😚一个不甘平凡的普通人,致力于为Golang社区和算法学习做出贡献,期待您的关注和认可,陪您一起学习打卡!!!😘😘😘
🤗专栏:算法学习
🤗专栏:Go实战
💬个人主页:个人主页

跟着我一起来学习go爬虫吧!!!
文章介绍:爬取网站的招聘信息
方法:使用go自带的http包中的方法去爬取相应的数据
希望对您有所帮助,您的一键三连是我更新的动力!!!十分感谢
文章目录
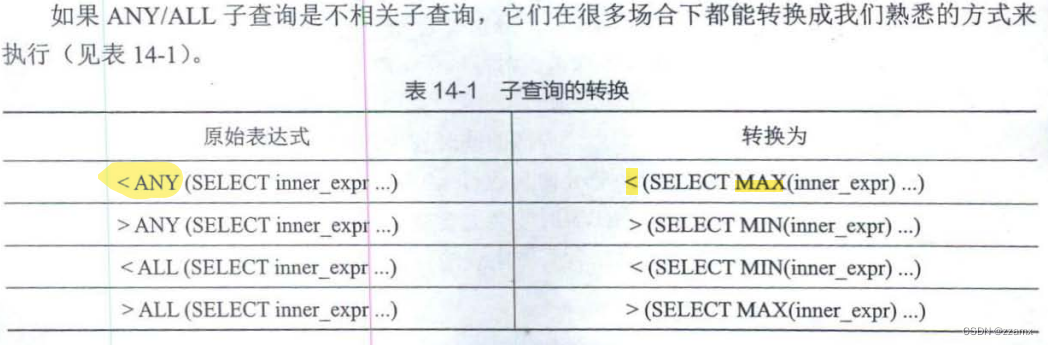
- 页面数据分析
- 爬取动态页面
- 判断类型
- 抓包模拟请求头
页面数据分析
常见的页面分为:静态页面和动态页面
如何判断是什么类型的页面呢? 通过查看页面的源代码,如果和你通过f12查看的页面元素一致,那么就说明是静态页面。
如果是静态页面的话, 可以通过直接获取网页链接,然后根据自己想要的标签然后获取对应的数据,这一类比较简单一点。
什么情况下是动态抓取? 如果查看源代码之后,发现元素的组成和通过f12不一致,并且由很多ajax或者js或者css构成,那么就不能直接通过拿链接去获取对应的数据,因为这样我们无法获得所有想要的数据,只会获得一部分。
那我们应该怎样去做呢??
爬取动态页面
爬取动态页面的最常见的方法就是:通过抓包,获取对应的ajax文件,通过查看自己想要的json数据位置,锁定对应的文件,然后模拟请求头抓取,下面以抓取某站的校招信息为例子:
判断类型
查看源代码: 判断出如果直接抓取不会拿到数据

所以需要动态抓取
抓包模拟请求头
步骤一:
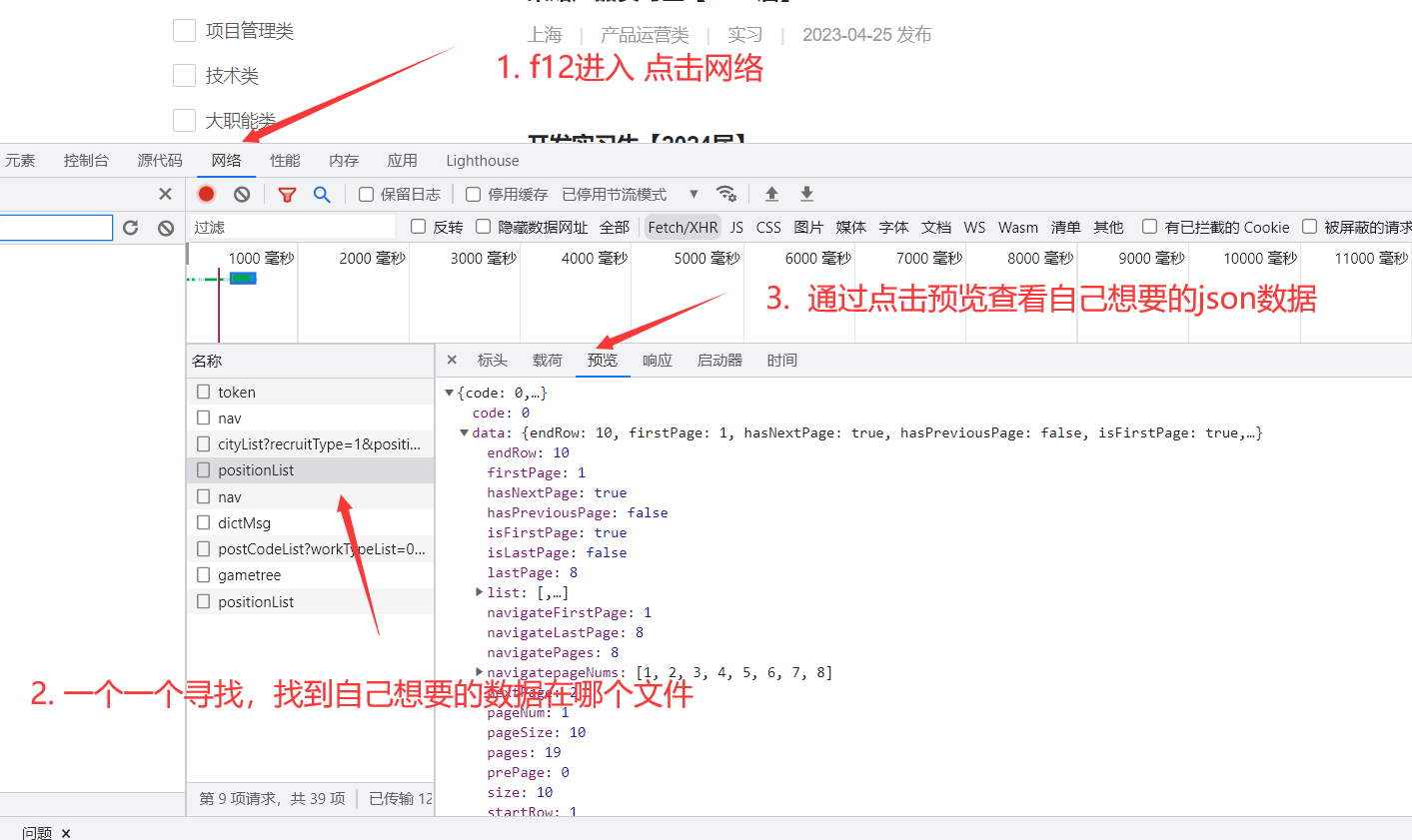
步骤二:
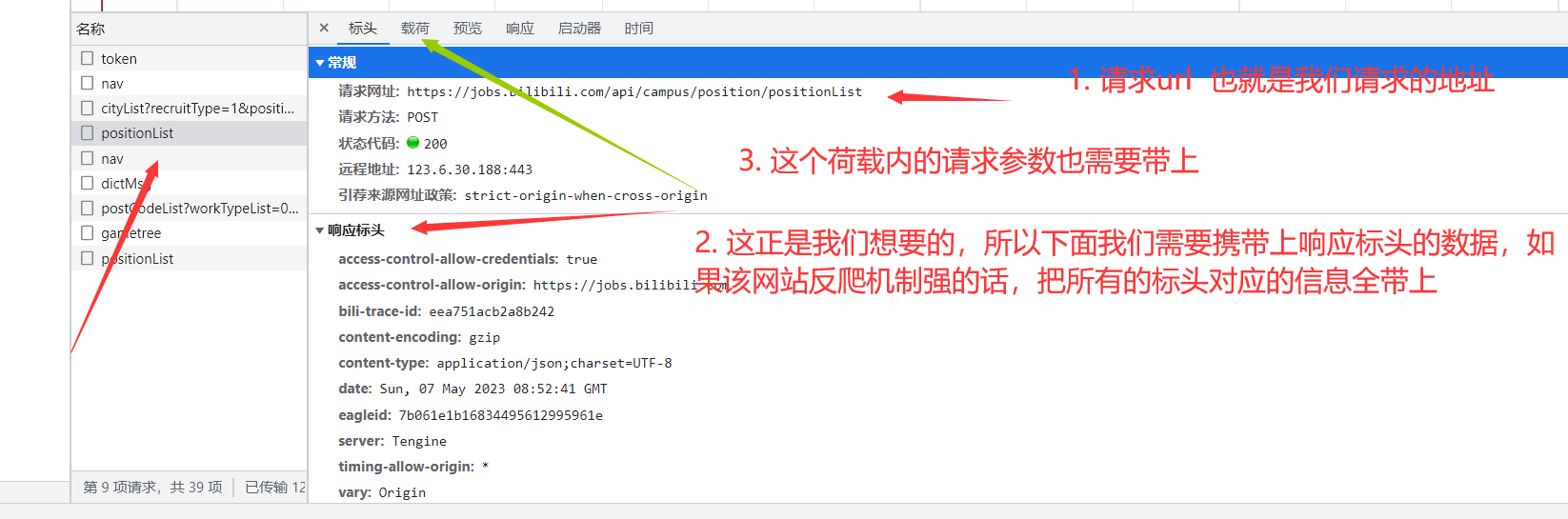
步骤三:
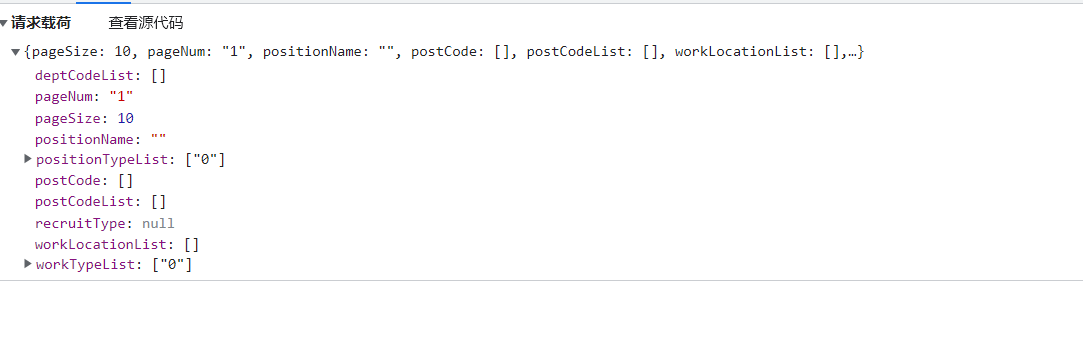
具体代码实现:
这一块几乎涵盖了http包中爬虫所有用法 哥们自己看吧,写的很清楚了
// 抓取职位信息,主要作用:抓取到页面的id,为之后的每一页信息爬取做铺垫
func Fetch(url string, Method string, requestBody []byte) {
//url := "https://jobs.bilibili.com/api/campus/position/positionList"
// 构造请求体
//requestBody := []byte(`{"pageSize":10,"pageNum":"2","positionName":"","postCode":[],"postCodeList":[],"workLocationList":[],"workTypeList":["0"],"positionTypeList":["0"],"deptCodeList":[],"recruitType":null}`)
req, err := http.NewRequest(Method, url, bytes.NewBuffer(requestBody))
if err != nil {
fmt.Println(err)
return
}
// 添加请求头部信息
req.Header.Add("authority", "jobs.bilibili.com")
req.Header.Add("accept", "application/json, text/plain, */*")
req.Header.Add("accept-language", "zh-CN,zh;q=0.9")
req.Header.Add("content-type", "application/json;charset=UTF-8")
req.Header.Add("origin", "https://jobs.bilibili.com")
req.Header.Add("referer", "https://jobs.bilibili.com/campus/positions?type=0&page=2")
req.Header.Add("sec-ch-ua", `"Chromium";v="112", "Google Chrome";v="112", "Not:A-Brand";v="99"`)
req.Header.Add("sec-ch-ua-mobile", "?0")
req.Header.Add("sec-ch-ua-platform", `"Windows"`)
req.Header.Add("sec-fetch-dest", "empty")
req.Header.Add("sec-fetch-mode", "cors")
req.Header.Add("sec-fetch-site", "same-origin")
req.Header.Add("user-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36")
req.Header.Add("x-appkey", "ops.ehr-api.auth")
req.Header.Add("x-channel", "campus")
req.Header.Add("x-csrf", "728e3c6c-e981-412e-be94-ab1f76557972")
req.Header.Add("x-usertype", "2")
// 发送请求并获取响应
client := &http.Client{}
resp, err := client.Do(req)
if err != nil {
fmt.Println(err)
return
}
defer resp.Body.Close()
// 处理响应数据
err = json.NewDecoder(resp.Body).Decode(&receive)
if err != nil {
fmt.Println("Error decoding JSON:", err)
return
}
//将所有的id信息添加到Allid数据中
for i := 0; i < 10; i++ {
//AllId = append(AllId, receive.Data.List[i].Id)
if len(receive.Data.List) == i {
return
}
AllId = append(AllId, receive.Data.List[i].Id)
}
}