void advanceRunState(int targetState) {
// 进来直接死循环
for (;;) {
// 拿到当前的ctl
int c = ctl.get();
// runStateAtLeast(c, targetState):当前的c是不是大于STOP(如果大于Stop的话,说明线程池状态已经G了
// 基于CAS,将ctl从c修改为Stop状态,不修改工作线程个数,仅仅将状态修改为Stop
// 如果可以修改成功,直接退出即可
if (runStateAtLeast(c, targetState) || ctl.compareAndSet(c, ctlOf(targetState, workerCountOf(c))))
break;
}
}
// 将线程池中的线程全部中断
private void interruptWorkers() {
// 加锁
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 循环遍历线程组
for (Worker w : workers)
// 中断线程
// 这里会给线程打一个中断的标记,具体什么时候中断线程,需要我们自己去控制
w.interruptIfStarted();
} finally {
// 解锁
mainLock.unlock();
}
}
// 删除当前所有的工作线程
private List<Runnable> drainQueue() {
// 存放工作线程的队列
BlockingQueue<Runnable> q = workQueue;
// 返回的结果
ArrayList<Runnable> taskList = new ArrayList<Runnable>();
// 清空阻塞队列并将数据放入taskList中
q.drainTo(taskList);
// 校验当前的数据是够真的清空
if (!q.isEmpty()) {
// 如果确实有遗漏的,毕竟这哥们也没上锁
// 手动的将线程从workQueue删除掉并且放到taskList中
for (Runnable r : q.toArray(new Runnable[0])) {
if (q.remove(r))
taskList.add(r);
}
}
// 最终返回即可
return taskList;
}
final void tryTerminate() {
for (;;) {
// 拿到ctl
int c = ctl.get();
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// CAS将当前的ctl设置成TIDYING
if (ctl.compareAndSet(c, ctlOf(TIDYING, 0))) {
try {
// 该方法是一个钩子函数,我们自己定义,在线程池销毁之前做最后的处理
terminated();
} finally {
// 将ctl设置成TERMINATED标志着线程池的正式结束
ctl.set(ctlOf(TERMINATED, 0));
// 线程池提供了一个方法,主线程在提交任务到线程池后,是可以继续做其他操作的。
// 咱们也可以让主线程提交任务后,等待线程池处理完毕,再做后续操作
// 这里线程池凉凉后,要唤醒哪些调用了awaitTermination方法的线程
// 简单来说,当时等待线程池返回的主线程,由于线程池已经销毁了,他们也必须要唤醒
termination.signalAll();
}
return;
}
} finally {
// 解锁
mainLock.unlock();
}
}
}
8.2 shutdown 方法
public void shutdown() {
// 加锁
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
// 将线程池状态修改为SHUTDOWN
advanceRunState(SHUTDOWN);
// 将线程池中的线程全部中断
interruptIdleWorkers();
onShutdown(); // hook for ScheduledThreadPoolExecutor
} finally {
mainLock.unlock();
}
// 查看当前线程池是否可以变为TERMINATED状态
// 从 SHUTDOWN 状态修改为 TIDYING,在修改为 TERMINATED
tryTerminate();
}
四、流程图

五、总结
鲁迅先生曾说:独行难,众行易,和志同道合的人一起进步。彼此毫无保留的分享经验,才是对抗互联网寒冬的最佳选择。
其实很多时候,并不是我们不够努力,很可能就是自己努力的方向不对,如果有一个人能稍微指点你一下,你真的可能会少走几年弯路。
如果你也对 后端架构和中间件源码 有兴趣,欢迎添加博主微信:hls1793929520,一起学习,一起成长
我是爱敲代码的小黄,独角兽企业的Java开发工程师,CSDN博客专家,喜欢后端架构和中间件源码。
我们下期再见。
我从清晨走过,也拥抱夜晚的星辰,人生没有捷径,你我皆平凡,你好,陌生人,一起共勉。
往期文章推荐:
- 从源码全面解析LinkedBlockingQueue的来龙去脉
- 从源码全面解析 ArrayBlockingQueue 的来龙去脉
- 从源码全面解析ReentrantLock的来龙去脉
- 阅读完synchronized和ReentrantLock的源码后,我竟发现其完全相似
- 从源码全面解析 ThreadLocal 关键字的来龙去脉
- 从源码全面解析 synchronized 关键字的来龙去脉
- 阿里面试官让我讲讲volatile,我直接从HotSpot开始讲起,一套组合拳拿下面试







![[Golang] 爬虫实战-获取动态页面数据-获取校招信息](https://img-blog.csdnimg.cn/ed1783558dfa434ab6e44ae52069de24.png)