文章目录
- 前言
- 文献阅读
- 摘要
- 简介
- 数据
- 方法论
- 预测结果
- 结论
- 时间序列预测
- 总结
前言
本周阅读文献《Water quality forecasting based on data decomposition, fuzzy clustering and deep learning neural network》,文献主要结合数据分解、模糊C均值聚类和双向门控循环单元,提出了一种新的混合模型。应用EWT将原始水质时间序列分解为若干分量,然后利用FCM将分解的子序列重新组合为3个分量(低、中、高频分量),之后,对于每个聚类组件,使用BiGRU来构建预测模型。总体实验结果表明,所提模型在水质预报方面效果好。另外,主要阅读了应用深度学习方法对水质进行预测的文献,最后总结水质预测的过程以及阅读的文献提高水质预测的主要思路。
This week,I read an article which proposes a novel hybrid model by combining data decomposition, fuzzy C-means clustering and bidirectional gated recurrent unit. In the proposed forecast model, EWT was applied to decompose the original water quality time series into several components and then, FCM was used to recombine the decomposed subseries into three components (low, middle and high frequency component). Subsequently, for each clustered component, BiGRU was employed to build prediction model. The overall experiment results demonstrated that the proposed model was very successful for water quality forecasting.In addition, I mainly read the literature that applied deep learning methods to predict water quality.Finally, I summarize the process of water quality prediction and the main idea of literature to improve water quality prediction.
文献阅读
题目:Water quality forecasting based on data decomposition, fuzzy clustering and deep learning neural network
作者:Jin-Won Yu a b, Ju-Song Kim a b, Xia Li a, Yun-Chol Jong b, Kwang-Hun Kim b, Gwang-Il Ryang b
摘要
水质预报可以为公众健康保护提供有用的信息,支持水资源管理。为了更准确地预测水质,该文结合数据分解、模糊C均值聚类和双向门控循环单元,提出了一种新的混合模型。首先,通过经验小波变换将原始水质数据分解为若干个子序列,然后通过模糊C均值聚类对分解后的子系列进行重新组合;接下来,针对每个聚类序列,应用双向门控循环单元来开发预测模型。最后,通过对子序列的预测求和获得预测结果。利用中国鄱阳湖水质数据对所提出的预测模型进行了评价。结果表明,所提出的预报模型对4个水质数据均有较准确的预报结果:提前59天预报7个水质数据集的MAPE平均值为4.59%。此外,我们的模型显示出比其他模型更好的预测性能。特别是,与单一BiGRU模型相比,MAPE平均下降了 32.86%。结果表明,所提预报模型能够有效地用于水质预报。
简介
随着人工智能的发展,机器学习模型正在成为数据驱动建模的重点。Jimeno-Saez等人(2020)使用支持向量回归(SVR)来预测Mar Menor(欧洲最大的高盐水肋泻湖)的叶绿素a浓度。Li等人(2021a)提出了一种混合模型,该模型将长短期记忆(LSTM)和卷积神经网络(CNN)应用于废水处理系统。 Zhi等人(2021)应用LSTM开发溶解氧预测模型。Miao 等人 (2021) 比较了 SVR、LSTM 和门控循环单元 (GRU) 用于化学需氧量 (COD) 预测的预测性能。在上述研究中,机器学习模型,特别是LSTM和GRU等深度学习模型,显示出强大的水质预测能力。然而,在某些情况下,单个机器学习模型无法提供令人满意的预测结果,因为水质通常以非常复杂的方式变化,因此,一些研究提出了几种类型的混合模型,例如数据同化模型(Wang等人,2016)和理论指导模型(Karpatne等人,2017)。但是,这些模型直接使用单比例数据,因此只能使用数据的表面特征。研究表明,基于多尺度数据的模型,即基于数据分解的模型可以从原始时间序列中提取更详细的信息,以便通过这种模型获得更准确的预测。利用数据分解开发预测模型,许多研究人员开发了结合数据分解和机器学习算法的新型混合模型:基于小波分解的预测模型,基于经验模式分解的预测模型,基于经验模式分解的预测模型,基于经验小波变换的预测模型,从以往的研究结果可以看出,数据分解技能是增强回归模型模拟能力的有效方法。然而,基于数据分解的预测模型研究大多采用一次性数据分解法,将整个数据的分解结果用于模型训练或测试。由于在分解过程中使用了应该已知的未来值,因此这种方法没有实际用途。为了解决这个问题,最近的几项研究提出了基于实时数据分解的模型。然而,一些研究表明,基于实时数据分解的预测模型比不结合数据分解的单一模型提供的结果更差。这是因为在实时分解中,通过逐步分解获得的分解结果彼此具有不同的趋势,因此它在每个步骤中提取不同的关系,导致回归建模失败,换句话说,为了成功应用数据分解来开发预测模型,必须设计适当的数据分解策略和建模方法。水质时间序列数据与其他时间序列数据(如空气质量或风速)具有不同的特征。它在许多方面都与其他人不同,例如监测周期和时间相关性等(Rashed and Younis,2012;Snortheim等人,2017)。因此,开发基于实时数据分解的水质预报模型具有实际意义。
文献的贡献:
本文利用经验小波变换(EWT)、模糊C均值聚类(FCM)和双向门控循环单元(BiGRU)提出了一种新的基于数据分解的预测模型。
这项研究的主要新颖之处如下。
1)采用FCM来减少实时数据分解造成的不必要错误。在基于数据分解的预测模型中,大量模式通常会对预测准确性产生负面影响(Sun and Li,2020;吴和林,2019)。
2)BiGRU首次应用于水质预测。GRU 仅考虑单向关系,因此它无法完全表示具有双向相关性的数据的关系(Ahmed 和 Ghabayen,2020 年;孟等人,2021 年)。由于BiGRU由两个GRU(前向传播和向后传播)组成,以考虑双向关系,因此BiGRU可以预期是比GRU更好的水质预测选择。
3)提出了一种新的基于数据分解的建模方法。与现有的基于数据分解的建模方法不同(Ahani 等人,2020 年;Wang和Wu,2016),该方法收集每个时间点的分解结果,考虑整体动态趋势并构建输入输出关系。
数据
使用了3个监测站,每个站点的水质数据包括2个水质参数(溶解氧(DO),氨氮(NH3–H)) 从 1 年 2017 月 30 日至 2020 年 15 月 2 日。前 2 个月的数据集用于模型训练,未来 2 个月的数据集用于模型验证,剩余 1 个月的数据集用于模型测试。
方法论
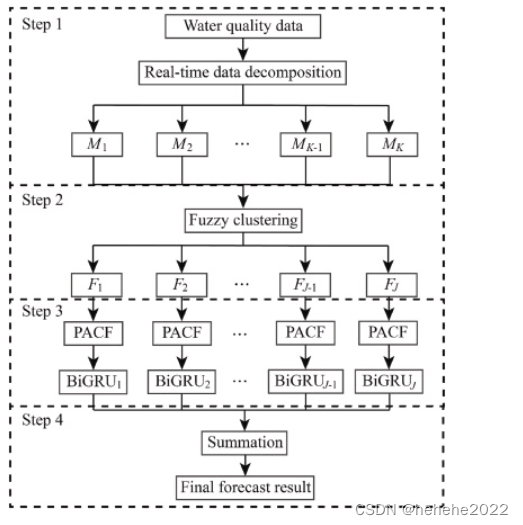
预测过程概述
1.水质时间序列分解为几个组成部分
2.分解的组件由FCM重新组合
3.对于步骤2得到的每个子序列,进行偏自相关函数(PACF)分析,从其时滞子序列中获取适当的输入数据,然后采用BiGRU得到预测结果
4.最终预测结果是通过对步骤3中获得的预测结果求和获得的
预测方法流程图:
数据分解
为了分解数据,首先,我们需要选择合适的分解算法。在这项研究中,我们选择了经验小波变换(EWT)作为我们的分解算法,因为它是一种有效的算法,既具有小波变换(WT)的数学基础,又具有经验模态分解(EMD)的适应性。
提出的数据分解策略:
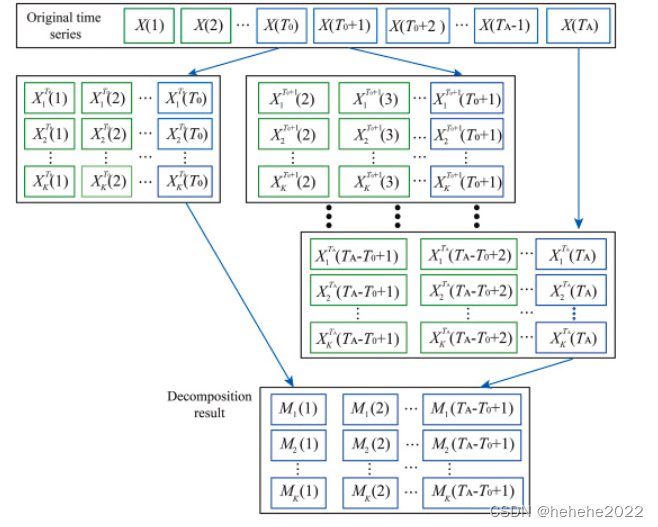
通过模糊 C 均值聚类进行重组
对于模糊 C 均值聚类 (FCM) 的应用,需要确定要聚类的组件之间的距离。在这项研究中,动态时间扭曲(DTW)用于此目的,因为该距离不仅可以考虑序列之间的尺度差异,还可以考虑时间延迟。
通过 BiGRU 获取预测
在以前的研究中,许多类型的机器学习方法被应用于水质预测。其中,LSTM和GRU因其长期记忆能力而引起研究人员的注意。特别是GRU由于其结构简单、仿真能力高等特点,在许多研究中得到了广泛的应用。然而,由于GRU只在一个方向上提取信息,因此它不能充分表示双向时间相关性。BiGRU结合了两个GRU,可以成功地克服GRU的缺点,因为它通过使用向后GRU和前向GRU在两个方向上提取信息。BiGRU已经应用于风速和空气质量预报的多项研究中,并被证明比GRU更有效。
评估指标
平均绝对误差(MAE)、均方根误差(RMSE)、平均绝对百分比误差(MAPE)、方向变化统计
,纳什-萨特克利夫效率(NSE)用于评估预测性能。
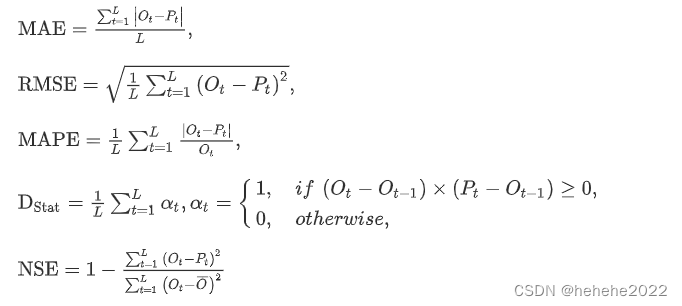
预测结果
预测所提议模型的性能:
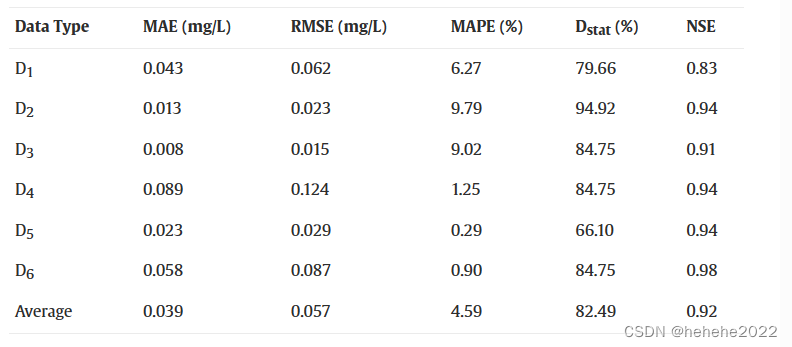
我们可以看到,对DO(D4-D6) 预测非常准确(MAPE <1.3%),对于 NH3–N,所提出的模型也显示出良好的预测性能(MAPE<10%)。
与其他模型的比较:
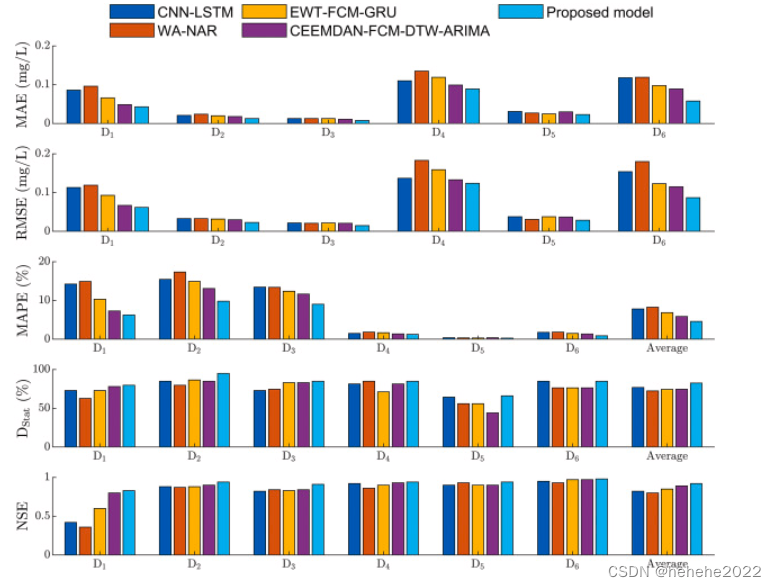
在未应用数据分解的模型(LSTM、GRU、BIGRU)中,BiGRU提供了最高的精度,这表明BiGRU具有很高的仿真能力。与单一模型相比,基于数据分解的模型提供了更好的预测结果。结果表明,数据分解是增强预测能力的有效方法。我们的模型EWT-FCM-BiGRU的预测结果优于VMD-FCM-BiGRU,CEEMDAN-FCM-BiGRU并且证明了EWT比其他分解算法更适合开发预测模型。
结论
本研究结合EWT、FCM和BiGRU提出了一种新的水质预测模型。在所提出的预测模型中,应用EWT将原始水质时间序列分解为若干分量,然后利用FCM将分解的子序列重新组合为3个分量(低、中、高频分量)。随后,对于每个聚类组件,使用BiGRU来构建预测模型。
时间序列预测
题目:A novel hybrid water quality forecast model based on real-time data decomposition and error correction
关键词:Water quality;Hybrid model;Machine learning;Improved complete ensemble empirical mode decomposition with adaptive noise (ICEEMDAN);Bidirectional long short-term memory (BLSTM);Variational mode decomposition (VMD)
摘要:准确的水质预报非常重要,因为它可以通过未来信息支持水资源管理。在这项研究中,我们提出了一种通过使用数据分解、纠错和机器学习的新型混合模型。在我们的方法中,首先,初始预测是通过预测模型获得的,该模型使用改进的完整集成经验模式分解以及自适应噪声和双向长短期记忆(BLSTM)神经网络。其次,利用变分模态分解和BLSTM神经网络构建的新型纠错框架,通过修正初始预测误差来提高预测精度。使用中国鄱阳湖水质数据对模型进行评价。结果表明,我们的模型对所有9个水质数据集的预报性能均有很高的准确率(提前7天预报的平均绝对百分比误差(MAPE)为2.12%;提前30天预报的平均绝对百分比误差为4.06%)。此外,我们的模型优于竞争对手模型,特别是与没有纠错框架的预测模型相比,提前33天预测的MAPE平均值降低了33.7%;30.48%提前30天的预测。本研究表明,所提出的纠错框架是提高水质预测精度的有效工具。
总结:研究提出了一种基于实时数据分解和纠错方法的新型水质预测模型。采用ICEEMDAN和VMD对原始水质时间序列和误差序列进行分解,降低机器学习模型输入和输出的复杂性。这篇文献与上面文献阅读的那篇文献有些相似。
研究的主要发现总结如下。
1)实时数据分解是一种新颖而出色的数据预处理技术,用于增强预测能力。
2)基于数据分解的误差校正可以通过有效纠正误差来提高预测精度。
3)基于误差校正的预测模型可以提供高度准确的结果。
题目:An interpretable hierarchical neural network insight for long-term water quality forecast: A study in marine ranches of Eastern China
关键词:Deep learning;Self-attention mechanism;Temporal convolutional network;Dissolved oxygen;Forecast
摘要:准确预测水质参数对于水质监测和水质调控具有重要意义。然而,日益复杂的海水环境使得提高水质参数预测的准确性具有挑战性。本研究提出了一种新的用于预测水质参数的可解释深度学习方法。该方法将分解后的特征数据输入到不同的堆栈中进行数据处理。设计了几个平行结构堆栈来捕获分解序列的特征。提出了一种基于近期和长期历史数据相结合的新型注意力机制,以及一种增强的双残差时间卷积网络块模块。本研究使用了从山东半岛沿海八个海洋牧场获得的溶解氧数据。结果表明,模型预测结果的MAE、RMSE和MAPE均比其他算法低33.48%、33.33%和29.26%,平均高6%。我们的模型在预测值和观测值之间表现出最高的拟合程度,线性拟合最好,误差最小。我们的工作为调查海洋牧场水质预测的原因和影响提供了一个有价值的框架。
题目:Water quality assessment of a river using deep learning Bi-LSTM methodology: forecasting and validation
摘要:本文引入基于深度学习的Bi-LSTM模型(DLBL-WQA)预测印度亚穆纳河水质因子。现有方案不执行缺失值插补,只关注学习过程,而不包含与训练误差相关的损失函数。该模型展示了一种新的方案,该方案在第一阶段包括缺失值插补,第二阶段从给定的输入数据生成特征图,第三阶段包括Bi-LSTM架构以改进学习过程,最后,应用优化的损失函数来减少训练误差。因此,所提出的模型提高了预测的准确性。在德里地区的几个地点收集了6年(2013-2019年)不同水质因子的月度样本数据。实验结果表明,模型的预测值与实际值吻合较近,可以揭示未来的趋势。将我们的模型的性能与SVR,随机森林,人工神经网络,LSTM和CNN-LSTM等各种最先进的技术进行了比较。为了检查精度,使用了均方根误差 (RMSE)、平均绝对误差 (MAE)、均方误差 (MSE) 和平均绝对百分比误差 (MAPE) 等指标。通过测量COD和BOD水平进行实验分析。COD 分析显示,帕拉地区的 MSE、RMSE、MAE 和 MAPE 值分别为 0.015、0.117、0.115 和 20.32。同样,BOD 分析指示 MSE、RMSE、MAE 和 MAPE 值分别为 0.107、0.108、0.124 和 18.22。对比分析表明,所提模型在最佳预测精度和最低错误率方面优于所有其他模型。
题目:A Multi-Step Approach for Optically Active and Inactive Water Quality Parameter Estimation Using Deep Learning and Remote Sensing
关键字:deep learning;multi-step forecasting;physico-chemical parameters;time series forecasting;water quality monitoring
摘要:水是人类生存的基本资源,但饮用不适合饮用的水会导致严重的疾病。高分辨率卫星图像的获取为水质监测技术的创新提供了机会。通过遥感,可以根据卫星图像的波段组合估计水质参数浓度。本研究研究了一种用于预测多步参数浓度的混合遥感和深度学习方法,以推进传统采用的水质评估技术。对深度学习模型,包括卷积神经网络(CNN)、全连接网络(FCN)、递归神经网络(RNN)、多层感知器(MLP)和长短期记忆(LSTM),用于光学活性参数(即电导率(EC))和非活动参数(即溶解氧(DO))的多步估计。EC和DO浓度的估计有助于分析水中杂质和氧气的水平。拟议的解决办法将提供关于改善社会所需的水管理技术必要变革的信息。EC和DO参数作为具有相关参数的独立变量,即pH值,浊度,总溶解固体,叶绿素a、Secchi 圆盘深度和地表温度,这些数据是从2014 年拉瓦尔河网的 Landsat-2021 数据中提取的。双向LSTM获得了更好的结果,DO的均方根误差(RMSE)为0.2(mg/L),RMSE为281.741(uS/cm)分别代表 EC。结果表明,混合方法在光学活性和非活性水质参数的多步预测特征提取和评估中提供了高效准确的结果。
总结:传统上,水质估计研究侧重于预测水质指数(WQI)值,在遥感中,通过测量水体与光相互作用时改变其光谱特性的参数来监测水质。这些被称为水的光学活性成分。然而,仅靠遥感无法评估水质并得到精确和准确的结果。因此,将遥感和人工智能相结合进行准确水质预测。本研究研究了一种利用遥感和深度学习技术应用于光学活性和非活性水质参数估计的方法。
题目:Algal bloom forecasting with time-frequency analysis: A hybrid deep learning approach
关键字:Algal bloom forecasting;Deep learning;Long-short-term-memory (LSTM);Wavelet analysis
摘要:深度学习长期短期记忆(LSTM)技术的迅速出现为藻华预测提供了有希望的解决方案。然而,藻类动力学中的不连续和非平稳过程仍然在很大程度上限制了LSTM的功能。为了克服这一挑战,引入了一种先进的时频小波分析(WA)技术来提高LSTM的预测精度。 本文中,新型混合方法(WLSTM)成功地将门多塔湖(美国威斯康星州)经典LSTM的藻类预测不准确性降低了41%±8%,在每小时、每天和每月的时间分辨率下具有强大的提前一步预测(R2= 分别为 0.976、0.878 和 0.814)。此外,WLSTM优于其他两种广泛使用的藻类预测方法 - 深度神经网络(DNN)和自回归积分移动平均(ARIMA)模型,其表现为均方根误差平均降低72%和85%。此外,WLSTM在实验施肥的湖泊(密歇根州星期二湖)中实施,以进行多步骤预测检查。它令人满意地预测了藻类波动,涉及大量的峰值和极值,并以平均95%的高精度>准确率呈现了准确的判断结果。
题目:A systematic literature review of deep learning neural network for time series air quality forecasting
摘要:工业发展、城市化和交通的迅速发展导致空气质量下降,对人类健康和环境可持续性产生负面影响,特别是在发达国家。已经进行了大量关于使用机器学习开发空气质量预测模型以控制空气污染的研究。因此,有大量关于机器学习在空气质量预测中的应用的评论。与深度学习架构相比,机器学习的浅层架构存在一些局限性,并且预测准确性较低。深度学习是计算智能领域的一项新技术;因此,它在空气质量预测中的应用仍然有限。本研究旨在研究深度学习在时间序列空气质量预报中的应用。因此,从所有科学数据库中彻底进行文献检索,以避免不必要的混乱。本研究总结并讨论了应用于空气质量预报的不同类型的深度学习算法,包括理论背景、超参数、应用和局限性。还介绍了具有数据分解、优化算法和时空模型的混合深度学习,以突出这些技术在解决单个深度学习模型的缺点方面的有效性。明确指出,混合深度学习能够以比单个模型更高的精度预测未来的空气质量。在研究的最后,为未来的模型开发提出了一些可能的研究方向。本综述研究的主要目的是提供深度学习在时间序列空气质量预测中的应用的综合文献摘要,这可能有益于感兴趣的研究人员进行后续研究。
总结:这篇文献是总结了深度学习在时间序列空气质量预测中应用的一篇综述,总结了深度学习预测模型的主要组成部分,如特征提取、数据分解和时空依赖性。
总结
水质预测的过程:
1.水质监测站点获取水文数据和水质数据,根据水质现状评价结果研究主要污染物指标。
2.在进行水质时序预测之前,监测数据污染物浓度值存在缺失或数据突变,会对水质数据进行数据预处理。
3.特征提取,通过相关性分析(计算水质指标之间的相关系数判断相关程度)等对预处理后的水质数据进行特征提取。
4.根据研究区域的特征和各模型的特点选取合适的水质预测模型。

目前所阅读的文献提高水质预测的主要思路:
1.进行数据分解,分解算法被证明是从时间序列数据中提取动态特征的有用策略,分解的本质是将时间序列数据从非静态转移到静态,因此分解算法可以合理地被认为是机器学习建模过程中预处理步骤的新颖方法。
2.预处理技术:模糊聚类(FC)方法,小波变换(WT);后处理技术:多元线性回归(MLR),多元线性回归(MLR),广义似然不确定性估计 (GLUE),贝叶斯模型平均 (BMA),贝叶斯不确定性处理器 (BUP)
3.混合模型:CNN-LSTM,CNN-GRU,与统计模型的杂交,比如SARIMA-LSTM混合模型;与其他 ML 算法的混合,比如梯度提升决策树 (GBDT)与LSTM结合。
4.遥感结合深度学习,遥感图像可用于通过研究图像颜色和纹理进行涉及光学活性参数(如叶绿素α、浊度、有色溶解有机物等)的广域WQ预测。
5.元启发式优化算法计算模型的最优参数值。