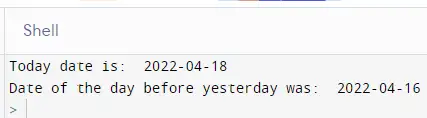
TIPS
- 在类当中不受访问限定符的限制,在类外面才会受到限制
- 由于内存栈区的使用习惯是先使用高地址,再使用低地址;因此比方说有两个实例化对象依次创建,并且这两个实例化对象当中都有析构函数,也就是当退出销毁的时候,都承担着归还内存堆区空间给操作系统的任务,那么应该是后创建的实例化对象先执行释放堆区空间的任务,因为栈区的使用习惯是地址从高到低,那么当退出销毁归还给操作系统的时候就是按从低到高的地址顺序
- 实际上对于类的实例化对象当中的自定义类型成员,无论是从自己去实现构造函数,析构函数与拷贝构造函数,还是编译器去默认生成的角度去看的话,那些自定义类型成员都是比较省心的,因为自定义类型成员变量它本质上也是一个五脏俱全的类的实例化对象,我只需要去调用它的构造函数/析构函数/拷贝构造函数即可。
构造函数复习与回顾

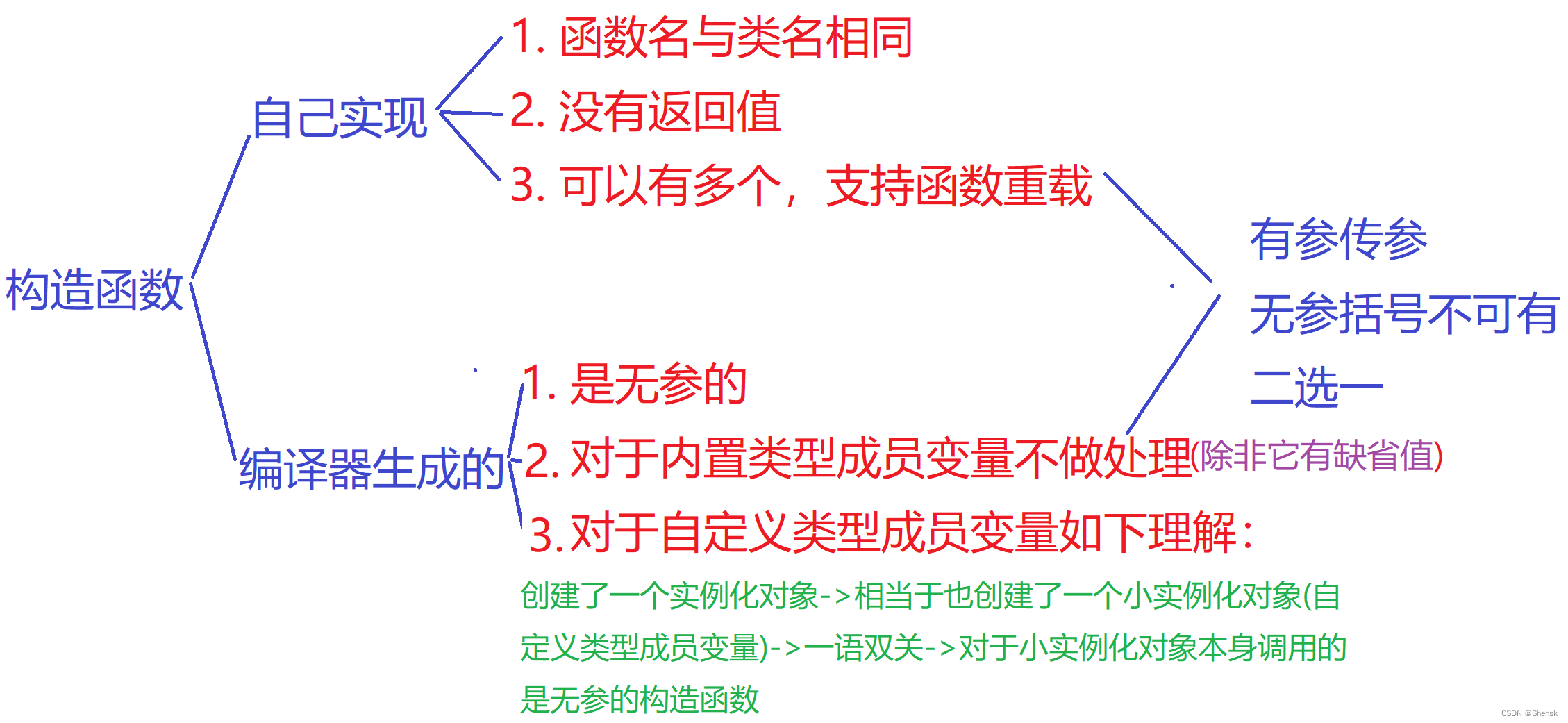
- 构造函数支持函数重载
- 默认构造函数就是无参的构造函数或全缺省的构造函数,或者说编译器自己生成的构造函数,这三个函数被称为默认构造函数,默认构造函数的话有且只能存在一个
- 如果说用户没有去显示的去定义一个构造函数,那么编译器会默认生成一个无参的构造函数,注意编译器自己生成的一个默认构造函数是没有参数的,并且对于编译器自己生成的默认构造函数,对于某些属于内置类型的成员变量是不做处理的,但是对于那些自定义类型的成员变量会进行处理。
- 并且构造函数一定要放在类当中的public区域的,因为如果你把构造函数放在私有区域的话,当类的实例化对象创建的时候,会一语双关去调用这个构造函数,但如果这个构造函数在私有区域的话,就无法调用与访问,所以说,就会报错。
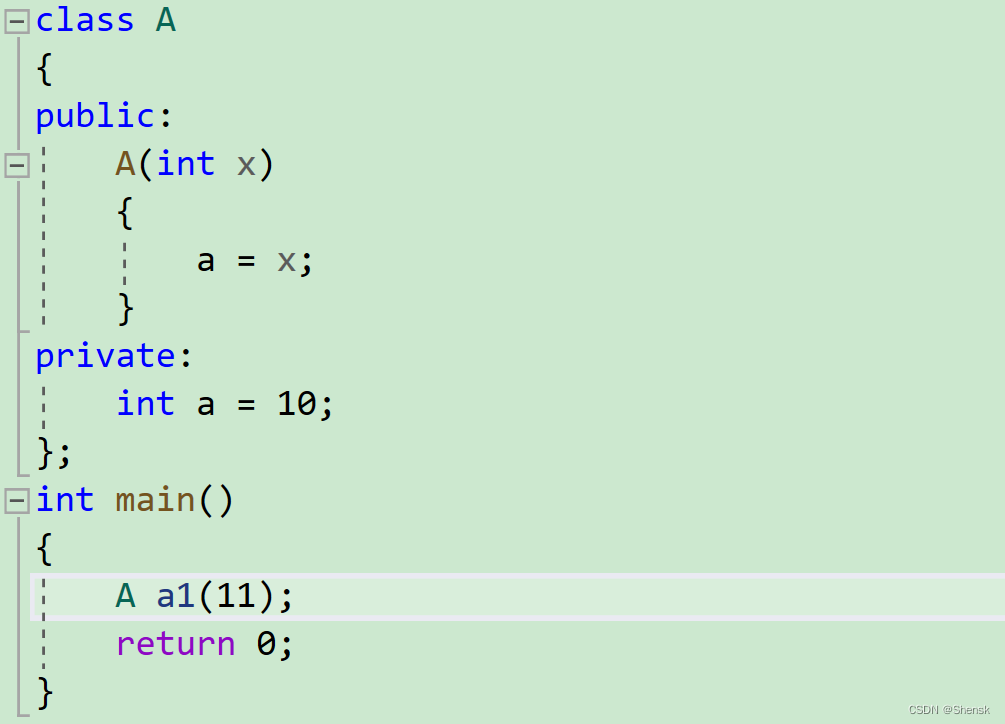

- 构造函数在整个对象的生命周期内是只能够调用一次,然后构造函数的调用与类的实例化对象创建在语法上面格式一模一样,所以相当于是一语双关,然后构造函数的调用(就是类的实例化对象的创建)如果说没有参数的话,后面是不能加上括号的,这个与普通的函数调用并不一样
- 在c++11当中打了一个补丁,也就是说当在创建类的时候,可以对这些类的内置类型成员变量去给一个初始值(缺省值),那么这样子的话,编译器默认生成的构造函数将会用缺省初始值对于那些内置类型的成员变量进行初始化。
编译器自己生成的默认构造函数对于内置类型与自定义类型处理详解

- 在一般情况下,构造函数都需要我们自己去写,当然也有以下几种特殊情况:因为如果你不想去写构造函数的话,就要寄希望于编译器自己生成的构造函数能够完成对于你这个类的对象各个成员进行初始化的工作。但问题就在于编译器自己生成的构造函数对于内置类型不会进行初始化,所以说如果说你的内置类型都有缺省值的话且初始化符合我们的要求那么就可以用编译器默认生成的构造函数。
- 然后之前一直在提编译器生成的默认构造函数会对自定义类型的成员变量进行初始化:这边就需要注意两点,首先各种各样杂七杂八的指针,无论它指向的内存空间里面的数据类型是什么,但终究还是指针,并不属于自定义类型。第二就在于,对于正儿八经的自定义类型如class,struct…的成员变量,编译器默认生成的构造函数 确实会对他进行初始化,但结合之前的一语双关的知识,会发现这个初始化需要建立在这些类型都进行默认构造的前提之下。这边必须结合一语双关的那个知识。
- 其实编译器默认生成的那个构造函数对于自定义类型的成员变量进行初始化,你可以把它理解成:首先你先创建了一个类的实例化对象,那么这个实例化对象里面它势必会包含那个自定义类型的成员变量,所以说你在创建类的实例化对象的时候,其实也是在创建了那个自定义类型的成员变量。那么既然那个自定义类型的成员变量被创建出来,如stack s1; 那么这时候就可以用之前讲的一语双关的看法去看待他,于此同时你会发现确实会进行初始化,只不过是那个自定义类型的成员变量在创建的时候调用的那个构造函数是无参的,也就是那三个默认构造函数当中的其中某一个。那如果说对于那个自定义类型的成员变量要带参进行初始化,那这个就涉及到之后的知识…
析构函数
- 析构函数:与构造函数功能相反,析构函数不是完成对对象本身的销毁,局部对象销毁工作是由编译器完成的。而对象在销毁时会自动调用析构函数,完成对象中资源的清理工作

3. 析构函数如果我们不写的话,编译器也会自动默认生成一个,对于编译器自己生成的默认析构函数,对于这个类的对象当中的内置类型的成员变量的话不做任何处理,对于自定义类型的成员变量的话去对应的调用它的析构函数
4. 一般情况下,如果说向内存的堆区动态申请资源就需要显示写析构函数释放资源,不然就会造成内存泄露;然后如果没有动态申请的资源,就不需要写析构函数;或者说需要释放的成员都是自定义类型,那也就不需要去写析构函数,因为编译器自己生成的析构函数会对那些自定义类型的成员变量进行处理(实际上就是去调用那些自定义类型的析构函数)

简单示例代码
#include <iostream>
#include <stdlib.h>
using namespace std;
class A
{
public:
//构造函数
A(int size)
{
_size = size;
_pa = (int*)malloc(sizeof(int) * _size);
if (_pa == NULL)
{
perror("malloc failed");
return;
}
}
void input()
{
for (int i = 0; i < _size; i++)
{
scanf("%d", &_pa[i]);
}
}
void output()
{
for (int i = 0; i < _size; i++)
{
cout << _pa[i] << " ";
}
cout << endl;
}
~A()
{
free(_pa);
_size = 0;
}
private:
int* _pa;
int _size;
};
int main()
{
A a(10);
a.input();
a.output();
return 0;
}

拷贝构造函数
- 如果说实例化对象进行函数传值传参(包括一语双关当中的构造函数)或者实例化对象之间进行赋值(还有一种场景就是函数的传值返回,因为传值返回的话,在函数的外面就会有一个东西去接受返回值,所以本质上就是赋值),这就意味着有新的实例化对象生成,也就意味着一语双关会调用构造函数,此时调用的这个构造函数就是拷贝构造函数。
- 由于他也是默认成员函数,所以说可以自己写一个在类当中,如果自己没有显示实现的话,编译器也会自己默认生成一个拷贝构造函数。
- 拷贝构造函数:只有单个形参***,该形参是对本类类型对象的引用(一般常用const修饰),在用已存在的类类型对象创建新对象时由编译器自动调用***
- 对于编译器自己默认生成的拷贝构造函数的话,对于内置类型成员也会进行处理,对于自定义类型成员肯定会进行处理。对于内置类型成员完成值拷贝或浅拷贝(就是说将对象以内存存储按字节序完成拷贝,就是类似于像memcpy一样,一个字节一个字节的给他拷贝过去,是相当直白与耿直的拷贝);然后对于自定义类型的成员变量,就去调用他的拷贝构造函数。
- 按道理来说,编译器自己生成的默认拷贝构造函数已经能够满足拷贝实例化对象的一个需求,实际上大部分情况都是这样。但也会存在着特殊情况会发生严重的错误:比如说在实例化对象当中,有一个成员指针指向的是一块内存堆区上的空间,此时如果用编译器的默认拷贝构造函数,那么也会把那个成员指针按每个字节给他全部拷贝到新的实例化对象当中,就会导致两个实例化对象的成员指针指向的都是同一块内存堆区空间。
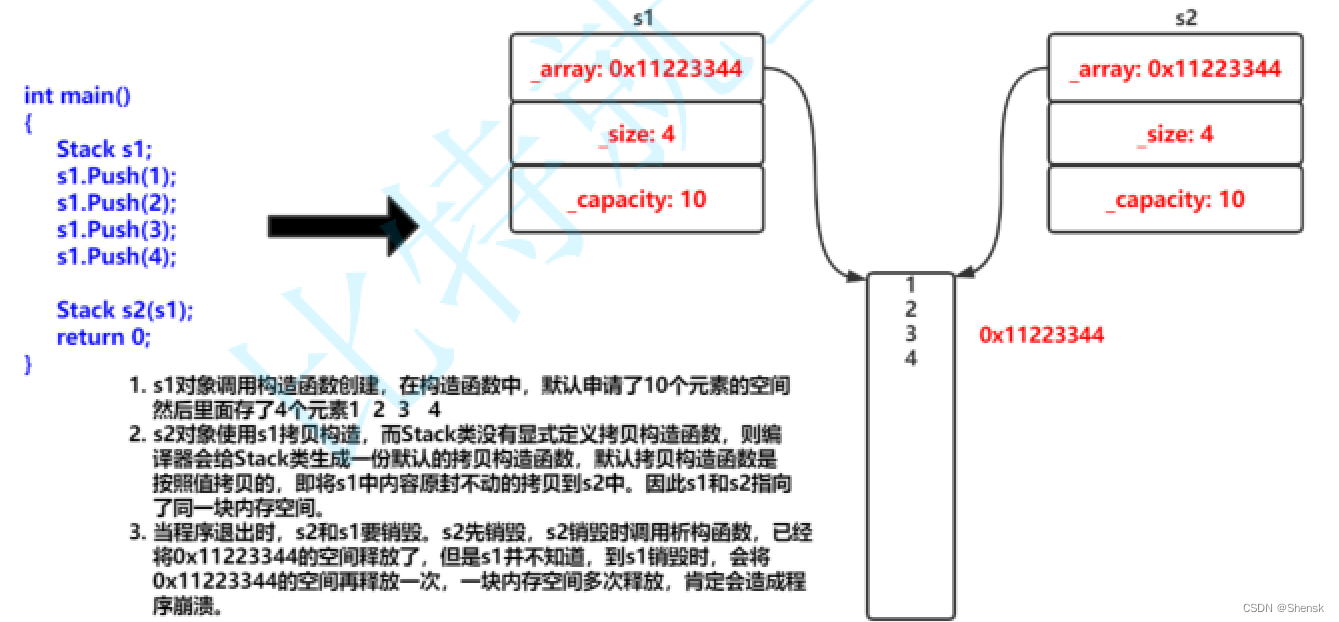
- 这就会造成两个问题***:1. 首先就是在这两个实例化对象消亡的时候会调用两次析构函数,也就意味着同一块内存堆取空间被释放free了两次;2. 这两个实例化对象共同指向同一内存空间,就使得他们已经丧失了相互之间的独立性,只要在某一个实例化对象当中修改一下内存数据,对于另一个实例化对象也会受到影响。***
- 注意:在编译器生成的默认拷贝构造函数中,内置类型是按照字节方式直接拷贝的,而自定义类型是调用其拷贝构造函数完成拷贝的。

关于拷贝构造函数参数不能传值而需要用引用的解释
- 因为对于一个实例化对象,如果说需要参与到函数的传值传参调用的话,那么必须要先进入到该类的拷贝构造函数当中,如果说拷贝构造函数的参数也是传值的话,那么这时候相当于又是类的实例化对象在进行函数的传值传参调用,那么又需要去进入到拷贝构造函数,如此一来的话,就会无穷递归下去
- 拷贝构造函数的参数只有一个且必须是类类型对象的引用,使用传值方式编译器直接报错,因为会引发无穷递归调用。

关于自己写拷贝构造函数时的const修饰问题
- 这就涉及到之前的引用的时候,权限能够给平移或者缩小,但是不能够进行权限放大,所以说在引用某一个变量或者内存空间的时候,如果说在特定的情形之下,那个内存空间里面的数据是不能被修改的,那么某个外号的引用一般都需要用const的修饰一下去引用,因为权限是可以平移或缩小的。
- 由于我是依据一个已经存在的实例化对象,然后把它各个成员的数据拷贝到一个新的实例化对象,那么我原先的实例化对象当中,各个成员的数据肯定是不能被修改的,因此在引用的时候,必须要用const的修饰一下。
从拷贝构造函数得到关于引用的一些思考
- 所以这也从侧面角度更加凸显出了引用参与到函数传参与函数返回的重要性,尤其是当涉及到实例化对象进行函数传参与函数返回的时候,如果说不进行引用的优化的话,那么这时候会有新的实例化对象的创建与调用拷贝构造函数,尤其是当为深拷贝的时候,效率就会放慢,但是如果我用引用的话,效率就会高不少。
- 为了提高程序效率,一般对象传参时,尽量使用引用类型,返回时根据实际场景,能用引用尽量使用引用。
代码模拟(我自己实现的拷贝构造函数(深拷贝))
#include <iostream>
#include <stdlib.h>
using namespace std;
class A
{
public:
//构造函数
A(int size)
{
_capacity = size;
_pa = (int*)malloc(sizeof(int) * _capacity);
if (_pa == NULL)
{
perror("malloc failed");
return;
}
}
//拷贝构造函数
A(const A& a)
{
_capacity = a._capacity;
_pa = (int*)malloc(sizeof(int) * a._capacity);
if (_pa == NULL)
{
perror("malloc failed");
return;
}
memcpy(_pa, a._pa, sizeof(int) * a._capacity);
}
void input()
{
for (int i = 0; i < _capacity; i++)
{
scanf("%d", &_pa[i]);
}
}
void output()
{
for (int i = 0; i < _capacity; i++)
{
cout << _pa[i] << " ";
}
cout << endl;
}
~A()
{
free(_pa);
_capacity = 0;
}
private:
int* _pa;
int _capacity;
};
int main()
{
A a(10);
cout << "往实例化对象a里面输入:" << endl;
a.input();
cout << "实例化对象a里面的数据" << endl;
a.output();
A b = a;
cout << "实例化对象b是a的拷贝,b目前数据如下:" << endl;
b.output();
cout << "修改a的数据,重新输入" << endl;
a.input();
cout << "现在实例化对象a里面的数据" << endl;
a.output();
cout << "现在实例化对象b里面的数据" << endl;
b.output();
return 0;
}

代码模拟(编译器自己生成的拷贝构造函数(浅拷贝))
#include <iostream>
#include <stdlib.h>
using namespace std;
class A
{
public:
//构造函数
A(int size)
{
_capacity = size;
_pa = (int*)malloc(sizeof(int) * _capacity);
if (_pa == NULL)
{
perror("malloc failed");
return;
}
}
void input()
{
for (int i = 0; i < _capacity; i++)
{
scanf("%d", &_pa[i]);
}
}
void output()
{
for (int i = 0; i < _capacity; i++)
{
cout << _pa[i] << " ";
}
cout << endl;
}
~A()
{
free(_pa);
_capacity = 0;
}
private:
int* _pa;
int _capacity;
};
int main()
{
A a(10);
cout << "往实例化对象a里面输入:" << endl;
a.input();
cout << "实例化对象a里面的数据" << endl;
a.output();
A b = a;
cout << "实例化对象b是a的拷贝,b目前数据如下:" << endl;
b.output();
cout << "修改a的数据,重新输入" << endl;
a.input();
cout << "现在实例化对象a里面的数据" << endl;
a.output();
cout << "现在实例化对象b里面的数据" << endl;
b.output();
return 0;
}

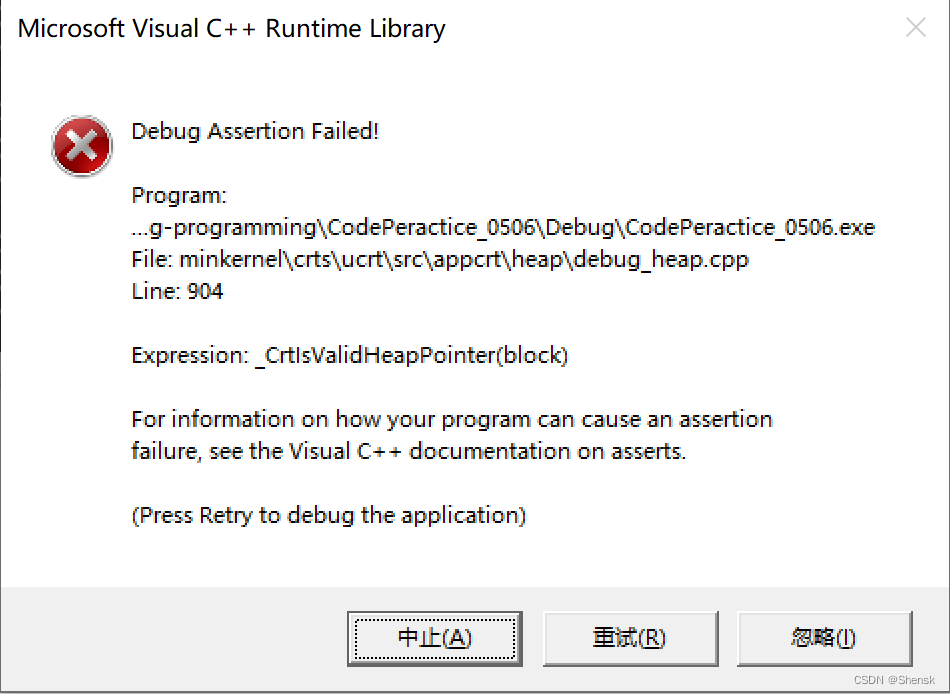
上面这个报错主要在于一块堆区空间被释放完了之后又去释放一遍