前言:尽量使用简单易懂的通俗语言让大家初步了解各个重要的知识点。博学之,审问之,慎思之,明辨之,笃行之。
一、容器(Collection)
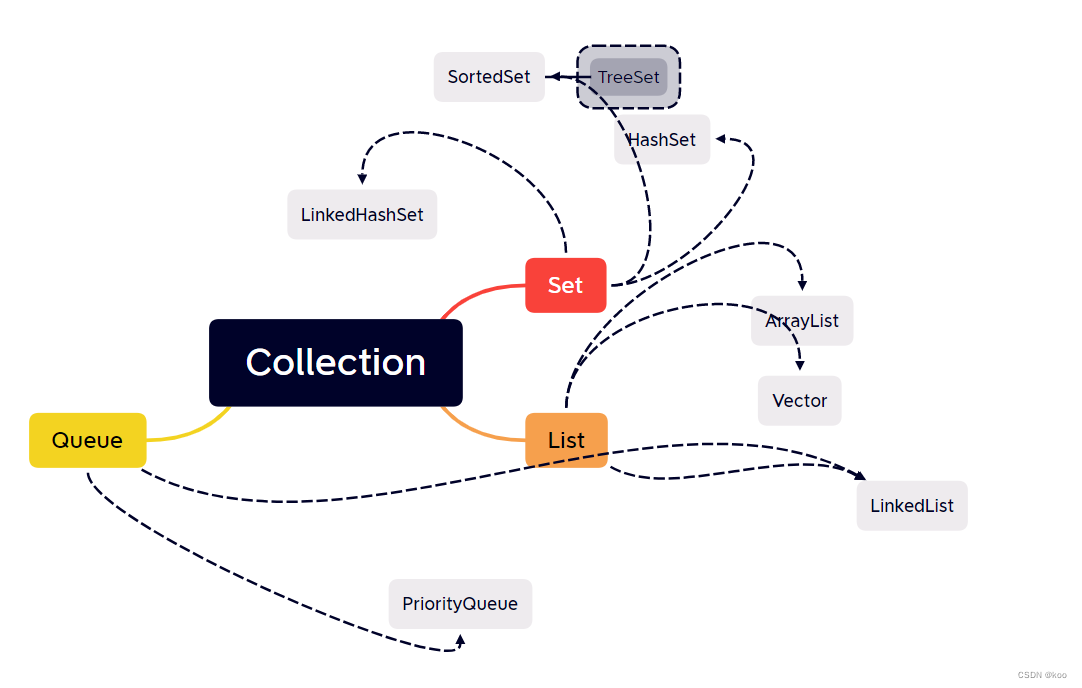
Collection容器其实是用来存储独立元素的各种数据结构,如图所示。主要是Set、List、Queue等数据结构,又分为不同的分支具有部分不同的属性和特性。Collection是整个集合框架的基础,提供了维护一组对象的基本接口。
1、ArrayList
ArrayList其实就是动态数组或可扩容数组,底层也是数组实现,基本容量为10,扩容机制为(size*1.5),即每次扩容都是上一次的1.5倍。这也就导致如果数据量较大时,进行写入数据会较慢,因为需要进行不断的扩容。
2、LinkedList
LinkedList是顺序访问结构,也就是链表,内部实现为双向列表,因此在头尾增删数据会比较迅速,随机插入则需要遍历。
3、Vector
Vector类似于ArrayList,但是扩容机制不同,它的扩容机制默认为2倍,且相比之下是线程安全的。因为大多数Vector的方法是synchroization(同步),而ArrayList的方法是不同步的。且Stack为Vector的子类。
二、Map类
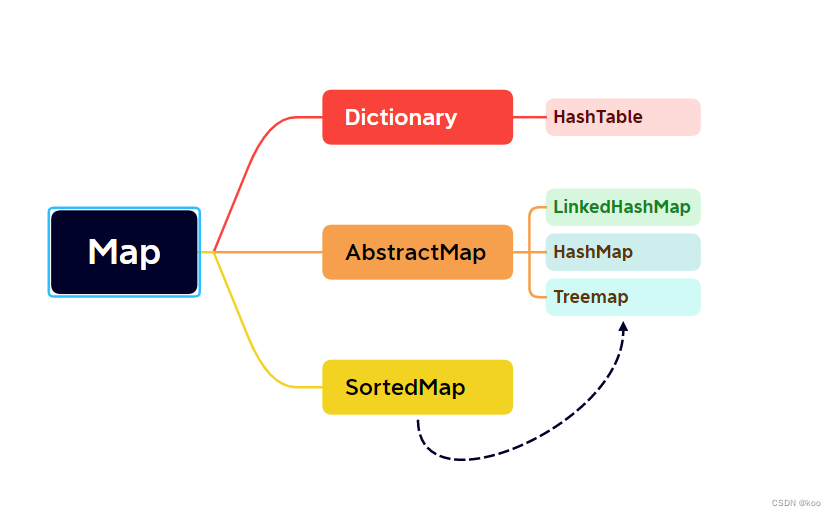
1、HashMap
HashMap是最常用的Map结构,通常用来存储K-V键值对形式的数据,且用数组来存储键值对,根据Key的hashcode来决定数组下标。且目前版本的JDK,HashMap的底层实现是通过数组+树+链表的形式。一般只有当一个Key对应多个值,使得该hashcode下标对应的链表超过阈值时,会将链表重构为红黑树。查找的时间复杂度由链表的O(n)变成红黑树的O(log2n)。
其默认容量是16,且扩容为size*2,且一定为2的指数。
2、LinkedHashMap
与HashMap相比,LInkedHashMap内部维护了一个双向链表,使得存储的数据是有序的,而HashMap一般是无序的。且该双向链表可以看做是环形的。
3、HashTable
HashTable与HashMap类似,但是有以下不同点:
1、HashMap允许存储有且仅有一个Null值作为Key,HashTable不可以。
2、HashTable被Sybchronized修饰,意味着它的实现是线程安全的,HashMap则不是。
3、HashTable的默认容量是11,扩容机制为size*2+1。
4、TreeMap
类似于HashMap,不同点在于实现lSortMap接口,可以按顺序或自定义顺序进行遍历。
三、Set(集合)
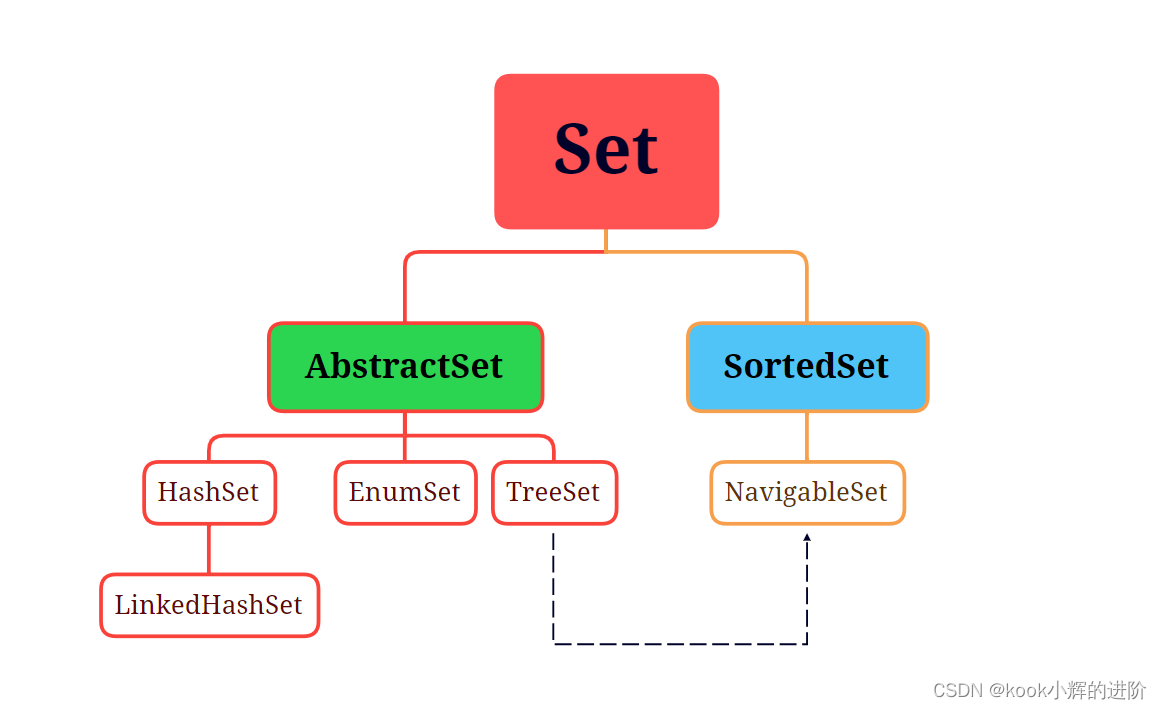
1、HashSet
集合的两个特性:
1、HashSet里不能有重复的元素
2、最多只允许有一个Null。
且HashSet实际上不是线程安全的,且存储的数据也是无序的。
2、LinkedHashSet
与HashSet相比,LinkedHashSet则是可以维护插入元素的顺序,因为其内部有双向链表进行对数据的维护。
3、TreeSet
TreeSet具有HashSet的所有特性,并且还能够进行排序,可以通过实现Comparator(比较器)来实现排序。
四、Queue
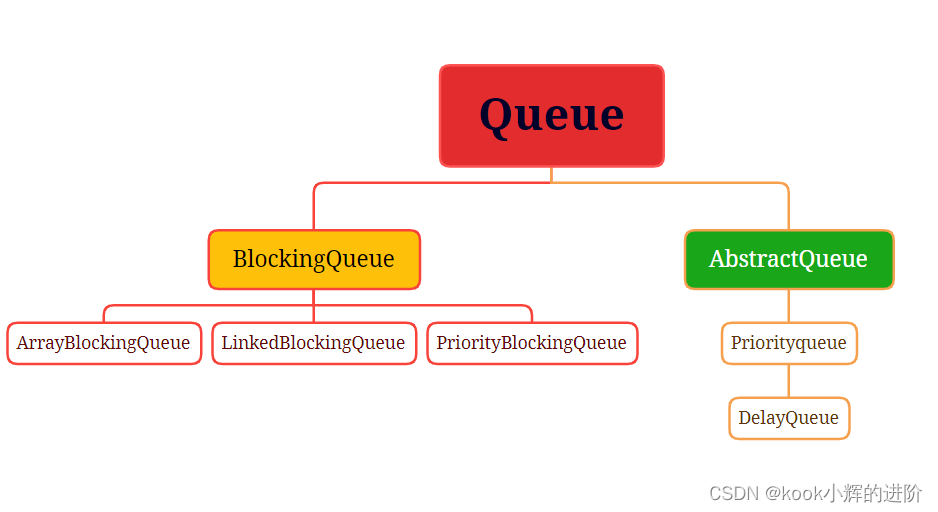
1、BlockingQueue
多线程环境下,经常使用的“生产者-消费者”模式,负责生产的线程将是生产的资源放入一个共享容器,并且由消费者取出。那么这个容器一般可以是Queue或者Stack。阻塞队列可以在仓库满时把生产线程挂起,在仓库为空时把消费者线程挂起。
2、ArrayBlockingQueue
ArrayBlockingQueue是基于数组实现的有界阻塞队列,满足FIFO的特性,是一个典型的有界缓冲,数组大小是固定的,确定就无法再更改了。
3、LinkedBlockingQueue
LinkedBlockingQueue是基于链表实现的,且可以指定容量,具有两份重入锁,对应取值与存值。
4、PriorityBlockingQueue
PriorityBlockingQueue不是一个FIFO队列,需要提供一个Comparator,或者Comparable接口,队头元素为最小的元素。它也是用数组实现的最小堆结构。
发文不易,恳请大佬们高抬贵手!
点赞:随手点赞是种美德,是大佬们对于本人创作的认可!
评论:往来无白丁,是你我交流的的开始!
收藏:愿君多采撷,是大佬们对在下的赞赏!