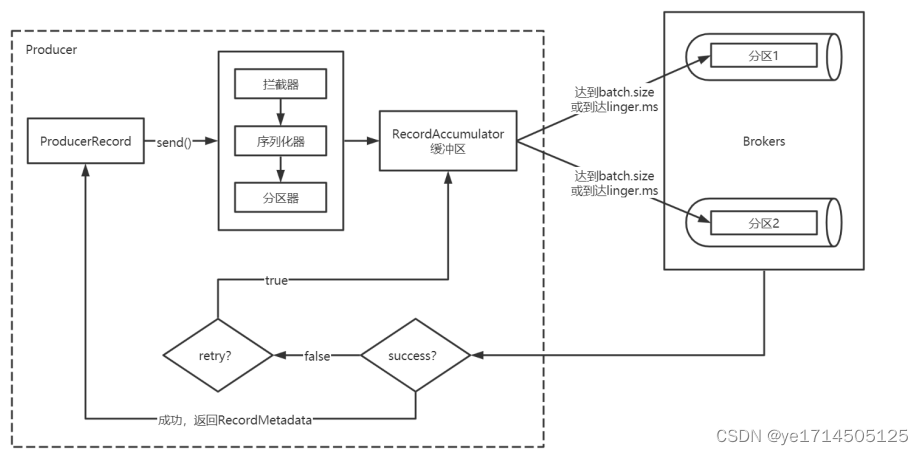
消息发送流程介绍
- Producer创建时,会创建⼀个sender线程并设置为守护线程。
- ⽣产消息时,内部其实是异步的;⽣产的消息先经过拦截器->序列化器->分区器,然后将消息缓存在缓冲区(该缓冲区也是在Producer创建时创建)。
- 批次发送的条件为:缓冲区数据⼤⼩达到batch.size或者linger.ms达到上限,哪个先达到就算哪个。
- 批次发送后,发往指定分区,然后落盘到broker;如果⽣产者配置了retrires参数⼤于0并且失败原因允许重试,那么客户端内部会对该消息进⾏重试。
- 落盘到broker成功,返回⽣产元数据给⽣产者。
- 元数据返回有两种⽅式:⼀种是通过阻塞直接返回,另⼀种是通过回调返回。
生产流程代码
kafka生产消息Demo
private KafkaProducer<String, String> producer;
private static final String GENERAL_TOPIC = "test";
@PostConstruct
public void init() {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaUrl);
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
// 失败尝试次数
properties.put(ProducerConfig.RETRIES_CONFIG, 3);
// 是否压缩发送,压缩发送的好处是 节省了网络传输事件,但增加了CPU利用率
properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "gzip");
// 0:只管发送,不管kafka节点是否成功接收。 1:kafka的leader节点收到 2:主节点和从节点都有收到
properties.put(ProducerConfig.ACKS_CONFIG, "all");
producer = new KafkaProducer<>(properties);
}
@PreDestroy
public void destroy() {
producer.close();
}
public void send(String msg) {
send(GENERAL_TOPIC, msg);
}
public void send(String topic, String msg) {
/**
* ProducerRecord实际满参构造函数有5个
* ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value)
* @param topic 主题
* @param partition 指定分区存储
* @param timestamp 消息时间戳.
* @param key 决定分区的key值
* @param value 消息内容
*/
ProducerRecord<String, String> producerRecord = new ProducerRecord<>(topic, msg);
// 消息发送成功与否情况回调
producer.send(producerRecord, (metadata, exception) -> {
if(exception == null) System.out.println("send success");
else System.out.println("send error");
});
}
| 属性 | 说明 |
|---|---|
| bootstrap.servers | kafka的url连接地址 |
| key.serializer | key值序列化器 |
| value.serializer | value值序列化器 |
| acks | 确认broker是否成功接收到生产消息 0:发送后不管broker接收结果 1:broker主节点收到消息 all:主和跟随者节点都收到该消息 |
| compression.type | 是否压缩发送,减少网络传输时间,但增加了CPU算力 |
| retries | 重试次数 |
拦截器
上述demo中,如配置了拦截器,则先走拦截器过滤,如下源码。
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
// intercept the record, which can be potentially modified; this method does not throw exceptions
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
return doSend(interceptedRecord, callback);
}
public ProducerRecord<K, V> onSend(ProducerRecord<K, V> record) {
ProducerRecord<K, V> interceptRecord = record;
for (ProducerInterceptor<K, V> interceptor : this.interceptors) {
try {
interceptRecord = interceptor.onSend(interceptRecord);
} catch (Exception e) {
// 拦截器抛出的异常是没用的哈
if (record != null)
log.warn("Error executing interceptor onSend callback for topic: {}, partition: {}", record.topic(), record.partition(), e);
else
log.warn("Error executing interceptor onSend callback", e);
}
}
return interceptRecord;
}
拦截器基类:
/**
* 手动修改record,返回新的记录
*/
public ProducerRecord<K, V> onSend(ProducerRecord<K, V> record);
/**
* 记录发送到服务器后回调,或者发送服务器异常回调。 在 callback回调执行前执行该方法
*/
public void onAcknowledgement(RecordMetadata metadata, Exception exception);
/**
* 拦截器关闭时调用
*/
public void close();
- onSend(ProducerRecord):该⽅法封装进KafkaProducer.send⽅法中,即运⾏在⽤户主线程中。 Producer确保在消息被序列化以计算分区前调⽤该⽅法。⽤户可以在该⽅法中对消息做任何操作,但最好保证不要修改消息所属的topic和分区,否则会影响⽬标分区的计算。
- onAcknowledgement(RecordMetadata, Exception):该⽅法会在消息被应答之前或消息发送失败时调⽤,并且通常都是在Producer回调逻辑触发之前。 onAcknowledgement运⾏在Producer的IO线程中,因此不要在该⽅法中放⼊很重的逻辑,否则会拖慢Producer的消息发送效率。
- close:关闭Interceptor,主要⽤于执⾏⼀些资源清理⼯作。
如前所述, Interceptor可能被运⾏在多个线程中,因此在具体实现时⽤户需要⾃⾏确保线程安全。
分区器
分区器,顾名思义对生产的消息进行分区运算,这里我们可以在配置中添加自己的分区器,也可以使用kafka默认分区器。
默认分区器工作机制:
/**
* 如果record指定分区不为空,则使用record自带的partition
*/
private int partition(ProducerRecord<K, V> record, byte[] serializedKey, byte[] serializedValue, Cluster cluster) {
// record是否含partition
Integer partition = record.partition();
return partition != null ?
partition :
partitioner.partition(
record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster);
}
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 获取所有的partitions
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
// 下一个值
int nextValue = nextValue(topic);
// 拿到所有可用分区
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
// 通过topic的下一个value,对可用的partition取模
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// 没有分区是可用的,对所有分区数取模
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// 通过key取hash,对partions数量取模
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
}
private int nextValue(String topic) {
// 线程安全的ConcurrentHashMap
AtomicInteger counter = topicCounterMap.get(topic);
if (null == counter) {
// 获取一个随机值
counter = new AtomicInteger(ThreadLocalRandom.current().nextInt());
// 存入map
AtomicInteger currentCounter = topicCounterMap.putIfAbsent(topic, counter);
if (currentCounter != null) {
counter = currentCounter;
}
}
return counter.getAndIncrement();
}
自定义分区器
- 实现Partitioner接口即可
- 在KafkaProducer中进⾏设置:configs.put(“partitioner.class”,“xxx.xx.Xxx.class”)
代码就略了
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);
/**
* partition关闭时调用
*/
public void close();
源代码原理剖析
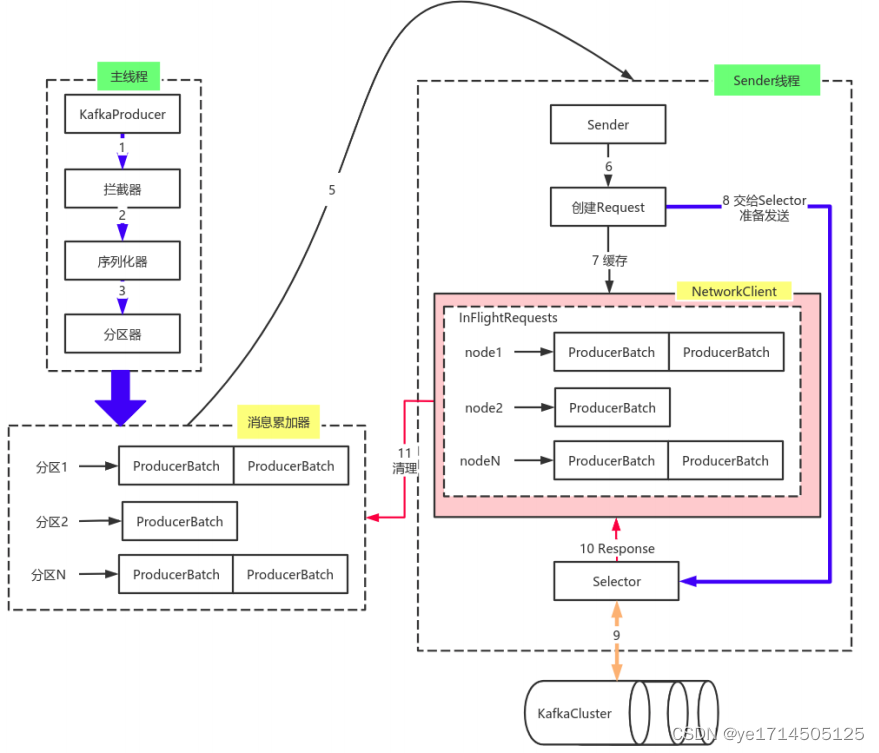
- 主线程:负责消息创建,拦截器,序列化器,分区器等操作,并将消息追加到消息收集器
主线程原理
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
TopicPartition tp = null;
try {
// 拿到集群原始数据初始化完成需要等待的时间
ClusterAndWaitTime clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), maxBlockTimeMs);
// 剩余的阻塞时长
long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);
Cluster cluster = clusterAndWaitTime.cluster;
byte[] serializedKey;
try {
// 序列化key
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() +
" specified in key.serializer", cce);
}
byte[] serializedValue;
try {
// 序列化value
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() +
" specified in value.serializer", cce);
}
// 获取消息所属的分区(见分区器)
int partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
// 消息头设置只读状态,防止更改
setReadOnly(record.headers());
Header[] headers = record.headers().toArray();
// 估算消息byte字节大小
int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(apiVersions.maxUsableProduceMagic(),
compressionType, serializedKey, serializedValue, headers);
// 验证消息的大小,不能太大
ensureValidRecordSize(serializedSize);
long timestamp = record.timestamp() == null ? time.milliseconds() : record.timestamp();
log.trace("Sending record {} with callback {} to topic {} partition {}", record, callback, record.topic(), partition);
// 回调包装,如果有拦截器,先回调拦截器的 acknowledge方法,再回调用户定义的callback方法
Callback interceptCallback = this.interceptors == null ? callback : new InterceptorCallback<>(callback, this.interceptors, tp);
// 如果开启事务需要将TopicPartition放transactionManager中
if (transactionManager != null && transactionManager.isTransactional())
//添加到缓冲区
transactionManager.maybeAddPartitionToTransaction(tp);
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs);
// 如果缓冲区新建或已满,唤醒sender线程
if (result.batchIsFull || result.newBatchCreated) {
this.sender.wakeup();
}
return result.future;
// handling exceptions and record the errors;
// for API exceptions return them in the future,
// for other exceptions throw directly
} catch (ApiException e) {
log.debug("Exception occurred during message send:", e);
if (callback != null)
callback.onCompletion(null, e);
this.errors.record();
if (this.interceptors != null)
this.interceptors.onSendError(record, tp, e);
return new FutureFailure(e);
} catch (InterruptedException e) {
this.errors.record();
if (this.interceptors != null)
this.interceptors.onSendError(record, tp, e);
throw new InterruptException(e);
} catch (BufferExhaustedException e) {
this.errors.record();
this.metrics.sensor("buffer-exhausted-records").record();
if (this.interceptors != null)
this.interceptors.onSendError(record, tp, e);
throw e;
} catch (KafkaException e) {
this.errors.record();
if (this.interceptors != null)
this.interceptors.onSendError(record, tp, e);
throw e;
} catch (Exception e) {
// we notify interceptor about all exceptions, since onSend is called before anything else in this method
if (this.interceptors != null)
this.interceptors.onSendError(record, tp, e);
throw e;
}
}
- 累加器原理
RecoderAccumulator中;
- 消息收集器RecoderAccumulator为每个分区TopicPartition都维护了⼀个 Deque 类型的双端队列,使用ConcurrentHashMap存储。
- ProducerBatch 可以理解为是 ProducerRecord 的集合,批量发送有利于提升吞吐量,降低⽹络影响;
- 由于⽣产者客户端使⽤ java.io.ByteBuffer 在发送消息之前进⾏消息保存,并维护了⼀个BufferPool 实现 ByteBuffer 的复⽤;该缓存池只针对特定⼤⼩( batch.size 指定)的 ByteBuffer进⾏管理,对于消息过⼤的缓存,不能做到重复利⽤。
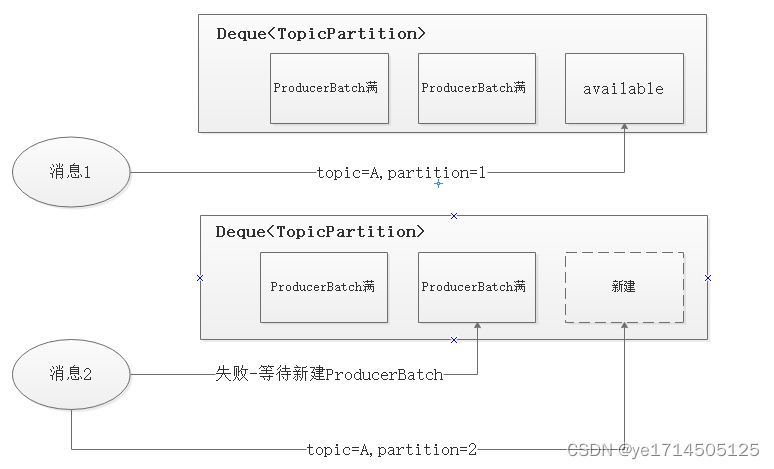
- 每次追加⼀条ProducerRecord消息,会寻找/新建对应的双端队列,从其尾部获取⼀个ProducerBatch,判断当前消息的⼤⼩是否可以写⼊该批次中。若可以写⼊则写⼊;若不可以写⼊,则新建⼀个ProducerBatch。
public RecordAppendResult append(TopicPartition tp,
long timestamp,
byte[] key,
byte[] value,
Header[] headers,
Callback callback,
long maxTimeToBlock) throws InterruptedException {
// 旨在记录正在添加消息的条目(添加完成后,会还原)
appendsInProgress.incrementAndGet();
ByteBuffer buffer = null;
if (headers == null) headers = Record.EMPTY_HEADERS;
try {
// 拿到Deque,如不存在则创建一个Deque(tp是Topic和Partition共同决定,作为key)
Deque<ProducerBatch> dq = getOrCreateDeque(tp);
synchronized (dq) {
if (closed)
throw new IllegalStateException("Cannot send after the producer is closed.");
// 尝试新增一条记录,如Deque末尾ProducerBatch集合存在且未满,追加记录,否则失败
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);
if (appendResult != null)
return appendResult;
}
/**
* 以下逻辑旨在给 Deque分配一个新的 ProducerBatch
*/
// 猜测可能是根据kafka的api版本分配的最大可用字节
byte maxUsableMagic = apiVersions.maxUsableProduceMagic();
// 分配到批次字节与消息本身所占用字节取最大值
int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression, key, value, headers));
log.trace("Allocating a new {} byte message buffer for topic {} partition {}", size, tp.topic(), tp.partition());
/**
* 分配内存,这行代码为什么没放到锁代码里面,想了想可能是这个原因
* 1. 消息生产是相当快的,ProducerBatch很快打满或超时发送到broker,也就是说多个线程排队抢dq期间,其中大部分线程可能都得重新键ProducerBatch。
* 2. 分配内存代码可能是相对耗时的,线程在等待获取锁的期间,先将内存提前分配避免进入到锁内,每个线程排队落库ProducerBatch再重新分配内存,提高效率
*/
buffer = free.allocate(size, maxTimeToBlock);
synchronized (dq) {
// 防止分配内存期间,其他线程已创建ProducerBatch,重试添加(防止并发)
if (closed)
throw new IllegalStateException("Cannot send after the producer is closed.");
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);
if (appendResult != null) {
return appendResult;
}
// 为消息分配内存
MemoryRecordsBuilder recordsBuilder = recordsBuilder(buffer, maxUsableMagic);
ProducerBatch batch = new ProducerBatch(tp, recordsBuilder, time.milliseconds());
// ProducerBatch添加记录
FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, headers, callback, time.milliseconds()));
// 添加到双端队列末尾
dq.addLast(batch);
incomplete.add(batch);
buffer = null;
return new RecordAppendResult(future, dq.size() > 1 || batch.isFull(), true);
}
} finally {
if (buffer != null)
// 释放缓存
free.deallocate(buffer);
// 该条消息添加完毕,还原
appendsInProgress.decrementAndGet();
}
}
- Sender线程:
- 该线程从消息收集器获取缓存的消息,将其处理为 <Node, List 的形式, Node表示集群的broker节点。
- 进⼀步将<Node, List转化为<Node, Request>形式,此时才可以向服务端发送数据。
- 在发送之前,Sender线程将消息以 Map<NodeId, Deque> 的形式保存到InFlightRequests 中进⾏缓存,可以通过其获取 leastLoadedNode ,即当前Node中负载压⼒最⼩的⼀个,以实现消息的尽快发出。
public void run() {
while (running) {
try {
// 开始消费
run(time.milliseconds());
} catch (Exception e) {
log.error("Uncaught error in kafka producer I/O thread: ", e);
}
}
/**
* 1. 以上消费鉴于线程的开关,在线程收到关闭命令后,停止消费。
* 2. 那未消费完的Deque怎么办,接着消费直至完成
* 3. 那些还在等待请求结果request 咋办,等着一起完成
*/
while (!forceClose && (this.accumulator.hasUndrained() || this.client.inFlightRequestCount() > 0)) {
try {
run(time.milliseconds());
} catch (Exception e) {
log.error("Uncaught error in kafka producer I/O thread: ", e);
}
}
if (forceClose) {
this.accumulator.abortIncompleteBatches();
}
try {
this.client.close();
} catch (Exception e) {
log.error("Failed to close network client", e);
}
log.debug("Shutdown of Kafka producer I/O thread has completed.");
}
void run(long now) {
if (transactionManager != null) {
try {
if (transactionManager.shouldResetProducerStateAfterResolvingSequences())
// 重置批次生产信息
transactionManager.resetProducerId();
// 如果事务还在进行中,等待
if (!transactionManager.isTransactional()) {
maybeWaitForProducerId();
} else if (transactionManager.hasUnresolvedSequences() && !transactionManager.hasFatalError()) {
transactionManager.transitionToFatalError(new KafkaException("The client hasn't received acknowledgment for " +
"some previously sent messages and can no longer retry them. It isn't safe to continue."));
} else if (transactionManager.hasInFlightTransactionalRequest() || maybeSendTransactionalRequest(now)) {
// as long as there are outstanding transactional requests, we simply wait for them to return
client.poll(retryBackoffMs, now);
return;
}
// do not continue sending if the transaction manager is in a failed state or if there
// is no producer id (for the idempotent case).
if (transactionManager.hasFatalError() || !transactionManager.hasProducerId()) {
RuntimeException lastError = transactionManager.lastError();
if (lastError != null)
maybeAbortBatches(lastError);
client.poll(retryBackoffMs, now);
return;
} else if (transactionManager.hasAbortableError()) {
accumulator.abortUndrainedBatches(transactionManager.lastError());
}
} catch (AuthenticationException e) {
// This is already logged as error, but propagated here to perform any clean ups.
log.trace("Authentication exception while processing transactional request: {}", e);
transactionManager.authenticationFailed(e);
}
}
// 这才是重点,发送生产数据
long pollTimeout = sendProducerData(now);
client.poll(pollTimeout, now);
}
private long sendProducerData(long now) {
//步骤1:获取元数据
Cluster cluster = metadata.fetch();
// get the list of partitions with data ready to send
//步骤2: 判断哪些Partition有消息可以发送,获取到这个partition的Leader Partition对应的Broker主机
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
// if there are any partitions whose leaders are not known yet, force metadata update
//步骤3:标识还没有拉取到元数据的topic
if (!result.unknownLeaderTopics.isEmpty()) {
// The set of topics with unknown leader contains topics with leader election pending as well as
// topics which may have expired. Add the topic again to metadata to ensure it is included
// and request metadata update, since there are messages to send to the topic.
for (String topic : result.unknownLeaderTopics)
this.metadata.add(topic);
log.debug("Requesting metadata update due to unknown leader topics from the batched records: {}", result.unknownLeaderTopics);
this.metadata.requestUpdate();
}
// remove any nodes we aren't ready to send to
Iterator<Node> iter = result.readyNodes.iterator();
long notReadyTimeout = Long.MAX_VALUE;
while (iter.hasNext()) {
Node node = iter.next();
//步骤4:检查与要发送的主机的网络是否已经建立好
if (!this.client.ready(node, now)) {
iter.remove();
notReadyTimeout = Math.min(notReadyTimeout, this.client.pollDelayMs(node, now));
}
}
// create produce requests
/**步骤5:要发送的partition有很多个,很有可能有一些partition的Leader Partition有可能是在同一台服务器上的
* 当我们的分区的个数大于集群节点个数时,一定会有多个Leader分区在同一台服务器上,
* 它会按照Broker进行分组,同一个Broker的Partition为同一组
*/
Map<Integer, List<ProducerBatch>> batches = this.accumulator.drain(cluster, result.readyNodes,
this.maxRequestSize, now);
if (guaranteeMessageOrder) {
// Mute all the partitions drained
for (List<ProducerBatch> batchList : batches.values()) {
for (ProducerBatch batch : batchList)
this.accumulator.mutePartition(batch.topicPartition);
}
}
//步骤6:放弃超时的batch
List<ProducerBatch> expiredBatches = this.accumulator.expiredBatches(this.requestTimeoutMs, now);
// Reset the producer id if an expired batch has previously been sent to the broker. Also update the metrics
// for expired batches. see the documentation of @TransactionState.resetProducerId to understand why
// we need to reset the producer id here.
if (!expiredBatches.isEmpty())
log.trace("Expired {} batches in accumulator", expiredBatches.size());
for (ProducerBatch expiredBatch : expiredBatches) {
failBatch(expiredBatch, -1, NO_TIMESTAMP, expiredBatch.timeoutException(), false);
if (transactionManager != null && expiredBatch.inRetry()) {
// This ensures that no new batches are drained until the current in flight batches are fully resolved.
transactionManager.markSequenceUnresolved(expiredBatch.topicPartition);
}
}
sensors.updateProduceRequestMetrics(batches);
// If we have any nodes that are ready to send + have sendable data, poll with 0 timeout so this can immediately
// loop and try sending more data. Otherwise, the timeout is determined by nodes that have partitions with data
// that isn't yet sendable (e.g. lingering, backing off). Note that this specifically does not include nodes
// with sendable data that aren't ready to send since they would cause busy looping.
long pollTimeout = Math.min(result.nextReadyCheckDelayMs, notReadyTimeout);
if (!result.readyNodes.isEmpty()) {
log.trace("Nodes with data ready to send: {}", result.readyNodes);
// if some partitions are already ready to be sent, the select time would be 0;
// otherwise if some partition already has some data accumulated but not ready yet,
// the select time will be the time difference between now and its linger expiry time;
// otherwise the select time will be the time difference between now and the metadata expiry time;
pollTimeout = 0;
}
//步骤7:发送请求
sendProduceRequests(batches, now);
return pollTimeout;
}